制作目标检测数据集入门到精通(一)常用数据集(及下载数据网站)汇总
目录
-
- 前言
- 1.目标识别知名数据集
-
- 1.1 PASCAL VOC
- 1.2 MS COCO
- 1.3 ImageNet
- 2 人脸识别相关
-
- 2.1 FERET人脸数据库
- 2.2 CMU Multi-PIE人脸数据库
- 2.3 年龄识别数据集IMDB-WIKI
- 2.4 Large-scale CelebFaces Attributes (CelebA) Dataset
- 2.5 Labeled Faces in the Wild Home (LFW)
- 2.6 CeFA
- 2.7 WildestFaces
- 3 skyimg.ai 发布的相关图像数据集的整理
- 4 CVonline: Image Databases
-
-
- 行动数据库
- 属性识别
- 自动驾驶
- 生物/医学
- 摄像机校准
- 事件摄像机数据
- 人脸和眼睛/虹膜数据库
- 指纹
- 一般图像
- 常规RGBD、三维点云和深度数据集
- 一般视频
- 手、手抓握、手动作和手势数据库
- 图像、视频和形状数据库检索
- 对象数据库
- 人(静态和动态),人体姿势
- 人员检测和跟踪数据库(另见监控)
- 遥感
- 机器人学
- 场景或场所,场景分割或分类
- 分割
- 同时定位和绘图
- 监视和跟踪(另见人员)
- 纹理
- 城市数据集
- 视觉与自然语言
- 其他收藏页
- 杂项主题
-
- 5 其他网友整理的数据合集
-
- 包括了视频、音频、NLP 、CV、 金融、交通、医疗、社会数据等多方面。
- 5 汇总几个下载一般数据集的常用网站
-
- 5.1、Kaggle数据集
- 5.2、Amazon数据集
- 5.3、UCI机器学习资源库
- 5.4、谷歌数据集搜索引擎
- 5.5、微软数据集
- 5.6、Awesome Public Datasets Collection
- 5.7、政府数据集
- 5.8、计算机视觉数据集
- 5.9 阿里天池
- 5.10 格物钛
- 6 部分数据交易平台
前言
本篇主要的目的是网罗汇总个人认知范围内的所有比较好的数据集及其链接地址、相关信息、以及链接地址等。以便于大家使用的时候可以尽快下载,尽快找到足量数据,所以事无巨细全都汇总在一起。主要包括以下几个来源:
- 学术上已经公布发表,或者成为业界检测某种算法性能的知名数据集
- 已知的别人已经整理过的、公开的数据整理数据集序列表
- 数据量丰富的,可以免费下载的常用网站
1.目标识别知名数据集
1.1 PASCAL VOC
- 简介
PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge。该挑战的主要目的是识别真实场景中一些类别的物体。在该挑战中,这是一个监督学习的问题,训练集以带标签的图片的形式给出。这些物体包括20类:
Person: person Animal: bird, cat, cow, dog, horse, sheep Vehicle:
aeroplane, bicycle, boat, bus, car, motorbike, train Indoor: bottle,
chair, dining table, potted plant, sofa, tv/monitor
- 数据说明
该挑战主要包括三类任务:
分类(classification),
检测(detection),
分割(segmentation)
所有的标注图片都有Detection需要的label, 但只有部分数据有Segmentation Label。
VOC2007中包含9963张标注过的图片, 由train/val/test三部分组成, 共标注出24,640个物体。VOC2007的test数据label已经公布, 之后的没有公布(只有图片,没有label)。
VOC2012的trainval/test包含08-11年的所有对应图片。trainval有11540张图片共27450个物体。 对于分割任务, VOC2012的trainval包含07-11年的所有对应图片, test只包含08-11。trainval有 2913张图片共6929个物体。
在这里采用PASCAL VOC2012作为例子:
.
