java多线程-学习总结(完整版)
java多线程
- 线程和进程
- 线程的生命周期
-
- 新建New
- 就绪&运行 Runable&Runnging
- 阻塞Blocked
- 等待 waiting
- 计时等待Time waiting
- 销毁Terminated
- 线程池概念和多线程使用场景
- 线程池的参数解析
-
- 线程池阻塞队列BlockingQueue
- 线程池工厂ThreadFactory
- 线程池拒绝策略RejectedExecutionHandler
- JDK Executors线程池的几种实现方式
-
- 创建类型简单解析
-
- newCachedThreadPool
- newFixedThreadPool(附加源码解析)
- 线程池的参数设置方案
-
- 动态设置参数
- 总结&反思
- Spring boot使用线程池
- 参考资料
线程和进程
进程是系统进行资源调度和分配的基本单元,是操作系统的基础。线程是系统调度的最小单元,是进程的运算单元。一个进程可能包含一个或者多个线程。
线程的生命周期
线程的生命周期分别六个:新建、就绪&运行、阻塞、等待、计时等待、销毁

新建New
线程的创建有几种方式:Thread类创建、实现Runnable接口、Callable和Future创建
# 1、thread
new Thread() {
@Override
public void run() {
}
}.start();
# runnable
public class RunnableThread implements Runnable {
@Override
public void run() {
System.out.println("runnable thread");
}
public static void main(String[] args){
Thread t = new Thread(new RunnableThread());
t.start();
}
}
# Callable&Future
public class CallableThread implements Callable {
@Override
public Integer call() throws Exception {
System.out.println("Callable Thread return value");
return 0;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask future = new FutureTask(new CallableThread());
new Thread(future).start();
System.out.println(future.get());
}
}
其实,比较细心看的话,最终都是Runnable一种方式实现,下面我们一起来解读Thread的部分源码:
1、为啥线程有如上介绍的六种状态呢,这是线程 Thread对象定义的java.lang.Thread.State枚举属性
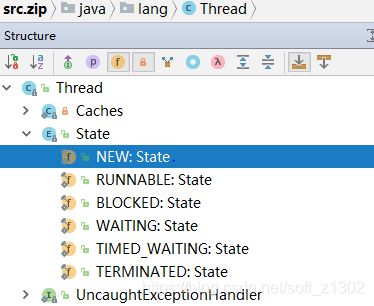
每种状态的意义和实现方式英文中都描述很清楚。其实个人以前初学线程时,还有一些疑问,为啥要用线程以及执行线程的start和run方法区别在哪,接下来个人感官解读一下源码流程:
线程初始化方法:
/**
* Initializes a Thread.
*
* @param g 线程组,是维护线程树的对象,所有线程必须具备的属性要素,这里可以判断线程是否具有相应的权限,以及是否合法,线程状态,是否守护线程等;目标是维护一组线程和线程组,同时我们要注意的线程之前的通讯是局限于线程组,是一组线程中维护的线程**
* @param target 运行线程的对象,线程执行时拿到的run或者call方法的目标对象
* @param name 当前线程名称
* @param stackSize 新建线程时栈大小,当为0时可忽略
*
* @param acc 上下文权限控制
*/
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc) {
// ………… 省略部分代码
/*获取安全管理策略,主要用来检查权限相关因素,若权限不满足时,抛出异常SecurityException,启动时是通过jvm参数设置[java.security.manager],具体可查看 [java API](https://docs.oracle.com/en/java/javase/15/docs/api/java.base/java/lang/SecurityManager.html)*/
SecurityManager security = System.getSecurityManager();
if (g == null) { // 当java.security.manager不设置时,这里为空
// 若需要安全管理策略,直接取得线程组
if (security != null) {
g = security.getThreadGroup();
}
// 不存在父级树寻找
if (g == null) {
g = parent.getThreadGroup();
}
}
// 检查权限
g.checkAccess();
/*
* 检测是否能被实力构造和重写
*/
if (security != null) {
if (isCCLOverridden(getClass())) {
security.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION);
}
}
// 以便垃圾回收,增加未启动线程数
g.addUnstarted();
// 设置是否守护线程,线程优先级,安全控制,执行目标,堆栈长度以及线程id等
………… 省略部分代码
}
