小白机器学习实用笔记
小白机器学习实用笔记
- 一.什么是机器学习
-
- 机器学习项目流程
- 特征工程三大步骤:特征抽取、预处理、降维
- 数据类型
- 数据集
- 监督学习与无监督学习
- 二.用sklearn对特征进行提取(特征抽取)
-
- 1: 字典的文字特征提取
- 2:count方式提取文字特征
- 3:tf-idf对文字特征提取
打算利用空余时间学习python机器学习,通过写文章的方式来记录学习成果。持续更新中。。。。。
一.什么是机器学习
机器学习是一种数据科学技术,它帮助计算机从现有数据中学习,从而预测未来的行为、结果和趋势
机器学习项目流程
1.根据原始数据明确问题,该做什么
2.特征工程
3找到合适算法,进行训练预测
4模型的评估,判定效果
特征工程三大步骤:特征抽取、预处理、降维
1.特征抽取:将文字、图像等转化为数字
2.预处理:将数字转化为格式统一、符合规范的数值,并且减少特殊值
3.降维:进行数据的筛选,取出最有代表性的数据特征
数据类型
· 散 型 数 据 : 由 记 录 不 同 类 别 个 体 的 数 目 所 得 到 的 数 据 , 又 称 计 数 数 据 , 所 有 这 些 数 据 全 部 都 是 整 数 , 而 且 不 能 再 细 分 , 也 不 能 进 一 步 提 高 他 们 的 精 确 度 。
· 连 续 型 数 据 : 变 量 可 以 在 某 个 范 围 内 取 任 一 数 , 即 变 量 的 取 值 可 以 是 连 续 的 , 如 , 长 度 、 时 间 、 质 量 值 等 , 这 类 整 数 通 常 是 非 整 数 , 含 有 小 数 部 分 。
数据集
数据集的组成为 特征值+目标值
特征值就是已有数据,目标值就是要预测(分类)的目标
监督学习与无监督学习

监督学习:有目标值+特征值(特征值为已有数据,目标值为预测数据)
无监督学习:没有目标值,只有特征值
分类:目标值为离散型,分类最基本是二分类。
回归:目标值为连续性
二.用sklearn对特征进行提取(特征抽取)
scikit-learn 是基于 Python 语言的机器学习工具
简单高效的数据挖掘和数据分析工具
1: 字典的文字特征提取
- 调用:from sklearn.feature_extraction import DictVectorizer
- 作用:能够对字典进行特征的提取

- 代码实现
dic=DictVectorizer()
data=dic.fit_transform([{
'city':'北京','temperature':100},{
'city':'上海','temperature':60},{
'city':'深圳','temperature':30}])
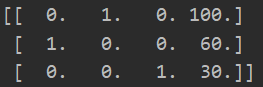
print(data)
输出: 
这是one-hot方式编码的sparse矩阵,有节约内存的优点
可以通过调整参数sparse=False来输出数组
2:count方式提取文字特征
- 调用:from sklearn.feature_extraction.text import CountVectorizer
- 作用:对句子或者段落进 行特征提取,能够对目标的词语出现次数记录,作为句子的特点
注意:
1.英文不需要分段,因为每个单词之间有空格
2.中文要用jieba库,将汉字进行分段,对每个词语都会进行空格分割,否则无法识别哪个为一组词(英文没有这个问题)
3.Jieba.cut()即可返回的是元祖,需要用list()转为列表,再.join为字符串 - 代码实现(英文):
cv=CountVectorizer()
data=cv.fit_transform(["life is short,i like python ","life is too long,i dislike python"])
print(cv.get_feature_names())#获取特征名
print(data.toarray())#没有sparse=False设置,所以需要用toarray方式输出数组
- 输出:

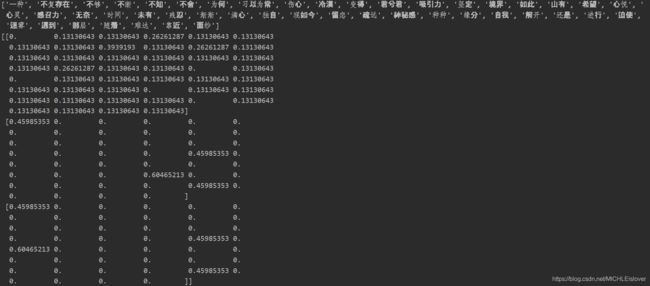
在上列的输出中,代表着下列特征值0,1对应的特征名,每一组数据有该特征,对应1,没有该特征,对应0 - 代码实现(中文):
atext= jieba.cut ( "山有木兮未有枝,心悦君兮君不知,有种种吸引力、感召力,神秘感迫使心灵不断地靠近,随着迷雾的不断解开,那层面纱不复存在,变得习以为常,渐渐地进行疏远,为何如此伤心?是自我不够坚定还是心灵难达境界,让我独自伤心,满心的希望、不舍与留恋,现如今变得冷漠、伤心、无奈" )
btext= jieba.cut ('在对的时间遇到对的人,是一种缘分')
ctext= jieba.cut("在错的时间遇到错的人,是一种残忍")
#转换为列表Jieba.cut()只可返回的是元祖,需要用list()转为列表,再.join为字符串
aa=list(atext)
bb=list(btext)
cc=list(ctext)
#用空格将他们再变连为字符串
t1 = ' '.join ( aa )
t2 = ' '.join ( bb )
t3 = ' '.join ( cc )#t3:在 错 的 时间 遇到 错 的 人 , 是 一种 残忍
cv = CountVectorizer ()
data = cv.fit_transform ( [t1,t2,t3] )
print ( cv.get_feature_names () )
print ( data.toarray () )
- 输出:

3:tf-idf对文字特征提取
对于文本特征识别,什么词出现在其他文章中越少,越有代表性
TF-IDF的主要思想是:如果某个词或者短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或者短语更具有更好的类别区分能力,适合用来分类
- tf *idf便是该词语的重要性,是特征提取的方式
- Tf:term frequency:词的频率
- Idf:逆文档频率 ,由log(总文档数量/该词出现的文档数量)得出
这样能够有效的剔除像‘明天’,‘所以’这样的词,因为他们经常在文档中出现,让其不影响结果的判断
- 调用:from sklearn.feature_extraction.text import TfidfVectorizer

- 代码实现:
atext = jieba.cut (
"山有木兮未有枝,心悦君兮君不知,有种种吸引力、感召力,神秘感迫使心灵不断地靠近,随着迷雾的不断解开,那层面纱不复存在,变得习以为常,渐渐地进行疏远,为何如此伤心?是自我不够坚定还是心灵难达境界,让我独自伤心,满心的希望、不舍与留恋,现如今变得冷漠、伤心、无奈" )
btext = jieba.cut ( '在对的时间遇到对的人,是一种缘分' )
ctext = jieba.cut ( "在错的时间遇到错的人,是一种残忍" )
# 转换为列表
aa = list ( atext )
bb = list ( btext )
cc = list ( ctext )
t1 = ' '.join ( aa )
t2 = ' '.join ( bb )
t3 = ' '.join ( cc )
tf = TfidfVectorizer()
data = tf.fit_transform ( [t1 , t2 , t3] )
print ( tf.get_feature_names () )
print ( data.toarray () )
- 输出: