相关链接
极客时间课程: https://time.geekbang.org/cou...
课程配套 Github: https://github.com/onebirdroc...
每个部分都有一份课堂上 ppt 的 pdf 版本.
概述
ElasticSearch 简介及其发展历史
ElasticSearch 是一个开源的分布式搜索与分析引擎, 提供了近实时搜索和聚合两大功能.
ES 版本与升级
0.4: 2010年2月1.0: 2014年1月2.0: 2015年10月5.0: 2016年10月- Lucene 6.x
- Type 标记为 deprecated, 支持 Keyword 类型
6.0: 2017年10月- Lucene 7.x
- SQL 的支持
- 索引生命周期管理
7.0: 2019年4月- Lucene 8.x
正式废除单个索引下多个 Type 的支持
这意味着 一个索引 对应 一个Type
Security 功能免费试用
从 6.8 和 7.1 开始
- ECK - ElasticSearch Operator on Kubernetes
Elastic Stack 家族成员


Logstash: 数据处理管道
开源的服务器端数据处理管道, 支持从不同的来源采集数据, 转换数据, 并将数据发送到不同的存储库中.
最早是用于日志的采集和处理
特性
实时解析和转换数据
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化, 完全排除敏感字段
可扩展
- 200 个多个插件(日志/数据库/Arcsigh/Netflow)
可靠性安全性
- Logstash 会通过持久化队列来保证至少将运行中的事件送达一次
- 数据传输加密
- 监控
Kibana: 可视化分析利器
- Kibana 名字含义 = Kiwifruit + Banana
- 数据可视化工具, 帮助用户解开对数据的任何疑问
- 基于 Logstash 的工具, 2013 年加入 Elastic 公司
BEATS : 轻量的数据采集器
Filebeat: 日志文件
日志文件可以通过filebeat抓取,直接丢进es或者logstash处理后入库
Packetbeat: 网络抓包
...
X-Pack : 商业化套件
- 6.3 之前的版本, X-Pack 以插件方式安装
X-Pack 开源后(2018年), ELasticSearch & Kibana 支持 OSS 版和 Basic 两种版本
- 部分 X-Pack 功能支持免费试用, 6.8 和 7.1 开始, Security 功能免费
- OSS, Basic(免费), 黄金级, 白金级
应用场景
应用场景
- 搜索
- 日志管理
- 安全分析
- 指标分析
- 业务分析
- 应用性能监控
ES 提供了如模糊搜索, 搜索条件的算分等关系型数据库所不擅长的功能, 但是在事务性方面不如关系型数据库强大.
因此在实际生产环境中, 应结合具体业务要求, 综合使用.
单独使用 ES 或与现有数据库集成 ?
- 单独使用 ES 存储: 架构会简单很多.
若存在以下情况则更推荐与数据库集成(推荐)
- 与现有系统的集成
- 需考虑事务性
- 数据更新频繁
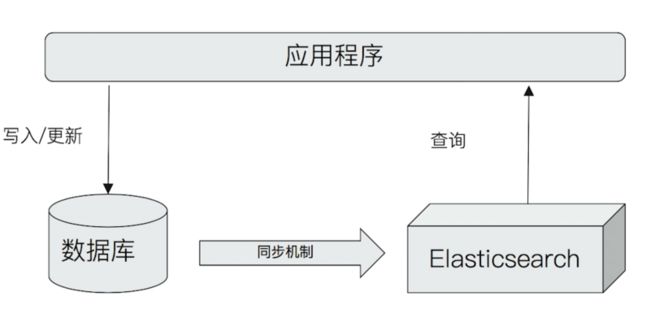
如果没特殊情况, 建议使用同步机制, 将数据库中的数据同步到 ElasticSearch.
比如 MySQL 的 BinLog + MQ 写入 ES.这部分可查看存储系统实战那个课程.
对于日志收集的架构
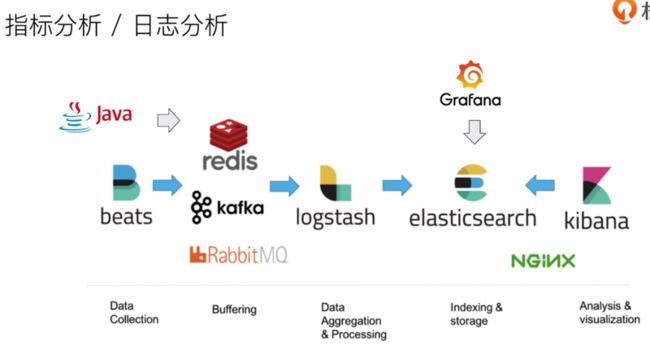
- redis/kafka/RabbitMQ 作为缓冲层, 支撑高并发写入
- logstash: 转换, 聚合, 写到 ElasticSearch
扩展
报警
Kibana 自带的 Watcher 使用时要加钱... 可以考虑用以下方案替代:
-
Star 7.1k
没有图形化界面管理, 走配置文件
这里有个示例(不确定质量如何): https://segmentfault.com/a/11...
-
与 kibana 结合, 但版本更新较慢, 截止 2020年11月16日 11:08:44 只适配到 7.6.1 的 kibana 版本(预发布版), 上一个正式版本是 6.8.4
ui: 告警管理及报告
这里有个示例(不确定质量如何): https://segmentfault.com/a/11...
安装上手
ElasticSearch 的安装与简单配置
ES 配置文件详解: https://www.elastic.co/guide/...
安装 Java

安装并运行 ES
压缩包方式安装
压缩包方式安装
下载并解压 ES
或使用 yum 之类的安装...
直接下载速度太慢了, 建议翻..墙
- 确认配置文件
config/elasticsearch.yml 运行
bin/elasticsearch默认端口: 9200
ES 会优先使用系统已安装的 JDK(读取环境变量 JAVA_HOME)
JVM 配置
修改 JVM - config/jvm.options
- 7.1 下的默认设置是 1GB
配置的建议
- Xms 和 Xmx 设置成一样
- Xmx 不要超过机器内存的 50%
- 不要超过 30GB - https://www.elastic.co/blog/a...
config/elasticsearch.yml
- path.data: 数据保存目录
- path.logs: 日志保存目录
- network.host: 监听地址(本地只有本地)
- ...
更多的配置说明参见: https://www.elastic.co/guide/...
目录结构
RPM 方式安装
- 下载并安装 RPM 包
- 默认配置文件
/etc/elasticsearch/elasticsearch.yml - 额外的配置文件
/etc/sysconfig/elasticsearch包含环境变量及堆大小, 文件描述符设置
- 用 SysV 或 Systemd 管理进程
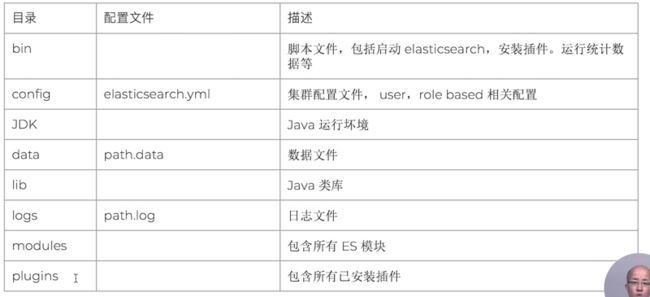
文件目录分布结构
| Type | Description | Default Location | Setting |
|---|---|---|---|
| home | Elasticsearch home directory or $ES_HOME |
/usr/share/elasticsearch |
|
| bin | Binary scripts including elasticsearch to start a node and elasticsearch-plugin to install plugins |
/usr/share/elasticsearch/bin |
|
| conf | Configuration files including elasticsearch.yml |
/etc/elasticsearch |
ES_PATH_CONF |
| conf | Environment variables including heap size, file descriptors. | /etc/sysconfig/elasticsearch |
|
| data | The location of the data files of each index / shard allocated on the node. Can hold multiple locations. | /var/lib/elasticsearch |
path.data |
| jdk | The bundled Java Development Kit used to run Elasticsearch. Can be overridden by setting the JAVA_HOMEenvironment variable in /etc/sysconfig/elasticsearch. |
/usr/share/elasticsearch/jdk |
|
| logs | Log files location. | /var/log/elasticsearch |
path.logs |
| plugins | Plugin files location. Each plugin will be contained in a subdirectory. | /usr/share/elasticsearch/plugins |
|
| repo | Shared file system repository locations. Can hold multiple locations. A file system repository can be placed in to any subdirectory of any directory specified here. | Not configured | path.repo |
安装插件
# 查看当前已安装插件列表
bin/elasticsearch-plugin list
# 也可以通过 RESTFul 接口查看已安装插件列表
curl http://localhost:9200/_cat/plugins?v
# 安装完需重启 ES 才能生效
## 安装analysis-icu
bin/elasticsearch-plugin install analysis-icu
## 安装 analysis-ik 插件
### 若存在网络问题, 则可先通过其他方式下载插件到本地, 再安装(注意插件版本号必须和 ElasticSearch 版本号按照规则对应, 这里以 v7.9.1 为例)
bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.1/elasticsearch-analysis-ik-7.9.1.zip
# 重启 ES
# Test
curl -X POST "localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d '{ "analyzer": "ik_smart", "text": "中文分词" }'
在开发机运行多个 ES 实例
# 端口分别自动从 9200~9202
bin/elasticsearch -E node.name=node1 -E cluster.name=geektime -E path.data=node1_data -E path.logs=node1_logs -d
bin/elasticsearch -E node.name=node2 -E cluster.name=geektime -E path.data=node2_data -E path.logs=node1_logs -d
bin/elasticsearch -E node.name=node3 -E cluster.name=geektime -E path.data=node3_data -E path.logs=node1_logs -d如果是 windows 则用下面的
bin\elasticsearch.bat -E node.name=node1 -E cluster.name=geektime -E path.data=node1_data -E path.logs=node1_logs
bin\elasticsearch.bat -E node.name=node2 -E cluster.name=geektime -E path.data=node2_data -E path.logs=node2_logs
bin\elasticsearch.bat -E node.name=node3 -E cluster.name=geektime -E path.data=node3_data -E path.logs=node3_logs注: Windows 环境中(cmder)使用-d选项无效, 无法在后台执行, 因此需要开3个命令行环境来执行.可以直接写成 3 个批处理文件, 方便处理.
Kibana 的安装与界面快速浏览
Kibana 配置文件详解: https://www.elastic.co/guide/...
安装并运行
压缩包方式安装
- 下载并解压
确认配置文件
config/kibana.ymlserver.port: 5601 #server.host: "localhost" server.host: "0.0.0.0" elasticsearch.hosts: ["http://localhost:9200"] #i18n.locale: "en" i18n.locale: "zh-CN"- 启动:
bin/kibana
RPM 方式安装
- 下载并安装 RPM 包
- 默认配置文件
/etc/kibana/kibana.yml - 用 SysV 或 Systemd 管理进程
文件目录结构
| Type | Description | Default Location | Setting |
|---|---|---|---|
| home | Kibana home directory or $KIBANA_HOME |
/usr/share/kibana |
|
| bin | Binary scripts including kibana to start the Kibana server and kibana-plugin to install plugins |
/usr/share/kibana/bin |
|
| config | Configuration files including kibana.yml |
/etc/kibana |
|
| data | The location of the data files written to disk by Kibana and its plugins | /var/lib/kibana |
path.data |
| logs | Logs files location | /var/log/kibana |
path.logs |
| optimize | Transpiled source code. Certain administrative actions (e.g. plugin install) result in the source code being retranspiled on the fly. | /usr/share/kibana/optimize |
|
| plugins | Plugin files location. Each plugin will be contained in a subdirectory. | /usr/share/kibana/plugins |
安装插件

bin/kibana-plugin install plugin_locationbin/kibana-plugin listbin/kibana remove
Cerebro 的安装与简单配置
Cerebro 是一个方便管理 ES 集群的工具.
安装并运行
- 下载 并解压
- 确认配置
conf/application.conf - 确认配置
conf/reference.conf - 运行
bin/cerebro
在本机 Docker 运行 ELK Stack 和 Cerebro
https://www.elastic.co/guide/...
若要在生产环境中使用 Docker, 还需要进行一些额外配置
课程老师提供的 docker-compose 配置, 同时该链接提供了一些参考链接
这里有一份 ELK docker-compose 配置 Star 9.8k+
⭐ ELK docker-compose Github
https://github.com/youjiaxing...
- fork 一份 star 9.8k 的来修改
这里默认配置是单节点, 但是按照其中的简单文档, 也可以快速配置成多节点的集群模式.
单节点
docker-compose.yml
version: "3"
services:
elasticsearch:
build:
context: ./elasticsearch
args:
ELK_VERSION: ${ELK_VERSION}
volumes:
- ./elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- elasticsearch:/usr/share/elasticsearch/data
ports:
- "9200:9200"
- "9300:9300"
environment:
ES_JAVA_OPTS: "-Xms512m -Xmx512m"
ELASTIC_PASSWORD: password
# 使用单节点 discoverty 可禁用生产模式并避免启动时的检查
# see https://www.elastic.co/guide/en/elasticsearch/reference/current/bootstrap-checks.html
discovery.type: "single-node"
kibana:
build:
context: ./kibana
args:
ELK_VERSION: ${ELK_VERSION}
volumes:
- ./kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml:ro
ports:
- "5601:5601"
depends_on:
- elasticsearch
cerebro:
image: "lmenezes/cerebro:0.9.2"
depends_on:
- elasticsearch
ports:
- "9000:9000"
command:
- -Dhosts.0.host=http://elasticsearch:9200
logstash:
build:
context: ./logstash
args:
ELK_VERSION: ${ELK_VERSION}
volumes:
- ./logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml:ro
- ./logstash/pipeline:/usr/share/logstash/pipeline:ro
- ./logstash/data:/data:ro
ports:
# 可通过 5000 端口向 logstash 写入日志
- "5000:5000/tcp"
- "5000:5000/udp"
- "9600:9600"
environment:
LS_JAVA_OPTS: "-Xmx512m -Xms512m"
depends_on:
- elasticsearch
volumes:
elasticsearch:.env
ELK_VERSION=7.8.0elasticsearch/Dockerfile
ARG ELK_VERSION
# https://www.docker.elastic.co/
FROM docker.elastic.co/elasticsearch/elasticsearch:${ELK_VERSION}
# RUN elasticsearch-plugin install analysis-icuelastcisearch/config/elasticsearch.yml
---
## Default Elasticsearch configuration from Elasticsearch base image.
## https://github.com/elastic/elasticsearch/blob/master/distribution/docker/src/docker/config/elasticsearch.yml
#
cluster.name: "docker-cluster"
network.host: 0.0.0.0
## X-Pack settings
## see https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-xpack.html
#
xpack.license.self_generated.type: basic
# xpack.security.enabled: false
xpack.monitoring.collection.enabled: truekibana/Dockerfile
ARG ELK_VERSION
FROM docker.elastic.co/kibana/kibana:${ELK_VERSION}
# Add your kibana plugins setup here
# Example: RUN kibana-plugin install kibana/config/kibana.yml
---
## Default Kibana configuration from Kibana base image.
## https://github.com/elastic/kibana/blob/master/src/dev/build/tasks/os_packages/docker_generator/templates/kibana_yml.template.js
#
server.name: kibana
server.host: 0.0.0.0
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
i18n.locale: "zh-CN"
## X-Pack security credentials
#
elasticsearch.username: elastic
elasticsearch.password: password
xpack.security.enabled: falselogstash/Dockerfile
ARG ELK_VERSION
FROM docker.elastic.co/logstash/logstash:${ELK_VERSION}
# Add your logstash plugins setup here
# Example: RUN logstash-plugin install logstash-filter-json多节点
docker-compose.yml
version: "3"
services:
es01:
build:
context: ./elasticsearch
args:
ELK_VERSION: ${ELK_VERSION}
container_name: es01
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- "9200:9200"
- "9300:9300"
environment:
node.name: es01
cluster.name: es-docker-cluster
discovery.seed_hosts: es02,es03
cluster.initial_master_nodes: es01,es02,es03
bootstrap.memory_lock: "true"
ES_JAVA_OPTS: "-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
es02:
build:
context: ./elasticsearch
args:
ELK_VERSION: ${ELK_VERSION}
container_name: es02
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- "9201:9200"
- "9301:9300"
environment:
node.name: es02
cluster.name: es-docker-cluster
discovery.seed_hosts: es01,es03
cluster.initial_master_nodes: es01,es02,es03
bootstrap.memory_lock: "true"
ES_JAVA_OPTS: "-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
es03:
build:
context: ./elasticsearch
args:
ELK_VERSION: ${ELK_VERSION}
container_name: es03
volumes:
- data03:/usr/share/elasticsearch/data
ports:
- "9202:9200"
- "9302:9300"
environment:
node.name: es03
cluster.name: es-docker-cluster
discovery.seed_hosts: es01,es02
cluster.initial_master_nodes: es01,es02,es03
bootstrap.memory_lock: "true"
ES_JAVA_OPTS: "-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
kibana:
build:
context: ./kibana
args:
ELK_VERSION: ${ELK_VERSION}
container_name: kibana
# volumes:
# - ./kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml:ro
environment:
SERVER_NAME: kibana
ELASTICSEARCH_HOSTS: http://es01:9200
ELASTICSEARCH_URL: http://es01:9200
I18N_LOCALE: zh-CN
ports:
- "5601:5601"
depends_on:
- es01
- es02
- es03
cerebro:
image: "lmenezes/cerebro:0.9.2"
container_name: cerebro
ports:
- "9000:9000"
command:
- -Dhosts.0.host=http://es01:9200
depends_on:
- es01
- es02
- es03
logstash:
build:
context: ./logstash
args:
ELK_VERSION: ${ELK_VERSION}
container_name: logstash
volumes:
# - ./logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml:ro
- ./logstash/pipeline:/usr/share/logstash/pipeline:ro
- ./logstash/data:/data:ro
environment:
MONITORING_ELASTICSEARCH_HOSTS: http://es01:9200
ports:
# 可通过 5000 端口向 logstash 写入日志
- "5000:5000/tcp"
- "5000:5000/udp"
- "9600:9600"
environment:
LS_JAVA_OPTS: "-Xmx512m -Xms512m"
depends_on:
- es01
- es02
- es03
volumes:
data01:
data02:
data03:Dockerfile 配置文件同 "单节点模式的一样"
logstash/pipeline/logstash.conf
input {
tcp {
port => 5000
}
}
## Add your filters / logstash plugins configuration here
output {
elasticsearch {
hosts => "es01:9200"
}
}logstash/pipeline/movielens.conf
input {
file {
path => "/data/ml-latest-small/movies.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["id","content","genre"]
}
mutate {
split => { "genre" => "|" }
remove_field => ["path", "host","@timestamp","message"]
}
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://es01:9200"
index => "movies"
document_id => "%{id}"
}
stdout {}
}Logstash 的安装与导入数据
安装并运行
- 下载 并解压
- 确认配置
logstash.conf - 执行
bin/logstash -f logstash.conf
学习使用的测试数据及可以从 Movielens 下载
logstash.conf 配置文件指定了导入数据的来源(input), 过滤(filter), 输出(output)
ElasticSearch 入门
基本概念 1
文档 (Document)
文档

