python基本数据类型,运算符
一: 变量名
1.1:变量名的使用
1.2: 变量命名规范
1.3:变量值的两大特征
二:基本数据类型
2.1 整型 int
2.2 浮点型 float
2.3 字符串 str
2.4 列表 list
2.5: 字典 dict
2.6 布尔值 bool
三:基本运算符
3.1 算术运算符
3.2 比较运算符
3.3 赋值运算符
3.4 逻辑运算符
四:掌握操作
一: 变量名
1.1:变量名的使用
先定义,后引用
定义阶段:
age=18
#定义过程由变量名,赋值符号,变量值组成。
| 变量定义过程的成分 | 作用 |
|---|---|
| 变量名 | 用来找值 |
| 赋值符号 | 将变量值的内存地址绑定给变量名 |
| 变量值 存储的数据, | 记录事物的状态 |
#整个变量定义过程是这样的:
先在内存中申请内存空间用来存放变量值,将内存空间的内存地址绑定给变量名。
引用阶段:
print(age)
》》18
1.2: 变量命名规范
给变量命名要做到“见名知意”
1.2.1:变量名由数字,字母和下划线组成。
1.2.2:不能由数字开头。:
1.2.3:不能出现python关键字。
例:错误示范
print=123
print(print)
关键字不能出现:
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from','global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
1.3:变量值的两大特征
1.3.1:查询类型:
age=18
salary=20.0
print(type(age),type(salary))
#加入type就是引入变量值的类型
》》》
1.3.2:查询id
id就是值在内存中的身份证号,反应的就是内存地址。
如果两个变量的id一样,说明它们位于相同的内存地址,
那么值一定相等。
继上:
print(id(age),id(salary))
》》140735206000832 2236839546224
ps:
is:判断id(内存地址)是否相等
==:判断内存地址是否相等
x=10
y=x
print(id(x),id(y))
print(x is y)
》》140735209932736 140735209932736
True
#在pycharm中,由于内置文件的优化,出现了小整数池的概念。即pycharm预先开辟了
一些内存空间存储常用的数字和字符串。当这些数字被调用时,直接给他们分配内存地址,提高
了程序运行的效率。 (有些数字判断出同一个id和同一个内存地址的原因是因为pycharm里面的小整池预留的原因,再运行时直接关联过去,弊端就是pycharm在启动是会慢些,但不影响使用,小整数是-5~256,True,False,None;超出即不同,python解释器里面也有同样的情况,若数字范围扩大不用在意。)
1.3.3:内存管理
内存管理主要涉及的是垃圾回收机制(gc)。
垃圾回收机制的核心原理是统计引用计数。通过统计引用计数,标记清除和分代回收机制来提高对内存的使用效率。
首先引入堆区和栈区的概念:
栈区存放的是变量名和内存地址的关系,可以简单理解为,变量名存内存地址。
堆区存放的是变量值。
强调:只站在变量名的角度去谈一件事情。
变量名的赋值(x=10)还有变量名的传参(print(x)),传递的都是内存中栈区的数据。而栈区的数据是对变量名和内存地址的对应关系。
python是引用传递。
同时应该避免循环引用(一般发生于容器类型数据类型相互应用)。

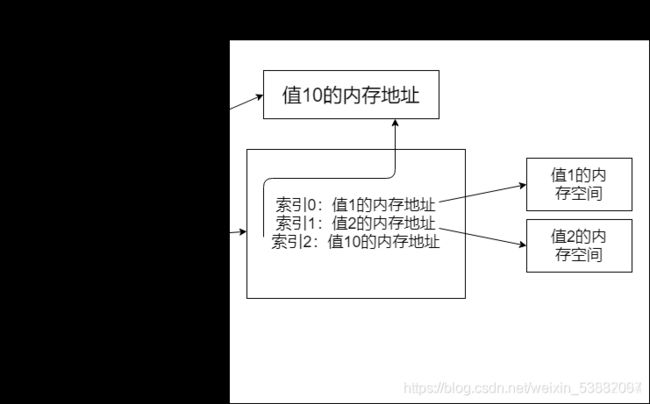
列表是如何存储的呢?
二:基本数字类型
2.1 整型 int:(不可分割,一个整体)
2.1.1:用途:整数,记录年龄,个数,号码,等级整数相关的
2.1.2:定义方式:
age=18 #age=int(18) int在后台自己做的工作
print(type(age))
>>><class 'int'>
2.1.3 int 数据类型操作:可以把数字组成的字符串转成整型。
例:
res = int("18")
print(res,type(res))
>>>18 <class 'int'> ##int是18的工厂函数
2.1.4 常用操作+内置方法
数学运算+比较运算
总结:只能存一个值,是不可变类型。
2.2 浮点型 float:(不可分割,一个整体)
2.2.1 用途:小数,记录薪资,身高,体重
2.2.2 定义方式:
salary = 3.1 #salary = float(3.1) ##float在背后做的事情
2.2.3 float 数据类型转换:可以把小数组成的字符串转成浮点型。
例:
res=float(111)
print(res,type(res))
>>>111.0 <class 'float'>
2.2.4 常用操作+内置方法
数学运算+比较运算
总结:只能存一个值,是不可变类型。
2.3 字符串 str:(不可分割,一个整体)
位于 " " ’ ’ 之间的字符,作用是描述性质的内容。
name='wth'
position="boss"
message = '''
wo
de
tian'''
导语:正是因为前面三种介绍的数据类型都是不可分割的数据类型,所以引入了可以收入多值的容器型
数据类型。当我们想一次性将很多数值存储起来的时候,数字类型和字符串类型已经很难满足。
2.4 列表 list:(*****)
2.4.1:用途:按照位置存放多个任意类型的值
2.4.2:定义方式:在[ ]内用逗号分开多个任意类型的值,这些值属于同一属性。
例:
l=[11,11.33,"xxx",[11,22,33]] #l=list(....)
print(type(l))
2.4.3 list数据类型转换:把可迭代的类型转换成列表,可以被for循环遍历的类型都是可迭代的
例:
res = list("hello")
print(res)
>>>['h', 'e', 'l', 'l', 'o']
res = list({
"k1":111,'k2':2222})
print(res)
>>>['k1', 'k2']
2.4.4 常用操作+内置方法
按索引存取值(正向取+反向取):即可存也可取
例:
l = [111,222,333]
print(id(l))
>>>1857958381952
例:
l = [111,222,333]
print(id(l))
l[0]=666 #改列表中的一个数据,id不变
print(id(l))
>>>2086374410496
2086374410496
总结:列表可存多个值,有序,是可变类型
2.4.5 l.remove 列表指定删除
例:
l=[111,222,333]
l.remove(222) #删哪个就把哪个放在扩号里
print(l)
2.4.6 l.pop 列表中索引指定删除
例:
l=[111,222,333]
l.pop(1) #删哪个就用索引
print(l)
>>>[111, 333]
(l.pop删除是相当于把框框里面的鸡蛋拿走,其他两种删除就是删除元素)
2.5: 字典 dict:(*****)
2.5.1 用途:按照 key :value的方式存放多个值,其中key对value应该有描述性的效果。
例:
#d={} #两个定义随意,都一样 #空字典也是字典
d=dict()
print(type(d))
>>> <class 'dict'>
2.5.2定义方式:位于 { } 之间的数值或者字符,存放不同属性的元素。每个元素由 key:value 组成。key必须是不可变类型, 通常是字符串类型,value可以是任何类型。key不能重复。
2.5.2 作用:按照 key :value的方式存放多个值,其中key对value应该有描述性的效果。
一个列表字典合用的案例:存放多个同学的信息。
students=[
{
'name': 'zhang','gender':'male','age':18},
{
'name': 'wang', 'gender': 'male', 'age': 18},
{
'name':' li', 'gender': 'female', 'age': 18},
{
'name': 'wei', 'gender': 'male', 'age': 18}]
print(students[1]['name'])
>> 'wang'
取数据的时候,描述为“取第二个学生的姓名”。通过描述也可以反推是如何建立数据的,列表嵌套字典。
例二:
stud={
'wth1': {
'age':18, 'phone': 188, 'sex': 'male'},
