高效Transformer层出不穷,谷歌团队综述文章一网打尽

计算机视觉研究院专栏
作者:Edison_G

计算机视觉研究院
长按扫描二维码
关注我们 获取更多资讯
自 2017 年诞生以来,Transformer 模型在自然语言处理、计算机视觉等多个领域得到广泛应用,并出现了大量变体。近期涌现的大量 Transformer 变体朝着更高效的方向演化,谷歌研究者对这类高效 Transformer 架构进行了综述。

Transformer 是现代深度学习领域一股令人敬畏的力量,它广泛应用于语言理解、图像处理等多个领域,并产生了极大的影响。过去几年,大量研究基于 Transformer 模型做出基础性改进。人们对此的巨大兴趣也激发了对更高效 Transformer 变体的研究。
近期涌现了大量 Transformer 模型变体,研究者和从业者可能难以跟上创新的节奏。在该论文写作时(2020 年 8 月),之前的半年出现了十多个新的高效 Transformer 模型。因此,对已有文献进行综述对于社区而言是有益和及时的。
自注意力机制是 Transformer 模型的核心典型特征。该机制可被看作是一种类似图的归纳偏置,将序列中的所有 token 与基于相关性的池化操作连接起来。对于自注意力的一个担忧是其时空复杂度都是平方级的,这妨碍模型在多种环境下的可扩展性。最近出现了大量试图解决该问题的 Transformer 模型变体,本文将这类模型称作「高效 Transformer」(efficient Transformer)。
基于此,模型的效率有了不同的诠释。效率可能指模型的内存占用,当模型运行的加速器内存有限时这尤为重要;效率也可能指训练和推断过程中的计算成本,如 FLOPs 数。尤其对于设备端应用而言,模型应在有限的计算预算下运行。该综述论文从内存和计算两个角度来考虑 Transformer 的效率。
高效自注意力模型对于建模长序列的应用很关键,如通常包括较多像素或 token 的文档、图像和视频。因此,广泛采用 Transformer 优先考虑的是处理长序列的效率。
该论文旨在对这类模型的近期发展进行综述,主要聚焦于通过解决自注意力机制的平方级复杂度来提升 Transformer 效率的建模发展和架构创新,同时该论文还简要探讨了通用改进和其他效率改进。
该论文提出了一种针对高效 Transformer 模型的分类法,按照技术创新和主要用途进行分类。具体而言,该论文综述了在语言和视觉领域均有应用的 Transformer 模型,并为其中的部分模型提供了详细的解读。

论文链接:https://arxiv.org/pdf/2009.06732.pdf
关于 Transformer
Transformer 是将 Transformer 块一个个堆叠而成的多层架构,标准 Transformer 的架构如下图所示:
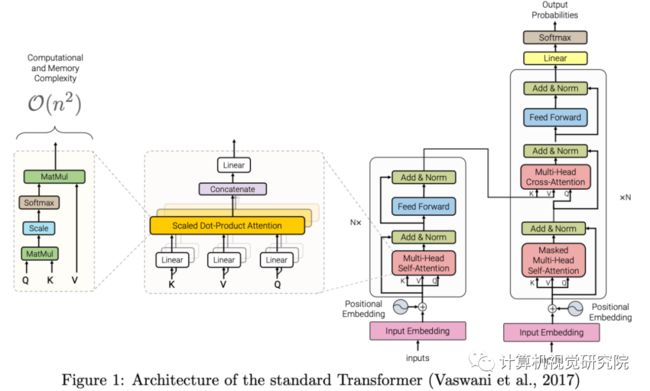
Transformer 块的特征是多头自注意力机制、position-wise 前馈网络、层归一化模块和残差连接。Transformer 模型的输入通常是形状为 R^B × R^N 的张量,B 表示批大小,N 表示序列长度。
输入首先经过嵌入层,嵌入层将每个 one-hot token 表示转换为 d 维嵌入,即 R^B × R^N × R^D 。然后将这个新的张量与位置编码(positional encoding)相加,并输入到多头自注意力模块中。位置编码可以采用正弦输入的形式,或者可训练嵌入。
多头自注意力模块的输入和输出由残差连接和层归一化层来连接。将多头自注意力模块的输出传送至两层前馈网络,其输入 / 输出通过残差和层归一化来连接。子层残差连接与层归一化可表示为:
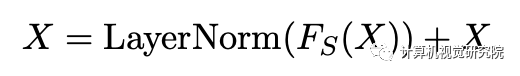
其中 F_S 是子层模块,它要么是多头自注意力,要么是 position-wise 前馈层。
高效 Transformer 模型综述
这部分对高效 Transformer 模型进行了综述。首先我们来看不同模型的特点,表 1 列出了目前发布的高效 Transformer 模型,图 2 展示了多种重要高效 Transformer 模型的图示。
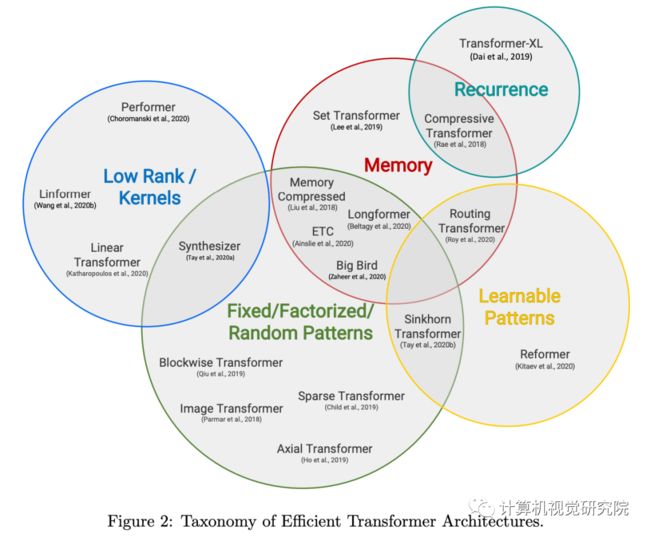
图 2:高效 Transformer 模型的分类,分类标准是模型的核心技术和主要应用场景。
表 1:按发布时间顺序整理的高效 Transformer 模型
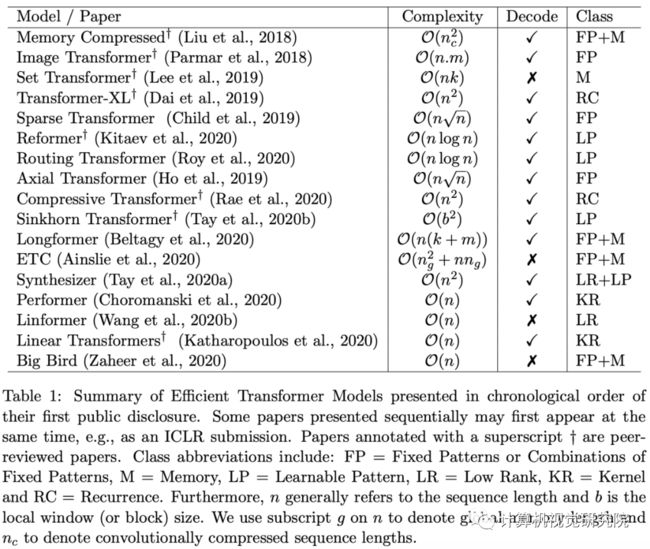
此外,这部分还详细介绍了多个重要的高效 Transformer 模型,并分析了它们的优缺点和独特之处。这些模型包括:Memory Compressed Transformer、Image Transformer、Set Transformers、Sparse Transformers、Axial Transformers、Longformer、ETC、BigBird、Routing Transformers、Reformer、Sinkhorn Transformers、Linformer、Synthesizers、Performer、Linear Transformers、Transformer-XL 和 Compressive Transformers。
具体细节此处不再赘述,详情参见原论文第三章。
论文最后讨论了这些模型的评估情况和设计趋势,并简要概述了可以提高 Transformer 效率的其他方法,如权重共享、量化 / 混合精度、知识蒸馏、神经架构搜索(NAS)和 Task Adapter。
/End.
我们开创“计算机视觉协会”知识星球一年有余,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

如果想加入我们“计算机视觉研究院”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
计算机视觉研究院
长按扫描二维码
关注我们 获取更多资讯