JSON 文档

Logstash 会自动进行数据类型推算
文档的元数据

_all 字段从 7.0 开始废除
索引(Index)
索引

索引的不同语义

Type

抽象与类比

并不是那么恰当的对比
RESTful Api

基本概念 2
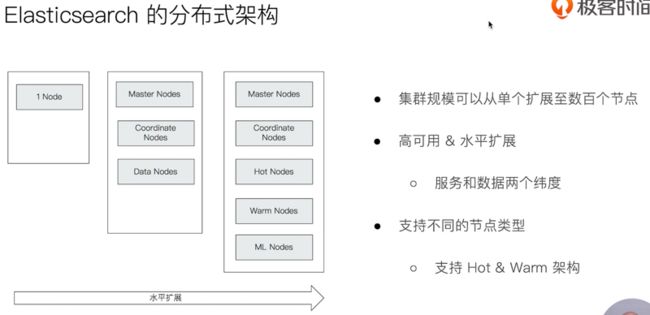
分布式
分布式系统的可用性与扩展性

分布式特性

节点
节点

Master-eligible nodes 和 Master Node

Data Node & Coordinating Node

其他的节点类型

冷热节点
- Hot: 存储热数据
- Warn: 存储冷数据(指较少访问)
配置节点类型

每个节点设置单一角色的好处:
- 更好的性能, 不同用途的节点可以配置不同级别的硬件.
- 职责很明确
分片
分片(Primary Shard & Replica Shard)


number_of_shards主分片数量
number_of_replicas每个主分片的副本数量
分片的设定

"主分片数" 是在索引创建时预先设定, 且后续无法修改的.
集群
# 查看集群健康状态
## Green 主分片与副本都正常分配
## Yellow 朱分片全部正常分配, 有副本分片未能正常分配
## Red 有主分片未能分配(例如当服务器的磁盘容量超过85%时去创建一个新的索引)
GET _cluster/health
# 查看节点状态
GET _cat/nodes?v
# 查看分片状态
GET _cat/shards?v文档的 CRUD 与批量操作
7.0 开始, 索引的 type 固定使用 _doc, 索引和 type 的关系固定是 一对一.

create 创建一个文档
指定文档 Id
PUT 索引名/_create/文档Id
{
"key1": "value1",
...
}- 若对应的文档 Id 已存在, 会失败.
自动生成文档 Id
POST 索引名/_doc
{
"key1": "value1",
...
}get 一个文档
GET 索引名/_doc/文档Id文档存在则返回 HTTP 200, 不存在返回 HTTP 404
返回的信息包含两部分
文档元数据(meta data)
_index/_type: 文档所属索引和type_version: 版本信息, 同一个 Id 的文档, 即使被删除, Version 号也会不断增加.
文档原始数据
_source: 默认包含了文档的所有原始信息
index 一个文档
Index 与 Create 不一样, Index 的行为:
- 如果文档不存在, 就索引新的文档.
如果文档已存在, 会删除旧文档, 然后索引新的文档, 并且版本号
_version会 +1Create 这种情况是直接返回错误.
PUT 索引名/_doc/文档Id
{
"key": "value",
...
}- 实际使用
POST 索引名/_doc/文档Id效果也一样, 猜测这两个是等同的.
查询参数
op_typeindex(默认): 索引文档create: create文档, 等同PUT 索引名/_create/文档Id
update 一个文档
Update 行为
不会删除原来的文档, 而是实现真正的数据更新
_version也会递增.- 主要用于部分更新文档
// 可以理解为 PATCH(不过 ES 好像不支持这个)
POST 索引/_update/文档Id
{
"doc": {
"key": "value",
...
}
}
payload 部分要包含在
doc 字段中
_update_by_query 更新多个文档
https://www.elastic.co/guide/...
POST my-index-000001/_update_by_query?conflicts=proceed
POST my-index-000001/_update_by_query?conflicts=proceed
{
"query": {
"term": {
"user.id": "kimchy"
}
}
}
POST my-index-000001/_update_by_query
{
"script": {
"source": "ctx._source.count++",
"lang": "painless"
},
"query": {
"term": {
"user.id": "kimchy"
}
}
}delete 一个文档
DELETE 索引/_doc/文档Id_delete_by_query 删除多个文档
https://www.elastic.co/guide/...
POST /my-index-000001/_delete_by_query
{
"query": {
"match": {
"user.id": "elkbee"
}
}
}
POST /metricbeat-7.9.3/_delete_by_query?conflicts=proceed
{
"query": {
"match_all":{}
}
}bulk 批量操作
// 这是一个示例
// 以下的 index, delete, create, update 都是一种操作, 除了 delete 外, 其他的要紧跟着一行表示操作的内容.
POST _bulk
{ "index": {"_index":"test", "_id": "1"}}
{ "field1": "value1" }
{ "delete": { "_index":"test","_id":"2"}}
{ "create": { "_index":"test2", "_id": "3"}}
{ "field1": "value3" }
{ "update": {"_index":"test", "_id": "1"}}
{ "doc": {"field2":"value2"}}支持在一个 API 调用中, 对不同的索引进行操作
POST 索引名/_bulk ...可以在 URI 中指定要操作的索引, 也可以在请求中的
_index指定_index若同时在 URL 和 Payload 中都指定了索引, 则以 Payload 中那一条具体操作指定的索引为准.
支持四种类型操作
- index
- create
- delete
- update
- 每一条操作的执行不影响其他操作
- 批量操作也需要避免一次操作太多, 导致给 ES 集群压力太大.
返回结果中包含各个操作的结果
{ "took" : 2089, "errors" : false, "items" : [ // 操作结果 ... ] }
mget 批量读取
批量操作可以减少网络连接所产生的开销, 提高性能.
// 这是一个示例
GET _mget
{
"docs": [
{"_id":"1"},
...
]
}- 可以在 URI 中指定要操作的索引, 也可以在请求的 Payload 中的
_index指定 返回结果包含所有文档内容
{ "docs" : [ // 各个文档(当然也有可能是没找到) ... ] }
msearch 批量查询
// 示例
POST _msearch
{"index":"kibana_sample_data_ecommerce"}
{"query":{"match_all":{}},"size":1}
{"index":"kibana_sample_data_flights"}
{"query":{"match_all":{}},"size":2}- 可以在 URI 中指定要操作的索引, 也可以在请求的 Payload 中的
_index指定
常见错误返回
倒排索引介绍
倒排索引的核心组成
这里没有局限在 ES, 而是一个通用的倒排索引的核心组成.
倒排索引主要包含两个部分
单词词典(Term Dictionary): 记录所有文档的单词, 记录单词到倒排列表的关联关系
- 单词词典一般比较大, 可以通过 B+ 树或哈希拉链法实现, 以满足高性能的插入与查询
倒排列表(Posting List)
倒排索引项(Posting)
- 文档 ID
- 词频 TF - 该单词在文档中出现的次数, 用于相关性评分
位置 Position - 单词在文档中分词的位置. 用于语句搜索 (phrase query)
注意这是单词的位置, 而不是字节/字符位置.
偏移 Offset - 记录单词的开始结束位置, 实现高亮显示
字节/字符位置.
ElasticSearch 的倒排索引
- ElasticSearch 的 JSON 文档中的每个字段, 都有自己的倒排索引.
可以指定对某些字段不做索引
- 优点: 节省存储空间
- 缺点: 字段无法被搜索
通过 Analyzer 进行分词
Analysis 与 Analyzer
Analysis(
[ə'næləsɪs]): 分析器. 文本分析把全文本转换成一系列单词(term / token) 的过程(这个操作也叫分词).- Analysis 使用 Analyzer 来实现具体的分词.
- 可使用 ES 内置的分析器, 或按需定制分析器.
- 除了数据写入时转换词条, 匹配 Query 语句时也需要用相同的分析器对查询语句进行分析.
Analyzer(
['ænəˌlaɪzə]): 分词器.- Character Filters
- Tokenizer
- Token Filter
Analyzer 分词器
Analyzer 的组成部分
Analyzer 分词器是专门处理分词的组件.
Analyzer 主要有三部分组成
- Character Filters
针对原始文档处理, 例如去除 html
- Tokenizer
按照规则切分为单词
- Token Filter
将切分的单词进行加工, 小写, 删除 stopwords, 增加同义词等操作.
Analyzer = CharFilters(0个或多个) + Tokenizer(恰好一个) + TokenFilters(0个或多个)
_analyze API
测试某个 Analyzer 的分词效果
GET _analyze { "analyzer": "具体分词器名字, 比如: standard", "text": "待测试的文本内容" }测试某个索引的字段的分词效果
POST 索引名/_analyze { "field": "字段名", "text": "..." }测试自定义分词器的效果
POST _analyze { "char_filter": [], "tokenizer": "指定某个 tokenizer, 比如: standard", "filter": ["指定 Token Filter, 比如: lowercase"],
}
#### ElasticSearch 的内置分词器
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停止词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Patter Analyzer - 正则表达式,默认\W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
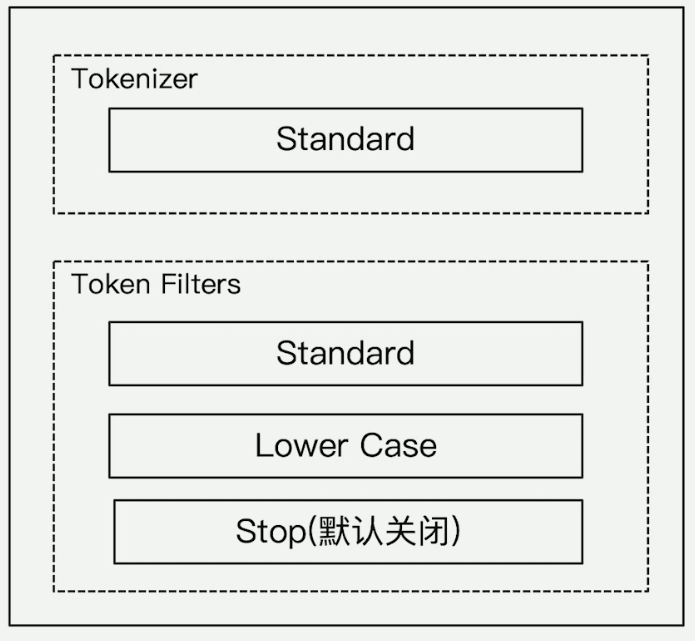
##### standard (默认的分词器)
行为
1. 按词切分
2. 小写处理
3. 默认未启用 Stop 停止词过滤
GET _analyze
{
"analyzer": "standard",
"text": "............."
}
##### simple
行为
1. 按照非字母切分
2. 去除非字母部分
3. 小写处理
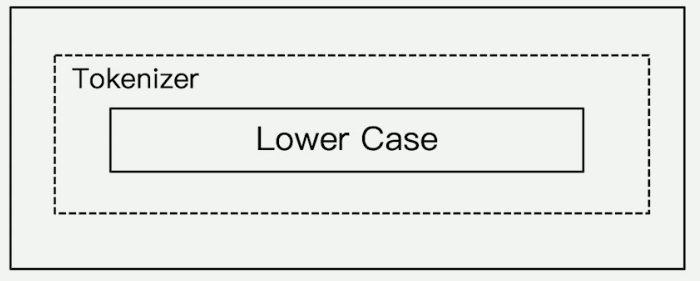
GET _analyze
{
"analyzer": "simple",
"text": "......."
}
##### whitespace
行为
1. 按照空白切分