'wth2': {
'age':19,'phone': 186, 'sex': 'female'},
'wth3': {
'age':20,'phone': 205, 'sex': 'female'},
'wth4': {
'age':21,'phone': 238, 'sex': 'male'}}
print(stud['wth1']['phone']) #取第一个字典里第一个人的电话
>>188
取数据的时候,通过描述同样可以反推数据是如何建立的,字典嵌套字典。
2.5.3 数据类型转换
例:
res=dict([("name","egon"),["age",18],["gender","male"]])
print(res)
>>> {
'name': 'egon', 'age': 18, 'gender': 'male'}
还可以这么玩:快速初始化好一个列表
res = {
}.fromkeys(['name',"age","gender"],[])
res["name"]=666
>>> {
'name': 666, 'age': [], 'gender': []}
res = {
}.fromkeys(['name',"age","gender"],[])
res["name"].append(11111)
print(res)
>>> {
'name': [11111], 'age': [11111], 'gender': [11111]}
2.5.3 常用操作+内置方法
详见四
2.6 布尔值 bool:(不可分割,一个整体)
作用:布尔值并不是直接调用,而是应用于真假状态的应用。
x=True
y=False
print(x,y,type(x),type(y)) #加入type查询布尔值类型
ps:布尔值分为两类:
1:显示:能明确看到得到true,false
2:隐式:0,None,空白对应隐式布尔值为false,其余都是(所有的布尔值都可以成为隐式,)
例:
print(10 and 3 and 4 > 2)#为true
print (10 and 0 and 4 > 2) #满足上述出
现0为false
2.7 不可变类型
值改变,但是id不变,就是产生了新值,原值是不可变类型
例:
x=10
print(id(x))
x=11
print(id(x))
>>>140703835097024
140703835097056
2.8 可变类型
值改变,但是id不变,证明就是在改原值,原值就是可变类型
例:
l = [111,222,333]
print(id(l))
l[0]=66666
print(id(l))
>>>2376388053184
2376388053184
总结:只要能把中间的某一个元素换掉的都是可变类型,不能换中间某个元素,而只能把整体换掉的都是不可变类型。
2.9 元组tuple
2.9.1 用途:元组就相当于一种不可变的列表,所以说元组也是按照位值存放多个值的。
2.9.2 定义方式:在( )内用逗号分隔开个多个任意类型的元素
例:
t=(11,11.33,"xxx",[44,55])
print(type(t))
>>> <class 'tuple'>
注意:如果元组内只有一个元素,那么必须要用逗号分隔开
例:
t=(11,)
print(type(t)
2.9.3 常用操作+内置方法
跟列表相同
总结:存多个值,有序,不可以变
三:基本运算符
3.1 算术运算符
算术运算符包括的运算有
+,-,*,/,**,%,//
+,-,*,/,
算术运算符一般应用于数字类型(整型和浮点型)中,对数据进行操作。比如:
print(10+1)
print(10-1)
print(10*2)
print(10/3)
print(10**3)#10的3次方0
print(10%3)#取余数
print(10//3)#地板除,只保留整数部分
》》》11
》》》9
》》》20
》》》3.33333333334
》》》100041
》》》1
》》》3
在这里插入代码片
ps: + 和 * 也可以应用到字符串中,但由于是申请新的内存地址存储新生成的字符串,所以不经常使用字符串的 + 和 * 操作。
3.2 比较运算符
比较运算符包括的运算有
==,>,<,>=,<=,!=
只有当数值类型相同,值也相同的时候,才是True
m=10
n='10'
print(m==n)
》》》False
3.3 赋值运算符
3.3.1 链式赋值
当想同时对多个变量赋予相同的值时,使用这种赋值方法。
x=y=z=100
3.3.2 增量赋值
当记录变量递进的变化状态时,使用这种赋值方法。
x+=1
3.3.3 交叉赋值
当想要交换两个变量的值(可以是数字类型,可以是字符串类型、列表类型、字典类型)时,使用这种赋值方法。
x=123
y=456
x,y=y,x
print(x,y)
》》》‘456’ ‘123’
3.3.4 解压赋值
