“免疫杀手” Deep X-RAY

对于人体来说,免疫系统是抵抗病毒的“安全防线”。而对于企业来说,WAF(Web Application Firewal,简称WAF)就好比企业安全的免疫系统,它是网络安全边界上的第一道防线,帮助企业抵御病毒入侵。
近日,腾讯朱雀实验室发现了一种全新的攻击技术,能够借助机器学习,以黑盒方式探测出WAF后端规则,从而实现完美规避。对于企业来说,这无疑是个“免疫杀手”。新技术的出现,必然会带来新的影响。唯有不断探索安全的边界,提前发现风险,才能促进行业安全水平提升。
朱雀实验室是TEG安全平台部下设的安全实验室,专注于实战攻防和AI安全研究,通过发掘腾讯业务和前沿技术的安全风险,以攻促防,守护腾讯安全。
一、网络边界的免疫系统“WAF”
2019年底出现的新冠病毒“COVID-19”,以迅雷不及掩耳之势在全球肆虐。在疫苗出现之前,抵抗病毒靠的是自身免疫力,它是人体的一道“防火墙”,抵抗各种病毒细菌的入侵。

WAF(Web Application Firewal,简称WAF)就好比企业安全的免疫系统,它是网络安全边界上的第一道防线,被广泛的应用在了电子商务、企业门户、博客论坛等诸多类型的站点中。类似于人体免疫力抵御病毒的入侵,WAF免疫系统抵挡外部黑客入侵、攻击、渗透,从而防止商业机密被盗取、用户数据被泄漏等安全事件的发生。通常WAF系统基于多条规则(我们称之为正则表达式)来拦截外部攻击的,这就好比免疫系统中的白细胞杀死侵入人体的病毒细菌。WAF系统中的规则就好比人体的白细胞,而病毒和细菌便是常见的网络攻击,例如sql注入攻击。

二、探测防御系统的X光
当人体免疫系统出问题时,病毒细菌便会趁虚而入,造成疾病的产生。而对于WAF系统也是同样的道理,当黑客掌握了WAF规则的漏洞的时候,便可绕过防御系统继续攻击,危害企业安全。那么如何逆向出规则呢?
我们首先看看安全专家是如何做的,这里以ModSecurity中的一条防护规则为例,updatexml对于做渗透的同学都很熟悉,它常用在报错注入当中用来获取数据。

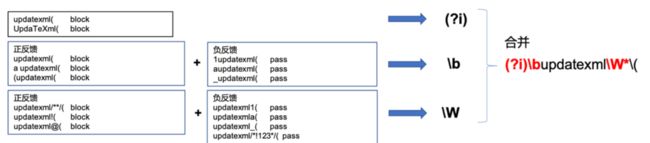
防护规则:(?i)\bupdatexml\W*\(
分解这条规则,如上图所示,有两个比较重要的部分,边界匹配\b和NonWord匹配\W,我们再来看下边的图表,以\W为例,它代表非字符集,也就是数字、大小写字母、下划线之外的字符。这里我们可以通过输入不同字符得到的反馈来推测出正则单元,例如输入a1_得到pass反馈,输入特殊字符等等得到block反馈,进而通过集合运算知道这里是一个\W规则。

这里以一个例子说明如何得到完整的规则的。当人工看到一条被拦截的payload的时候,首先关注的肯定是某个关键字,例如这里的updatexml,基于关键字我们通过不断增加、减少、修改字符来测试规则得到反馈,目的是找出一个临界点,此时修改或是减少任意一个字符都不在匹配规则,达到了最小匹配,也就是所谓的种子payload:updatexml(。
 mark
mark
基于种子payload,在关键字的边界构造不同的字符来探测出正则单元,例如判断大小写是否敏感,以及使用a1_等word字符匹配关键字边界得到反馈来判断边界匹配\b,通过在边界添加a1_等word字符推测正则单元\W,最终我们合并得到完整规则:(?i)\bupdatexml**\W***\(
总结一下,人工探测工作概括为这四点:
推测最小匹配单元(种子payload)
基于种子payload探测正则单元
合并正则单元得到完整规则
测试规则准确性。
思考整个人工探测的过程,我们发现有很多不足之处,一方面依赖测试人员的水平,经验不足的人未必能够完成,另一方面存在大量的重复劳动,而且每个人的经验也是有限的,很难覆盖到全部攻击方法,如何实现自动化是一个迫切需要解决的问题。
三、Deep X-RAY窃取你的防护策略
考虑到机器学习强大的学习能力,当提供足够量的数据时,算法完全可以学习到这种经验,将安全专家的安全经验通过数据驱动的方式沉淀起来,从而自动化的批量规则逆向。

数据驱动的核心任务是使用模型学习数据中包含的规律,因此首要的工作是收集payload数据,payload可看作是一段文本,通常词向量模型预训练,生成每个单词的分布式表示,然后在这些payload中使用注意力机制抽取出种子payload,对种子payload的每个位置通过推荐模型推荐出可能的探测单词,根据正负反馈反推出该位置的正则单元,经过重复次数探测后处理后得出该种子payload对应的防护策略。
3.1 数据采集
数据决定了效果的上限,而模型只是逼近这个上限。因此,高质量、覆盖广的攻击payload,是本项目的一个关键,这里我们选择了ModSecurity开源WAF作为payload产生器。
具体来说,在ModSecurity开源的规则集中,利用遍历算法将复杂的正则表达式自动化拆解为单一规则。例如:({'REQUEST_HEADERS'}, '^(?:ht|f)tps?://(.*?)\\/')拆解为http://(.*?)\\/、https://(.*?)\\/等多个独立规则,然后对规则进行分词,对缩略形式的规则单元替换成对应的字符,如'\d'替换成0,'\w'替换成a, '.*'替换成a,最终形成诸如http://a/、https://a/、ftp://a/等形式的攻击payload。
在Python正则表达式库中,可以对原始正则表达式解析,遍历这棵树就能产生很多条被命中的payload,如果修改其中的一部分,会产生不命中的payload,这样就获得了原始正负样本数据。
\bupdatexml\W*\('解析树
3.2 预训练词向量
既然有了数据,那么AI算法可以做哪些事呢?我们首先想到的是将payload中的安全经验沉淀下来,即单词之间是怎么搭配的,哪些单词意思又是相近的,这实际上是一个自动化提取Payload的文本特征的过程。
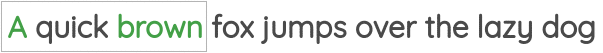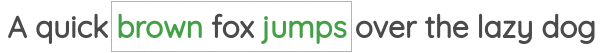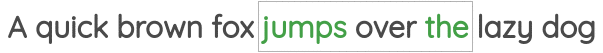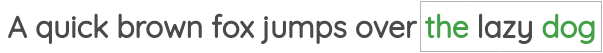
在机器学习中,有一类预训练算法,通过自监督的方式去学习特征。在这里,我们应用一种称为词向量的技术提取特征。举个例子,如上图所示,划定一个固定大小的窗口,通过黑色的中间词预测他的邻居,也就是绿色的单词,就可以获得每个单词的特征表示。在具体实现中,使用一个单隐藏层的浅层网络来完成,这里获得的词向量特征,会应用在后续AI模型任务中。
3.3 种子payload生成
根据前面人工推断的流程,要解决的第一个问题就是如何从原始payload中产生种子payload,以适应不同WAF产品下的检测规则变化问题。如下图所示,这条payload中实际上包含了多个攻击部分,如果不加处理直接进行探测,会难以确定真正起作用的部分。因此,我们需要使用控制变量法,将其中所有的攻击子序列提取出来。

这里我们应用深度学习中的注意力机制来解决关键词定位问题。什么是注意力机制呢?我们用一个生活中的例子来讲解。当你和你的朋友在酒吧聊天时,尽管环境很嘈杂,但你仍然可以听清楚他说的每一句话,因为你把环境中无关紧要的背景都忽略了,只关注对话内容,但是,如果服务员突然喊你的名字,你立刻就会有所反应。这个例子说明,注意力就是一种加权机制,能够动态的调节关注点,对结果有影响的内容会被重点突出来。
注意力机制的核心思想是从关注全局到关注局部,关注那些对最终结果起作用的局部特征,因此通过注意力机制,我们可以得出每个单词对最终结果的重要性排序。

回到我们的场景中,这里的注意力机制就是计算每个单词对block和pass这两种标签的重要性的反馈,进而缩小搜索空间和尝试次数。具体到实现上,就是对输入的payload提取特征后后,给每个单词一个权值,这个权值在训练分类模型的过程中不断优化,最终在预测过程中,只需取出payload中对应的权值,进行排序即可。
3.4 探测单词推荐
有了种子payload后,探测过程也能自动化吗?考虑到人工探测过程是基于专家经验的,在updatexml和(之间,专家会认为可能会优先检测特殊符号,这种经验从算法的角度来看是可以自动化建模的:首先依据经验抽取候选探测集,根据探测结果修正预期,让模型记住该环境下的习惯性搭配,然后把它应用在新payload探测过程中。

因此,这里我们构建了一个简单的推荐算法模型,从被block和pass的数据集开始,训练分类模型,根据预测结果进行线上探测,探测结果作为新的训练集,如此迭代,最终实现增量学习,让模型变得越来越准确。从实现的角度来看,也是比较简单的,在提取的特征基础上通过池化层降低维度,最后接一层Softmax输出每个候选单词的概率,选择概率最大/最小的,即黑样本和白样本,探测数量达到阈值,例如6后,即停止此次探测。

这里给出一张图描述总体的探测流程,
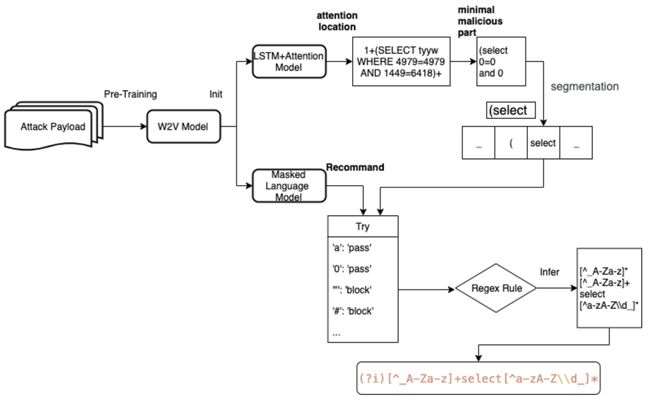
四、实验
首先,我们针对AWS WAF进行了攻击,并针对每一步做了演示图。
第一步:基于 AWS WAF 对大量攻击 Payload 的不同响应结果,AI 算法反推并打印 WAF规则。

第二步:我们将打印的规则部署为本地 WAF。
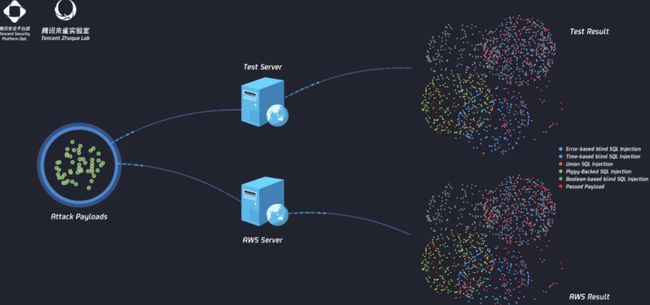
第三步:对比验证,对于同一Payload集合的表现和 AWS WAF 高度一致,拟合度达到 93.8%。

通过这个测试案例,我们可以看到AI针对云上的服务可以大大提升攻击效率和攻击规模,攻击者可以轻松获取模型规则,进而实施绕过,获取敏感数据。

我们还针对Google Cloud和Fortinet的WAF策略进行了测试,这些产品的防护策略与ModSecurity类似,得到的拟合率全部达到95%以上。

五、反思
5.1 场景启发
除了WAF这种场景外,该窃取方法也可用于风控规则策略,根据线上反馈探测打击边界,进而实现绕过。但是这种攻击也有难以覆盖的场景,如果WAF使用基线模型分析请求并比较与正常业务的偏离程度,即类似白名单方式,那么是难以穷尽的,此外,如果是基于AI的后端策略,由于考虑上下文,该策略很难以正则表达式的形式显式输出来,这类模型也就难以生效。
在实验的过程中,我们也发现,部分WAF产品会拒绝响应单一IP多次请求,这种场景下可使用秒拨IP方式对抗,一方面防止IP被封,另一方面也可以并行处理,缩短窃取时间。此外,对于语义模型&AI模型能力克隆,学术界也有一些研究,通过构建本地影子模型、合成数据增强等方式,可以以一个黑盒的方式复制原始模型的能力,在安全领域的顶会中,也出现了多篇论文。

5.2 防御措施
从防御的角度看,抵御窃取攻击最直接的方法是使用伪标签干扰模型训练过程,重写http响应,加深标签的不确定性。后台策略在阻断恶意payload时,返回的响应从403变成200,这样错误的标签实际上是一种数据投毒,会导致模型无法正确训练,从而使得窃取攻击失效。
此外,通过限制单个IP的请求次数、请求速率,多次攻击时跳出验证码验证等方式,可以大大提升窃取攻击的工程难度和代价,让攻击者望而却步。
5.3 研究展望
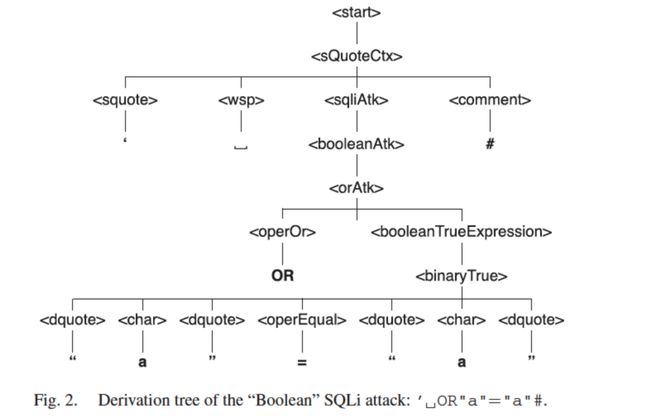
前面我们打印出了WAF防护规则,这些规则定义一个检测语言,实际上我们可以对这些规则进一步分解,构建如下图所示的巴克斯范式语法分解树,遍历这棵树,就会生成很多决策边界的payload,利用遗传算法进行变异等操作,辅助以排序模型,可以筛选出那些最有可能绕过的payload,实现自动化的bypass。当然,这方面的研究比较前沿,基于GAN/Seq2Seq等生成模型的也有不少,这些都给了我们进一步探索的思路。
六、新的威胁
Deep X-Ray是安平朱雀实验室在AI安全领域的一次尝试,它暴露出了目前主流云厂商防御系统存在的问题,云上安全面临着严重的安全挑战。就像变异的新冠病毒一次次突破人体的免疫系统,威胁着人类的生命健康。
新技术的出现,必然会带来新的影响。正如AI的成熟,让生活更加便捷,让生产更加高效,但也带来了新的威胁。人工智能的崛起,在一定程度上也让网络安全领域,将掀起一次技术变革。当黑客用AI把自己武装到牙齿的时候,其危害远远超过传统的网络攻击手段。因此现在开发的基于 AI 的防御机制在很大程度上也可能用于基于 AI 的攻击。Deep X-Ray对抗AI版本的门神这样的场景,会在未来的攻防实践中拉开序幕,AI vs AI才是安全的终极形态!