└── VOCdevkit #根目录
└── VOC2012 #不同年份的数据集,这里只下载了2012的,还有2007等其它年份的
├── Annotations #存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等
├── ImageSets #该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本
│ ├── Action
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── JPEGImages #存放源图片
├── SegmentationClass #存放的是图片,语义分割相关
└── SegmentationObject #存放的是图片,实例分割相关
说明:
Annotation文件夹存放的是xml文件,该文件是对图片的解释,每张图片都对于一个同名的xml文件。
ImageSets文件夹存放的是txt文件,这些txt将数据集的图片分成了各种集合。
其中Action下存放的是人的动作(例如running、jumping等等,这也是VOC challenge的一部分);
Layout下存放的是具有人体部位的数据(人的head、hand、feet等等,这也是VOC challenge的一部分);
Main下存放的是图像物体识别的数据,总共分为20类;
Segmentation下存放的是可用于分割的数据。
JPEGImages文件夹存放的是数据集的原图片
SegmentationClass以及SegmentationObject文件夹存放的都是图片,且都是图像分割结果图
- 下载链接
Pascal VOC网址:http://host.robots.ox.ac.uk/pascal/VOC/
查看各位大牛算法的排名的Leaderboards:http://host.robots.ox.ac.uk:8080/leaderboard/main_bootstrap.php
训练/验证数据集下载(2G):host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
数据下载镜像网站(实测迅雷教育网速度很快):https://pjreddie.com/projects/pascal-voc-dataset-mirror/
官方说明:The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Development Kit
1.2 MS COCO
- 简介
是微软公司建立的数据集。对于目标检测任务,COCO包含80个类别,每年大赛的训练和和验证集包含120,000张图片,超过40,000张测试图片。下面是这个数据集中的80个类别:
Person#1:person
Vehicle#8:bicycle,car,motorcycle,airplane,bus,train,truck,boat
Outdoor#5:traffic light, firhydrant, stop sign, parking meter, bench
Animal#10:bird,cat, dog,horse, sheep, cow, elephant, bear, zebra,
giraffe Accessory#5:backpack, umbrella,handbag, tie, suitcase
Sport#10:frisbee, skis,snowboard, sports ball, kite, baseball bat ,
baseball glove, skateboard, surfboard, tennisracket Kitchen#7:bottle,
wine glass,cup, fork, knife, spoon, bowl Food#10:banana,
apple,sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake
Furniture#6: chair, couch, potted plant,bed, dining table, toilet
Electronic#6:tv, laptop, mouse,remote, keyboard, cell phone
Appliance#5:microwave, oven,toaster, sink, refrigerator Indoor#7:book,
clock, vase,scissors, teddy bear, hair drier, toothbrus
- 数据说明
数据集格式介绍:http://cocodataset.org/#format-data。
重要的网址:
在学习过程中,博主发现了写的更为详细和全面的一些介绍博客,记录在这里供大家参考:
COCO数据集的标注格式-知乎专栏
COCO有5种类型的标注,分别是:物体检测、关键点检测、实例分割、全景分割、图片标注,都是对应一个json文件。json是一个大字典,都包含如下的关键字:
{
"info" : info,
"images" : [image],
"annotations" : [annotation],
"licenses" : [license],
}
虽然每个json文件都有"info", “images” , “annotations”, "licenses"关键字,但不同的任务对应的json文件中annotation的形式不同,具体格式就不展开讨论了。
- 下载链接
数据集官网首页:http://cocodataset.org/#home
数据集下载:可用迅雷去下载官方链接,速度还是挺快的。如果速度不快,可能你需要找“正确版本”的迅雷
1.3 ImageNet
- 简介
是一个计算机视觉系统识别项目,是目前世界上图像识别最大的数据库,是美国斯坦福的计算机科学家,模拟人类的识别系统建立的。ImageNet数据集是按照WordNet架构组织的大规模带标签图像数据集。大约1500万张图片,2.2万类,每张都经过严格的人工筛选与标记。ImageNet类似于图片所有引擎。
其中,包括边界框的目标检测数据集,训练数据集包括500,000张图片,属于200类物体。由于数据集太大,训练所需计算量很大;类别数较多;造成了很少使用和目标检测的难度也很大。
ImageNet是根据WordNet层次结构组织的图像数据集。在ImageNet中,目标是为了说明每个synset提供平均1000幅图像。 每个concept图像都是质量控制和人为标注的(quality-controlled and human-annotated)。 在完成之后,希望ImageNet能够为WordNet层次结构中的大多数concept提供数千万个干净整理的图像(cleanly sorted images)。
ImageNet是一项持续的研究工作,旨在为世界各地的研究人员提供易于访问的图像数据库。目前ImageNet中总共有14197122幅图像,总共分为21841个类别(synsets),大类别包括:amphibian、animal、appliance、bird、covering、device、fabric、fish、flower、food、fruit、fungus、furniture、geological formation、invertebrate、mammal、musical instrument、plant、reptile、sport、structure、tool、tree、utensil、vegetable、vehicle、person。
- ImageNet数据集介绍以及下载链接:
http://www.image-net.org/
2 人脸识别相关
2.1 FERET人脸数据库
由FERET项目创建,此图像集包含大量的人脸图像,并且每幅图中均只有一个人脸。该集中,同一个人的照片有不同表情、光照、姿态和年龄的变化。包含1万多张多姿态和光照的人脸图像,是人脸识别领域应用最广泛的人脸数据库之一。其中的多数人是西方人,每个人所包含的人脸图像的变化比较单一。
http://www.nist.gov/itl/iad/ig/colorferet.cfm
2.2 CMU Multi-PIE人脸数据库
由美国卡耐基梅隆大学建立。所谓“PIE”就是姿态(Pose),光照(Illumination)和表情(Expression)的缩写。CMU Multi-PIE人脸数据库是在CMU-PIE人脸数据库的基础上发展起来的。包含337位志愿者的75000多张多姿态,光照和表情的面部图像。其中的姿态和光照变化图像也是在严格控制的条件下采集的,目前已经逐渐成为人脸识别领域的一个重要的测试集合。
http://www.flintbox.com/public/project/4742/
2.3 年龄识别数据集IMDB-WIKI
包含524230张从IMDB和Wikipedia爬取的名人数据图片。应用了一个新颖的化回归为分类的年龄算法。本质就是在0-100之间的101类分类后,对于得到的分数和0-100相乘,并将最终结果求和,得到最终识别的年龄。
https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/
2.4 Large-scale CelebFaces Attributes (CelebA) Dataset
CelebFaces Attributes Dataset (CelebA) is a large-scale face attributes dataset with more than 200K celebrity images, each with 40 attribute annotations. The images in this dataset cover large pose variations and background clutter. CelebA has large diversities, large quantities, and rich annotations, including
10,177 number of identities,
202,599 number of face images, and
5 landmark locations, 40 binary attributes annotations per image.
这是由香港中文大学汤晓鸥教授实验室公布的大型人脸识别数据集。该数据集包含有200K张人脸图片,人脸属性有40多种,主要用于人脸属性的识别。
下载链接
2.5 Labeled Faces in the Wild Home (LFW)
More than 13,000 images of faces collected from the web. Each face has been labeled with the name of the person pictured. 1680 of the people pictured have two or more distinct photos in the data set.