接下来讲解一下直接执行run和start方法区别,执行run是居于现有jvm的当前线程执行方法体。执行start是居于jvm所在的进程分配资源,创建栈帧空间出来创建新的执行单元。分配问栈帧空间之类,在当前栈帧空间调用Thread的run方法,进而run调用传入的target的run方法(有兴趣的可以解读open jdk的start0方法)。
# Thread#run
@Override
public void run() {
if (target != null) {
target.run(); // runnable
}
}
就绪&运行 Runable&Runnging
当我们新建线程完后执行start才进入就绪状态Runnable,线程内部调用了run方法时进入运行阶段Running,但是直接执行run方法不是启动线程,具体如下验证。
public class RunStartThread extends Thread {
public RunStartThread(String name) {
super(name);
}
@Override
public void run() {
System.out.println(System.currentTimeMillis());
try {
sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
RunStartThread rst = new RunStartThread("runThread");
rst.run(); // 主线程运行run方法
rst.start(); // 启动子线程运行run
}
}
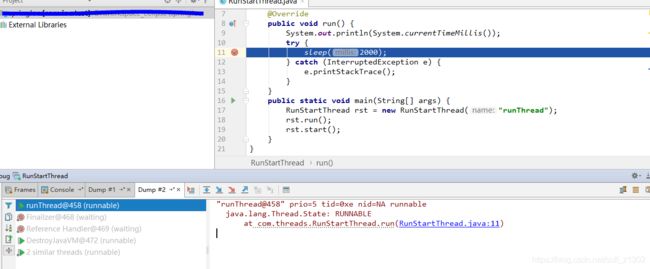
运行如上代码的run方法抓取线程dump如下图,我们观察线程名称是"main"

当运行start方法时,我们再抓取dump时,发现目前正在运行的线程名称是我自定义的线程名称runThread,此外我们发现start并不是直接调用runnable的run,而是调用本地方栈中的start0,让jvm来处理线程调度。
阻塞Blocked
线程进入blocked状态时一般是自动等待后进入运行状态或者直接死亡结束,一般导致blocked的是synchronized,如下代码示例,因此我们开发时主要尽量不要使用synchronized,原因有是锁匙自动释放不可控,此外是单线程运行,同一对象不能同时运行,如果真需要控制线程安全性的编程,尽量用Lock:
public class BlockThreads {
public static void main(String[] args) throws InterruptedException {
TestThread th = new TestThread();
th.runThread(th,"Thread1");
th.runThread(th,"Thread2");
th.runThread(th,"Thread3");
System.out.println("111");
}
private static class TestThread {
public synchronized void sayHello() throws InterruptedException {
System.out.println(System.currentTimeMillis());
Thread.sleep(3000);
}
public void runThread(TestThread th, String threadName) {
new Thread(threadName) {
@Override
public void run() {
try {
th.sayHello();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}.start();
}
}
}
等待 waiting
导致线程处于等待的方法有Object#wait(Object#notify或者Object#notifyAll恢复)、Thread#join以及LockSupport#park(LockSupport#unpark),这里导致处于等待状态时CPU是释放出资源的。
计时等待Time waiting
Object#wait(time)、LockSupport#parkNanos、以及LockSupport#parkUntil等待时间,其实Time waiting概念我们使用到很多场景,比如nginx调优,线程销毁时间的调优,请求并发时超时时间的设置。有效的设置超时时间有利于提高系统的吞吐量
销毁Terminated
线程销毁有自动销毁和手动销毁,自动销毁即线程自己执行完run方法后,JVM就会销毁线程,手动销毁可以使用Thread#stop方法销毁,但是此方法已经废弃,因为是暴力手段,可能内部JVM监控信息也无法监控,Thread#interrrupted方法进行销毁判断,若不能销毁,则会发生InterruptedException异常
线程池概念和多线程使用场景
线程是执行单元,线程池即一组执行单元组成的集体,也就是线程的一种使用方式,线程池用来维护线程的启动、服用、调度机制。在多核CPU和多任务调度时,我们可以用线程池来处理多线程,提高CPU的使用同时控制CPU高压,提高性能和避免阻塞。比如短信发送,http请求,定时任务,异步调用之类。
线程池的参数解析
JDK自带的创建线程对象是ThreadPoolExecutor,对象中有几个参数分别为:核心线程数、最大数线程数、线程存活时间、线程工厂、线程拒绝策略。如下源码
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
具体几个含义有简单文字简介:核心线程数corePoolSize是运行的线程数,当同一时间线程数量大于核心线程数时,线程进入等待队列workQueue,超出等待队列时将会有新建非核心的线程(maximumPoolSize-corePoolSize)执行,当线程数量大于maximumPoolSize+workQueue#size时,将会发生拒绝策略,具体拒接策略后面再讨论。引用美团技术团队的图美团技术团队

线程池阻塞队列BlockingQueue
JDK自带的常见的等待队列有LinkedBlockingQueue、ArrayBlockingQueue、SynchronousQueue(而外提及一点队列长度是可以动态改变的哦,比如LinkedBlockingQueue的capacity设置为volatile)
- LinkedBlockingQueue是链表节点存储,FIFO模型,链表类型存储当然是无界限,一般设置这个时,最大线程数基本无效,因为永远不会超出长度,除非发生OOM异常,在大量等待线程的高并发条件下建议采用此阻塞队列。
- ArrayBlockingQueue 指定长度等待队列,此有点是比较精确的设置数据队列来实现等待队列。
- SynchronousQueue 无缓存等待队列,队列始终为0,此操作一般是无界操作,充分利用CPU的使用率,比如Executors#newCachedThreadPool就是用次方法实现。
线程池工厂ThreadFactory
常用开源项目线程池工厂有CustomizableThreadFactory、ThreadFactoryBuilder、BasicThreadFactory,工厂方法主要设置线程的优先级和线程名之类的线程属性,这里就不细讲解了,主要如下简单实用例子:
ublic class ThreadFactoryTest implements ThreadFactory {
private final AtomicInteger threadCount = new AtomicInteger(0);
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(2, 2, 60L, TimeUnit.SECONDS, new LinkedBlockingDeque(), new ThreadFactoryTest());
executor.submit(() -> {
System.out.println(String.format("thread-Name = %s,Thread priority = %d",
Thread.currentThread().getName(), Thread.currentThread().getPriority()));
});
executor.submit(() -> {
System.out.println(String.format("thread-Name = %s,Thread priority = %d",
Thread.currentThread().getName(), Thread.currentThread().getPriority()));
});
}
/**
* @param r 传入的线程
**/
@Override
public Thread newThread(Runnable r) {
Thread th = new Thread(r);
th.setPriority(2);
th.setName("设置线程名前缀" + this.threadCount.incrementAndGet());
return th;
}
}
线程池拒绝策略RejectedExecutionHandler
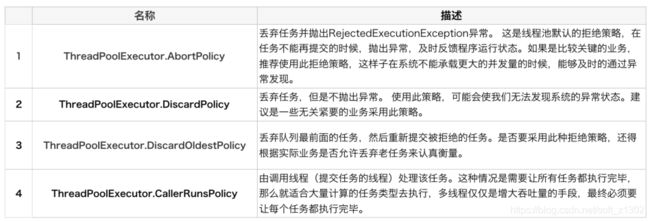
JDK常见的拒绝策略AbortPolicy中止策略、CallerRunsPolicy超出时执行run、DiscardPolicy超出时丢弃、DiscardOldestPolicy丢弃队列最后一个。
JDK Executors线程池的几种实现方式
Executors是工具类(一般s后最都是工具类,比如Arrays,Systems,Collections,Objects等),废话多说,Executors创建线程的方法有newFixedThreadPool,newCachedThreadPool(ThreadPoolExecutor主要源码解析),newScheduledThreadPool,newSingleThreadExecutor,newSingleThreadScheduledExecutor。
创建类型简单解析
newCachedThreadPool
newCachedThreadPool提供两个构造方法实现,一个无参构造Executors#newCachedThreadPool();,一个有参构造 Executors#newCachedThreadPool(ThreadFactory threadFactory)
优点:核心线程数设置为0,意思CPU有空闲时,有线程进入则马上进入执行状态,等待队列为无界同步等待队列SynchronousQueue,即多CPU的情况下充分利用,其实综合上面两个因素可知最大线程数设置相当于无效,因此充分利用多核CPU的特性。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
缺点:高并发时导致CPU占用100%,其他线程任务无法处理,还有长期CPU高压会发热导致高温。我们系统建议CPU使用不要超过80%,常态不要超过60%。下面来介绍其中两个执行方法以及附加源码解析
newFixedThreadPool(附加源码解析)
Executors#newFixedThreadPool固定大小的线程池,即设置核心线程数和最大线程数一样。等待队列是无界线性等待队列。这里有个优点是充分利用线程的复用。至于为啥呢,当然是解读源码见证:
AbstractExecutorService#submit方法创建任务FutureTask并调用ThreadPoolExecutor#execute:
public Future submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture ftask = newTaskFor(task, null); // 新建future任务
execute(ftask);
return ftask;
}
接下来重点解析ThreadPoolExecutor#executor里的执行方法,分三步走(这里提到一个点,线程数量和状态时通过AtomicInteger的32位的ctl,高三位是状态保存,低29是线程池的最大数量):
int c = ctl.get();/* 获取主线程状态控制29位变量 */
if (workerCountOf(c) < corePoolSize) { /* 前29位作为统计线程数,判断worker是否大于核心线程数 */
if (addWorker(command, true)) /* 添加worker工作线程,若新建成功则执行线程,并返回true */
return;
c = ctl.get(); /* 再次检测当前线程地位29 */
}
if (isRunning(c) && workQueue.offer(command)) { // worker无法获取和创建,插入等待队列
int recheck = ctl.get(); // 再次检测线程池worker大小
if (! isRunning(recheck) && remove(command)) // 若线程池不可运行状态,且移除当前线程成功,则拒绝策略
reject(command);
else if (workerCountOf(recheck) == 0) // 若当前没有线程worker,即核心线程为0,则立即执行队列
addWorker(null, false);
}
else if (!addWorker(command, false)) // 队列已经满了,则直接添加非核心线程并运行
reject(command); // 运行或者创建非核心线程失败,则拒绝策略
通过上面分析可知,线程池的状态保存是高三位,低29位保存运行线程数量。
接下来重点讲worker和task
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
// ……………… 省略部分代码
for (;;) {
// ……………… 省略部分代码
// 这里判断最大worker数,查看是核心线程还是最大线程,若超出范围直接返回创建worker失败
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c)) // 创建worker前检测后并增加运行线程数
break retry;
}
}
// …………
Worker w = null;
try {
// 新建worker,同时调用ThreadFactory的newThread进而线程池的参数,比如参数名称等
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock; // 获取线程池锁
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
// 判断是否有效范围内
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); // 创建worker成功后直接调用线程的start方法执行线程,并且返回成功,调用worker启动后将会执行run方法。
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
经过代码分析最终都是worker来调度任务,当线程数大于核心线程数时,worker传入的线程为空,此时需要执行的任务放在队列的workQueue中(即new Worker->start worker -> runWork -> getTask - > runTask),真理就在我们如下runWorker方法。这里有一个“提交优先级概念”,先执行核心线程task != null再执行getTask(),意思队列溢出的线程其实是优先执行。因为如上代码execute讲解溢出队列直接直接addworker优先于队列的添加。
/*
worker启动时,委托给主线程的runWorker
*/
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
// ………省略部分代码
// 获取当前任务,当时非核心时且添加进队列时为null,需要从队列中获取
Runnable task = w.firstTask;
// …………
/* 当任务为空,且队列也不为空是,不执行 */
while (task != null || (task = getTask()) != null) {
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null; //这个地方非常关键,执行完后队列中查找。
w.completedTasks++;
w.unlock();
}
}
线程池的参数设置方案
我们一般考虑的两个因素是CPU还有IO,一般参数设置都是针对CPU密集型和IO密集型,但是还要结合实际业务场景分析,比如业务耗时,tps之类的因素合理分配核心线程数和最大线程数,最好动态设置参数(JDK支持动态调整核心线程数和最大线程数以及等待队列的长度,再结合apollo配置中心动态更新再好不过了,如美团技术团队)
CPU密集型,核心线程数设置为CPU有效个数+1,最大线程数设置为因为2×CPU有效个数+1,可能有些假死。
IO密集型即核心线程数为2×CPU有效个数,最大线程数为25×CPU有效个数,具体如下
动态设置参数
动态设置线程池的大小有利于处理高峰问题以及调优线程池数据,采取方法是ThreadPoolExecutor#setCorePoolSize动态设置核心线程数,interruptIdleWorkers可以清空空闲的worker以便占用资源,如下代码所示:
public void setCorePoolSize(int corePoolSize) {
if (corePoolSize < 0)
throw new IllegalArgumentException();
int delta = corePoolSize - this.corePoolSize; // 设置的核心线程数和原来的差值
this.corePoolSize = corePoolSize;
if (workerCountOf(ctl.get()) > corePoolSize) // 工作worker是否大于设置的核心线程数,如果大于则当worker空余时清空。
interruptIdleWorkers(); // 这方法其实很重要,我们可以用来设置回收没有使用的核心线程数,
else if (delta > 0) { // 若设置线程数大于原有线程数,则看队列是否有等待线程,如果有则直接循环创建worker并执行task任务,知道worker大于最大线程数或者队列已空
// We don't really know how many new threads are "needed".
// As a heuristic, prestart enough new workers (up to new
// core size) to handle the current number of tasks in
// queue, but stop if queue becomes empty while doing so.
int k = Math.min(delta, workQueue.size());
while (k-- > 0 && addWorker(null, true)) {
if (workQueue.isEmpty())
break;
}
}
}
总结&反思
1、addWorker(Runnable firstTask, boolean core) 新建worker,此方法的参数firstTask为空时,居于预热的功能,类似于spring的懒加载
2、setCorePoolSize动态设置核心线程数
3、setMaximumPoolSize 动态设置最大线程数
4、CPU密集型和IO密集型
5、runWorker worker执行任务
6、interruptIdleWorkers销毁空闲核心线程
7、Executors创建线程方式newFixedThreadPool、newCachedThreadPool、newScheduledThreadPool、newSingleThreadExecutor
8、execute和submit执行优先级和提交优先级,以及两者区别是有返回值之类。
9、创建线程的几种方式Thread、runnable、Callable和future,以及线程都有哪些状态,对于JVM的栈调试的使用
10、常见阻塞线程LinkedBlockingQueue、ArrayBlockingQueue、SynchronousQueue
11、常见的线程工厂CustomizableThreadFactory、ThreadFactoryBuilder、BasicThreadFactory以及目的
12、RejectedExceptionHandler常见几个实现类AbortPolicy、CallerRunsPolicy、DiscardPolicy、DiscardOldestPolicy
13、如何动态设置核心线程数和最大线程数以及阻塞队列
14、ThreadGroup、securityManager有什么意思
15、后续追加………………
Spring boot使用线程池
这里制作简单实用,详细使用还得结合实际场景:
@SpringBootTest
@EnableAsync
class PoolApplicationTests {
@Autowired
private PoolService poolService;
@Test
void contextLoads() {
poolService.say1();
poolService.say2();
}
}
@Service
public class PoolService {
@Value("${spring.pool.core.size:5}")
private int coreSize;
@Value("${spring.pool.max.size:10}")
private int maxNumSize;
/**
* 自定义线程池
*
* @return
*/
@Bean("executor")
public Executor executor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(coreSize);
executor.setMaxPoolSize(maxNumSize);
executor.setQueueCapacity(20);
executor.initialize();
return executor;
}
/**
* 在目标线程池执行任务
*/
@Async(value = "executor")
public void say1() {
System.out.println(Thread.currentThread().getName());
}
@Async(value = "executor")
public void say2() {
System.out.println(Thread.currentThread().getName());
}
}
参考资料
【1】JDK 1.8 源码
【2】美团技术团队(部分图片引用和知识点)
【3】线程和进程百度百科