顾名思义,想要将一个容器类型数据结构打开解压出来里面的值时,使用这种数据类型。
l=[1,2,3,4,5,6]
a,b,c,d,e,f=l
print(a,b,c,d,e,f)
》》》1 2 3 4 5 6
可以一次取到容器数据类型中的每个值,也可以按照需求只取前几个,后面几个或者前面几个值和后面几个值。用*收集不想被解压赋值的值,绑定给__这个变量名(可以理解为带_这个是不想要的数据)。
只取前n个值:
x1,x2,*__=[1,2,3,4,5,6]
print(x1,x2,_)
》》》1 2 [3,4,5,6]
只取后面n个值:
*__,x3,x4=[1,2,3,4,5,6]
print(_,x3,x4)
》》》[1,2,3,4] 5 6
同时取前n个值和后m个值:
x1,*__,x4=[1,2,3,4,5,6]
print(x1,_,x4)
》》》1 [2,3,4,5] 6
#X1,X4只是代名词可以替换成其他,跟数字无关,
#列表可以取到对应位置的值,字典只能取得key的值。
3.4 逻辑运算符
3.4.1 not
将紧跟其后的条件取反。
3.4.2 and
连接左右两个条件,只有两个条件都为True的时候,整个逻辑式才为True。
3.4.3 or
连接左右两个条件,只要有一个条件为True,整个逻辑式就为True。
3>4 and 4>3 or not 1==3 and ‘x’ == ‘x’ or 3 >3
ps:
多个and 同时出现,从左到右判断,一旦某个条件为false,则无需再往右判断,可以立即判定最终结果为false,只有在所有条件都为true的情况下,最终条件结果才为false
多个or同时出现时,从左到右判断,一旦某个条件成立就返回True,两个条件同时为false时返回false
成员运算符;判断某一个字母是不是出现在列表里面。
3.5:身份运算符
is:用来比教的是id
is not : is比对完过后的值取反
总结:优先级()》not>and>or
四:掌握操作切片(顾头不顾尾,步长)
4.1:strip 保留中间
#脱掉外衣,单独剥离出来
例:
name='@egon**' #定义的变量值可举一反三
print(name.strip('@')) #想剥离什么就在strip后扩号内放什么
>> egon** #返回的值剥离@
对于指定需要输出的内容,我们可以使用一下切片的方式:
例:
msg="egon:123:3000" # 字符串整体有规律或很长
res=(msg[0:4]) #先通过赋值将原字符串按位置索引切片缩小范围
print(res[0]) #在按位置索引去除所需内容
>>>e
对于简短的字符串切片可用:
name=" alex"
print(name[4:5]) #顾头不顾尾 指定其中的几个数
》》 x
例:
name=" alex"
print(name[-3:]) #还可以从右边开始取值,-3:表示从右边开始数后面3个数取出来,没有-0
>>>lex
#上面两个位置索引取值中的“:” 放在后面就是从后面开始,放在前面就是从前面开始,“:”前面或后面没有填数字意思是从0开始,取其中几个或一个,若不写“:”就是指定单个位置。
总结:存多个值,无序,可变
4.2:lstrip 移除左边
#去除前面的空白字符 移除左边的空格 只去掉左边的
例:
name='@egon**' #定义的变量值可举一反三
print(name.lstrip('@')) #除去前面的@
>>> egon**
4.3:rstrip 去除末尾
#去除后面的空白字符 移除右边的空格 删除字符串末尾的指定字符
例:
name='@egon**' #定义的变量值可举一反三
print(name.rstrip('*')) #去除后面的*
>>> @egon
4.4:upper 把所有变大写
例:
msg = "aAbB"
print(msg.upper())
>>> AABB
4.5:lower 把所有变小写
例:
msg = "aAbB"
print(msg.lower())
>>> aabb
4.6:startswith 以…开头
例:
name='alex_SB'
print(name.endswith('SB')) #判断是否以给定的字符串开头
>>> True
4.7:endswith 以…结尾
例:
name='alex SB'
print(name.endswith('alex')) #判断是否以给定的字符串结尾
>>> False
4.8:format的三种玩法
format 字符串格式化
例:
msg="my name is %s my age is %s" %("egon",18)
print(msg) #将后面()里的内容传值到前面的占位符
>>> my name is egon my age is 18
##可见这种形式传值只能按照顺序一一对应传值
##%s从python诞生就有,但format后面才有,python2,python3都可以用,效率高于%S
