[TOC]
Query DSL (官方文档整理)
https://www.elastic.co/guide/...
复合查询
https://www.elastic.co/guide/...
bool
The default query for combining multiple leaf or compound query clauses, as must, should, must_not, or filter clauses. The must and should clauses have their scores combined — the more matching clauses, the better — while the must_not and filter clauses are executed in filter context.
boosting
Return documents which match a positive query, but reduce the score of documents which also match a negative query.
constant_score
A query which wraps another query, but executes it in filter context. All matching documents are given the same “constant” _score.
dis_max
A query which accepts multiple queries, and returns any documents which match any of the query clauses. While the bool query combines the scores from all matching queries, the dis_max query uses the score of the single best- matching query clause.
function_score
Modify the scores returned by the main query with functions to take into account factors like popularity, recency, distance, or custom algorithms implemented with scripting.
Geo 查询
Shape 查询
Joining 查询
基于全文的查询
https://www.elastic.co/guide/...
全匹配查询 match_all
Span 查询
Specialized 查询
Term-level 查询
intervals
A full text query that allows fine-grained control of the ordering and proximity of matching terms.
match
The standard query for performing full text queries, including fuzzy matching and phrase or proximity queries.
match_bool_prefix
Creates a bool query that matches each term as a term query, except for the last term, which is matched as a prefix query
match_phrase
Like the match query but used for matching exact phrases or word proximity matches.
match_phrase_prefix
Like the match_phrase query, but does a wildcard search on the final word.
multi_match
The multi-field version of the match query.
common
A more specialized query which gives more preference to uncommon words.
query_string
Supports the compact Lucene query string syntax, allowing you to specify AND|OR|NOT conditions and multi-field search within a single query string. For expert users only.
simple_query_string
A simpler, more robust version of the query_string syntax suitable for exposing directly to users.
深入搜索
基于词项和基于全文的搜索
基于 Term(词项) 的查询
词项
Term 的重要性
- Term 是表达语义的最小单位.
搜索和利用统计语言模型进行自然语言处理都需要处理 Term
特点
Term Level Query
- Term Query
- Range Query
- Exists Query
- Prefix Query 前缀查询
- Wildcard Query 通配符查询
在 ES 中, Term 查询, 对输入不做分词. 会将输入作为一个整体, 在倒排索引中查找准确的词项, 并且使用相关度算分公式为每个包含该词项的文档进行 相关度算分 - 例如 "Apple Store"
比如对于一个 Text 字段, 在 term 查询时使用大写的文本进行查询, 此时是拿不到结果的, 因此默认情况下该 Text 字段对应的倒排索引中存储的是经过 standard 分词器处理的文本(standard 包含 lowercase character filter).
而对于 Keyword 字段, 倒排索引存储的是原始的数据(比如 "iPhone"), 那么在 term 查询时就必须使用 "iPhone", 而不是 "iphone"
可以通过 Constant Score 将查询转换成一个 Filtering, 避免算分, 并利用缓存, 提高性能.
对于 term 查询, 通常是不需要 score, 这种情况下可以通过 constant_score 将跳过算分的步骤.
term 查询
Term 查询的示例
// productId 和 desc 都是 dynamic mapping 设置的 Text 类型, 且同时存在另一个类型为 keyword 的多字段.
POST products/_bulk
{"index":{"_id":1}}
{"productID":"XHDK-A-1293-#fJ3", "desc":"iPhone"}
{"index":{"_id":2}}
{"productID":"KDKE-B-9947-#kL5", "desc":"iPad"}
{"index":{"_id":3}}
{"productID":"JODL-X-1937-#pV7", "desc":"MBP"}
GET products/_search
{
"query": {
"term": {
"desc": {
"value": "iphone"
// 由于 term 查询不会做分词处理, 而底层存储的是小写处理的(视具体analyzer), 因此使用 iPhone 是无法匹配到文档的.
//"value":"iPhone"
}
}
},
"profile": "true"
}
GET products/_search
{
"query": {
"term": {
"productID": {
"value": "xhdk"
//"value": "XHDK-A-1293-#fJ3"
//"value": "xhdk-a-1293-#fj3"
}
}
}
}多字段 mapping 和 term 查询

多字段特性
- ES 默认会为每个 Text 字段增加一个名为 "keyword" 的 keyword 类型子字段
- 可以利用该子字段来实现精确匹配
复合查询
Constant Score
将 Query 转成 Filter, 忽略 TF-IDF 计算, 避免相关性算分的开销
即便是对 Keyword 进行 Term 查询, 也会进行算分
_score而大多数情况下这种场景是不需要得分的.
- Filter 可以有效利用缓存
示例
POST products/_search
{
// 通过 explain,可以看到 _explanation.description 中没有了 TF, IDF 算分过程
"explain": true,
"query": {
"constant_score": {
"filter": {
"term": {
"productID.keyword": "XHDK-A-1293-#fJ3"
}
}
}
}
}基于全文的查询
https://www.elastic.co/guide/...
特点
全文本查找
Match Query
minimum_should_match: 默认是 1operator: 默认是 OR
Match Phrase Query
slop: 默认是 0
- Query String Query
全文本查询的特点
- 索引和搜索时都会进行分词. 查询字符串先传递到一个合适的分词器, 然后生成一个供查询的词项列表
查询时候会对输入的查询进行分词, 然后每个分词逐个进行底层的查询, 最终将结果进行合并, 并为每个文档生成一个算分.
例如查询 "Matrix reloaded", 会查找包括 Matrix 或 reloaded 的所有结果.
Match Query 的查询过程
- 对待查询文本进行分词
- 对于上述的每个词项(term)到对应的倒排索引查询并打分
- 汇总上述各个查询的得分
- 按照得分排序, 返回结果
结构化搜索
ES 中的结构化搜索(Structured search)
是指对结构化数据的搜索.
- 日期, 布尔类型, 数字: 有精确的格式, 可以进行逻辑操作. 包括比较数字或时间的范围, 或判断两个值的大小
结构化的文本可以做精确匹配或部分匹配
颜色, 标签, 识别码
- Term 查询 / Prefix 前缀查询
- 结构化结果结果只有 "是" 或 "否" 两个值
根据场景需要, 可以决定结构化搜索是否需要打分
对不同结构化数据的搜索
布尔
// 对布尔值查询, 有算分 POST products/_search { "profile": "true", "query": { "term": { "available": { // available 是布尔类型 "value": true } } } }对于不需要算分的, 可以通过 constant score 将查询转为 filter
POST products/_search { "profile": "true", "query": { "constant_score": { "filter": { "term": { "available": { "value": true } } } } } }数字
// 数字 range 查询 GET products/_search { "profile": "true", "query": { "range": { "price": { "gte": 20, "lte": 30 } } } }日期
// 日期 range 查询 GET products/_search { "profile": "true", "query": { "constant_score": { "filter": { "range": { "date": { // 相对时间 "gte": "now-2y" } } } } } }非空
// Exists GET products/_search { "query": { "constant_score": { "filter": { "exists": { "field": "date" } } } } }多值字段
- 多值字段的 term 查询是 "包含" 而不是 "完全相等"
若要"完全相等"的解决方案: 增加一个额外字段进行计数.
// 处理多值字段 POST /movies/_bulk {"index":{"_id":1}} {"title":"Father of the Bridge part II", "year":1995, "genre":"Comedy"} {"index":{"_id":2}} {"title":"Dave", "year":1993, "genre":["Comedy", "Romance"]} GET movies/_mapping POST movies/_search { "query": { "constant_score": { "filter": { "term": { "genre.keyword": "Comedy" // 可以匹配上面两条 } } } } }- 多值字段的 term 查询是 "包含" 而不是 "完全相等"
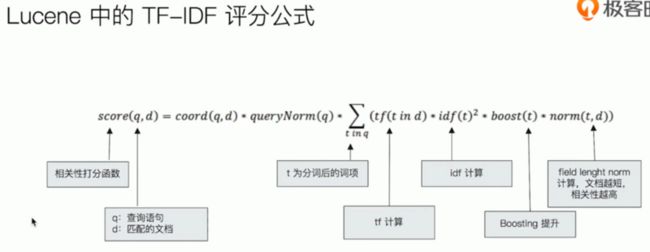
搜索的相关性算分
相关性 Relevance
- 搜索的相关性算分, 描述了一个文档和查询语句匹配的程度(也可以说是 "相似程度"). ES 会对每个匹配查询条件的结果进行算分 _score
打分的本质是排序, 需要把最符合用户需求的文档排在前面.
- ES 5 之前默认的相关性算分采用 TF-IDF
后续的默认采用 BM 25
?
TF-IDF
TF-IDF 被公认是信息检索领域最重要的发明.
- TF-IDF 的本质就是将 TF 求和变成 TF 加权求和.
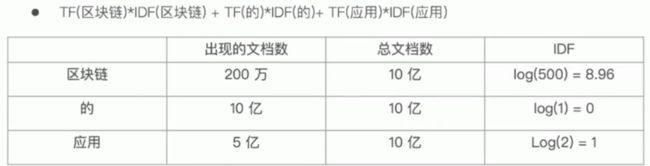
- 现代搜索引擎对 TF-IDF 进行了大量细微的优化.
- 可以通过 Explain API 查看 TF-IDF

词频 TF
- Term Frequency: 检索词在一篇文档中出现的频率 = 检索词出现的次数 / 文档总词数
- 度量一条查询和结果文档相关性的简单方法: 简单将搜索中的每一个词的 TF 进行相加.
- Stop Word
停止词(比如 "的") 在文档中通常会出现多次, 但是对于贡献相关度几乎没有用户, 不用考虑其 TF.
逆文档频率 IDF
Inverse Document Frequency = log(全部文档数 / 检索词出现的文档总数)
- DF: 检索词在所有文档中出现的频率
BM 25


Boosting Relevance

Query & Filter 与多字段查询
Query Context 与 Filter Context
ES 中的搜索提供 Query 和 Filter 这两种不同的 Context:
- Query Context: 相关性算分
- Filter Context: 不需要算分(Yes or No), 可以利用 Cache, 获得更好的性能.
bool 查询
复合查询: bool Query
- 可以是一个或多个查询子句的组合
- 每个查询子句计算的评分会被合并到总的相关性评分中.
共4种子句
Query Context: 贡献得分
must: 必须匹配.should: 选择性匹配.
Filter Context: 不贡献得分
filter: 必须匹配must_not: 必须不匹配.
bool 查询语法
- 子查询可以任意顺序出现
- 可以嵌套多个查询
- 示例语法

- 同一层级下的竞争字段, 具有相同的权重. 通过嵌套 bool 查询, 可以改变对算分的影响.