LFW数据集是为了研究非限制环境下的人脸识别问题而建立的。这个数据集包含超过13,000张人脸图像,均采集于Internet。
每个人脸均被标准了一个人名。其中,大约1680个人包含两个以上的人脸。
这个集合被广泛应用于评价Face Verification算法的性能。

下载链接
2.6 CeFA
发布了迄今为止最大的人脸活体检测数据集,在模式、被测目标数量和攻击类型方面都是如此。更重要的是,CeFA是唯一一个带有民族标签的公开人脸活体检测数据集。此外,通过从多模态数据中学习补充信息来缓解民族偏见,提供了一条基线:PSMM Net。广泛的实验验证了算法的实用性以及在所提出的数据集上训练模型的泛化能力。
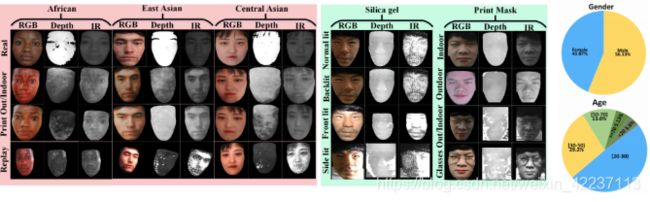
论文 | https://openaccess.thecvf.com/content/
WACV2021/papers/Liu_CASIA-SURF_CeFA_A_
Benchmark_for_Multi-Modal_Cross-Ethnicity_Face_Anti-Spoofing_WACV_2021_paper.pdf
数据集 | https://sites.google.com/qq.com/face-anti-spoofing/welcome/challengecvpr2020?authuser=0
备注 | WACV2021
2.7 WildestFaces
研究了人脸识别背景下的部分监督域迁移问题,基于干净的训练图像,评估算法对粗劣视频中人的识别能力。引入一个数据集:WildestFaces,包含模糊、姿势多样性、遮挡和分辨率等不利图像。
论文 | https://arxiv.org/abs/2009.07576
数据集 | https://ycbilge.github.io/wildestFaces
备注 | WACV2021
3 skyimg.ai 发布的相关图像数据集的整理
大类主要包括:自然图像数据集、 人脸数据集、 视频数据集、 文本数据集、 推荐系统和排名、 语音数据集、 音符数据集等因为数量众多,还是参见 datawhale的整理版
4 CVonline: Image Databases
这是一个非常强、内容覆盖面大、整理完善的汇总CV领域数据资源的网页
大类主要包括:
行动数据库
属性识别
自动驾驶
生物/医学
摄像机校准
事件摄像机数据
人脸和眼睛/虹膜数据库
指纹
一般图像
常规RGBD、三维点云和深度数据集
一般视频
手、手抓握、手动作和手势数据库
图像、视频和形状数据库检索
对象数据库
人(静态和动态),人体姿势
人员检测和跟踪数据库(另见监控)
遥感
机器人学
场景或场所,场景分割或分类
分割
同时定位和绘图
监视和跟踪(另见人员)
纹理
城市数据集
视觉与自然语言
其他收藏页
杂项主题
原网页链接:http://homepages.inf.ed.ac.uk/rbf/CVonline/Imagedbase.htm
或者参见有些人的翻译的版本:链接
5 其他网友整理的数据合集
包括了视频、音频、NLP 、CV、 金融、交通、医疗、社会数据等多方面。
链接地址:https://blog.csdn.net/qq_32447301/article/details/79487335
5 汇总几个下载一般数据集的常用网站
不仅包含用于实验的大型数据集,还附带对数据集的描述以及使用示例。有的还包含用于解决与该数据集相关机器学习问题的算法代码。
5.1、Kaggle数据集
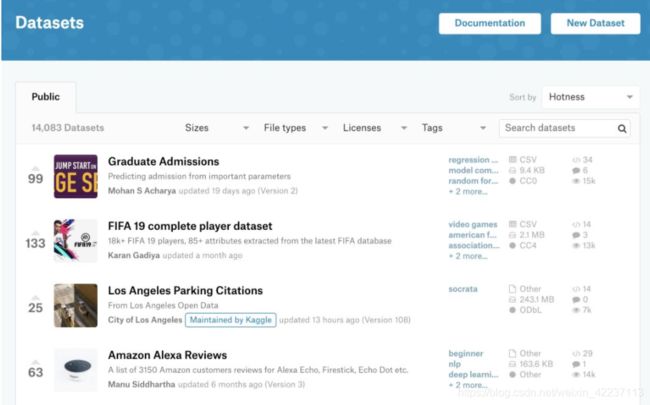
数据集地址:https://www.kaggle.com/datasets
5.2、Amazon数据集
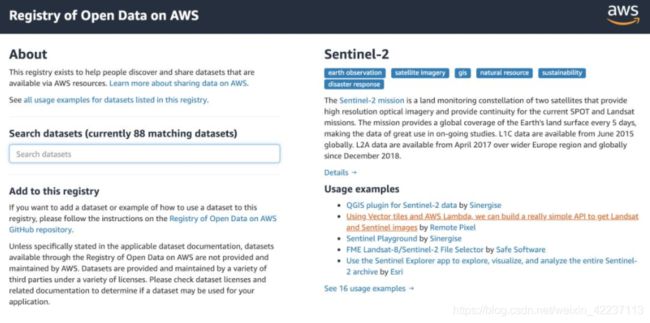
数据集地址:https://registry.opendata.aws/
该数据源包含多个不同领域的数据集,如:公共交通、生态资源、卫星图像等。
网页中也有一个搜索框来帮助用户寻找想要的数据集,还有所有数据集的描述和使用示例,这些数据集信息丰富且易于使用!
数据集存储在Amazon Web Services (AWS)资源中,比如Amazon S3——云中的一个高度可伸缩的对象存储服务。
如果用户正在使用AWS进行机器学习实验和开发,这将非常方便,由于它是AWS网络的本地数据,因此数据集的传输将非常快。
5.3、UCI机器学习资源库
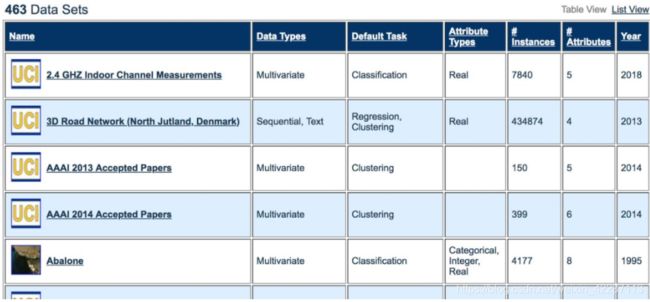
数据集地址:https://archive.ics.uci.edu/ml/datasets.html
另一个来自加州大学信息与计算机科学学院的大型资源库,包含100多个数据集。
用户可以找到单变量和多变量时间序列数据集,分类、回归或推荐系统的数据集。
有些UCI的数据集已经是被清洗过的。
5.4、谷歌数据集搜索引擎
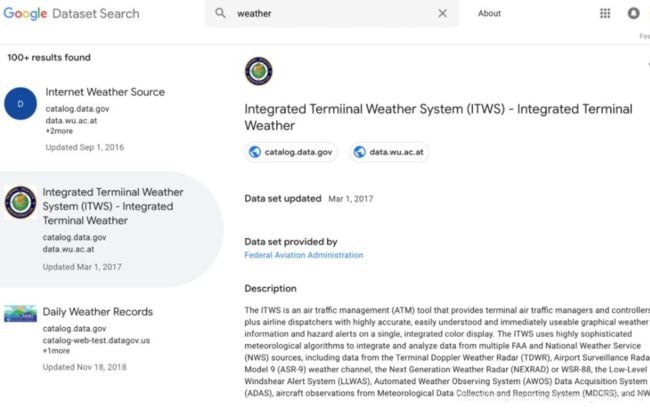
数据集地址:https://toolbox.google.com/datasetsearch
在2018年末,谷歌做了他们最擅长的事情,推出了另一项伟大的服务——它是一个可以按名称搜索数据集的工具箱。
他们的目标是统一成千上万个不同的数据集存储库,使这些数据能够且易被发现。
5.5、微软数据集
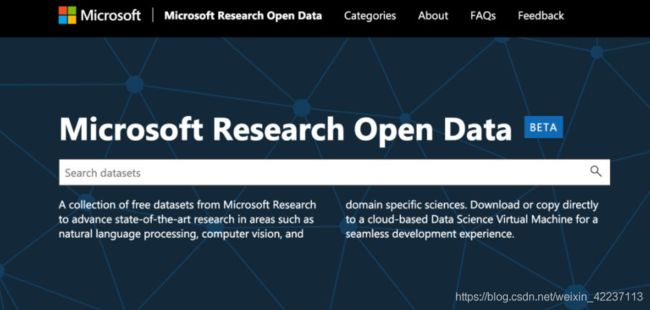
数据集地址:https://msropendata.com/
2018年7月,微软与外部研究社区共同宣布推出“Microsoft Research Open Data”。
它在云中包含一个数据存储库,用于促进全球研究社区之间的协作。它提供了一系列用于已发表研究的、经过处理的数据集。
5.6、Awesome Public Datasets Collection
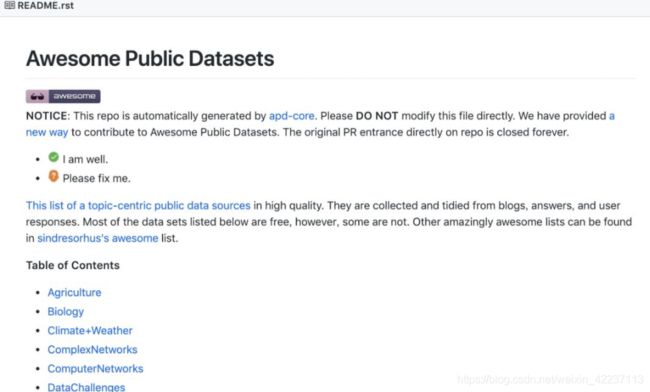
数据集地址:https://github.com/awesomedata/awesome-public-datasets
这是一个按“主题”组织的数据集,比如生物学、经济学、教育学等。
这里列出的大多数数据集都是免费的,但是在使用任何数据集之前,用户需要检查一下许可要求。
5.7、政府数据集
政府相关数据集也很容易找到的。
许多国家为了提高透明度,向公众分享了各种数据集。以下是一些例子:
欧盟开放数据门户:欧洲政府数据集。
数据集地址:https://data.europa.eu/euodp/data/dataset
美国政府数据:目前由于一些非政治性原因,暂时无法访问。
数据集地址:https://www.data.gov/
新西兰政府数据集:
数据集地址:https://catalogue.data.govt.nz/dataset
印度政府数据集:
数据集地址:https://data.gov.in/
5.8、计算机视觉数据集
数据集地址:https://www.visualdata.io/
Visual Data包含一些可以用来构建计算机视觉(CV)模型的大型数据集。
用户可以通过特定的CV主题查找特定的数据集,如语义分割、图像标题、图像生成,甚至可以通过解决方案(自动驾驶汽车数据集)查找特定的数据集。
5.9 阿里天池
数据集地址:https://tianchi.aliyun.com/dataset?spm=5176.12282016.0.0.29536d92P3ZKjo
5.10 格物钛
