论文笔记+源码 DETR:End-to-End Object Detection with Transformers
〇、本论文需要有的基础知识
- 目标检测:了解传统目标检测的基本技术路线(如anchor-based、非最极大值抑制、one-stage、two-stage),大致了解近两年的SOTA方法(如Faster-RCNN)
- Transformer:了解Transformer的机制,知道self-attention机制
- 二分图匹配:了解图论中的二分图匹配,知道匈牙利算法
一、 摘要核心点
1. 相比传统路线:去掉了很多手工设计模块(hand-designed):如非极大值抑制、anchor的设计
这些手工设计的模块里均为人为对task先验知识的一定程度上的“先验的编码(encode)”
2. DETR核心内容:
a set-based global loss → forces unique predictions via:
(a) bipartite matching, and
(b) a transformer encoder-decoder architecture.(本文用的Transformer网络是non-autoregressive非自回归的)
关于非自回归的介绍可以参考https://zhuanlan.zhihu.com/p/82892975
3. DETR能做到的事:
· 输入: a fixed small set of learned objects queries
· DETR输出:
(a) the relations of the objects
(b) the global image context to directly output the final set of prediction in parallel
4. 流程架构示意图:
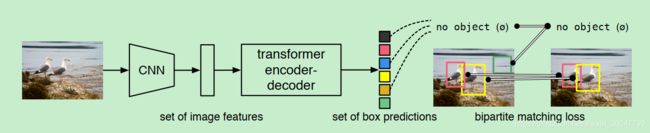
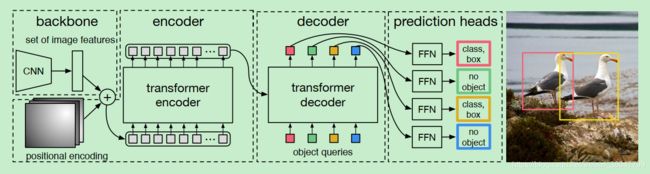
更细节一些的流程架构示意图↓:
二、 正文
1. 首先定性object detection问题为set of prediction
2. 整个网络设计是端到端(end-to-end)的,然后用一个“集合”损失函数(set loss function)来训练,这个损失函数描述预测框和ground-truth框之间的二分图匹配( performs bipartite matching between predicted and ground-truth objects)来训练
3. DETR仅仅是架构上的创新,并没有创新独有的层(就好像resnet创新了跳连,DETR没有在layer这个层面进行创新)
4. DETR用的“匹配”损失函数(matching loss function)将预测框“一一分配”给ground-truth框(uniquely assigns a prediction to a ground truth object,这里的“一一分配”正是bipartite matching的本身含义);而且能保证对预测对象的排列顺序保持不变(这也是用二分图匹配建模的原因,这里特指无向二分图)(uniquely assigns a prediction to a ground truth object)→这是能够并行化预测的一个原因
“matching”这里是图论里的概念,可以参考https://www.renfei.org/blog/bipartite-matching.html
5. 对于建模为“Set Prediction”(“集合”预测)的考虑:
通常“集合”预测任务是一种多标签分类问题。多标签分类问题的解决方法通常是“one-vs-rest”(“一对多”,one-vs-rest,又称one-vs-all, 这里指的是将label的类别作为“一”,将其余类别当做一个整体作为“多”,进行训练),这种方法不适用于“元素”间有底层关系结构的情况(“元素”e.g.几乎一模一样的预测框)(does not apply to problems such as detection where there is an underlying structure between elements (i.e., near-identical boxes)。这个方法会导致大量几乎一样的结果的情况(near-duplicates),传统的目标检测方法会用后处理(如非极大值抑制)来解决这个问题(成堆的近乎一样的预测结果),但是如果是建模为set prediction就不用这些后处理。set prediction需要在全局上有个策略来对这些“元素”之间的关系建模,来避免预测过多的无用、复制的结果造成冗余。
6. 对于采用“Bipartite Matching”(二分图匹配)作为“预测值→ground-truth值”的损失函数的考虑:
在Set Prediction问题中,损失函数必须满足“预测顺序不变性”(invariant by a permutation of the predictions,即预测值/框的顺序不能影响损失值),而二分图匹配——这里特指的是“无向”二分图匹配将“预测值→ground-truth值”的关系建模为了一个无向二分图,这种图的“匹配”不存在顺序问题。特别地,用“匈牙利算法”来求解二分图匹配问题。
· “Bipartite Matching”(二分图匹配)(1)能保证预测顺序不变性”; (2)能保证两者间的“一一匹配”
7. 对于大物体的预测更准确:
文章中说“a result likely enabled by the non-local computations of the transformer”,这里的“non-local computations”指的是Non-local Neural Networks(https://arxiv.org/pdf/1711.07971.pdf)这篇文章中的Non-local概念。
non-local computations指的是计算“非局部”感受野上的信息,可以参考https://zhuanlan.zhihu.com/p/33345791
三、结果
四、源码讨论
为了防止后面代码项目有改动,我摘出来写本文时候(2020.06.18)的最新的一次提交(1fcfc65)来做部分源码说明
(1)DETR网络结构一览:
class DETR(nn.Module):
""" This is the DETR module that performs object detection """
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):
""" Initializes the model.
Parameters:
backbone: torch module of the backbone to be used. See backbone.py
transformer: torch module of the transformer architecture. See transformer.py
num_classes: number of object classes
num_queries: number of object queries, ie detection slot. This is the maximal number of objects
DETR can detect in a single image. For COCO, we recommend 100 queries.
aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used.
"""
super().__init__()
self.num_queries = num_queries
self.transformer = transformer
hidden_dim = transformer.d_model
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
self.query_embed = nn.Embedding(num_queries, hidden_dim)
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
self.backbone = backbone
self.aux_loss = aux_loss
def forward(self, samples: NestedTensor):
""" The forward expects a NestedTensor, which consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
It returns a dict with the following elements:
- "pred_logits": the classification logits (including no-object) for all queries.
Shape= [batch_size x num_queries x (num_classes + 1)]
- "pred_boxes": The normalized boxes coordinates for all queries, represented as
(center_x, center_y, height, width). These values are normalized in [0, 1],
relative to the size of each individual image (disregarding possible padding).
See PostProcess for information on how to retrieve the unnormalized bounding box.
- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list of
dictionnaries containing the two above keys for each decoder layer.
"""
if not isinstance(samples, NestedTensor):
samples = nested_tensor_from_tensor_list(samples)
features, pos = self.backbone(samples) # backbone是一个CNN用于特征提取
src, mask = features[-1].decompose() #??
assert mask is not None
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0] # 这里是吧features的其中一部分信息作为src传进Transformer,input_proj是一个卷积层,用来收缩输入的维度,把维度控制到d_model的尺寸(model dimension)
outputs_class = self.class_embed(hs) # 为了把Transformer应用于目标检测问题上,作者引入了“类别嵌入网络”和“框嵌入网络”
outputs_coord = self.bbox_embed(hs).sigmoid() # 在框嵌入后加入一层sigmoid输出框坐标(原论文中提到是四点坐标,但是要考虑到原图片的尺寸)
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out
@torch.jit.unused
def _set_aux_loss(self, outputs_class, outputs_coord):
# this is a workaround to make torchscript happy, as torchscript
# doesn't support dictionary with non-homogeneous values, such
# as a dict having both a Tensor and a list.
return [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]可以看到 DETR的主体框架是:

(2)Backbone的源码如下:
BackboneBase:
class BackboneBase(nn.Module):
def __init__(self, backbone: nn.Module, train_backbone: bool, num_channels: int, return_interm_layers: bool):
super().__init__()
for name, parameter in backbone.named_parameters():
if not train_backbone or 'layer2' not in name and 'layer3' not in name and 'layer4' not in name:
parameter.requires_grad_(False)
if return_interm_layers:
return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"}
else:
return_layers = {'layer4': "0"}
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
self.num_channels = num_channels
def forward(self, tensor_list: NestedTensor):
xs = self.body(tensor_list.tensors)
out: Dict[str, NestedTensor] = {}
for name, x in xs.items():
m = tensor_list.mask
assert m is not None
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
out[name] = NestedTensor(x, mask)
return outBackbone:
class Backbone(BackboneBase):
"""ResNet backbone with frozen BatchNorm."""
def __init__(self, name: str,
train_backbone: bool,
return_interm_layers: bool,
dilation: bool):
backbone = getattr(torchvision.models, name)(
replace_stride_with_dilation=[False, False, dilation],
pretrained=is_main_process(), norm_layer=FrozenBatchNorm2d)
num_channels = 512 if name in ('resnet18', 'resnet34') else 2048
super().__init__(backbone, train_backbone, num_channels, return_interm_layers)Backbone其实是resnet的改编版,(1)一个是用了FrozenBatchNorm2d,冻结了部分参数,实际上这不是DETR的首创,作者的同事(也是facebook)开源的maskrcnn-benchmark中就用到过这个FrozenBatchNorm2d
(2)把resnet作为backbone套到了另一个子网络里,这个子网络主要是把送进去tensor list送进resnet网络,然后逐个提取出来其中的节点(也就是里面的Tensor),把每个节点的“mask”提出来做一次采样,然后再打包进自定义的“NestedTensor”中,按照“名称”:Tensor的方式存入输出的out。(这个NestedTensor一个Tensor里打包存了两个变量:x和mask)
TBC.(没写完的部分最近会补上,毕竟我也是边看边学然后记下来的……)