GET _analyze
{
"analyzer": "whitespace",
"text": "........"
}
##### stop
> stop 分词器在 simple 分词器基础上增加了 stop filter.
1. 按照非字母切分
2. 去除非字母部分
3. 小写处理
4. 去除 stop (停止词) 部分
> 会把 the, a , is, in, ... 等修饰性词语去除
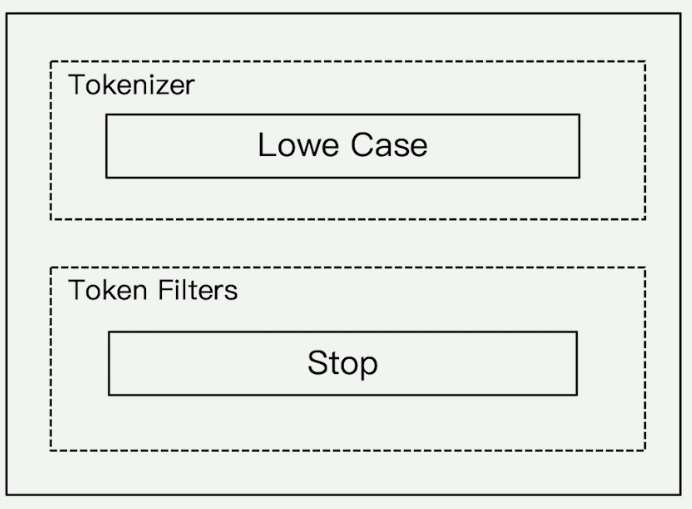
GET _analyze
{
"analyzer": "stop",
"text": "....."
}
##### keyword
行为
1. 不分词
直接将输入当做一个 term 输出
当不需要对输入进行分词时, 可以选择 keyword 分词器.
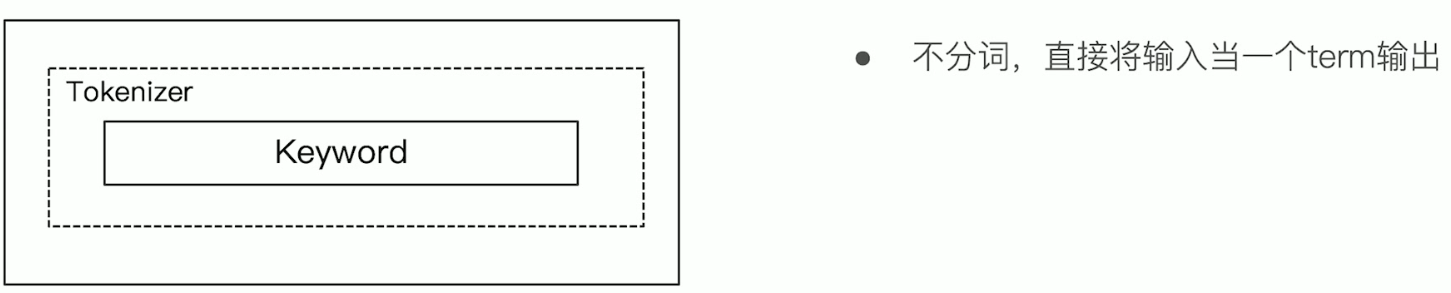
GET _analyze
{
"analyzer": "keyword",
"text": "..."
}
##### pattern
行为
1. 通过正则表达式分词
> 默认是 `\W+`, 即 `[^a-zA-Z0-9_]`, 对非单词字符进行分割
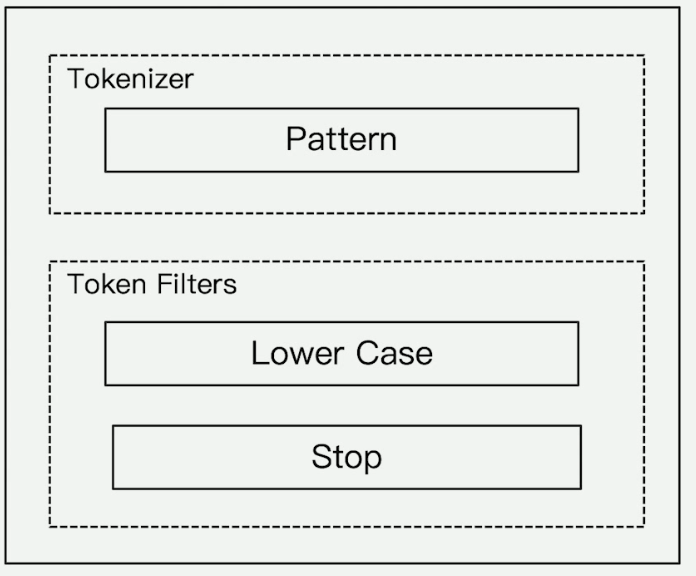
GET _analyze
{
"analyzer": "pattern",
"text":"..."
}
##### language