- should 和 must_not 的搭配可以实现 should_not 的逻辑

Boosting 是控制相关度的一种手段
boost 参数的含义
- boost > 1: 打分的相关度相对性提高
- 0 < boost < 1: 打分的权重相对性降低
- boost < 0: 贡献负分

boostingPOST news/_search { "query": { "boosting": { "positive": { "match": { "content": "apple" } }, // 此时 boost 为 "negative_boost" 的值, 即 0.1 // 也就是搜索结果中包含 juice 的打分的权重相对性会大幅降低. "negative": { "match": { "content": "juice" } }, "negative_boost": 0.1 } } }
比如使用 bool 复合查询时, 同一个查询在文章的 title 和 content 匹配到时的权重可以设置不同, 从而优化搜索结果的相关性.当搜索某些查询的同时要减少其他特定类型查询时, 也可以使用 boosting 来实现.
单字符串多字段查询: dis_max
对多个字段同时查询相同内容时, 有以下几种策略
使用 bool 查询的 should
POST blogs/_search { "query": { "bool": { "should": [ { "match": { "title": "Brown fox" } }, { "match": { "body": "Brown fox" } } ] } } }算分过程
- 查询 should 语句中的两个查询
- sum 两个查询的评分
- 乘以匹配语句的总数
- 除以所有语句的总数
这种方式在有些情况下(查询内容在每个字段上都有, 都每个的相关度都不高)会使相关度较低的评分反而相对更高.
使用 disjunction max query
POST blogs/_search { "query": { "dis_max": { "tie_breaker": 0.2, "queries": [ { "match": { "title": "brown fox" } }, { "match": { "body": "brown fox" } } ] } } }算分过程
- title 和 body 字段互相竞争, 这里会取单个最佳匹配的字段的评分
- 将其他匹配字段的评分与 tie_breaker 相乘
- 对以上评分求和并规范化
- 使用下面的 multi_match
关于 Tier Break
- 这是一个介于 0~1 之间的浮点数.
- 0 代表使用最佳匹配
- 1代表所有语句(匹配字段)都同等重要
单符串多字段查询: multi_match
Multi Match 是一种支持在多字段上进行查询的语法.
https://www.elastic.co/guide/...
共有三种使用场景
最佳字段 (Best Fields)
这是默认类型.
当字段之间相互竞争, 又相互关联. 例如 title 和 body 这样的字段. 评分来自最匹配字段.
POST blogs/_search { "query": { "multi_match": { "type": "best_fields", // 这是默认的 type, 可以省略不写 "query": "Quick pets", "fields": ["title", "body"], "tie_breaker": 0.2, "minimum_should_match": "20%" // minimum_should_match 等参数可以传递到生成的 query 中 } } }与 DisMaxQuery 的主要区别在于, MultiMatch 是专门用于单字符串多字段查询, 但 DisMaxQuery 并不局域于此.
多数字段 (Most Fields)
- 处理英文内容时, 一种常见的手段是, 在主字段(Analyzer: english) 抽取词干, 加入同义词以匹配更多的文档. 同时加入子字段(analyer: standar)以提供更加精确的匹配. 其他字段作为匹配文档提高相关度的信号. 匹配字段越多则越好.
- 不支持 operator ??
PUT titles { "mappings": { "properties": { "title": { "type": "text", "analyzer": "english", // english 分词器会将不同时态的词统一抽取词干, 以匹配更多的文档, 但同时也会导致精确度降低, 时态信息丢失. "fields": { // 这里创建了一个子字段, 名为 "std", 使用 "standard" 分词器. "std":{"type": "text", "analyzer": "standard"} } } } } } GET titles/_search { "query": { "multi_match": { "query": "barking dogs", "type": "most_fields", "fields": ["title^10", "title.std"] // 同时匹配主字段和子字段, 同时这里设置 title 的 boost 为 10 来提高 title 字段的重要性. } } }
用广度匹配字段 title, 包括尽可能多的文档, 以提高召回率. 同时有使用字段 title.std 作为信号将相关度更高的文档置于结果顶部.
-
- 每个字段对于最终评分的贡献可以通过自定义值 boost 来控制.
跨字段搜索 (Cross Fields)
- 对于某些实体, 例如人名, 地址, 图书信息. 需要在多个字段中确认信息, 单个字段只能作为整体的一部分. 希望在任何这些列出的字段中找到尽可能多的词.
- 支持 operator
无需使用 copy_to 即可实现跨字段搜索, 同时支持搜索的内容在所有字段中出现(通过设置 operator: "AND")
copy_to 需要消耗额外的存储空间
- 相比 copy_to, 它的另一个优势是可以在搜索时指定不同字段的权重.
POST address/_search { "query":{ "multi_match":{ "query": "Poland Street W1V", // 其中 Poland 是在 "street" 字段, W1V 是在 "postcode" 字段 "type": "cross_fields", "operator": "AND", "fields": ["street", "city", "country", "postcode"] } } }
多语言及中文分词与检索
自然语言与查询 Recall
提升自然语言查询的召回率(Recall) 常用优化策略
- 归一化词元: 清除变音符号, 如 rǒle 时也会匹配 role
抽取词根: 清除单复数和时态的差异
比如增加一个使用 analyzer: english 的子字段.
- 包含同义词
- 拼写错误: 拼写错误, 或者同音异形词
混合多语言的挑战
多语言场景
- 不同的索引使用不同的语言
- 同一个索引中, 不同的字段使用不同的语言
- 同一个字段内混合不同的语言
混合语言常见的问题
- 词干提取: 以色列文档包含了希伯来语、阿拉伯语、俄语、英语.
- 不正确的文档频率: 比如在英文为主的文章中, 德文算分高(因为稀少)
- 用户语言识别(Compact Language Detector): 需要判断用户搜索时的语言
分词的挑战
- 英文分词: You're 分成一个还是多个? Half-baked 是要分成两个词?
中文分词
- 分词标准: 标准不一样, 比如姓名是否要分开, 具体情况需制定不同的标准.
- 歧义(组合型歧义, 交集型歧义, 真歧义)
中文分词
中文分词法的演变
- 字典法
最小词数的分词理论
无法解决二义性问题
统计语言模型
解决了二义性问题
- 基于统计的及其学习算法
常用的算法是 HMM, CRF, SVM, 深度学习等算法.
以及基于神经网络的分词器等.
中文分词器以统计语言模型为基础, 到今天基本可以看作是已经解决的问题.
- 不同分词器的好坏, 主要差别在于数据的使用和工程使用的精度.
常见的分词器都是使用机器学习算法和词典相结合
机器学习: 提高分词准确率
词典: 改善领域适应性
HanLP
一个面向生产环境的自然语言处理工具包
同样提供 ES 版本
https://github.com/KennFalcon...


IK 分词器
https://github.com/medcl/elas...

Pinyin Analysis
https://github.com/medcl/elas...

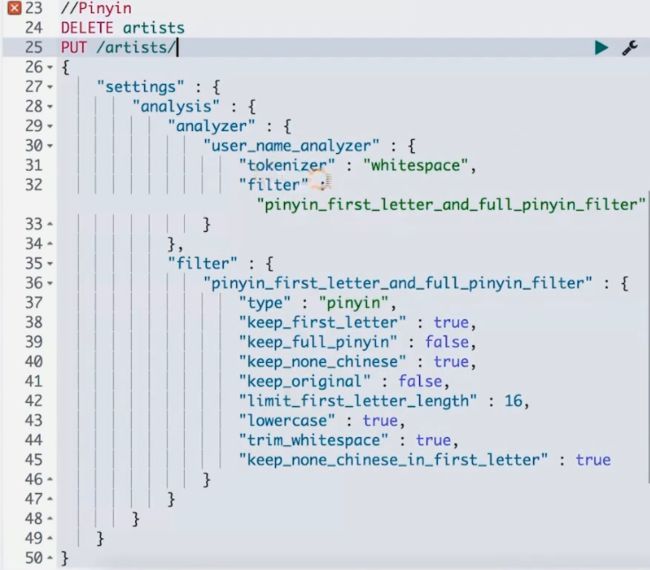
Space Jam, 一次全文搜索的实例
TMDB 数据库
- 创建于 2008 年, 电影的 Meta Data 库.
- 提供 API, 总共有超过20万开发人员和公司在使用
测试的一般步骤(使用脚本处理)
选择合适的 mapping
- 分词器
- 多字段属性
- reindex 数据(delete, index)
选择合适的查询(可通过高亮来显示结果, 方便比较查询效果)
- 同义词
- 为字段设置不同的权重
- 查询并高亮显示结果
- 分析搜索结果, 重复步骤 1
测试相关性: 理解原理 + 多分析 + 多调整测试.
注意不要过度调试相关度, 而是要监控搜索结果, 监控用户点击最顶端结果的频次.
将搜索结果提高到极高水平的唯一途径:
- 需要具有度量用户行为的强大能力
- 可以在后台实现统计数据, 比如用户的查询和结果, 有多少被点击了
- 哪些搜索没有返回结果
使用 Search Template 和 Index Alias 查询
Search Template
Search Template 的主要目的是为了解耦程序和搜索 DSL
各司其职, 解耦开发人员, 搜索工程师, 性能工程师.
https://www.elastic.co/guide/...
在开发初期, 虽然可以明确查询参数, 但往往还不能确定查询的DSL的最终版本, 此时可以通过创建 Search Template.
开发人员直接使用 Search Template, 传入参数. 若后续 DSL 语句需要优化/变化(不涉及传入参数), 则搜索工程师/性能工程师只需要直接修改 Search Template 即可, 无需修改程序代码.
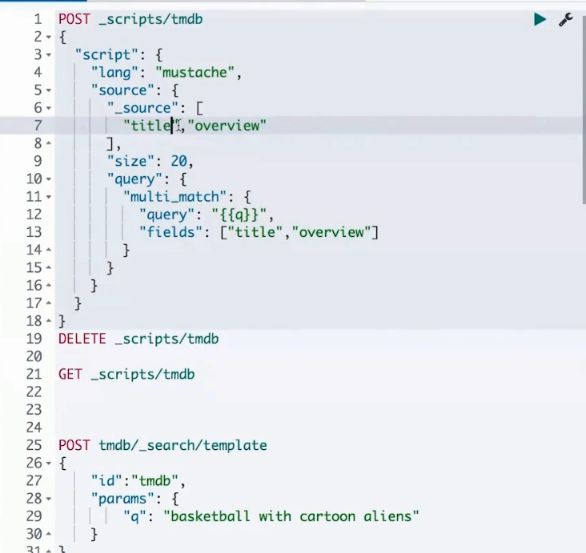
示例
// 创建一个 search template
POST _scripts/
{
"script": {
"lang": "mustache",
"source": {
"query": {
"match": {
"title": "{{query_string}}"
}
}
}
}
}
// 获取一个 search template
GET _scripts/
// 删除一个 search tempalte
DELETE _scripts/
// 使用一个 search template
GET 索引名/_search/template
{
"id": "",
"params": {
"query_string": "search for these words"
}
}
// 或者是不创建 search template, 而是直接当场使用
GET _search/template
{
"source" : {
"query": { "match" : { "{{my_field}}" : "{{my_value}}" } },
"size" : "{{my_size}}"
},
"params" : {
"my_field" : "message",
"my_value" : "foo",
"my_size" : 5
}
} 
Index Alias
Index Alias 主要目的是: 实现零停机的运维.
程序使用 ES 搜索时, 可以指定固定的索引别名, 而无需关心其真实的索引名.
甚至可以为索引别名指定额外条件:

使用索引别名的大致步骤
- 为索引定 一个别名

- 通过索引别名读写数据
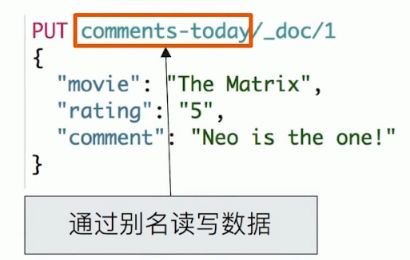
写入实践序列的数据时利用 Index Alias
也可以使用如下方式:
PUT /索引名
{
"aliases": {
"索引别名": {
// "is_write_index": true
.....
}
}
}
// 或这种方式简单创建 index alias
PUT /索引名/_alias/索引别名索引别名参数说明
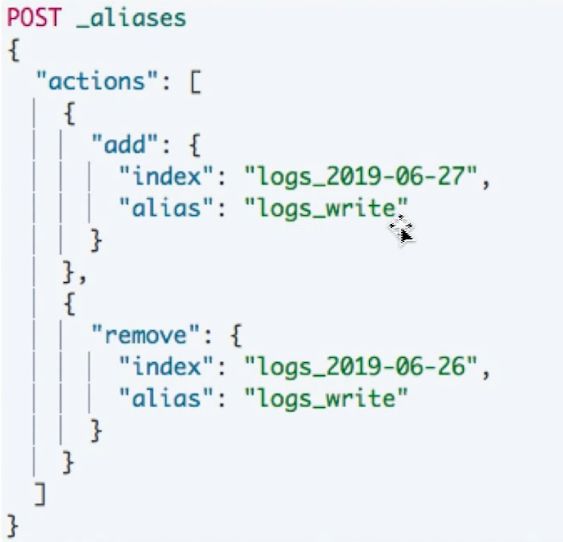
is_write_index: 当别名指向多个索引时, 需配置写到其中哪一个具体索引上(只能指向 1 个索引).默认无需手动配置.
常用的使用场景是在 rollover 时, 别名指向了这一系列所有索引, 但只对最新创建的索引设置
is_write_index: true. 当进行 rollover 操作(此时会创建新索引), 再将 is_write_index 设置到新索引上, 并移除老的索引上的该配置.
综合排序: Function Score Query 优化算分
ES 默认会按照文档相关度算分, 但是仅使用默认的 score 得分排序无法满足某些特定条件.
Function Score Query
Function Score Query: 可以在查询结束后, 对每一个匹配的文档进行一系列重新算分, 并根据新生成的分数进行排序.
计算分值的函数
- Weight: 为每一个文档设置一个简单而不被规范化的权重
Field Value Factor: 使用该数值来修改 _score, 例如将"热度"和"点赞数"作为算分的参考因素
- modifier: 平滑曲线

