【Selenium】Selenium自动化入门之八大元素定位
前文已经学会如何简单地使用webderiver了,这篇就交自动化测试入门必备元素定位的技巧
不管是web端使用Selenium还是app端使用Appium,只要是UI测试,就逃不掉元素定位这个技能
可以说如何定位元素,将定型一个测试人员的测试思维
本章将带大家如何用firebug插件来检查页面中的元素
此外还做了一份Chrome浏览器如何检查元素和IE浏览器如何检查元素的文档,需要的可以点击并输入暗号:CSDN获取
书接前文:【Selenium】selenium自动化入门之webdriver框架使用
appium教程:【appium】appium自动化入门之环境搭建(上)
目录
- 1.2 常用 8 种元素定位(Firebug 和 firepath)
-
- 前言
- 1.2.1 环境准备
- 1.2.2 查看页面元素:
- 1.2.3 find_element_by_id()
- 1.2.4 find_element_by_name()
- 1.2.5 find_element_by_class_name()
- 1.2.6 find_element_by_tag_name()
- 1.2.7 find_element_by_link_text()
- 1.2.8 find_element_by_partial_link_text()
- 1.2.9 find_element_by_xpath()
- 1.2.10 find_element_by_css_selector()
- 总结
- 1.3 xpath 定位
-
- 前言
- 1.3.1 xpath:属性定位
- 1.3.2 xpath:其它属性
- 1.3.4 xpath:层级
- 1.3.6 xpath:逻辑运算
- 1.3.7 xpath:模糊匹配
- 后话
1.2 常用 8 种元素定位(Firebug 和 firepath)
前言
元素定位在 firefox 上可以安装 Firebug 和 firepath 辅助工具进行元素定位。
1.2.1 环境准备
- 浏览器选择:Firefox
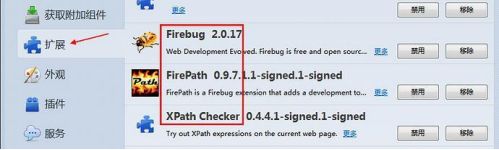
- 安装插件:Firebug 和 FirePath(设置>附加组件>搜索:输入插件名称>下载安装后重启浏览器)
- 安装完成后,页面右上角有个小爬虫图标
- 快速查看 xpath 插件:XPath Checker 这个可下载,也可以不用下载
- 插件安装完成后,点开附加组件>扩展,如下图所示
1.2.2 查看页面元素:
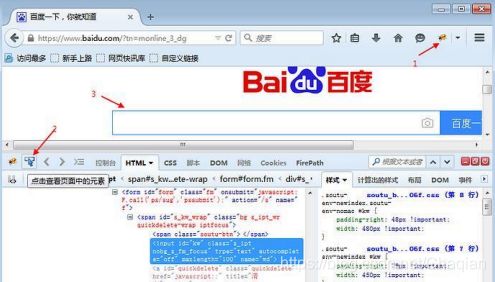
以百度搜索框为例,先打开百度网页
- 点右上角爬虫按钮
- 点左下角箭头
- 讲箭头移动到百度搜索输入框上,输入框高亮状态
- 下方红色区域就是单位到输入框的属性:
1.2.3 find_element_by_id()
- 从上面定位到的元素属性中,可以看到有个 id 属性:“kw”,这里可以通过它的 id 属性单位到这个元素。
- 定位到搜索框后,用 send_keys()方法, 输入文本
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# 通过id定位百度搜索框,并输入“测试”
driver.find_element_by_id("kw").send_keys("测试")
1.2.4 find_element_by_name()
- 从上面定位到的元素属性中,可以看到有个 name 属性:name=“wd”,这里可以通过它的 name 属性单位到这个元素。
- 提前说明:这里运行后会报错,因为这个搜索框的 name 属性不是唯一的,是无法通过 name 属性直接定位到输入框
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# 通过name定位百度搜索框,并输入“测试”
driver.find_element_by_name("wd").send_keys("测试")
1.2.5 find_element_by_class_name()
- 从上面定位到的元素属性中,可以看到有个 class 属性:class=“s_ipt”,这里可以通过它的 class 属性单位到这个元素。
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# 通过class定位百度搜索框,并输入“测试”
driver.find_element_by_class_name("s_ipt").send_keys("测试")
1.2.6 find_element_by_tag_name()
1.从上面定位到的元素属性中,可以看到每个元素都有 tag(标签)属性,如搜索框的标签属性,就是最前面的 input
2.很明显,在baidu这样一个页面中,相同的标签有很多,所以一般不用标签来定位。以下例子,仅供参考
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# 通过tag定位百度搜索框,并输入“测试”
driver.find_element_by_tag_name("s_ipt").send_keys("测试")
1.2.7 find_element_by_link_text()
-
定位百度页面上"hao123"这个按钮
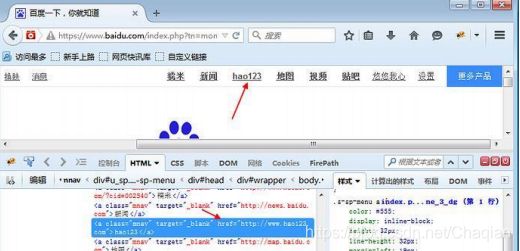
查看页面元素:
hao12
3 -
从元素属性可以分析出,有个 href = "http://www.hao123.com
说明它是个超链接,对于这种元素,可以用以下方法
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# 通过link属性定位到(hao123)按钮,并点击按钮
driver.find_element_by_link("hao123").click()
1.2.8 find_element_by_partial_link_text()
- 有时候一个超链接它的字符串可能比较长,如果输入全称的话,会显示很长,这时候可以用一模糊匹配方式,截取其中一部分字符串就可以了
- 如“hao123”,只需输入“ao123”也可以定位到
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# partial_link是一种模糊匹配的方式,对于超长字符串截取其中一部分
driver.find_element_partial_link_text("hao123").click()
1.2.9 find_element_by_xpath()
- 以上定位方式都是通过元素的某个属性来定位的,如果一个元素它既没有 id、name、class 属性也不是超链接,这么办呢?或者说它的属性很多重复的。这个时候就可以用 xpath 解决
- xpath 是一种路径语言,跟上面的定位原理不太一样,首先第一步要先学会用工具查看一个元素的 xpath
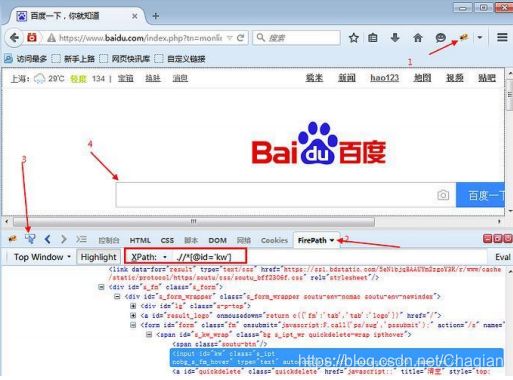 3.按照上图的步骤,在 FirePath 插件里 copy 对应的 xpath 地址
3.按照上图的步骤,在 FirePath 插件里 copy 对应的 xpath 地址
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# 在firePath里copy处xpath地址
driver.find_element_by_xpath(".//*[@id='kw']").send_keys("测试")
1.2.10 find_element_by_css_selector()
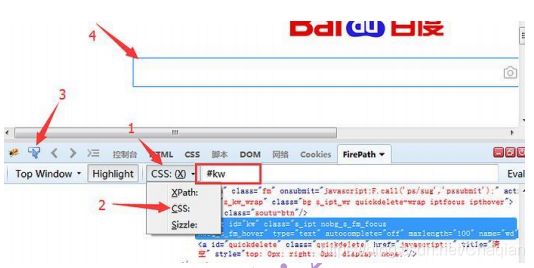
- css 是另外一种语法,比 xpath 更为简洁,但是不太好理解。这里先学会如何
用工具查看,后续的教程再深入讲解 - 打开 FirePath 插件选择 css
- 定位到后如下图红色区域显示
总结
selenium 的 webdriver 提供了 18 种(注意是 18 种,8种定位,8种复数定位还有两种参数化定位)
的元素定位方法
这里主要掌握xpath和css定位,这两种定位非常的更加灵活,足以应对大部分公司的业务需求了
接下来就着重讲这两种定位方式的使用
1.3 xpath 定位
前言
在上面简单的介绍了用工具查看目标元素的 xpath 地址,工具查看比较死板,不够灵活,有时候直接复制粘贴会定位不到。这个时候就需要自己手动的去写xpath 了,这一篇详细讲解 xpath 的一些语法。
那么什么是 xpath 呢?
官方介绍:XPath 即为 XML 路径语言,它是一种用来确定 XML 文档中某部分位置的语言。
反正小编看这个介绍是云里雾里的,通俗一点讲就是通过元素的路径来查找到这个元素的,相当于通过定位一个对象的坐标,来找到这个对象。
1.3.1 xpath:属性定位
- xptah 也可以通过元素的 id、name、class 这些属性定位,如下图
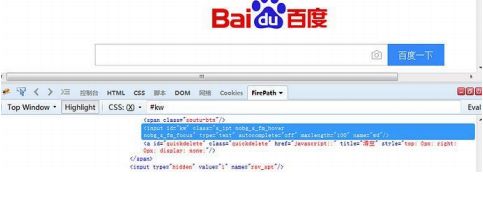
- 于是可以用以下 xpath 方法定位
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# 用xpath通过id属性定位
driver.find_element_by_xpath("//*[@id='kw']").send_keys("测试")
# 用xpath通过name属性定位
driver.find_element_by_xpath("//*[@name='wd']").send_keys("测试")
# 用xpath通过class属性定位
driver.find_element_by_xpath("//*[@class='s_ipt']").send_keys("测试")
1.3.2 xpath:其它属性
实际业务操作中,没有id、name、class 这些元素属性都是挺正常的,这时候也可以通过其它属性定位的
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# 用xpath通过其他属性定位
driver.find_element_by_xpath("//*[@autocomplete='off']").send_keys("测试")
1.3.3 xpath:标签
- 有时候同一个属性,同名的比较多,这时候可以通过标签筛选下,定位更准一点
- 如果不想制定标签名称,可以用*号表示任意标签
- 如果想制定具体某个标签,就可以直接写标签名称
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# 用xpath通过其他属性定位
driver.find_element_by_xpath("//*input[@autocomplete='off']").send_keys("测试")
# 用xpath通过id属性定位
driver.find_element_by_xpath("//*input[@id='kw']").send_keys("测试")
# 用xpath通过name属性定位
driver.find_element_by_xpath("//*input[@name='wd']").send_keys("测试")
1.3.4 xpath:层级
- 如果一个元素,它的属性不是很明显,无法直接定位到,这时候我们可以先找它的父元素
- 找到父元素后,再找下个层级就能定位到了
- 如果父元素的属性也不是很明显,那么就找父元素的父元素,直到找到最外层的标签,这就是层级定位元素
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# 通过定位父元素来定位input输入框
driver.find_element_by_xpath("//span[@id='s_kw_wrap']/input").send_keys("测试")
# 通过定位父元素的父元素来定位input输入框
driver.find_element_by_xpath("//span[@id='form']/span/input").send_keys("测试")
-
如果一个元素它的兄弟元素跟它的标签一样,这时候无法通过层级定位到。
-
虽然其中一个元素很难识别,但是时间是有先后的,于是可以通过它生成的时间定位到
-
如下图三个元素
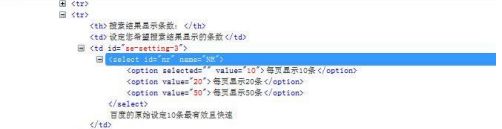
-
用 xpath 定位索引,是从 1 开始算起的,跟 Python 的索引不一样
# 用xpath定位第一个
driver.find_element_by_xpath("//span[@id='nr']/option[1]").click()
# 用xpath定位第二个
driver.find_element_by_xpath("//span[@id='nr']/option[2]").click()
1.3.6 xpath:逻辑运算
- xpath 还有一个比较强的功能,是可以多个属性逻辑运算的,可以支持与(and)、或(or)、非(not)
- 一般用的比较多的是 and 运算,同时满足两个属性
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# xpath逻辑运算
driver.find_element_by_xpath("//*[@id='kw' and @autocomplete='off']")
1.3.7 xpath:模糊匹配
- xpath 还有一个非常强大的功能,模糊匹配
- 掌握了模糊匹配功能,基本上没有到位不到的
- 比如我要定位百度页面的超链接“hao123”,在上一篇中讲过可以通过by_link,也可以通过 by_partial_link,模糊匹配定位到。当然 xpath 也可以有同样的功能,并且更为强大
# coding:utf-8
from selenium import webderiver
driver = webderiver.Firefox()
driver.get("https://www.baidu.com")
# xpath模糊匹配功能
driver.find_element_by_xpath("//*[contains(text(),'hao123')]").click()
# xpath模糊匹配某个属性
driver.find_element_by_xpath("//*[contains(@id,'kw')]").click()
# xpath模糊匹配以什么开头
driver.find_element_by_xpath("//*[starts-with(@id,'s_kw_')]").click()
# xpath模糊匹配以什么结尾
driver.find_element_by_xpath("//*[ends-with(@id,'kw_wrap')]").click()
# xpath以正则表达式定位
driver.find_element_by_xpath("//*[matchs(test(),'hao13')]").click()
后话
模糊定位是真的强,可以说模糊定位能够定位一半的元素,剩下的一半就可以交给Css定位去定位到
下一篇更新css,今日周末,应该可以一起更新出来
另外再提一嘴,这边是有视频教程的,需要的可以点击并输入暗号:CSDN或者有什么不懂的,想版本不兼容,奇奇怪怪的bug也可进来交流提出