GET _analyze
{
"analyzer": "english",
"text": "..." // running 会转为 run, foxes 复数转化为单数的 fox, evening 转化为 even, ....
}
#### 中文分词
ES 默认提供的分词对于中文不友好, 只会将中文句子切分成一个一个"字", 而不是"词".
##### ⭐IK
https://github.com/medcl/elasticsearch-analysis-ik
- 支持自定义词库, 支持热更新分词字典
- 提供
- Analyzer: `ik_smart` , `ik_max_word`
- Tokenizer: `ik_smart` , `ik_max_word`
安装
ELK_VERSION=7.9.1
bin/elasticsearch-plugin install "https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v${ELK_VERSION}/elasticsearch-analysis-ik-${ELK_VERSION}.zip"
7.9.3
elasticsearch-plugin install "https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip"
如果上面的安装方式不行, 那么可以尝试用解压缩的方式直接安装(具体参见 ik 项目的 markdown)
##### THULAC
> ... ES 版的都没在维护, 忽略吧
https://github.com/microbun/elasticsearch-thulac-plugin
- THU Lexucal Analyzer for Chinese, 清华大学自然语言处理和社会人文计算实验室的一套中文分词器
##### ICU
提供了 Unicode 的支持, 更好的支持亚洲语言
安装
bin/elasticsearch-plugin install analysis-icu
## SearchAPI 概览
### 指定查询的索引

### Search API 类型
ES 主要提供两种 Search API
- URI Search
- Request Body Search
// 搜索所有索引
GET /_search
// 搜索多个索引(逗号分隔)
GET /index1,index2/_search
// 搜索符合命名的多个索引
// * 是通配符
GET /indexname*/_search
// 搜索单个索引
GET /indexname/_search
#### URI Search
在 URL 中使用查询参数
- 使用 `q` 指定查询字符串
- "query string syntax", KV 键值对

#### Request Body Search
使用 ES 提供的基于 JSON 格式的更加完备的 DSL(领域查询语言)

### 搜索结果部分字段说明
返回结果中部分字段说明
- `took`: 花费的时间
- `hits.total`: 符合条件的总文档数
- `hits.hits`: 结果集, 默认返回前 10 个文档
- `hits.hits.$._score`: 文档的相关度评分
### 搜索结果的相关性 Relevance
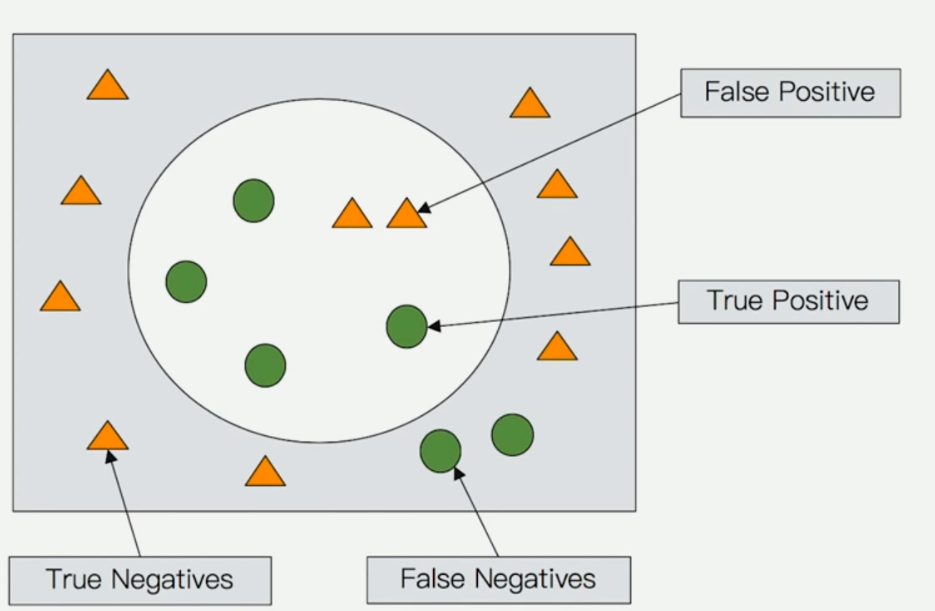
衡量相关性
- Precision(查准率)
无关文档越少越好
- Recall(查全率)
相关的文档越多越好
- Ranking
能够按照相关度排序
使用 ES 的查询和相关的参数可以改善搜索的 Precision 和 Recall
$$
Precision = \frac{True Positive}{实际的返回结果集}
$$
$$
Recall = \frac{True Positive}{所有应返回的结果集}
$$
## URISearch 详解
### 通过 URI Query 实现搜索
GET movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s
{
"profile": "true"
}
- `q` 指定查询语句, 使用 Query String Syntax
- `df` 默认字段, 不指定时会对所有字段进行查询
- `sort` 排序
- `from` 和 `size` 用于分页
- `profile: true`: 输出查询的执行计划
### Query String Syntax
> 以下以查询 `movies` 索引为例.
- 指定字段 vs 泛查询
// 泛查询(对所有字段应用各种类型的查询)
GET movies/_search?q=2012
// 指定字段
GET movies/_search?q=title:2012
- Term vs Phrase
// 其中的 "Mind" 部分是泛查询(即此时是对文档中所有字段查询 "Mind")
GET movies/_search?q=title:Beautiful Mind
// Phrase查询: 使用引号
GET movies/_search?q=title:"Beautiful Mind"
- 分组与引号
// 分组, Bool 查询
GET movies/_search?q=title:(Beautiful Mind)
// 引号, Phrase
GET movies/_search?q=title:"Beautiful Mind"
- 布尔操作
AND / OR / NOT 或者 `&&` / `||` / `!`
> 注意必须大写
// 布尔 AND
// Title 必须同时包含 Beautiful 和 Mind
GET movies/_search?q=title:(Beautiful AND Mind)
// 布尔 NOT
// Title 必须包含 Beautiful, 但不能包含 Mind
GET movies/_search?q=title:(Beautiful NOT Mind)
- 分组
- `+` 表示 must
- `-` 表示 must_not
// 布尔 must
// Title 必须包含 Mind
// %2B 是加号的 urlencode
GET movies/_search?q=title:(Beautiful %2BMind)&sort=_score:asc
- 范围查询
- `[]` 闭区间
- `{}` 开区间
GET movies/_search?q=year:[* TO 2018]
- 算术符号
GET movies/_search?q=year:>=1980
GET movies/_search?q=year:(>=1980 AND <=2018)
GET movies/_search?q=year:(%2B>1980 %2B<=2018)
- 通配符查询
> 查询效率低, 占用内存大, 不建议使用(特别是放在最前面)
- `?` 表示1个字符
- `*` 表示任意个字符
// 通配符匹配
GET movies/_search?q=title:b*
- 正则表达式
GET movies/_search?q=title:/[abc]eautifu.?/
- 模糊匹配与近似查询
// 模糊匹配&近似度匹配
// 这里输入 beautifl 是一个错误的单词, 但通过近似度匹配能够匹配到
// 这里的 ~1 表示允许有一个字母有差别, 即 match_phrase 的 slop:1
GET movies/_search?q=title:beautifl~1
// 模糊匹配&近似度匹配
// ~2 即 match 的 minimum_should_match: 2
GET movies/_search?q=title:"Lord Rings"~2
## Request Body Search
将查询语句通过 HTTP Request Body 发送给 ES, 这种方式有特定的 DSL.
- 分页
- `from` 从 0 开始
- `size` 默认是 10
- 获取靠后的翻页成本较高
POST kibana_sample_data_ecommerce/_search
{
"from": 10,
"size": 20,
"query": { "match_all": {}}}
- 排序 `sort`
- 最好在 "数字型" 与 "日期型" 字段上排序
- 因为对于多值类型或分析过的字段排序, 系统会选一个值, 无法得知该值.
POST kibana_sample_data_ecommerce/_search
{
"sort": [{"order_date": "desc" }],
"query": { "match_all": {}}}
- `_source` filtering
> source filte 只是传输给客户端时进行过滤, 在 ES 节点间的数据传输(Fetch 等)还是会传输 _source 中的数据
- 如果 _source 没有存储, 那就只返回匹配的文档的元数据
- _source 支持使用通配符 ` _source: ["name*", "desc*"]`
POST kibana_sample_data_ecommerce/_search
{
"_source": ["order*", "customer*"],
"query": {"match_all": {}}}
- 脚本字段 `script_fields`
POST kibana_sample_data_ecommerce/_search
{
"script_fields": {
"新字段名": {
"script": {
"lang": "painless",
"source": "doc['currency'].value + ' ' + doc['taxful_total_price'].value"
}
}
},
"_source": ["currency", "taxful_total_price"],
"query": {"match_all": {}}}
### Match Query
查询表达式 Match
- operator
match 中的项(terms)之间, 默认的关系是 OR
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query.html
POST movies/_search
{
"query": {
"match": {
"title": {
"query": "Last Christmas" // 此时解释为 Last OR Christmas
}
}}
}
// 上面查询的简写
POST movies/_search
{
"query": {
"match": {
"title": "Last Christmas"
}}
}
// 完整书写
POST movies/_search
{
"query": {
"match": {
"title": {
"query": "Last Christmas", // 此时解释为 Last AND Christmas
"operator": "AND" // 默认是 OR
}
}}
}
### Match Phrase Query
短语搜索 Match Phrase
> 这也是属于全文搜索
match_phrase 的 terms 之间是 and 的关系, 并且 terms 之间位置关系也影响搜索的结果
POST movies/_search
{
"query": {
"match_phrase": {
"title": {
"query": "one love",
"slop": 1 // 默认是 0
}
}}
}
match 与 match_phrase 的区别
- match 中的 terms 之间是 or 的关系
- match_phrase 的 terms 之间是 and 的关系, 并且 terms 之间位置关系也影响搜索的结果
## QueryString & SimpleQueryString 查询
### Query String
类似 URI Query
POST users/_search
{
"query": {
"query_string": {
"default_field": "name",
"query": "Ruan AND yiMing"
}},
"profile": "true"
}
POST users/_search
{
"query": {
"query_string": {
"fields": ["name", "about"],
"query": "(Ruan AND yiMing) OR (Java AND Elasticsearch)"
}},
"profile": "true"
}
### Simple Query String
- 类似 Query String, 但会忽略部分错误的语法, 同时只支持部分查询语法
- 不支持查询文本中的 `AND`, `OR`, `NOT`, 这些会被视为普通字符串处理
- Term 之间的默认关系是 OR, 可以指定 Operator
- 支持部分逻辑
- `+` 替代 AND
- `-` 替代 NOT
- `|` 替代 OR
// Simple Query 默认的 operator 是 OR
// 会忽略查询内容中的 AND, OR
POST users/_search
{
"query": {
"simple_query_string": {
"fields": ["name", "about"],
"query": "Ruan AND yiMing"
}},
"profile": "true"
}
POST users/_search
{
"query": {
"simple_query_string": {
"fields": ["name", "about"],
"query": "Ruan yiMing",
"default_operator": "AND"
}},
"profile": "true"
}
## DynamicMapping 和常见字段类型
### Mapping
Mapping 类似数据库中的 schema 的定义, 作用如下:
- 定义索引中的字段的名称
- 定义字段的数据类型, 例如字符串, 数字, 布尔...
- 字段、倒排索引的相关配置, (Analyzed or Not Analyzed,Analyzer)
Mapping 会把 JSON 文档映射成 Lucene 所需要的扁平格式.
一个 Mapping 属于一个索引的 Type
- 每个文档属于一个 Type
- 每个 Type 都有一个 Mapping 定义
> 7.0 开始, 一个索引只能有一个默认的 Type(_doc).
### Dynamic Mapping
- 在写入文档时, 如果索引不存在, 会自动创建索引
- Dynamic Mapping 的机制, 使得我们无需手动定义 Mappings. ES 会自动根据文档信息, 推算出字段的类型
> 但有时候会推算错误, 例如地理位置信息
- 当类型设置不对时, 会导致一些功能无法正常运行, 例如 Range 查询.
**类型的自动识别**
| JSON 类型 | ES 类型 |
| --------- | ------------------------------------------------------------ |
| 字符串 | 匹配日期格式(`2018-07-24T10:29:48.103Z`), 会识别成 Date
匹配数字, 默认视为字符串, 可通过配置识别为 float 或 long
默认设置为 Text, 并且增加 keyword 子字段 |
| 布尔值 | boolean |
| 浮点数 | float |
| 整数 | long |
| 对象 | Object |
| 数组 | 由第一个非空数值的类型所决定 |
| 空值 | 忽略 |
### 字段的数据类型
数据类型
- 简单类型
- `text` / `keyword`
- `date`
- `integer` / `float` / `byte` / `short` / `scaled_float` / `half_float`
- `long` / `double`
- `boolean`
- IPv4 & IPv6
- 复杂类型 - 对象和嵌套对象