- factor
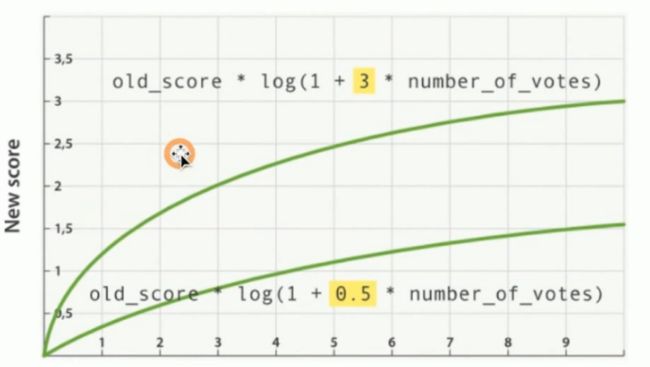
- modifier: 平滑曲线
$$
新的得分 = 原始得分 * 平滑函数(字段值 * factor)
$$
- Random Score: 为每一个用户使用一个不同的随机算分结果
- 衰减函数: 以某个字段的值为标准, 距离某个值越近, 得分越高
- Scirpt Score: 自定义脚本完全控制所需逻辑
Field Value Factor
按受欢迎度提升权重

Boost Mode 和 Max Boost
Boost Mode: 选择合适的最终得分策略
- Multiply: 原始分数与函数值的乘积
- Sum: 原始分数与函数值的和
- Min / Max: 原始分数与函数值取 最小 / 最大值
- Replace: 直接使用函数值取代原始分数
Max Boost: 可以将函数值控制在一个最大值, 避免影响过大.
POST blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": ["title", "content"]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log2p",
"factor": 0.1
},
"boost_mode": "sum", // 指定 Boost Mode: Sum
"max_boost": 3 // 指定 Max Boost: 3
}
}
}一致性随机函数
使用场景: 网站的广告需要提高展现率.
具体需求
- 让每个用户能看到不同的随机排名, 但是也希望同一个用户访问时, 结果的相对顺序保持一致(Consistently Random)

Suggest 搜索
下列不同 Suggest 搜索的比较.
精准度 (Precision)
- Completion
- Phrase
- Term
召回率 (Recall)
- Term
- Phrase
- Completion
性能 (Performance)
- Completion
- Phrase
- Term
Term & Phrase Suggester
搜索建议
- 现代的搜索引擎一般都会提供 Suggest as you type 的功能
- 可以帮助用户在搜索时自动补全或纠错
- 在 google 搜索时, 一开始会自动补全. 当输入到一定长度, 如因为单词拼写错误无法补全, 就会开始提示相似的词或者句子.
ES Suggester API
Suggester 是一种特殊类型的搜索, 并且它需要使用特定的数据类型来支撑 Suggest 搜索.
PUT 索引名 { "mappings": { "properties": { "字段名": { "type": "completion" } } } }- 原理: 将输入的文本分解为 Token, 然后在索引的字典里查找相似的 Term 并返回.
ES 设计了 4 种类别的 Suggesters 供不同场景使用
- Term & Phrase Suggester
- Complete & Context Suggester
Term Suggester
每个建议都包含一个算分, 相似性是通过 Levenshtein Edit Distance 算法实现的.
其核心思想就是一个词改动多少字符就可以和另外一个词一致.
可通过不同的可选参数来控制相似性的模糊程度, 例如 "max_edits"
Suggestion Mode
- Missing: 如索引中已经存在 term, 就不提供建议
- Popular: 推荐出现频率更加高的词
- Always: 无论是否存在, 都提供建议


- body 字段是 completion 数据类型.
Phrase Suggester
Phrase Suggester 在 Term Suggester 上增加了一些额外的逻辑.
一些参数
- Suggest Mode: missing, popular, always
- Max Errors: 最多可以拼错的 Terms 数
- Confidence: 限制返回结果数, 默认为 1


自动补全与基于上下文的提示
Completion Suggester
Completion Suggester 提供了"自动完成"(Auto Complete)的功能. 用户每输入一个字符, 就需要即时发送一个查询请求到后端查找匹配项.
- 并非通过倒排索引来完成, 而是采用了专门的数据结构: 将 Analyze 的数据编码成 FST 和索引一起存放.
- FST会被ES整个加载到内存, 速度很快.
- FST 只能用于前缀查找
定义 Mapping
PUT 索引名
{
"mappings": {
"properties": {
"属性名": {
"type": "completion"
}
}
}
}- type 是
completion - 通过 suggest 查询可以得到搜索建议
suggest 查询
POST 索引名/_search
{
"suggest": {
"此次返回的suggest名": {
"prefix": "前缀匹配内容",
"completion": {
"field": "前面定义的属性名"
}
}
}
}
Context Suggester
Context Suggester 是对 Completion Suggester 的扩展.
- 可以理解为是一种过滤, 在写入数据时定义数据的上下文.
- 在进行 Context Suggest 搜索时可以加入不同的上下文信息.
ES 可以定义两种类型的 Context
- Category: 任意的字符串
- Geo: 地理位置信息
实现 Context Suggester 的具体步骤
- 定制一个 Mappings
- 索引数据, 并且为每个文档加入 Context 信息
- 结合 Context 进行 Suggestion 查询
// 1. 定制一个 Mappings
PUT comments
{
"mappings": {
"properties": {
"comment_autocomplete": {
"type": "completion",
"contexts": [
{"type": "category", "name": "comment_category"}
]
}
}
}
}
// 2. 索引数据, 并且为每个文档加入 Context 信息
POST comments/_doc
{
"comment": "I love the star war movies",
"comment_autocomplete": {
"input": ["star wars"],
"contexts": {
"comment_category": "movies"
}
}
}
POST comments/_doc
{
"comment": "Where can i find a starbucks",
"comment_autocomplete": {
"input": ["starbucks"],
"contexts": {
"comment_category": "coffee"
}
}
}
// 3. 结合 Context 进行 Suggestion 查询
POST comments/_search
{
"suggest": {
"YOUR_SUGGESTION": {
"prefix": "sta",
"completion": {
"field": "comment_autocomplete",
"contexts": {
"comment_category": "coffee"
}
}
}
}
}配置跨集群搜索
为什么需要跨集群搜索
单集群存在的问题
当水平扩展时, 节点数不能无限增加
当集群的 meta 信息(节点, 索引, 集群状态)过多, 会导致更新压力变大, 单个 Active Master 会成为性能瓶颈, 导致整个集群无法正常工作.
多集群方案
- 早期 Tribe Node 方案存在一定问题, 现已被 Deprecated
ElasticSearch 5.3 引入了跨集群搜索的功能(Cross Cluster Search), 推荐使用
- 允许任何节点扮演 federated 节点, 以轻量的方式, 将搜索请求进行代理.
- 不需要以 Client Node 的形式加入其它集群
测试Demo
步骤一: 本机启动 3 个集群
elasticsearch -E node.name=cluster0node -E cluster.name=cluster0 -E path.data=cluster0_data -E discovery.type=single-node -E http.port=9200 -E transport.port=9300
elasticsearch -E node.name=cluster1node -E cluster.name=cluster1 -E path.data=cluster1_data -E discovery.type=single-node -E http.port=9201 -E transport.port=9301
elasticsearch -E node.name=cluster2node -E cluster.name=cluster2 -E path.data=cluster2_data -E discovery.type=single-node -E http.port=9202 -E transport.port=9302注意这是3个集群, 每个集群各自只配了一个节点
步骤二: 在每个集群上设置动态的设置
curl --location --request PUT 'http://127.0.0.1:9200/_cluster/settings' \
--header 'Content-Type: application/json' \
--data-raw '{
"persistent": {
"cluster": {
"remote": {
"cluster0": {
"seeds": [
"127.0.0.1:9300"
],
"transport.ping_schedule": "30s"
},
"cluster1": {
"seeds": [
"127.0.0.1:9301"
],
"transport.ping_schedule": "30s"
},
"cluster2": {
"seeds": [
"127.0.0.1:9302"
],
"transport.ping_schedule": "30s"
}
}
}
}
}'
curl --location --request PUT 'http://127.0.0.1:9201/_cluster/settings' \
--header 'Content-Type: application/json' \
--data-raw '{
"persistent": {
"cluster": {
"remote": {
"cluster0": {
"seeds": [
"127.0.0.1:9300"
],
"transport.ping_schedule": "30s"
},
"cluster1": {
"seeds": [
"127.0.0.1:9301"
],
"transport.ping_schedule": "30s"
},
"cluster2": {
"seeds": [
"127.0.0.1:9302"
],
"transport.ping_schedule": "30s"
}
}
}
}
}'
curl --location --request PUT 'http://127.0.0.1:9202/_cluster/settings' \
--header 'Content-Type: application/json' \
--data-raw '{
"persistent": {
"cluster": {
"remote": {
"cluster0": {
"seeds": [
"127.0.0.1:9300"
],
"transport.ping_schedule": "30s"
},
"cluster1": {
"seeds": [
"127.0.0.1:9301"
],
"transport.ping_schedule": "30s"
},
"cluster2": {
"seeds": [
"127.0.0.1:9302"
],
"transport.ping_schedule": "30s"
}
}
}
}
}'步骤三: 分别向每个集群写入数据
curl --location --request POST 'http://127.0.0.1:9200/users/_doc' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "user1",
"age": 10
}'
curl --location --request POST 'http://127.0.0.1:9201/users/_doc' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "user2",
"age": 20
}'
curl --location --request POST 'http://127.0.0.1:9202/users/_doc' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "user3",
"age": 30
}'步骤四: 跨集群搜索
curl --location --request POST 'http://127.0.0.1:9200/users,cluster1:users,cluster2:users/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query": {
"range": {
"age": {
"gte": 10,
"lte": 30
}
}
}
}'分布式特性及分布式搜索的机制
集群分布式模型及选主与闹裂问题
分布式架构
ES 的分布式
- 不同的集群使用不同的名字来区分, 默认名字是 "elasticsearch"
- 通过配置文件
elasticsearch.yml修改cluster.name, 或者在命令行中-E cluster.name=xxxx来指定
ES 的分布式架构的好处
- 存储的水平扩容, 支持 PB 级数据
- 提高系统的可用性, 部分节点停止服务, 整个集群的服务不受影响
Node
节点
节点是一个 ES 的实例
- 本质是一个 JAVA 进程
- 一个机器可以运行多个 ES 进程, 但生产环境一般建议一台机器上只运行一个 ES 实例.
- 每个节点都有名字, 通过配置文件配置, 或者在启动时通过
-E node.name=xxxx指定 - 每个节点在启动后, 会自动分配一个 UID, 保存在 data 目录下.
# 示例
bin/elasticsearch -E node.name=node1 -E cluster.name=geektime -E path.data=node1_data -E http.port=9200配置节点类型

Coordinating Node
Coordinating Node: 处理客户端请求的节点.
职责
接收客户端请求, 并将其路由到正确的节点
如创建索引的请求只有 Master 节点才能处理, 因此会自动将请求路由到 Master 节点.
- 所有节点默认都是 Coordinating Node
- 通过将其他类型设置成 False, 可以使自身成为 Delicated Coordinating Node
Data Node
Data Node: 可以保存数据的节点
- 节点启动后, 默认就是数据节点. 可以通过设置
node.data: false来禁止 职责
- 保存分片数据. 在数据扩展上起到了至关重要的作用 (由 Master Node 决定如何把分片分发到数据节点)
- 通过增加数据节点可以解决 数据水平扩展 和 数据单点 的问题
Master Node
Master Node: 每个集群只有一个主节点
职责
- 维护索引, 维护分片
- 维护并更新 Cluster State
最佳实践
- Master 节点非常重要, 在部署上需要考虑单点问题
- 可以为一个集群设置多个 Master 节点/ 每个节点只承担 Master 的单一角色
Master Eligible Nodes
Master Eligible Nodes: 候选节点, 指有资格通过选举成为 Master 的节点.
- 一个集群支持配置多个 Master Eligible 节点.
- Master Eligible 节点在必要时(如 Master 节点出现故障、 网络故障时)参与选主流程, 成为 Master 节点.
- 每个节点启动后, 默认就是一个 Master Eligible 节点. 可以通过设置
node.master: false来禁止 - 当集群内第一个 Master Eligible 节点启动后, 它会选举自己成为 Master 节点.
集群状态信息
集群状态信息 (Cluster State) 维护了一个集群中必要的信息
- 所有的节点信息
- 所有的索引和其相关的 Mapping 与 Setting 信息
- 分片的路由信息
每个节点上都保存了集群的状态信息, 但只有 Master 节点才能修改集群的状态信息, 并负责同步给其他节点.
为什么只有 Master 节点可以修改: 因为任意节点都能修改的话会导致 Cluster State 信息的不一致.
Master Node 选举过程与脑裂问题
选举
- 若集群不存在主节点或被选中的主节点丢失, 就是开始选举 Master 节点的流程.
- 集群中的 Master Eligible Node 会互相 Ping 对方, Node Id 低的会成为被选举的 Master 节点.
- 其他节点会加入集群, 但是不承担 Master 节点的角色.
Split-Brain 脑裂问题: 分布式网络的经典问题, 当出现网络问题, 一个节点和其他节点无法连接时, 各个被分割的网络区域内的节点会自行选举出一个 Master 节点, 导致在同一时刻集群存在多个 Master 节点, 各自维护不同的 cluster state. 当网络恢复时无法正确恢复集群状态.
避免闹裂问题
限定一个选举条件, 设置quorum(仲裁), 只有在 Master Eligible 节点数大于 quorum 时才能进行选举.
Quorum = 超过半数
当 3 个 master Eligible 时, 设置
discovery.zen.minimum_master_nodes为 2 即可避免脑裂
从 7.0 开始无需上述配置
- 移除
minimum_master_nodes参数, ES 自己选择可以形成仲裁的节点. - 典型的主节点选举现在只需要很短的时间就可以完成. 集群的伸缩变得更安全, 更容易, 并且可能造成丢失数据的系统配置选项更少了.
- 节点更清楚地记录它们的状态, 有助于诊断为什么它们不能加入集群或为什么无法选举出主节点.
- 移除
分片与集群的故障转移
分片
分片是 ES 分布式存储的基石.
分片的类型
- Primary Shard 主分片
Replica Shard 副本分片
1个索引 -> N 个主分片
1个主分片 -> M 个副本分片
Primary Shard
- 通过主分片, 可以将一份索引的数据分散到多个 Data Node 上, 实现存储的水平扩展.
- 主分片数在索引创建时指定, 后续默认不能修改, 除非重建索引.
Replica Shard
数据可用性.
- 通过引入副本分片, 可以提高数据的可用性.
- 当主分片丢失时, 副本分片可以 Promote 成为主分片.
- 副本分片数可以动态调整, 每个节点上都有完备的数据(指该副本分片对应的主分片的数据).
- 若不设置副本分片, 一旦出现节点硬件故障, 就有可能造成数据丢失.
提升系统的读取性能
- 副本分片由主分片同步, 通过支持增加 Replica 个数, 一定程度可以提高读取的吞吐量.
分片数的设定
- 主分片数过小时: 若索引增长很快, 集群将无法通过增加节点来实现对这个索引的数据扩展.
- 主分片数过大时: 导致每个分片的容量很小, 同时每个节点上存在过多分片是一定程度上影响性能的.
- 副本节点数设置过多: 会降低集群整体的写入性能.
设置主分片数及副本分片数
PUT 索引名
{
"settings": {
"number_of_shards": 3, // 3 个主分片
"number_of_replicas": 1 // 每个主分片对应一个副本分片
}
}上述配置后, 该索引共有 3 个主分片, 3 个副本分片.
集群故障转移
集群健康状态
- 绿色 Green: 健康状态, 所有主分片和副本分片都可用.
- 黄色 Yellow: 亚健康, 所有主分片可用, 部分副本分片不可用.
- 红色 Red: 不健康状态, 部分主分片不可用.
GET _cluster/health集群是具有故障转移能力的
- Master 节点会决定分片分配到哪个节点上
- 通过增加节点, 提高集群的计算能力.
- 故障转移期间, 集群健康状态会持续一小段时间的黄色. 待分片分配完毕后, 会恢复为绿色.

文档分布式存储
文档与分片
文档会存储在具体的某个 Primary 分片和对应的 Replica 分片上.
例如文档 1 可能存储在 P0 和 R0 分片上
文档到分片的映射算法
- 文档应尽量均匀分布在所有分片上, 充分利用硬件资源, 避免热点分片
潜在的算法
随机 / Round Robin: 分片数多时需多次查询才能获取到, 不靠谱.- 查表法
- 实时计算(比如 hash)
ES 采取的文档到分片的路由算法
shard = hash(_routing) % number_of_primary_shards- Hash 算法确保文档均匀分散到所有分片
- 默认的 _routing 值是文档 id
可以自行制定 routing 数值
// 比如相同国家的商品都分配到指定的 shard PUT goods/_doc/100?routing=country { "country": "...", ... }- 缺点: primary 分片数一旦确定后, 不能随意修改
更新/删除操作
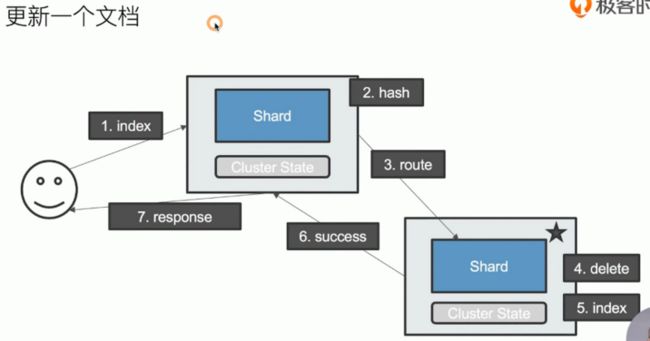
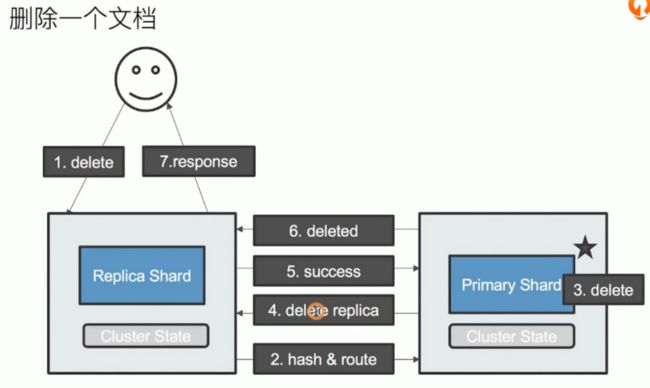
分片及其生命周期
分片的内部原理
ES 的分片
- 分片是 ES 中最小的工作单元
- ES 中一个分片的本质就是一个 Lucene 的 Index
了解分片的原理就能够理解 ES 的一些行为:
- ES 的搜索是近实时的(写入1秒后才能被搜到)
- ES 能够保证断电时数据不会丢失
- 删除文档并不会立刻释放空间
倒排索引不可变性
倒排索引采用 Immutable Design, 一旦生成, 不可更改.
不可变性带来的好处
- 无需考虑并发写文件的问题, 避免锁机制带来的性能问题
- 一旦读入内核的文件系统缓存, 便留在那里. 只要文件系统存有足够的空间, 大部分请求就会直接命中内存, 不会命中磁盘, 提升了很大的性能.
- 缓存容易生成和维护, 系统可以充分利用缓存. 倒排索引允许数据被压缩.
不可变性带来的问题
- 如果需要让一个新的文档可以被搜索, 需要重建整个索引
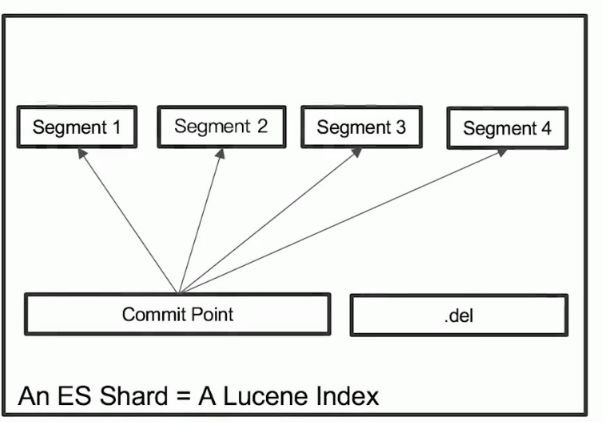
Lucene Index
Segment
在 Lucene, 单个倒排索引文件称为 Segment, Segment 是自包含, 不可变更的.
多个 Segments 汇总在一起, 称为 Lucene 的 Index, 其对应 ES 中的 Shard.
- 当有文档写入时, 会产生新 Segment.
- 查询时会同时查询所有 Segments, 并且对结果汇总.
Lucene 中有一个文件, 用来记录所有 Segments 信息, 叫做 Commit Point.
- 删除的文档信息保存在 ".del" 文件中
Refresh 过程
Refresh 指将 Index Buffer 写入 Segment 的过程.
数据在 Index Buffer 中是无法被搜索的, 只有 Segment 才会被搜索到.
- Refresh 不执行 fsync 操作
- Refresh 频率: 默认 1 秒发生一次, 可通过
index.refresh_interval配置. - 当 Index Buffer(默认是 JVM 的 10%) 被写满时, 也会触发Refresh
- 如果系统有大量的数据写入, 那就回产生很多 Segment
Segment 写入磁盘的过程(指 Refresh 过程) 相对耗时, 借助文件系统缓存, Refresh 时先将 Segment 写入缓存以开放查询.

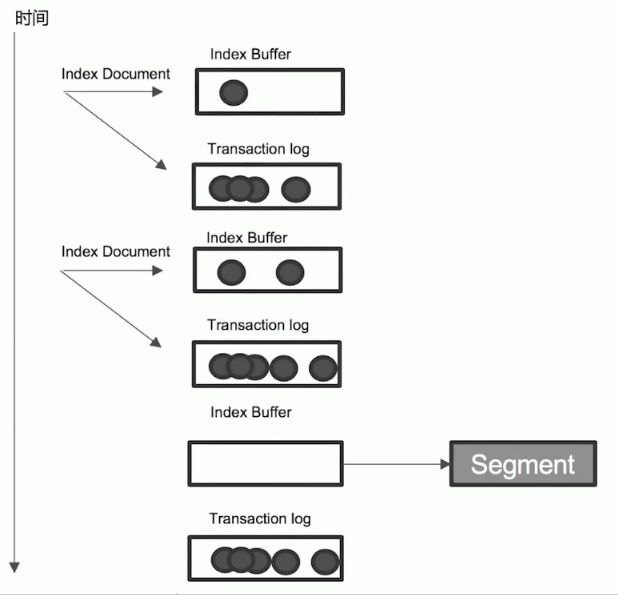
Transaction Log
Index Buffer 中的数据是在内存, 因此为了保证断电/程序崩溃时数据不丢失, 在 Index Document 写入 Index Buffer 的同时会写 Transaction Log. 在高版本中, Transaction Log 默认落盘.
- 每个分片有一个 Transaction Log
- 在 ES Refresh 时, Index Buffer 被清空, 但 Transaction Log 不会清空.
Flush 过程
ES Flush & Lucence Commit
- 调用 Refresh, 清空 Index Buffer
- 调用 fsync 将文件系统缓存中的 Segments 写入磁盘
- 清空(删除) Transaction Log
Flush 的时机
- 默认每 30 分钟调用一次
- Transaction Log 满(默认 512 MB)

Merge 过程
Merge 过程: 由于每次 Refresh 都会生成一个 Segment, 会导致 Segment 很多, 因此需要定期合并.
- 减少 Segments
- 删除已经被标记删除的文档
ES 和 Lucence 会自动进行 Merge 操作, 也可以通过 POST 索引名/_forcemerge 强制进行 Merge 操作.
剖析分布式查询及相关性算分
带着疑问: 为什么 ES 默认的主分片数设置为 1.
ES 的分布式搜索是分两个阶段进行的
- Query 阶段
用户发出请求到 ES 节点, 节点收到请求后会以 Coordinating 节点的身份在 6 个分片中随机选取 3个分片, 发送查询请求.
被选中的分片执行查询时, 会进行排序, 然后每个分片都返回 from + size 个排序后的文档的 id 和排序值给 Coordinating 节点.
- Fetch 阶段
Coordinating 在 Query 阶段共收到 3 * (from + size) 个文档 id 及其排序值后, 会重新进行排序, 并选取 from ~ (from + size) 个文档 的 id.
之后再以 multi get 请求的方式到各自的分片获取详细的文档数量.
这里以索引设置为 3个主分片, 2个副本分片为例.
上述的两阶段称为 Query-then-Fetch, 会存在两个问题:
问题一: 性能问题
- 每个分片需要查的文档个数= from + size
- coordinating(协调) 节点需要处理: number_of_shards * (from + size) 文档项
- 在深度分页时这个数据量是非常大的.
问题二: 评分问题
- 每个分片在 Query 阶段评分时是根据各自分片内的文档数据进行相关度计算的, 这会导致打分偏离的情况.
- 相关性算分在各个分片间是独立进行的, 当文档总数很少时, 且主分片数多时, 相关性算分会很不准确.
解决评分不准的方法
- 当数据量不大时: 将主分片数设置为 1
当数据量足够多时, 只要保证文档均匀分布在各个分片上, 那么
- 使用 DFS Query Then Fetch
在搜索的 URL 中指定参数
_search?search_type=dfs_query_then_fetch到每个分片把各分片的词频和文档频率进行搜集, 然后完整的进行一次相关性算分, 耗费更加多的 CPU 和内存, 执行性能低下, 一般不建议使用.
数据量少且主分片多的情况下打分偏差, 及使用 DFS Query Then Fetch 获取正确打分的例子.
DELETE message
PUT message
{
"settings": {
"number_of_shards": 20
}
}
POST message/_bulk
{"create":{}}
{"content": "good"}
{"create":{}}
{"content": "good morning"}
{"create":{}}
{"content": "good morning everyone"}
// 此时查询结果评分是有问题的, 所有文档的评分都是 0.2876821
POST message/_search
{
"query": {
"term": {
"content": {
"value": "good"
}
}
}
//,"explain": true
}
// 使用 DFS Query Then Fetch 正确获取打分
// 但这种方式性能很不好, 通常是不被推荐的
POST message/_search?search_type=dfs_query_then_fetch
{
"query": {
"term": {
"content": {
"value": "good"
}
}
}
}排序及Doc Values & Fielddata
排序
ES 默认采用相关性算分对结果进行降序排序
可以通过设定
sort参数自行设定排序- 若不指定
_score, 则算分为 null
- 若不指定
排序的过程
- 排序是针对字段原始内容进行的.
- 倒排索引无法发挥作用, 需要用到正排索引, 通过文档 Id 和字段快速得到字段原始内容.
ES 有两种实现方式
Fielddata
针对 text 字段
默认是关闭的, 可通过修改 Mapping 中字段的
fielddata: true来开启, 但必须了解到, 这边存储的是分词后的结果.若这不是想要的效果, 那可以为该 text 字段加一个 keyword 子字段, 然后直接使用该子字段.
PUT 索引名/_mapping
{
"properties": {
"属性名": {
"type": "text", // 这里以 text 类型为例
"fielddata": true // keyword 类型的默认开启了该属性, 因此无需特地设置.
}
}
}
```
Doc Values
列式存储, 对 text 类型无效
默认是开启的, 可通过修改 Mapping 中字段的
doc_values: false来关闭关闭 Doc Values 的好处:
- 增加索引的速度
- 减少磁盘空间
什么情况需要关闭:
- 当明确不需要该字段参与排序及聚合分析时.
关于 Doc Values 和 Field Data

排序部分示例
// 单字段
POST kibana_sample_data_ecommerce/_search
{
"size": 5,
"query": {
"match_all": {}
},
"sort": [
{
"order_date": {
"order": "desc"
}
}
]
}
// 多字段
POST kibana_sample_data_ecommerce/_search
{
"size": 5,
"query": {
"match_all": {}
},
"sort": [
{
"order_date": {
"order": "desc"
}
},
{
"_doc": {
"order": "asc"
}
},
{
"_score": {
"order": "desc"
}
}
]
}打开 Field Data (默认是未开启的, 此时无法对text类型排序)
// 打开 text 的 fielddata
PUT kibana_sample_data_ecommerce/_mapping
{
"properties": {
"customer_full_name": {
"type": "text",
"fielddata": true,
"fields": {
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
}
}
}
POST kibana_sample_data_ecommerce/_search
{
"size": 5,
"query": {
"match_all": {}
},
"sort": [
{
"customer_full_name": {
"order": "desc"
}
}
]
}分页与遍历: From, Size, Search After & Scroll API
常用的分页方式
post users/_search
{
"from":100,
"size":100,
"query":{
"match_all": {}
}
}默认情况使用相关度算分排序, 返回前10条记录.
- from: 开始的位置
- size: 期望获取的文档的的数量
但是这种方式存在如下问题: 深度分页问题.

分布式系统中深度分页的问题
ES是分布式的, 其数据分别保存在多个分片, 多台机器上.
当一个查询: From=990, Size=10
- 首先在每个分片上都获取 1000 个文档(默认是相关度评分前1000).
- 然后通过 Coordinating Node 聚合所有结果
- 最后再通过排序选取前 1000 个文档.
上述操作存在的明显问题就是, 当页数越深, 占用的内存会越多.
为了避免深度分页带来的内存开销, ES 有一个默认限定: 10000 个文档.
post users/_search
{
"from":10000,
"size":100,
"query":{
"match_all": {}
}
}
// 此时会报错: Result window is too large, from + size must be less than or equal to: [10000] but was [10100].ES 提供了 Search After 来解决深度分页问题.
Search After
Search After 避免了深度分页带来的性能问题, 但是其本身有着如下的限制
- 不支持指定页数 (From)
- 只能往下翻
使用:
第一次搜索需要指定 sort, 并且保证值是唯一的
可以通过加入
_id来保证唯一性post users/_search { "size": 100, "query": { "match_all": {} }, "sort": [ {"age":"desc"}, {"_id":"asc"} ] }每次搜索都会返回 sort, 后续的搜索需要使用上一次返回的 sort 以往下查询.
post users/_search { "size": 2, "query": { "match_all": {} }, "sort": [ {"age":"desc"}, {"_id":"asc"} ], "search_after": [ 2, // age "pq32RXUBu83_vZFOE_49" // _id ] }
Search After 解决深度分页的原理
- 每个分片通过唯一排序值定位, 仅返回需要处理的 size 个文档数
- Coordinating Node 聚合所有结果后排序并返回前 size 个

Size=10, 当查询 990~1000 时如上图所示, 各个分片仅返回符合条件的前 10 个文档(根据唯一排序值过滤)
Scroll Api
Scroll Api 也是用于解决深度分页的问题, 不过其原理不一样.
适用于大量导出数据.
原理
- 第一次查询时创建一个快照
- 后续的每次查询都输入上一次的 Scroll Id
存在的限制
- 在快照生成后, 新写入的数据无法被查到
// 第1次查询
POST users/_search?scroll=5m
{
"size":1,
"query": {
"match_all": {}
}
}
// 第2次查询
POST _search/scroll
{
"scroll": "1m",
"scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFEpxSVdSblVCbzV0OHBaRVFXU3pnAAAAAAAAAsQWblF6bktTeDZSN0tnbzRkRnE0SWJSQQ=="
}
关于
scroll 参数, 暂时还不大理解什么意思.
不同的搜索类型及其使用场景
- Regular
需要实时获取顶部的部分文档(例如查询最新的订单)
此时直接使用 "size" 即可
- Scroll
当需要全部文档(例如导出全部数据)时可以使用 Scroll Api
- Pagination
当需要分页时, 可以使用 From 和 Size.
但如果需要深度分页, 则选用 Search After
处理并发读写操作
并发控制一般来说有两种
- 悲观并发控制
通过对资源加锁, 防止冲突
- 乐观并发控制
假定冲突不会发生, 不会阻塞正在尝试的操作.
ES 采用的是乐观并发控制.
ES 中的文档是不可变更的, 如果你更新了一个文档:
- 将旧文档标记删除
- 增加一个新文档, 并将其 version 字段加 1
ES 的版本控制分为
- 内部版本控制
if_seq_no+if_primary_term - 外部版本控制(即由其他数据库作为主要数据存储, 并控制数据的版本)
version+version_type= external
示例 - 内部版本控制
1. 初始化索引
DELETE users
PUT users/_doc/1
{
"name": "jason",
"age": 18
}2. 获取文档初始版本
// 获取 _id=1 的文档
GET users/_doc/1
// 返回结果:
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "jason",
"age" : 18
}
}3. 第一次更新
// 第1次更新
PUT users/_doc/1?if_seq_no=0&if_primary_term=1
{
"title": "jason",
"age": 19
}
// 返回值
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}4. 第二次更新
// version_conflict_engine_exception
PUT users/_doc/1?if_seq_no=1&if_primary_term=1
{
"title": "jason",
"age": 20
}此时会报版本冲突错误
示例 - 外部版本控制
PUT users/_doc/1?version=100&version_type=external
{
"title": "jason",
"age": 20
}每次更新, version 只能往大了加, 否则会提示版本冲突错误.
深入聚合分析 Aggregation
聚合类型
聚合主要有以下几种
- Bucket Aggregation 桶聚合
分桶聚合
- Metric Aggregation 度量聚合
数学计算
- Pipeline Aggregation 管道聚合
对其他聚合结果进行二次聚合
- Matrix Aggregation 矩阵聚合
对多个字段的操作, 并提供一个结果矩阵
SQL 与 ES 的聚合类比

Aggregation 属于 Search 的一部分, 一般建议将其 Size 指定为 0.
Aggregation 语法
POST 索引名/_search
{
// 与 Query 同级的关键词
"aggs": {
"聚合名1": {
// 聚合的定义: 不同的 type + body
"<聚合 type>": {
// aggregation body, 不同 aggregation type 对应的 body 格式也不同
...
},
// 可选: meta
"meta": {
...
},
// 可选: 子查询, 嵌套聚合
"aggs": {
...
}
},
// 可以包含多个同级的聚合查询
"聚合名2": {
...
}
},
}本节课程使用数据初始化
DELETE employees
PUT employees
{
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"gender": {
"type": "keyword"
},
"job": {
"type": "text",
// text 类型默认不开启 fielddata, 因此该字段无法用于 terms 聚合.
// "fielddata": true,
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 50
}
}
},
"name": {
"type":"text"
},
"salary":{
"type":"integer"
}
}
}
}
GET employees
PUT /employees/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "Emma","age":32,"job":"Product Manager","gender":"female","salary":35000 }
{ "index" : { "_id" : "2" } }
{ "name" : "Underwood","age":41,"job":"Dev Manager","gender":"male","salary": 50000}
{ "index" : { "_id" : "3" } }
{ "name" : "Tran","age":25,"job":"Web Designer","gender":"male","salary":18000 }
{ "index" : { "_id" : "4" } }
{ "name" : "Rivera","age":26,"job":"Web Designer","gender":"female","salary": 22000}
{ "index" : { "_id" : "5" } }
{ "name" : "Rose","age":25,"job":"QA","gender":"female","salary":18000 }
{ "index" : { "_id" : "6" } }
{ "name" : "Lucy","age":31,"job":"QA","gender":"female","salary": 25000}
{ "index" : { "_id" : "7" } }
{ "name" : "Byrd","age":27,"job":"QA","gender":"male","salary":20000 }
{ "index" : { "_id" : "8" } }
{ "name" : "Foster","age":27,"job":"Java Programmer","gender":"male","salary": 20000}
{ "index" : { "_id" : "9" } }
{ "name" : "Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000 }
{ "index" : { "_id" : "10" } }
{ "name" : "Bryant","age":20,"job":"Java Programmer","gender":"male","salary": 9000}
{ "index" : { "_id" : "11" } }
{ "name" : "Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000 }
{ "index" : { "_id" : "12" } }
{ "name" : "Mcdonald","age":31,"job":"Java Programmer","gender":"male","salary": 32000}
{ "index" : { "_id" : "13" } }
{ "name" : "Jonthna","age":30,"job":"Java Programmer","gender":"female","salary":30000 }
{ "index" : { "_id" : "14" } }
{ "name" : "Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary": 25000}
{ "index" : { "_id" : "15" } }
{ "name" : "King","age":33,"job":"Java Programmer","gender":"male","salary":28000 }
{ "index" : { "_id" : "16" } }
{ "name" : "Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "17" } }
{ "name" : "Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "18" } }
{ "name" : "Catherine","age":29,"job":"Javascript Programmer","gender":"female","salary": 20000}
{ "index" : { "_id" : "19" } }
{ "name" : "Boone","age":30,"job":"DBA","gender":"male","salary": 30000}
{ "index" : { "_id" : "20" } }
{ "name" : "Kathy","age":29,"job":"DBA","gender":"female","salary": 20000}Metric Aggregation
Metric Aggregation 支持
单值分析: 只输出一个结果
min,max,avg,sum: 最小, 最大, 平均, 总和// 找到最低的工资 POST employees/_search { "size": 0, "aggs": { "min_salary": { "min": { "field": "salary" } } } }cardinality: 基数统计, 理解为 count
多值分析: 输出多个分析结果
stats: 输出 count, min, max, avg, sum 统计值// 输出多个值 POST employees/_search { "size": 0, "aggs": { "stats_salary": { "stats": { "field": "salary" } } } }extended_stats: 除了 stats 的输出结果外, 还额外输出 方差(variance), 标准差(std_deviation) 等percentile: 百分位数percentile_rankstop_hits: 根据指定排序, 仅输出前N个文档
Bucket Aggregation
Bucket Aggregation:
- 按照一定的规则, 将文档分配到不同的桶中, 从而达到分类的目的.
- 支持嵌套: Bucket 聚合分析支持添加子聚合来进一步分析, 子聚合可以是 Bucket 及 Metric.
Bucket Aggregation 支持以下几种分桶:
非数字类型
termsPOST employees/_search { "size": 0, "aggs": { "terms_job": { "terms": { "field": "job.keyword", // 指定返回的桶数(默认是按数量返回前N个) "size": 10 } } } }Terms Aggregation 只能对打开了 fielddata 的字段进行聚合(具体是在索引的 mappings 中设置该字段时指定 fielddata 为 true)
数字类型
range: 按数字范围分桶POST employees/_search { "size": 0, "aggs": { "range_age": { "range": { "field": "age", "ranges": [ { "to": 30, // 自定义 key "key": "<30" }, { "from": 30, "to": 50 }, { "from": 50 } ] } } } }date_range: 对日期的范围分桶histogram: 对数字计算直方图数据POST employees/_search { "size": 0, "aggs": { "my_stats": { "histogram": { "field": "age", "interval": 1, "min_doc_count": 1 } } } }date_histogram: 对日期的直方图数据
示例: 嵌套聚合, 查找各个工种中, 年纪最大的前 3 名员工
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword"
},
"aggs": {
"old_employers": {
"top_hits": {
"size": 3,
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
}
}
}
}
}优化 Terms 聚合性能
当需要频繁聚合, 对聚合搜索有性能要求, 且持续地增加新文档时, 建议使用下面的方式来优化.
这样每次新增文档时, 都会预先处理聚合, 从而提升 Terms 聚合搜索时的性能.
- 设置
eager_global_ordinals为 true

Pipeline 聚合分析
Pipeline 管道聚合分析: 对聚合分析的结果, 再次进行聚合分析.
Pipeline 管道聚合, 根据分析结果输出到原结果中位置的不同, 分为两类
Sibling: 输出结果和现有分析结果同级
max_bucket,min_bucket,avg_bucket,sum_bucketstats_bucket,extended_stats_bucketpercentiles_bucket
Parent: 输出结果内嵌到现有的聚合分析结果之中
derivative: 求导cumulative_sum: 累计求和moving_avg: 滑动窗口(移动平均值)
示例: Sibling 类型的 Pipeline Aggregation
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword"
},
"aggs": {
"salary": {
"stats": {
"field": "salary"
}
}
}
},
// 获取平均工资最低的工作类型
"min_avg_salary_by_job": {
"min_bucket": {
"buckets_path": "jobs>salary.min"
}
},
// 平均工资的统计分析
"stats_avg_salary_by_job": {
"stats_bucket": {
"buckets_path": "jobs>salary.avg"
}
},
// 平均工资的百分位数
"percentiles_avg_salary_by_job": {
"percentiles_bucket": {
"buckets_path": "jobs>salary.avg"
}
}
}
}
// 返回值:
{
// ...,
"aggregations" : {
"jobs" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Java Programmer",
"doc_count" : 7,
"avg_salary" : {
"count" : 7,
"min" : 9000.0,
"max" : 38000.0,
"avg" : 25571.428571428572,
"sum" : 179000.0
}
},
{
"key" : "Javascript Programmer",
"doc_count" : 4,
"avg_salary" : {
"count" : 4,
"min" : 16000.0,
"max" : 25000.0,
"avg" : 19250.0,
"sum" : 77000.0
}
},
// ...
]
},
"min_avg_salary_by_job" : {
"value" : 9000.0,
"keys" : [
// 平均工资最低的工作是 Java
"Java Programmer"
]
},
"stats_avg_salary_by_job" : {
"count" : 7,
"min" : 19250.0,
"max" : 50000.0,
"avg" : 27974.48979591837,
"sum" : 195821.42857142858
},
"percentiles_avg_salary_by_job" : {
"values" : {
"1.0" : 19250.0,
"5.0" : 19250.0,
"25.0" : 21000.0,
"50.0" : 25000.0,
"75.0" : 35000.0,
"95.0" : 50000.0,
"99.0" : 50000.0
}
}
}
}示例: Parent 类型的 Pipeline Aggregation
{
"size": 0,
"aggs": {
// 对 age terms 分桶
"age": {
"histogram": {
"field": "age",
"interval": 1
},
"aggs": {
// 桶内计算平均工资
"avg_salary": {
"avg": {
"field": "salary"
}
},
// 桶内计算平均工资的累计求和
"cumulative_salary": {
"cumulative_sum": {
"buckets_path": "avg_salary"
}
}
}
}
}
}
// 返回值
{
// ...
"aggregations" : {
"age" : {
"buckets" : [
{
"key" : 20.0,
"doc_count" : 1,
"avg_salary" : {
"value" : 9000.0
},
"cumulative_salary" : {
"value" : 9000.0
}
},
{
"key" : 21.0,
"doc_count" : 1,
"avg_salary" : {
"value" : 16000.0
},
"cumulative_salary" : {
"value" : 25000.0
}
},
// ...
]
}
}
} 聚合范围
ES 聚合分析的默认作用范围是 query 的查询结果集.
ES 支持以下方式改变聚合的作用范围
query: 同时影响查询结果集和聚合范围post_filter: 只影响查询结果集POST employees/_search { "aggs": { "jobs": { "terms": { "field": "job.keyword" } } }, "post_filter": { "match": { "job.keyword": "Dev Manager" } } }aggs.*.filter: 只影响聚合范围, 但同时也收到全局 query 的影响POST employees/_search { "size": 0, "aggs": { // 返回的 all_jobs 聚合结果, 是对所有人的 job 分桶 "all_jobs": { "terms": { "field": "job.keyword" } }, // 返回的 older_person 聚合结果, 是仅对年龄 >= 35 的人的 job 分桶 "older_person": { "filter": { "range": { "age": { "gte": 35 } } }, "aggs": { "jobs": { "terms": { "field": "job.keyword" } } } } } }aggs.*.global: 只影响聚合范围, 此时忽略全局 query 的影响POST employees/_search { "size": 0, "query": { "range": { "age": { "gte": 1000 } } }, "aggs": { "jobs": { "terms": { "field": "job.keyword" } }, "all": { "global": {}, "aggs": { "jobs": { "terms": { "field": "job.keyword" } } } } } }
聚合排序
ES 中可以指定 order, 对聚合结果按照 count 和 key 进行排序
- 默认情况下, 按照 count 降序
- 指定 size 可以仅返回前 N 个结果
示例: 按照桶内数量升序, 若值相等则按照 key 升序
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
// 按照桶内数量升序, 若值相等则按照 key 升序
"order": [
{"_count": "asc"},
{"_key": "asc"}
]
}
}
}
}示例: 根据平均工资排序
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
// 根据平均工资排序
"order": [
{
"avg_salary": "desc"
}
]
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
}
}
}聚合分析的原理及精准度问题
分布式系统的近似统计算法

对于分布式系统的近似统计算法来说, 数据量, 精确度, 实时性 是难以兼得的.
- 当数据量很大, 对结果的精确度要求很高, 但对实时性要求不大时, 可以采用 Hadoop 离线计算
- 当数据量有限, 且实时性和精确度要求很高时, 此时 ES 可以通过将数据都放在一个主分片上, 从而保证精确度和实时性
- 当数据量很大, 且对实时性要求很高时, 数据在 ES 中会被存放在多个主分片上, 此时无法保证精确度.
ES 中有些统计能够保证精确度, 以 min 聚合分析的执行流程为例
- Coordinating Node 分别向各个主分片请求 min value
- 各个主分片计算出当前分片内的 min value
- Coordinating Node 汇总结果, 并得出精确的 min value
但其他的一些统计, ES 无法保证精确度, 以 term 分桶聚合为例
- 客户端向 Coordinating Node 发起 search 查询,
size: 3(仅返回前3个最大的分桶) Coordinating Node 分别向各个主分片请求
size: 3的 query实际上 ES 不一定是请求各个分片内的 top 3, 而是请求 top
shard_size, 这里只是举个例子.- 各个主分片返回当前分片内的 top 3
Coordinating Node 汇总结果, 但此时结果并不一定是准确的.

上面图中有点问题, 根据 官方文档, 上图的 doc_count_error_upper_bound 应该是 4 + 2 = 6, 而不是 7.
Terms Aggregation 的返回值示例
doc_count_error_upper_bound: 表示被遗漏的 term 分桶, 其中包含的文档可能的最大值个人理解, 比如说有3个主分片, 当 shard_size 值为 10 时, 3个主分片返回的桶中最小的那个桶的大小分别是 n1, n2, n3, 那么该值应该是 n1 + n2 + n3.
以上面那个 《Terms 不正确的案例》为例, doc_count_error_upper_bound = 6, 表示可能存在遗漏的最大大小为 6 的分桶.
sum_other_doc_count: 除了返回结果中 bucket 的 terms 以外, 其他 terms 的文档总数, 即总文档数 - 返回的文档数.

在查询时打开show_term_doc_count_error时会返回上述字段:

解决 terms 不准的问题: 提升 shard_size
Terms 聚合分布不准确的原因是, 数据分散在多个主分片上, Coordinating Node 无法获取数据全貌.
这里存在2个解决方案:
- 数据量不大时, 设置 Primary Shard 为 1, 从而保证准确性
- 在分布式数据上, 查询时设置更大的
shard_size, 令各个分片返回额外的数据, 从而提升准确率.
shard_size 设定
- 该值表示, Coordinating Node 向各个主分片请求返回的 size
调整 shard_size 大小, 可以降低
doc_count_error_upper_bound来提升准确度副作用是: 增加了整体的计算量, 会降低响应时间
- shard_size 默认大小设定
shard_size = size * 1.5 + 10
示例: terms 不准确的情况
DELETE my_flights
GET kibana_sample_data_flights
// 将 my_flights 的主分片数故意调整成 20
PUT my_flights
{
"settings": {
"number_of_shards": 20,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"AvgTicketPrice": {
"type": "float"
},
"Cancelled": {
"type": "boolean"
},
"Carrier": {
"type": "keyword"
},
"Dest": {
"type": "keyword"
},
"DestAirportID": {
"type": "keyword"
},
"DestCityName": {
"type": "keyword"
},
"DestCountry": {
"type": "keyword"
},
"DestLocation": {
"type": "geo_point"
},
"DestRegion": {
"type": "keyword"
},
"DestWeather": {
"type": "keyword"
},
"DistanceKilometers": {
"type": "float"
},
"DistanceMiles": {
"type": "float"
},
"FlightDelay": {
"type": "boolean"
},
"FlightDelayMin": {
"type": "integer"
},
"FlightDelayType": {
"type": "keyword"
},
"FlightNum": {
"type": "keyword"
},
"FlightTimeHour": {
"type": "keyword"
},
"FlightTimeMin": {
"type": "float"
},
"Origin": {
"type": "keyword"
},
"OriginAirportID": {
"type": "keyword"
},
"OriginCityName": {
"type": "keyword"
},
"OriginCountry": {
"type": "keyword"
},
"OriginLocation": {
"type": "geo_point"
},
"OriginRegion": {
"type": "keyword"
},
"OriginWeather": {
"type": "keyword"
},
"dayOfWeek": {
"type": "integer"
},
"timestamp": {
"type": "date"
}
}
}
}
// reindex
POST _reindex
{
"source": {
"index": "kibana_sample_data_flights"
},
"dest": {
"index": "my_flights"
}
}
GET my_flights/_count
GET kibana_sample_data_flights/_count
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"weather": {
"terms": {
"field": "OriginWeather",
"size": 1,
"shard_size": 2,
"show_term_doc_count_error": true
}
}
}
}
POST my_flights/_search
{
"size": 0,
"aggs": {
"weather": {
"terms": {
"field": "OriginWeather",
"size": 1,
"shard_size": 5,
"show_term_doc_count_error": true
}
}
}
}上述最后一个查询的返回结果
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 20,
"successful" : 20,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"weather" : {
// 可能遗漏的桶最大可能为 1193
"doc_count_error_upper_bound" : 1193,
"sum_other_doc_count" : 10735,
"buckets" : [
{
"key" : "Clear",
"doc_count" : 2324,
"doc_count_error_upper_bound" : 0
}
]
}
}
}数据建模


ES 中处理关联关系
ES 中往往考虑 Denormalize 数据: 读的速度变快、无需表连接、无需行锁
而关系型数据库则一般会考虑 Normalize 数据.
ES 主要采用以下 4 种方法处理关联
- 对象类型
- 嵌套对象(Nested Object)
- 父子关联关系(Parent / Child)
- 应用端关联
对象
使用示例
初始化相关数据
DELETE blog
PUT blog
{
"mappings": {
"properties": {
"content":{
"type": "text"
},
"time": {
"type": "date"
},
"user":{
"properties": {
"userid": {
"type": "long"
},
"username": {
"type": "keyword"
},
"city": {
"type": "text"
}
}
}
}
}
}
// 插入一条 Blog 信息
PUT blog/_doc/1
{
"content":"I like Elasticsearch",
"time":"2019-01-01T00:00:00",
"user":{
"userid":1,
"username":"Jack",
"city":"Shanghai"
}
}查询对象字段
// 查询对象字段
POST blog/_search
{
"query": {
"bool": {
"must": [
{
"match": {"user.username": "Jack"}
},
{
"match": {"content": "Elasticsearch"}
}
]
}
}
}
存储数组时存在的问题
ES 在存储时, 内部对象的边界并没有考虑在内, JSON 格式被处理成扁平式键值对的结构.
当对多个字段进行查询时, 会导致意外的搜索结果: 可以使用 Nested (内嵌对象) 来解决这个问题.
比如如下数据在 Lucene 中实际存储:
POST my_movies/_doc/1
{
"title":"Speed",
"actors":[
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}上述数据在 Lucene 中实际存储如下
"title": "Speed"
"actors.first_name": ["Keanu", "Dennis"]
"actors.last_name": ["Reeves", "Hopper"] 因此, 我们在搜索 actor: {first_name: "Keanu", last_name: "Hopper"} 时会错误地匹配到上述文档.
示例情况
DELETE my_movies
// 电影的Mapping信息
PUT my_movies
{
"mappings": {
"properties": {
"actors": {
"properties": {
"first_name": {
"type": "keyword"
},
"last_name": {
"type": "keyword"
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
// 写入一条电影信息(对于内部对象的存储, JSON格式被处理成扁平式键值对的结构存储)
POST my_movies/_doc/1
{
"title":"Speed",
"actors":[
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}
# 查询电影信息(错误地匹配到上面的文档)
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"actors.first_name": "Keanu"
}
},
{
"match": {
"actors.last_name": "Hopper"
}
}
]
}
}
}Nested 嵌套对象
什么是 Nested Data Type
Nested 数据类型:
- 允许对象数组中的对象被独立索引
在内部, Nested 文档会被保存在两个 Lucene 文档中, 在查询时做 Join 处理.
POST my_movies/_doc/1 { "title":"Speed", "actors":[ { "first_name":"Keanu", "last_name":"Reeves" }, { "first_name":"Dennis", "last_name":"Hopper" } ] }当 actors 是 Nested 类型字段时, 上述数据的 actors 中的多个子文档是分别存储的, 并不是扁平化的键值对结构.
使用示例
DELETE my_movies
PUT my_movies
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"actors": {
"type": "nested",
"properties": {
"first_name": {
"type": "keyword"
},
"last_name": {
"type": "keyword"
}
}
}
}
}
}
POST my_movies/_doc/1
{
"title":"Speed",
"actors":[
{
"first_name":"Keanu",
"last_name":"Reeves"
},
{
"first_name":"Dennis",
"last_name":"Hopper"
}
]
}
// 对于 nested 字段, 这样是匹配不到任何结果的
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"actors.first_name": "Keanu"
}
},
{
"match": {
"actors.last_name": "Reeves"
}
}
]
}
}
}
// 对于 nested, 这种常规写法也是搜索不到东西的
POST my_movies/_search
{
"query": {
"match": {
"actors.first_name": "Keanu"
}
}
}
// 对于 nested 字段, 搜索时必须使用 nested 专用的搜索语法
POST my_movies/_search
{
"query": {
"nested": {
"path": "actors",
"query": {
"bool": {
"must": [
{
"match": {
"actors.first_name": "Keanu"
}
},
{
"match": {
"actors.last_name": "Reeves"
}
}
]
}
}
}
}
}
// 对于 nested 字段, 搜索时必须使用 nested 专用的搜索语法
POST my_movies/_search
{
"query": {
"nested": {
"path": "actors",
"query": {
"match": {
"actors.first_name": "Keanu"
}
}
}
}
}
// Nested 查询
POST my_movies/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "Speed"
}
},
{
"nested": {
"path": "actors",
"query": {
"bool": {
"must": [
{
"match": {
"actors.first_name": "Keanu"
}
},
{
"match": {
"actors.last_name": "Hopper"
}
}
]
}
}
}
}
]
}
}
}
// 对于 nested 的分桶聚合(普通 aggregation 对于 nested 无效)
POST my_movies/_search
{
"size": 0,
"aggs": {
"actors": {
"nested": {
"path": "actors"
},
"aggs": {
"first_name": {
"terms": {
"field": "actors.first_name",
"size": 10
}
}
}
}
}
}文档的父子关系 Parent / Child
Parent / Child
Q: 要使用 Parent / Child ?
A: 对象和 Nested 对象存在局限性: 每次更新时, 需要重新索引整个对象(包括根对象和嵌套对象)
ES 提供了类似关系型数据库的 Join 的实现, 使用 Join 数据类型实现, 通过维护 Parent / Child 的关系, 从而分离两个对象
- 父文档和子文档是两个独立的文档.
- 更新父文档无需重新索引子文档.
- 子文档被添加/更新/删除时, 也不会影响到父文档和其他子文档
Q: 如何定义父子关系
- 设置索引的 Mapping
- 索引父文档
- 索引子文档
- 按需查询文档
注意!!! Parent/Child 父子关系的文档在查询时, 查询速度会慢几百倍.
Nested 类型的数据查询时是会慢几倍.
与嵌套对象的对比

使用示例
创建索引
DELETE my_blogs
// 创建索引
PUT my_blogs
{
"settings": {
"number_of_shards": 2
},
"mappings": {
"properties": {
"blog_comments_relation": {
// 指定 join 类型
"type": "join",
// 声明 Parent / Child 关系
"relations": {
// blog 是 Parent
// comment 是 Child
"blog": "comment"
}
},
"content": {
"type": "text"
},
"title": {
"type": "keyword"
}
}
}
}写入数据
// 索引父文档, "blog1" 是父文档的 id
PUT my_blogs/_doc/blog1
{
"title": "Learning Elasticsearch",
"content": "learning ELK @ geektime",
"blog_comments_relation": {
// 申明文档的类型是 blog, 即作为 Parent
"name": "blog"
}
}
PUT my_blogs/_doc/blog2
{
"title": "Learning Hadoop",
"content": "learning Hadoop",
"blog_comments_relation": {
"name": "blog"
}
}
// 索引子文档, "comment1" 是子文档的 id, 指定 routing, 确保子文档和父文档索引到同一个分片
PUT my_blogs/_doc/comment1?routing=blog1
{
"comment": "I am learning ELK",
"username": "Jack",
"blog_comments_relation": {
"name": "comment",
// "blog1" 是父文档 id
"parent": "blog1"
}
}
PUT my_blogs/_doc/comment2?routing=blog2
{
"comment": "I like Hadoop!!!",
"username": "Jack",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}
PUT my_blogs/_doc/comment3?routing=blog2
{
"content": "Hello Hadoop",
"username": "Bob",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}查询
// 根据 Parent Id 查询所属的子文档
POST my_blogs/_search
{
"query": {
"parent_id": {
"type": "comment",
"id": "blog2"
}
}
}
// Has Child 查询, 根据子文档属性, 查询对应的父文档
POST my_blogs/_search
{
"query": {
"has_child": {
"type": "comment",
"query": {
"match": {
// 查找子文档(评论)中包含 "hadoop" 的父文档
"comment": "hadoop"
}
}
}
}
}
// Has Parent 查询, 根据父文档属性, 查询相关的子文档
POST my_blogs/_search
{
"query": {
"has_parent": {
"parent_type": "blog",
"query": {
"match": {
// 查找父文档(文章)中内容包含 "Hadoop" 的文章的所有子文档
"content": "Hadoop"
}
}
}
}
}
// 查询父文档时, 按照正常传入父文档 id 即可.
GET my_blogs/_doc/blog2
// 查询子文档时, 必须同时指定子文档id 和对应 routing 才能查询到
GET my_blogs/_doc/comment3?routing=blog2重建索引
需要重建索引的场景:
- 索引内的 Mappings 发生变更: 字段类型变更, 分词器及字典更新
- 索引的 Settings 发生变更: 索引主分片数发生改变
- 集群内, 集群间需要做数据迁移
ES 用于支持重建索引的内置 API
- Update By Query: 在现有索引上重建
- Reindex: 在其他索引上重建
举例:为索引增加子字段, 修改 Mappings 对已存在的文档无效

上述事例, 之前的 mappings 中content字段没有子字段english。并且已经索引了一条
content为 “Hadoop is cool” 的文档。为了提高查询 recall(召回率), 修改 mappings, 为
content添加了使用 english 分词器的子字段english.但对于之前已经索引的文档, 这个新的子字段是无效的(即不包含已索引的文档).
举例: 修改索引中已存在字段的类型时会报错
比如字段 title 之前是 text 类型, 现在将它修改为 keyword 类型时会报错提示无法修改字段类型, 只能创建新的索引, 并且设定正确的字段类型, 再重新导入数据.
Update By Query
在修改了 mappings , 添加新字段后, 可以使用 _update_by_query, 在原来索引上重建索引.

Reindex API
Reindex API : 支持把文档从一个索引(src)拷贝到另一个索引(dest), dest 索引必须提前创建, 允许时其他集群的索引.
使用的场景:
- 修改索引的主分片数
- 改变字段的 Mapping 中的字段类型
- 集群内数据迁移 / 跨集群的数据迁移
注意
- Reindex 的 src 索引必须启用
_source才可以(正常索引默认是启用的) - Reindex 并不会尝试去创建 dest 索引(并不会复制 src 的 settings 和 mappings), 因此需要自己提前创建好 dest 索引, 设定 settings 和 mappings
使用 Reindex API

使用 op_type 指定 reindex 的行为: 仅创建不存在的文档
正常情况下, 文档如果已经存在, 会导致版本冲突

跨集群 Reindex
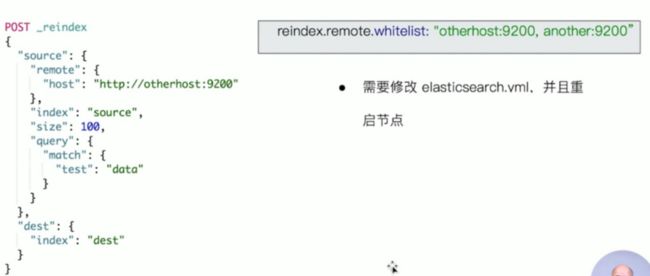
异步操作 Task API

Ingest Pipeline & Painless Script
ES 5.0 引入了 Ingest Node 节点类型. 默认情况下每个节点都是 Ingest Node:
- 具有预处理数据的能力, 能拦截 Index 和 Bulk API 的请求
- 对数据进行转换, 并重新返回给 Index 或 Bulk API
Ingest Node 提供了独立的数据预处理功能(无需 Logstash), 例如:
- 为某个字段设置默认值; 重命名字段名; 字段值分割
- 支持设置 Painless 脚本, 对数据进行更复杂的加工
Ingest Node v.s Logstash

Pipeline & Process
Pipeline: 管道会对通过的数据(文档)按照顺序进行加工
Process: ES 对一些加工行为的抽象包装
Pipeline 和 Process 的关系是 1:N
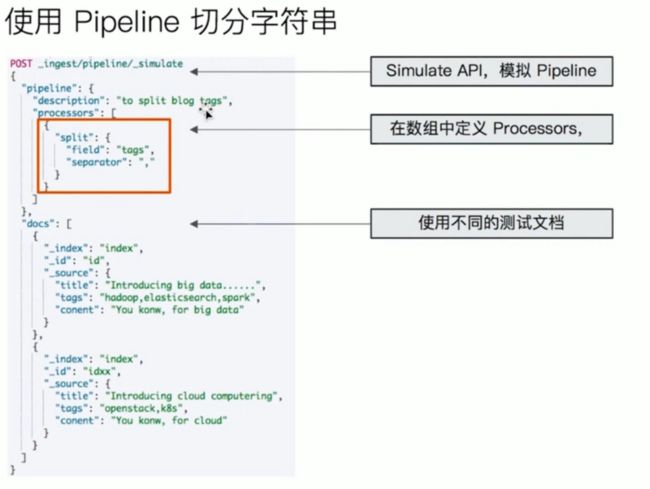
Simulate API 模拟 Pipeline
ES 提供了 Simulate API 用于模拟 Pipeline, 如下所示:
创建 Pipeline
在 ES 中创建一个 Pipeline

索引文档时使用 Pipeline

对已存在的文档引用 Pipeline
如果有部分文档需要重新应用 Pipeline, 那么可以使用 _update_by_query 来批量处理

这里使用了 query 根据条件筛选文档来重新应用管道, 若请求体为空, 则表示对所有文档都应用该管道.这里指定 update_by_query 的条件, 仅仅对特定文档进行处理(未被该管道处理过的), 确保不会发生错误.
内置的 Processes
部分内置的 Processors
https://www.elastic.co/guide/...


split
示例
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "...",
"processors": [
{
"split": {
"field": "test_field",
// 分割符
"separator": ";"
}
}
]
},
"docs": [
{
"_source": {
"test_field": "a;b;c"
}
}
]
}convert
https://www.elastic.co/guide/...
支持的转换类型:
- integer
- long
- float
- double
- string
- boolean
- auto
示例
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "...",
"processors": [
{
"convert": {
"field": "test_field",
"type": "integer",
"on_failure": [
{
"set": {
"field": "test_field",
"value": 0
}
}
]
}
}
]
},
"docs": [
{
"_source": {
"test_field": "123"
}
},
{
"_source": {
"test_field": "abc"
}
}
]
}date
关于 date process 支持的时间格式具体可以看: https://docs.oracle.com/javas...
其实采用的是 java 的日期时间 formatter 的模式.
grok
关于自带的 grok 模式可以查看: https://github.com/logstash-p...
这是中文版 https://www.cnblogs.com/zhang...
在定义 ingest pipeline 时, 建议使用 """ 来包裹 grok 表达式, 否则会各种蛋疼......
比如:
PUT _ingest/pipeline/php_fpm_log_pipeline
{
"description": "php-fpm 日志处理",
"processors": [
{
"grok": {
"field": "message",
"patterns": [
"""\[%{PHPFPM_TIMESTAMP:tmp.time}\] %{WORD:log.level}:\s*(\[pool %{WORD:fpm.pool}\])?\s*%{GREEDYMULTILINE:message}"""
],
"pattern_definitions": {
"PHPFPM_TIMESTAMP": """%{MONTHDAY}-%{MONTH}-%{YEAR} %{TIME}""",
"GREEDYMULTILINE": "(.|\n|\t)*"
},
"description": "提取时间和日志级别"
}
}
]
}一些方便的自定义 Grok 模式
// 匹配剩余的内容(多行)
GREEDYMULTILINE (.|\n|\t)*
Painless Scrit
ES 从 5.x 开始引入 Painless, 这是专门为 ES 设计并扩展了 Java 的语法.
6.0 开始, ES 只支持 Painless, 而不再支持之前的 Groovy, JS, Python 等脚本.
- Painless 支持所有 Java 的数据类型及 Java API 子集
- 特性: 高性能 / 安全, 其支持显示类型或者动态定义类型
理解为一种特殊的 Process ???
Painless 的用途

通过 Painless 脚本访问字段

一个示例
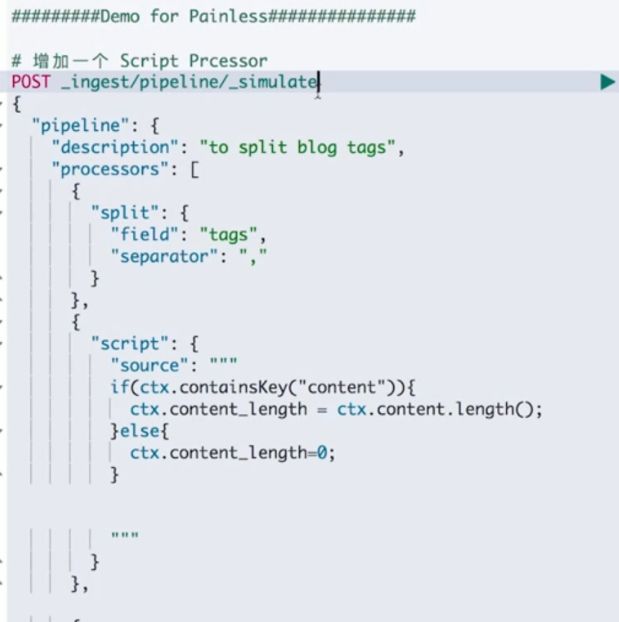

保存脚本在 Cluster State

示例: 返回数据前进行处理


ES 数据建模实例
什么是数据建模
数据建模(Data modeling) 是创建数据模型的过程:
- 是对真实世界进行抽象描述的一种工具和方法, 实现对现实世界的映射
- 三个过程: 概念模型 -> 逻辑模型 -> 数据模型(第三范式)
其中 数据模型 指结合具体的数据库, 在满足业务读写性能等需求的前提下, 确定的最终定义.
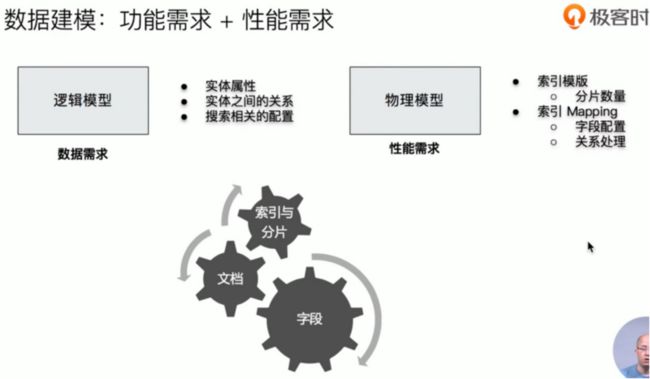
如何对字段进行建模
需要依次考虑的点
- 字段类型
- 是否需要搜索及分词
- 是否要聚合及排序
- 是否要额外的存储
同时善用相关 API
Index Template & Dynamic Template
- 根据索引的名字匹配不同的 Mappings 和 Settings
- 可以在一个 Mapping 上动态的设定字段类型
Index Alias
- 无需停机, 无需修改程序, 即可进行修改
- Update By Query & Reindex
考虑字段类型
Text v.s Keyword
Text
- 用于全文本字段, 文本会被 Analyzer 分词
- 默认不支持聚合分析及排序, 若需要的话则将该字段的 fielddata 设置为 true
Keyword
- 用于 id、枚举及不需要分词的文本 (如电话号码, email, 手机号码, 邮政编码, 性别等)
- 适用于 Filter (精确匹配), Sorting 和 Aggregation
设置多字段类型
- 默认会为文本类型设置成 text, 并且设置一个 keyword 的子字段
- 在处理人类语言时, 通过增加 "英文", "拼音" 和 "标准" 分词器, 提高搜索结构
对于结构化数据
数值类型
- 尽量选择贴近的类型 (例如能用 byte , 就不用 long)
枚举类型
- 设置为 keyword (即使是数字, 但若是仅用于枚举, 那么也应该设置成 keyword 以获得更好的性能)
其他
- 日期 / 布尔 / 地理信息
考虑搜索
- 如果字段不需要搜索、排序、聚合分析, 那么可以将
enabled设置为 false - 如果字段仅仅是不需要搜索, 那么可以将
index设置为 false 如果字段需要搜索
- 如果不需要算分, 那么可以将
norms设置为 false - 根据不同的需求, 设置对应的
index_options
- 如果不需要算分, 那么可以将
考虑聚合及排序
- 如果字段不需要搜索、排序、聚合分析, 那么可以将
enabled设置为 false - 如果字段不需要排序、聚合分析, 那么可以将
doc_values/fielddata设置为 false - 如果是更新频繁且聚合查询频繁的 keyword 类型, 那么推荐将
eager_global_ordinals设置为 true
考虑额外的存储
默认所有字段都会存储在 _source 中, 因此一般无需考虑将字段作额外的存储.
一般禁用 _source 的原因是
- 减少硬盘空间的占用(适用于指标性数据)
- 节省 I/O
但是如果仅仅是考虑到硬盘空间的占用, 那么应优先考虑 "增加压缩比 compression level", 而不是禁用 _source.
禁用 _source 存在的不便之处:
- 无法查看到 _source 字段
- 无法做 Reindex
- 无法做 Update 文档操作
若仅仅是为了在最终返回数据给客户端不返回 _source 字段, 那么使用 source filter 来控制即可, 无需禁用 _source.
一般来说, 是不建议禁用 _source 的!!!!
但是当我们确定要禁用 _source 时, 若需要额外存储某些字段, 则对这些字段可以设置 store 属性为 true.
几个简单示例
图书的索引

图书索引 - 需求变更 - 关闭 _source


ES 数据建模最佳实践
建议: 处理关联关系
对于关联关系
- 应优先考虑反范式(Denormalization), 即使用 Object 存储
若数据包含多数值对象, 同时有查询需求, 那么应使用 Nested 嵌套对象
比如电影需要存储多个演员的信息
当关联文档更新非常频繁时, 则应考虑使用 Child / Parent
比如文章和评论, 由于评论更新非常频繁, 因此评论不适合以 Nested 直接存储在文章中.
注意!!!!
Kibana 目前对于 nested 类型和 parent / child 类型支持不怎么好, 尽量在未来有可能更好的支持.
课堂上的 PPT 原文是写着说暂不支持.
- 如果需要使用 Kibana 进行数据分析, 在数据建模时仍需对嵌套和父子关联类型做出取舍
建议: 避免过多字段
一个文档中, 最好避免大量的字段:
- 过多的字段数不容易维护
Mapping 信息保存在 Cluster State 中, 数据量过大, 对集群性能会有影响
Cluster State 信息需要和所有节点同步
- 删除或者修改数据需要 reindex
默认的最大字段数是 1000
可以设置
index.mapping.total_fields_limit修改限定最大字段数
产生大量(成百上千)字段的原因: Dynamic Mapping
Dynamic:
- true: 未知字段会被自动加入索引
- false: 未知字段不会被自动加入索引, 但会保存在 _source
- strict: 未知字段会导致文档写入失败
控制到字段级别
建议生产环境不要使用 true, 谨慎使用 false, 推荐使用 strict.
还是得具体应用场景
示例: 使用 Cookie Service 不善导致的字段数量爆炸

上述问题的解决方案: Nested Object & Key Value

通过 Nested 对象保存 Key/Value 的优缺点
优点
- 有效地减少了字段数量
缺点
- 导致查询语句复杂度增加
- Kibana 的可视化分析对 Nested 对象支持不好
建议: 避免正则查询
问题
- 正则、通配符查询、前缀查询都属于 Term 查询, 但是性能不够好
- 若将通配符放在开头, 会导致性能的灾难
示例: 版本号查询
对于特定格式的版本号 主版本号.次版本号.bugfix版本号, 若我们直接用正则查询搜索版本字段(keyword 类型), 此时性能会很差.
但可以通过将字符串转换为对象来解决这个问题.

建议: 避免空值引起的聚合不准
字段的
null_value 设置项
示例: 空值导致聚合结果不准确

解决方案:
- 对于 rating 字段的属性, 设置其
null_value为 1 (根据业务来)
建议: 为索引的 Mapping 加入Meta信息

第二部分总结

Term 查询和基于全文 Match 搜索的区别
- 使用 Term 查询, 无论是查询 keyword 或 text 字段, 都不会对输入进行分词
使用 Match 查询则会对输入先进行分词, 再搜索
但若是对 keyword 字段进行查询, 此时 ES 会将本次的 Match 查询转换为 Term 查询, 且不对输入分词.

相关性的优化是一个迭代的过程, 因此建议使用 Search Template 来避免频繁修改代码.