msg = "my name is {x} my age is {y}".format(y=18,x="egon") #将后面()内的值传到前面的变量名,x,y,用{}
print(msg)
>>> my name is egon my age is 18
##format可以打乱顺序,但仍然可以指名道姓传值
res='{} {} {}'.format('egon',18,'male') #按顺序传值也可以
print(res)
>>> egon 18 male
res ='{1} {0} {1}'.format('egon',18,'male') #按指定位置顺序传值
>>> 18 egon 18
res ='{name} {age} {sex}'.format(age=18,sex='male',name='egon') #打乱顺序仍然可以传值
>>> egon 18 male
了解:
对比以上两种方法传值,还有个新语法“f”使用时将所需传的变量值用{},此方法效率更高,更简单!
name = "egon"
age = 18
print(f"my name is {name} my age is {age}")
4.9: split 分割 左到右
对有规律的字符串按某个分隔符切割成列表
4.9.1 默认从左往右
例:
name='root:x:0:0::/root:/bin/bash'
print(name.split(':')) #将:的进行分割
>>> ['root', 'x', '0', '0', '', '/root', '/bin/bash']
4.9.2 还可以指定切割几刀
例:
name='c:/a/b/c/d.txt'
print(name.split('/',1)) #指定以/为分割切一刀,拿到顶级目录
>>> ['c:', 'a/b/c/d.txt']
4.10:rsplit 切割 右到左
对有规律的字符串切割成列表
默认从右往左
例:
name='a|b|c'
print(name.rsplit('|',1)) #指定以|为分割从右边开始切一刀
>>> ['a|b', 'c']
4.11 join 重新拼接
把列表用某个链接符重新拼成字符串
例:
tag=''
print(tag.join(['egon','say','hello','world'])) #将列表重新拼成字符串
>>> egonsayhelloworld
4.12 replace 替换
例:
name='alex say :i have one tesla,my name is alex'
print(name.replace('alex','sb',1)) #1代表换一次,-1和不写几次都代表全部换
>>> sb say :i have one tesla,my name is alex
4.13 isdigit 判断字符是否为数字
可以判断bytes和unicode类型,是最常用的用于于判断字符是否为"数字"的方法
例:
age=input('>>>:')
print(age.isdigit())
>>>输入在返回布尔值判断
一般还可将此语法用在用户输入捣乱时,作为一个警告的作用。
例:
age=input('>>>:')
print(age.isdigit())
num = input(">>>:")
if num.isdigit():
num=int(num)
print(num>10)
else:
print("务必输入数字,小垃圾")
>>> : aa
务必输入数字,小垃圾
4.14 append 追加
例:
l=[111,222,333]
l.append(444)
print(l)
>>>[111, 222, 333, 444]
4.15 insert 插入
例:
l=[111,222,333]
l.insert(1,666) #1指的是位值
print(l)
4.16 del 万能删
例:
l=[111,222,333]
del l[0]
print(l)
五:了解操作(***)
字符串系列:
5.1 find 查找从左往右不报错
顾头不顾尾(开始位置包括在里面,结束位置不包括)
例:
name='egon say hello'
print(name.find('o',1)) #按位置索引查找,可指定位置,也可不指定,找不到也不报错,返回-1,若指定的位置不符,也不会报错,返回正确的所在位置,若字符串中有好几个,只报第一个。
>>> 2
5.2 rfind 查找从右向左不报错
顾头不顾尾
例:
name='egon say hello'
print(name.rfind('o'))
>>> 13
5.3 index
name='egon say hello'
print(name.index('e',2,4))
>>>报错
5.3 index 查找从左往右报错
找到即返回值,找不到报错
顾头不顾尾
例:
name='egon say hello'
print(name.index('e',1,4))
>>>0