- 对象类型 `object` / 嵌套类型 `nested`
- 特殊类型
- `geo_point` & `geo_shape` / percolator
### 能否更改 Mapping 的字段类型
**需要分两种情况**
1. 新增加字段
- dynamic = true 时, 一旦有新增文档的字段写入, mapping 也会同时更新(指新增该字段)
- dynamic = false 时, mapping 不会被更新, 此时新增的字段不会被索引, 但这些字段信息会出现在 _source 中
- dynamic = "strict" 时, 文档写入直接失败.
2. 对于已有字段
- 一旦有数据写入, 就不再支持修改字段定义
> Lucene 实现的倒排索引, 一旦生成后, 就不允许修改
如果需要改变字段类型, 必须 Reindex API 以重建索引.
**原因**
- 如果修改了字段的数据类型, 会导致已被索引的字段无法被索引
- 但如果是增加新的字段, 就不会有这样影响
### 控制 Dynamic Mappings
| dynamic 的值 | true | false | "strict" |
| -------------- | ---- | ----- | -------- |
| 文档可索引 | Y | Y | N |
| 字段可索引 | Y | N | N |
| Mapping 被更新 | Y | N | N |
- 当 dynamic 设置成 false 时, 包含新字段的文档可以被写入, 但仅 mapping 中已存在的字段会被索引, 新增字段不会被索引.
- 当 dynamic 设置成 "strict" 时, 包含新字段的文档写入直接出错.
// 将 dynamic 设置为 false (默认是 true)
// 此时后续新增的字段不会被自动索引
PUT 索引名/_mapping
{
"dynamic": false
}
// 将 dynamic 设置为 strict
PUT 索引名/_mapping
{
"dynamic": "strict"
}
## 显式设置 Mapping 设置与常见参数
PUT 索引名
{
"mappings": {
"properties": {
// 定义属性字段
"属性名": {
"type": "类型",
// ... 其他属性配置
}
},
// 定义其他 mapping 设置
...}
}
### 自定义 Mapping 的一些建议
- 参考 API 手册, 纯手写
- 为了减少输入的工作量, 减少出错概率, 可以依照以下步骤
1. 创建一个临时的 index, 写入一些样本数据
2. 通过访问 Mapping API 获得该临时文件的动态 Mapping 定义
3. 修改上述获得的 Mapping 定义后, 使用该配置创建自己的索引
4. 删除临时索引
### 字段属性设置
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-params.html
所有的字段属性
#### `enabled` 配置项
默认为 true.
当设置为 false 时, 该字段仅做存储(保存于`_source`), 但不支持对该字段搜索和聚合分析.
使用场景示例:
- 使用 ES 存储 web session, 仅需要对 session_id 和 last_updated 这两个字段进行搜索, 但对于具体的 session 数据不需要查询及聚合操作, 此时就可以将 session data 的 enabled 设置为 false.
PUT my-index-000001
{
"mappings": {
"properties": {
"user_id": {
"type": "keyword"
},
"last_updated": {
"type": "date"
},
"session_data": {
"type": "object",
"enabled": false
}
}
}}
#### `index` 配置项
控制当前字段是否被索引(倒排索引), 默认为 true.
若设置为 false, 则该字段不会被索引, 无法被搜索到(仍可以进行聚合分析)
这个主要用来避免创建索引, 节省空间.
PUT 索引名
{
"mappings": {
"properties": {
"属性名":{
"type": "...",
"index": false // 此时该字段不会被索引.
}
}}
}
#### `norms` 配置项
该配置项用于控制是否存储算分相关数据, 默认为 true.
若该字段不需要算分(score), 而仅仅是用于过滤(filter)或聚合分析(Aggregation), 那么可以关闭(设置为 false)以节约存储.
#### `doc_values` 配置项
> 排序, 聚合, 在Script中访问字段值需要不同于倒排索引的数据访问模式(需要获取该文档中该字段的值是多少, 而不仅仅是倒排索引中提供的哪个文档包含该字段), ES 提供了 doc value 和 fielddata 这两种方式来实现这一数据访问模式.
该配置项用于控制是否创建对应的 Doc Value, 对于大部分字段类型都有效(除了 text 和 annotated_text), 默认为 true.
Doc Value 是存放在磁盘上的数据结构(理解为正排索引即可), 当文档索引时创建, 用于支持排序和聚合分析.
> text 和 annotated_text 需手动设置 field_data 为 true 才可使用.
若该字段不需要排序, 不需要聚合, 不需要通过Script访问字段值时, 可以将其设为 false 以节省空间并提高性能.
#### `fielddata` 配置项
> 排序, 聚合, 在Script中访问字段值需要不同于倒排索引的数据访问模式(需要获取该文档中该字段的值是多少, 而不仅仅是倒排索引中提供的哪个文档包含该字段), ES 提供了 doc value 和 fielddata 这两种方式来实现这一数据访问模式.
该配置项用于控制是否启用 fielddata 这一数据结构, 该数据结构是在查询时才创建的仅存放在内存中的数据结构, fielddata 在 text 类型的字段上默认为 false.
> 这里的查询指: 该字段第一次用于排序, 聚合, 以及在脚本中使用时创建的.
fielddata 会消耗大量的 heap 空间, 且消耗额外的性能使得延迟上升, 因此对于 text 默认是不开启的.
在对 text 类型字段开启 fielddata 前需要谨慎考虑, 看能否用其他方案来代替: 比如多字段(text + keyword 子字段的组合)
#### `store` 配置项
是否额外存储该字段的值, 默认是不存储的.
> 但是ES中的字段通常会存储在 _source 中.
#### `coerce` 配置项
是否开启数据类型的自动转换(例如字符串转数字), 默认开启.
#### `multifield` 配置项
多字段特性
#### `dynamic`
true(默认)/false/strict
控制 Mapping 的自动更新规则
#### `index_options` 配置项
- Index Options 选项可以控制倒排索引记录的内容. 不同级别记录的内容不一样:
- `docs` 记录 doc id
- `freqs` 记录 doc id 和 term frequencies
- `positions` 记录 doc id / term frequencies / term position
- `offsets` 记录 doc id / term frequencies / term position / character offsets
> 我的理解是, 若是为了高亮搜索结果中的匹配字段, 则需要 character offsets 信息
- Text 字段类型默认记录 `positions` 级别, 其他默认为 `docs`
- 记录的内容越多, 占用存储空间越大
PUT 索引名
{
"mappings": {
"properties": {
"属性名":{
"type": "...",
"index_options": "offsets"
}
}}
}
#### `null_value` 配置项
- 当需要对 null 值实现搜索时可以配置该项
> 索引文档时, 字段的值为 null, 默认会被忽略.
- 只有 keyword 类型支持设置该配置项
PUT 索引名
{
"mappings": {
"properties": {
"属性名":{
"type": "keyword",
"null_value": "NULL"
}
}}
}
POST 索引/_doc
{
"属性名": null // 若为 null, 默认情况下该字段会被忽略. 在配置了 null_value 后, 其值被视为 "NULL" 字符串(但 _source 中保存的是 null)
}
GET 索引/_search
{
"query": {
"match": {
"属性名": "NULL" // 搜索时, 使用 "NULL" 表示搜索 null 值
}}
}
#### `copy_to` 配置项
> _all 在 ES 7 被 copy_to 所替代
- 该配置项用于满足一些特定的搜索需求
- copy_to 将字段的数值拷贝到目标字段, 实现类似 _all 的作用
- copy_to 的目标字段不会出现在 _source 中
PUT 索引名
{
"mappings": {
"properties": {
"属性名":{
"type": "...",
"copy_to": "另一个属性名"
}
}}
}
GET users/_search
{
"query": {
"match": {
"另一个属性名":"..."
}}
}
ES 中不提供专门的数组类型, 但是任何字段都可以包含多个同类型的数值.
示例:
PUT users/_doc/1
{
"name":"onebird",
"interests":["music","reading"]
}
// 其对应的 mapping 如下
{
"users" : {
"mappings" : {
"properties" : {
"interestst" : {
"type" : "text", // dynamic mapping 设置该字段是 "text" 类型.
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}}
}
## 多字段特性及Mapping中配置自定义Analyzer
### 多字段特性
默认的 dynamic mapping 会为 text 字段类型增加一个 keyword 子字段.
多字段提供的特性
- 可以用于实现精确匹配
- 可以使用不同的 analyzer
- 不同语言
- pinyin 字段的搜索
- 支持为搜索和索引指定不同的 analyzer
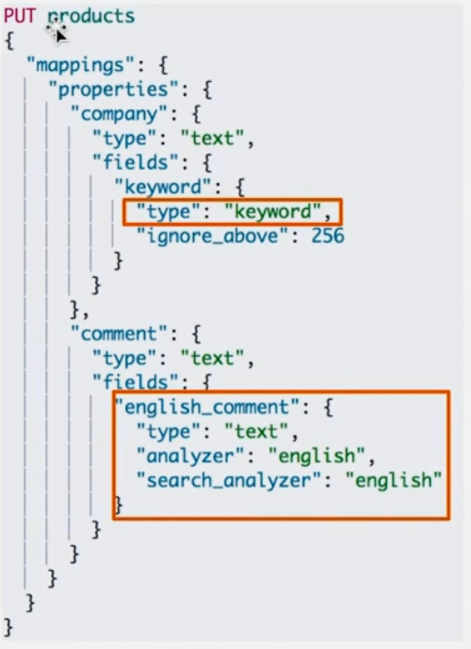
- 比如 "company" 存入的是 "厦门市XX网络有限公司", 对于 text 字段分词(ik_smart)后是 "厦门市", "XX", "网络", "有限公司", 那么使用 term 对 `company` 字段查询 "厦门市XX网络有限公司" 是无法获取到结果的. 但是使用 term 对 `company.keyword` 字段查询 "厦门市XX网络有限公司" 则可以精确匹配到.
### 精确值(Exact Values) vs 全文本(Full Text)
Exact Values
- 数字 / 日期 / 具体的一个字符串(例如 "Apple Store")
- ES 中的 keyword
- Exact Value 字段在索引时不需要做特殊的分词处理.
全文本
- 非结构化的文本数据
- ES 中的 text
示例图
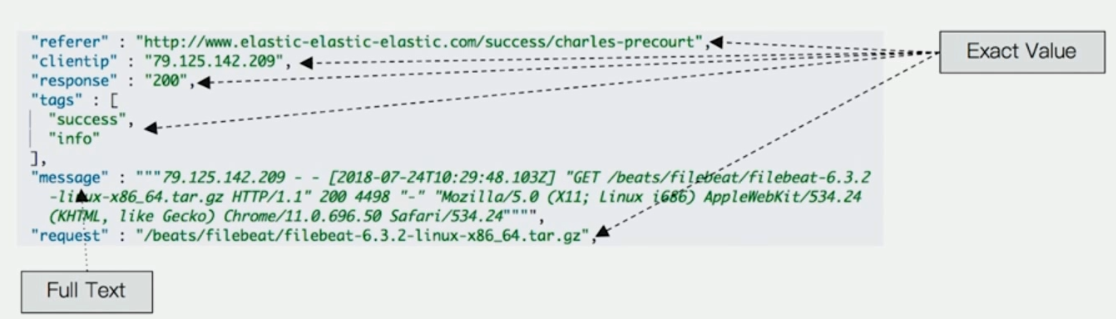
- 其中只有 "message" 字段需要全文本匹配
### 自定义分词器
当 [ES 自带的分词器](https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html)无法满足时, 可以自定义分词器: 组合不同的组件.
Analyzer = CharFilters(0个或多个) + Tokenizer(恰好一个) + TokenFilters(0个或多个)
示例
PUT 索引名
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer":{
"type": "custom",
"char_filter": [
"emoticons"
],
"tokenizer": "punctuation",
"filter": [
"lowercase",
"english_stop"
]
}
},
"char_filter": {
"emoticons": {
"type": "mapping",
"mappings": [":) => _happy_", ":( => _sad_"]
}
},
"tokenizer": {
"punctuation":{
"type": "pattern",
"pattern": "[ .,!?]"
}
},
"filter": {
"english_stop":{
"type":"stop",
"stopwords": "_english_"
}
}
}}
}
示例

#### Character Filters
在 Tokenizer 之前对文本进行处理, 例如增加删除及替换字符. 会影响 Tokenizer 的 position 和 offset 信息.
可以配置多个 Character Filters.
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-charfilters.html
部分自带的 Character Filters
- `html_strip`: 去除 html 标签
- `mapping`: 字符串替换
- `patter_replace`: 正则匹配替换
POST _analyze
{
"char_filter": [
// 去除 html 标签
"html_strip",
// 字符串替换
{
"type": "mapping",
"mappings": ["- => _", ":) => happy", ":( => sad"]
},
// 正则匹配替换
{
"type": "pattern_replace",
"pattern": "https?://(.*)",
"replacement": "$1"
}],
"tokenizer": "...",
"filter": [...],
"text": "......"
}
#### Tokenizer
将原始的文本按照一定的规则, 切分为词(term or token).
可以用 Java 开发插件实现自己的 Tokenizer.
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html
ES 内置的部分 Tokenizers
- whitespace
- standard
- uax_url_email
- pattern: 正则分词
POST _analyze
{
"tokenizer": {
"type": "pattern",
"pattern": "[ .,!?]"
},
"text": "..."}
- keyword
- path hierarchy: 文件路径分词
确保整个路径上任意一个路径都可以匹配到.
POST _analyze
{
"tokenizer": "path_hierarchy",
"text": "/user/path/to/php"}
#### Token Filters
将 Tokenizer 输出的单词(term) 进行增加, 修改, 删除
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenfilters.html
自带的部分 Token Filters
- lowercase: 转小写
- stop: 移除停止词
- synonym: 添加近义词
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-synonym-tokenfilter.html
POST _analyze
{
"filter": ["lowercase", "stop"],
"text": "/user/path/to/php"
}
## IndexTemplate 和 DynamicTemplate
> 生产环境中, 索引应考虑禁止 Dynamic Index Mapping,避免过多字段导致 Cluster State 占用过多.
>
> 同时应禁止索引自动创建的功能,创建时必须提供 Mapping 或通过 Index Template 进行设定
>
> ```
> // 禁止自动创建索引
> action.auto_create_index: false
> ```
>
>
### Index Template: 应用于新增索引
Index Template(索引模板) 可应用于符合条件的所有新创建索引.
- index template 仅对新创建的索引有效, 不会影响已存在的 index
- 可设定多个 index template, 这个设置会合并, 按照 order 从低到高依次覆盖.
当一个索引被新创建时:
1. 应用 ES 默认的 settings 和 mappings
2. 应用 order 数值低的 Index Template 中的设定
3. 应用 order 高的 index template 中的设定, 依次覆盖
4. 应用创建索引时, 用户手动指定的 Settings 和 Mappings 会覆盖之前模板中的设定
// 对所有新创建的索引生效(但好像 "*" 这样的设置有问题, ES 7.9.1 版本的一直提示 deprecated 啥的)
PUT _template/template_default
{
"index_patterns": ["*"],
"order": 0,
"version": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1}
}
// 创建的 index template 可对新创建的名为 "test*" 的索引生效
PUT _template/template_test
{
"index_patterns": ["test*"],
"order": 1,
"version": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 2},
"mappings": {
"date_detection": false,
"numeric_detection": true}
}
### Dynamic Template: 应用于新增字段
Dynamic Template 支持在具体的索引上指定规则, 为新增加的字段指定相应的 Mappings
具体是定义在某个索引的 `mappings.dynamic_templates` 中, 可以根据 ES 识别的数据类型, 结合字段名称来动态设定字段类型.
- template 有名称
- 匹配规则是一个数组
- 可以为匹配到的字段设置 mapping
比如
- 将指定数据类型的统一设定为其他类型
- 关闭某一特定类型
- 字段名称符合通配符匹配的设置为特定类型
示例
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"strings_as_boolean": {
"match_mapping_type": "string", // 匹配 string 类型
"match": "is*", // 匹配 is 作为字段名前缀的
"mapping": {
"type": "boolean" // 转换为 boolean 类型
}
}
},
{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]}
}
PUT my_index/_doc/1
{
"firstName": "Ruan", // dynamic mapping 会应用 dynamic template, 令该字段类型为 keyword
"isGm": "true" // 该字段类型会转化为 boolean
}
示例
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"full_name": {
"path_match": "name.*", // 匹配 name 对象下的所有字段
"path_unmatch": "*.middle", // 不匹配 任意对象下的 middle 字段
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
]}
}
PUT my_index/_doc/1
{
"name":{
"first":"John", // text 类型, 并 copy_to "full_name"
"middle": "Winston", // 按照默认 dynamic mapping 处理
"last": "Lennon" // text 类型, 并 copy_to "full_name"}
}
## 聚合分析(Aggregation)简介
> 在下一份笔记中有更详细的介绍.
ES 除了查询外, 还提供了针对 ES 数据进行**高实时性**的统计分析功能.
> 不像 Hadoop 的 T+1 那样处理.
通过聚合, 我们会得到一个数据的概览, 是分析和总结全套的数据, 而不是寻找单个文档.
> 包括 Kibana 的可视化报表都是利用 ES 的聚合分析功能.
### 聚合的方式
- Bucket Aggregation: 一些列满足特定条件的文档的集合
- 可以包含嵌套关系
- Term & Range (时间 / 年龄区间 / 地理位置)
- Metric Aggregation: 一些数学运算, 可以对文档字段进行统计分析
- Metric 会基于数据集计算结果, 除了支持在字段进行计算, 同样支持在脚本(painless script)产生的结果上进行计算
- 大多数 Metric 是数学计算, 仅输出一个值
- min / max / sum / avg / cardinality
- 部分 metric 支持输出多个数值
- stats / percentiles / percentile_ranks
- Pipeline Aggregation: 对其他的聚合结果进行二次聚合
- Matrix Aggregation: 支持对多个字段的操作并提供一个结果矩阵
### 示例
#### *示例: Term bucket 聚合*
// 按照目的地进行分桶统计
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": { // 关键词 aggs
"flight_dest": { // 自定义名字
"terms": { // 不同类型的分析, terms 是分桶
"field": "DestCountry"
}
}}
}
// 结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]},
"aggregations" : {
"flight_dest" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 3187,
"buckets" : [
{
"key" : "IT",
"doc_count" : 2371
},
......
]
}}
}
#### *示例: Term bucket 聚合 + min/max/avg 数学聚合*
// 查看航班目的地的统计信息, 增加平均, 最高最低价格
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"flight_dest": {
"terms": {
"field": "DestCountry"
},
"aggs": {
"avg_price": {
"avg": {
"field": "AvgTicketPrice"
}
},
"max_price": {
"max": {
"field": "AvgTicketPrice"
}
},
"min_price": {
"min": {
"field": "AvgTicketPrice"
}
}
}
}}
}
// 结果
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]},
"aggregations" : {
"flight_dest" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 3187,
"buckets" : [
{
"key" : "IT",
"doc_count" : 2371,
"max_price" : {
"value" : 1195.3363037109375
},
"min_price" : {
"value" : 100.57646942138672
},
"avg_price" : {
"value" : 586.9627099618385
}
},
.......
]
}}
}
#### *示例: Term bucket 聚合 + stats 数学聚合*
// 价格统计信息 + 天气信息
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"flight_dest": {
"terms": {
"field": "DestCountry"
},
"aggs": {
"stats_price":{
"stats": {
"field": "AvgTicketPrice"
}
},
"weather": {
"terms": {
"field": "DestWeather"
}
}
}
}}
}
// 结果
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]},
"aggregations" : {
"flight_dest" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 3187,
"buckets" : [
{
"key" : "IT",
"doc_count" : 2371,
"weather" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Clear",
"doc_count" : 428
},
{
"key" : "Sunny",
"doc_count" : 424
},
{
"key" : "Rain",
"doc_count" : 417
},
{
"key" : "Cloudy",
"doc_count" : 414
},
{
"key" : "Heavy Fog",
"doc_count" : 182
},
{
"key" : "Damaging Wind",
"doc_count" : 173
},
{
"key" : "Hail",
"doc_count" : 169
},
{
"key" : "Thunder & Lightning",
"doc_count" : 164
}
]
},
"stats_price" : {
"count" : 2371,
"min" : 100.57646942138672,
"max" : 1195.3363037109375,
"avg" : 586.9627099618385,
"sum" : 1391688.585319519
}
},
.......
]
}}
}
#### *示例: range bucket 聚合 + percentiles 百分位数聚合*
// 价格区间分桶
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"price_range": {
"range": {
"field": "AvgTicketPrice",
"ranges": [
{
"from": 0,
"to": 200
},
{
"from": 200,
"to": 500
},
{
"from": 500,
"to": 800
},
{
"from": 800
}
]
}
},
"price_percentile": {
"percentiles": {
"field": "AvgTicketPrice",
"percents": [
10,
15,
50,
80,
95,
99
]
}
}}
}
// 结果
{
"took" : 18,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]},
"aggregations" : {
"price_range" : {
"buckets" : [
{
"key" : "0.0-200.0",
"from" : 0.0,
"to" : 200.0,
"doc_count" : 749
},
{
"key" : "200.0-500.0",
"from" : 200.0,
"to" : 500.0,
"doc_count" : 3662
},
{
"key" : "500.0-800.0",
"from" : 500.0,
"to" : 800.0,
"doc_count" : 4689
},
{
"key" : "800.0-*",
"from" : 800.0,
"doc_count" : 3959
}
]
},
"price_percentile" : {
"values" : {
"10.0" : 262.04359058107656,
"15.0" : 311.0302956493907,
"50.0" : 640.3530744687757,
"80.0" : 884.7514024612299,
"95.0" : 1035.021676508585,
"99.0" : 1167.0564943695067
}
}}
}
# ES入门总结