在CV等计算机领域中,好的数据,对模型训练至关重要。自己做数据,即昂贵又费时费力;但是,使用现成的数据集,即不好找又不好下载及使用。直到最近,找到一个数据集获取神器 Graviti Open Dataset。
简单点说,Graviti 是一个提供公开数据集的平台,你可以很方便的搜索你想要的数据,可在线预览样例数据、标注、标签,对于国外的数据不需要“梯子”、可高速免费下载。
-
Graviti 收录了 400 多个高质量 CV 类数据集,覆盖无人驾驶、智慧零售、机器人等多种 AI 应用领域。
-
不仅种类多,还方便搜索,可以按应用行业 , 标注类型进行筛选!查找简单操作。
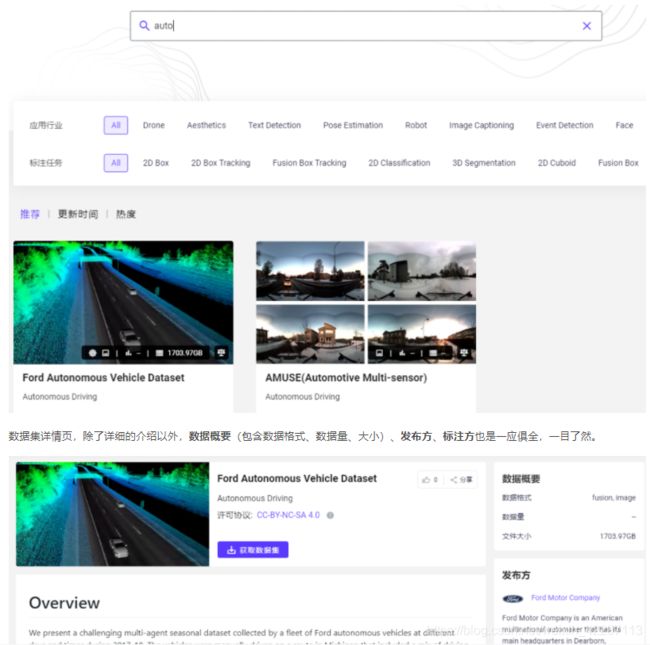
- 除了整合数据集信息以外,在线可视化也是亮点!无需下载直接可以浏览样例数据,标注、标签同样可以轻松在线查看。
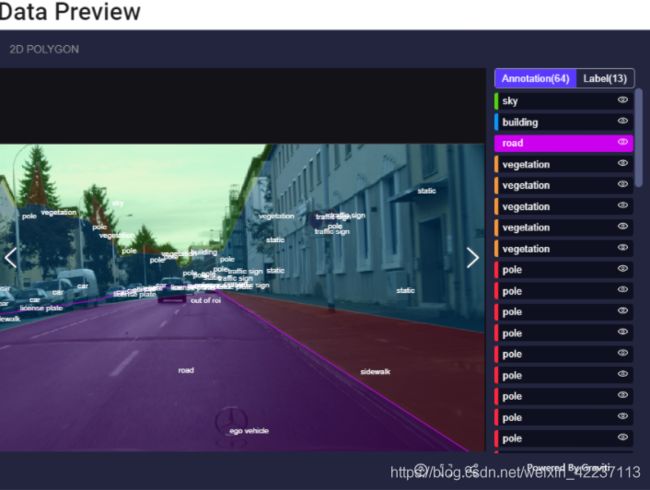
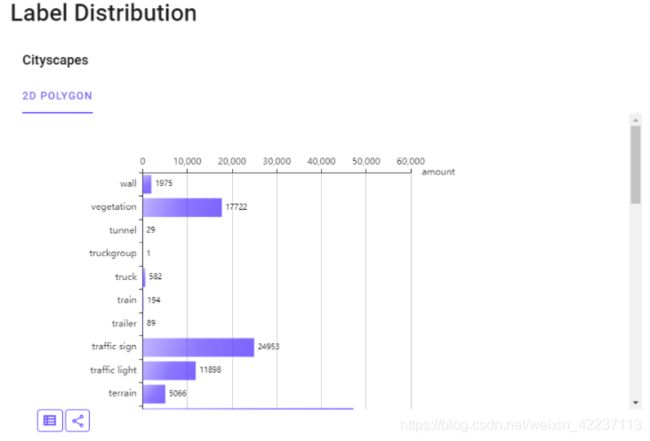
甚至,提供了数据分布:
官方地址:https://www.graviti.cn/open-datasets
6 部分数据交易平台
由于现在数据的需求很大,也催生了很多做数据交易的平台,当然,除去付费购买的数据,在这些平台,也有很多免费的数据可以获取。
- 优易数据:
拥有国家级信息资源的数据平台。包含政务、社会、社交、教育、消费、交通、能源、金融、健康等多个领域的数据资源。
- 数据堂:
提供数据交易、处理和数据API服务,包含语音识别、医疗健康、交通地理、电子商务、社交网络、图像识别等方面的数据。