有些时候需要找出其中一个内容的所在位置,但内容多的时候不方便一个个去数,那么也可以用到index
例:
name=" alex"
print(name.index('e'))
>>>3 #指示’e‘所在位置是第3位
5.4 rindex查找从右向左报错
找到即返回值,找不到报错
顾头不顾尾
例:
name='egon say hello'
print(name.rindex('e',1,4))
>>> 报错
5.5 count 计数
计算所在范围有几个指定需要的值个数
顾头不顾尾
例:
name='egon say hello'
print(name.count('e',1,11))
>>> 1
5.6 center 居中
例:
name='egon'
print(name.center(30,'-')) #将变量值居中打印,括号里设定两边内容
>>> -------------egon-------------
5.7: rjust 左边补齐
将字符串置于最右边 ,左边用( )里内容补齐
例:
name='egon'
print(name.rjust(30,'*'))
>>> **************************egon
5.8: ljust 右边补齐
将字符串置于最左边 ,右边用( )里内容补齐
例:
name='egon'
print(name.ljust(30,'*'))
>>>egon**************************
5.9: zfill 用0填充
例:
name='egon'
print(name.zfill(50))
>>>
0000000000000000000000000000000000000000000000egon
5.10: expandtabs 增加空格分隔
例:
name='egon\thello'
print(name)
print(name.expandtabs(1)) #指定1个
print(name.expandtabs(4)) #指定4个
print(name.expandtabs(6)) #指定6个
>>>
egon hello
egon hello
egon hello
egon hello
5.11:capitalize 首字母大写
例:
name='egon'
print(name.capitalize())
>>> Egon
5.12: swapcase 大小写翻转
例:
name='egon'
print(name.swapcase())
>>> EGON
5.13: title 每个单词的首字母大写
例:
msg='egon say hi'
print(msg.title())
>>> Egon Say Hi
is数字系列:
#is数字系列
#在python3中
num1=b'4' #bytes
num2=u'4' #unicode,python3中无需加u就是unicode
num3='四' #中文数字
num4='Ⅳ' #罗马数字
#isdigt:bytes,unicode #isdigt对应的是bytes,unicode
print(num1.isdigit()) #True
print(num2.isdigit()) #True
print(num3.isdigit()) #False
print(num4.isdigit()) #False
#isdecimal:uncicode
#bytes类型无isdecimal方法
print(num2.isdecimal()) #True
print(num3.isdecimal()) #False
print(num4.isdecimal()) #False
#isnumberic:unicode,中文数字,罗马数字
#bytes类型无isnumberic方法
print(num2.isnumeric()) #True
print(num3.isnumeric()) #True
print(num4.isnumeric()) #True
#三者不能判断浮点数
num5='4.3'
print(num5.isdigit())
print(num5.isdecimal())
print(num5.isnumeric())
'''
总结:
最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景
如果要判断中文数字或罗马数字,则需要用到isnumeric
'''
#is其他
print('===>')
name='egon123'
print(name.isalnum()) #字符串由字母或数字组成
print(name.isalpha()) #字符串只由字母组成
print(name.isidentifier())
print(name.islower())
print(name.isupper())
print(name.isspace())
print(name.istitle())
六: