hadoop总结
hadoop总结
Hadoop第一天
1.Vmwarey有三种模式:桥接模式 ,nat模式,host-only模式 一般情况下 用nat
2./etc是配置文件的目录/var是储存各种变化的文件。
3.修改主机名:vi/etc/sysconfig/network 修改原 hostname 为 newname
4.修改ip:/etc/sysconfig/network-scripts/ifcfg-eth0,修改之后
service network restart
reboot
5.ssh (secure shell的缩写) 是一种网络安全协议,通过使用ssh,可以对传输过程的数据进行加密,可以有效的防止在远程管理的过程中信息的泄露。
6.用户名密码验证流程:1.客户端向服务端发送一个ssh请求2.服务端就收到请求之后发送公钥给客户端3.客户端在输入密码的时候通过公钥加密 回传给服务端4.服务端通过私钥解密验证用户名密码是否正确 验证成功正常登录,验证失败再次验证。
7.默认情况下,CentOS 系统会自带安装 OpenSSH 服务。 (openssh 提供了 scp:远程拷贝 slogin:远程登录 sftp:安全文件传输)
8.Service iptables stop:关闭防火墙(临时关闭,重启开机还需要再次关闭)
Service iptables start:开启防火墙
Service iptables restart:重启
chkconfig iptables off 永久关闭防火墙
设置三台机器同一个时间:date -s “2018-7-23 9:26:23”
免密登陆
ssh-keygen(生成密钥) 四次回车
Ssh-copy-id 机器名/ip地址(发送公钥到其他机器) 【将公钥写入到知道机器上的文件里去了】
8.域名映射:vi /etc/hosts(修改host的文件)
Ip 主机名
Ip 主机名()
Ip 主机名(位置顺序是不能变的)
Window下要需要配置 c/windows/system32/dirvers/etc/hosts
9.linux 和windows 操作系统之间的传输 sftp 和lrzsz 用lrzsz
先安装:yum -y install lrzsz 即可 rz上传 sz 下载
10.分发文件
Scp -r install.log root@node-01:/root/aaa (在第一台机器上的文件编辑过程中,copy 到其他机器上对应的文件)
分发多个文件
Scp -r 发送文件1 空格 发送文件2 root@node-01:/root/aaa
11.用户权限:
chmod u+rwx (给用户添加权限)
Chmod u-x (删除用户权限)
一次性控制
Chmod 777 文件
12.ps -ef | grep sshd 查找指定 ssh 服务进程
13.find . -name “*.log” -ls 在当前目录查找以.log 结尾的文件,并显示
14.Mkdir -p /root/demo/demo2 创建多级目录
vi hello1.sh
ll
chmod +x /hello1.sh
ll
chmod +x ./hello1.sh
./hello1.sh
vi hello1.sh
./hello1.sh
Set
例子:
#!/bin/bash
echo “第一个参数为: 1 " ; e c h o " 参 数 个 数 为 : 1"; echo "参数个数为: 1";echo"参数个数为:#”;
echo “传递的参数作为一个字符串显示:$*”;
测试: ./test.sh 1 2 3
运算:脚本 expr 是一款表达式计算工具,使用它能完成表达式的求值操作
val=expr 2 + 2
echo $val
(())和【】 也可以运算
脚本:count=1
((count++))
echo c o u n t a = count a= counta=((1+2))
a=$[1+2]
echo $a
set 命令查看当前环境变量
Hadoop第二天
Zookeeper 是一个分布式协调服务的开源框架。
ZooKeeper 本质上是一个分布式的小文件存储系统。
Zookeeper的特性:
1.全局数据一致性:集群的每个服务器都保存一份相同的副本。
2.可靠性:如果消息被一台服务器接收,那么消息将被所有的服务器接收。
3.顺序型:包括全局有序和偏序俩种;
4.数据更新的原子性:一次数据更新,要么成功(半数以上节点成功),要么失败。
5.实时性:zookeeper 可以保证客户端在一个时间间隔内获得服务器的更新信息,或者服务器的失效信息。
Zookeeper 的集群角色
1.Leader:对于 create,setData,delete 等有写操作的请求,则需要统一转发给
leader 处理.(写操作,保证事务的顺序性)
2.Follower:处理非事务的请求(读操作),转发请求给leader;参与集群leader的选举机制。
3.Observer:不会参与任何形式的投票,只提供非事务的请求。对于事物请求也转发给 leader。
Zookeeper 集群搭建:
zookeeper集群的搭建
-
配置文件
-
myid
操作记录
# 清理掉以往安装记录 在每台机器上都需要执行
rm -rf /export/servers/zk349/ && rm -rf /export/data/zk/ && rm -rf /export/logs/zk
# 在node01上解压zookeeper
tar -zxvf zookeeper-3.4.9.tar.gz -C /export/servers/
# 对安装目录进行修改
cd /export/servers/
mv zookeeper-3.4.9/ zk
# 修改配置文件
cd /export/servers/zk/conf
mv zoo_sample.cfg zoo.cfg
cat zoo.cfg |grep -v "#"
# 得到以下结果
---
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/export/data/zk
logDataDir=/export/logs/zk
clientPort=2181
---
# 新增服务器节点信息,参见完整配置文件。
---
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
---
# 分发到其他机器上
scp -r /export/servers/zk/ node02:/export/servers/
scp -r /export/servers/zk/ node03:/export/servers/
# 在每台机器上创建一个myid文件,并写入编号
# node01 上执行
mkdir -p /export/data/zk
touch /export/data/zk/myid
echo "1" > /export/data/zk/myid
# node02上执行
mkdir -p /export/data/zk
touch /export/data/zk/myid
echo "2" > /export/data/zk/myid
# node03上执行
mkdir -p /export/data/zk
touch /export/data/zk/myid
echo "3" > /export/data/zk/myid
# 启动服务,在每台机器上都执行一遍
cd /export/servers/zk/bin/
./zkServer.sh start
# 启动完之后确定状态
./zkServer.sh status
完整配置文件
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/export/data/zk
logDataDir=/export/logs/zk
clientPort=2181
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
注意事项
前提:首先 安装jdk which java
- node01 这是本机的域名,需要大家修改下。
- vi编辑器,需要先输入i,然后粘贴内容
- 每台机器上都需要启动
Zookeeper节点 分为顺序节点/临时节点和持久节点。
若不写-s/-e 默认是持久节点(手动删除才会删除)
创建a节点: create -s /test a (顺序节点)
Create -e /test a (临时节点)(会话结束,临时
节点将被自动删除)
Zookeeper 的数据结构:
每一个节点被称为Znode. znode由三部分组成。
1.start:此为状态信息,描述该znode的版本,权限等信息。
2.Data:是与该节点关联的数据。
3.children :该znode的子节点。
Znode 有一个序列化特性。
第三天 数据分析
大数据时代的来临:
公开数据显示,互联网搜索巨头百度 2013 年拥有数据量接近 EB 级别。阿
里、腾讯都声明自己存储的数据总量都达到了百 PB 以上。此外,电信、医疗、
金融、公共安全、交通、气象等各个方面保存的数据量也都达到数十或者上百 PB
级别。全球数据量以每两年翻倍的速度增长,在 2010 年已经正式进入 ZB 时代,
到 2020 年全球数据总量将达到 44ZB。
Kb mb gb tb pb eb zb yb bb
大数据:指的是针对海量数据处理。
云计算:指的是硬件资源虚拟化,为数据运行提供环境。
企业在运行大数据选择:
-用实体的服务器
-用云服务器
-共有云
-私有云
–混合云
数据分析 :按照数据分析的时效性,我们将数据分析分为 离线分析和实时分析俩种。
数据分析:是通过传统的统计方法对收集来的数据 进行数据分析。他能够帮助企业进行判断和决策,以便企业做出相应的决策和行动。数据分析分为:描述性数据分析、探索性数据分析、验证性数据分析。同时数据分析可以分析过去的数据 也就是离线数据分析、分析当下的数据也就是实时的数据 叫做实时分析、还可以对未来的数据进行分析 也就是我们说的机械学习,机械学习呢 主要是分类和聚类 然后预测数据。
数据分析目的是什么呢:是将隐藏在数据背后的信息集中的提炼出来 总结出所研究对象的内在规律帮助管理者进行有效的判断和决策。
数据分析在企业的日常经营分析中主要有三大作用:现状分析(告诉我们当前的状况)、原因分析(某一现状为什么发生)、预测分析(告诉我们将来会发生什么)
数据分析的步骤:明确分析的目的和思路------>数据收集—>数据处理—>数据分析—>数据展现---->撰写报告
怎样理解传统数据分析和和当下的大数据分析?
共同点:都是挖掘数据中的规律和价值
不同点:数据量变大以后,不管是分析的技术 还是分析的方式 传统分析的方式已经接应不暇 需要采用大数据技术
企业中:数据分析最终就是为了赚钱。
离线分析(处理)针对已有的历史数据 开展分析处理,批处理。
实时分析(处理)针对当下的数据实时分析。流(Stream)处理
Apache kafka
1.明确分析的目的和思路 (分析体系框架)
2.数据收集 :按照确定的数据分析框架,收集相关的数据的过程,他为数据分析提供了素材和依据。
一般数据主要来源有一下 几种:
数据库:每个公司都有自己的业务数据库
公开的出版物:
互联网:
市场调查:
3.数据处理:对收集来的数据进行加工和处理。数据处理主要包括:数据清洗、数据转化、数据提取、数据计算等处理方法。
4.数据分析:用适当的分析方法及工具,对处理过的数据进行分析,,提取有价值的信息
其中数据挖掘是一种高级的数据分析方法。
5.数据展现:数据是通过表格和图形的方式展现出来。也就是我们说的图表说话。
6.撰写报告:就是对整个分析过程的总结和呈现。
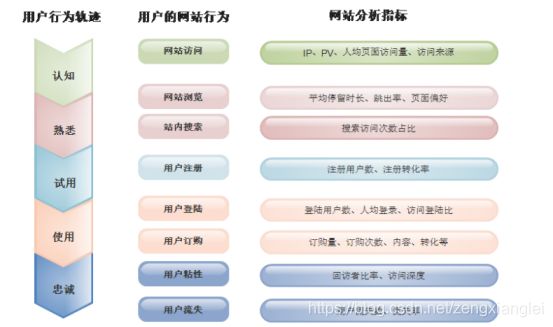
一、网站流量日志数据分析系统。
网站的访问者-----------网站服务器(log.文件)—工具提供商(数据处理服务器和分析报表服务器)-----------------------网站分析报表。
此系统存在的意义:帮助提高网站的流量,提升用户的体验,让客户更多的沉淀下来变成会员或者客户,通过更少的投入获得最大化收入。
改善网站的运营,获得更高的投资回报率(ROI).也就是赚更多的钱。
Windows中装载 就相当于将一个包解压 里面全是相关的rpm包。类似于一个中央仓库。
Linux 中 相当于 mount命令 mount -o loop /dev/cdrdom1 /root/itcast 【这里只是举一个例子 本地驱动
+cdrom】【在做本地yum源时 你需要将相关的镜像iso 上传到linux中,然后mount -o loop /路径.iso镜像 /目标目录。】 将cdrdom1装在到itcast 目录下 里面有package 目录 里面全是包
卸载:umount /root/itcast
比如:txt文件 用文本编辑器打开 doc用word打开 视频文件用播放器打开 而linux中的驱动 用mount 打开。
装载之后,itcast 文件中有俩个重要目录 package 和repodata package包 repodata: 包之间的依赖。
Yum源 有俩个配置 一是直接配置在/etc/yum.conf 中,其中包含一些
主要的配置信息。另外就是/etc/yum.repos.d/下的 xx.repo 后缀文件, 默认都
会被加载进来。
Rename .rep .repo.bat ./*.repo 将所有的repo文件改名 让其网络yum源失效
cp CentOS-Media.repo.bak CentOS-local.repo 开始配置本地yum源
将文件中的name 改为 this is my local yum source 0改为1
当本地已经安装了httpd
错误将卸载:yum
Rpm -qa yum 查看
Rpm -qa |grep yum |xargs rpm -e --nodeps 卸载和yum有关的所有组件
Rmp -qa yum 再次查看 没有了
Yum clear all :清理yum源让刚才修改生效。
本地yum源可以解决网络不好的情况下,yum时间过长的问题,但是本地yum源也有其明显的弊端,就是yum源的版本过旧不能随时更新。如果你想换回以前的yum源,将之前备份的repo文件恢复过来,再执行yum clean all和yum repolist all查看一下是否改变
Service httpd status
Service httpd start
Service httpd stop
Httpd -v 查看httpd版本
httpd是Apache超文本传输协议(HTTP)服务器的主程序。被设计为一个独立运行的后台进程,它会建立一个处理请求的子进程或线程的池。
A类网络的IP地址范围为1.0.0.1-127.255.255.254;第一个八位 是网络地址 后三个八位是主机地址。
B类网络的IP地址范围为:128.1.0.1-191.255.255.254;第二个八位是网络地址,剩下的三个是主机地址。
C类网络的IP地址范围为:192.0.1.1-223.255.255.254;第三个八位是网络地址,剩下的三个是
Node 1 上 装httpd 相当于tomcat (apche) index.html 在此机器上 【cd /var/www/html】
查看 httpd 开启状态: service httpd status
启动 httpd :service httpd start
Node3 部署上nginx 【cd /usr/local/nginx/html】
查看nginx 状态:ps -ef|grep nginx
启动nginx cd/usr/local/nginx sbin/nginx -c conf/nginx.conf
停止nginx: sbin/nginx –s stop
tail -f logs/access.log
Linux 系统下 nginx 不支持 中文,会将中文转为16进制
网站浏览日志:埋点 (分为俩种 一是· 可视化埋点 二是代码埋点)
第四天:Hadoop
Hadoop 是apache旗下的一个用Java语言实现的开源的软件框架。
允许在简单的编程模型在大量的计算机集群上对大型数据集进行分布式处理。
Hadoop 的几个核心组件:
Hdfs : (分布式文件系统) 结局海量数据的存储。
Yarn:(作业调度和集群资源管理的框架): 解决资源任务调度。
Mapreduce ( 分布式运算编程框架) :解决海量数据的计算。
Hadoop 生态圈:
Hdfs : (分布式文件系统) 结局海量数据的存储。
Mapreduce ( 分布式运算编程框架) :解决海量数据的计算
Hive:基于Hadoop的分布式数据仓库,提供基于sql的查询数据操作。
Hbase:基于Hadoop的分布式海量数据库。
Zookeep:分布式协调服务基础组件。
Mahout:基于mapreduce/spark/flink等分布式运算框架的机械学习算法库。
Flume:日志数据采集框架。
Impala:基于Hadoop的实时分析。
Hadoop的特点:
扩容能力: Hadoop是在可用计算机集群中分配数据并完成计算任务的,可以扩展到数以千计的节点中。
成本低:Hadoop 只需要通过普通的机器组成服务器集群来分发以及处理数据即可。
高效率:通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
可靠性:能自动维护数据的多分复制,并且在任务失败后能自动的重新部署计算任务。所以Hadoop按位存储和处理数据的能力值得人信赖。
Apache Hadoop 2.7.4
Hadoop集群一般来讲包含俩个集群:hdfs 集群和yarn集群,俩个逻辑上分离,但物理上常在一起。
Hdfs集群:负责海量数据的存储,主要角色有:
namenode ,datanode,secondaryNameNode.
yarn集群:负责海量数据运算是的资源的调度, 主要角色有:
ResourceManager 、NodeManager
而mapreduce 主要是一个分布式运算框架,主要是打包后运行在hdfs集群上,并且受到yarn集群的资源管理调度。
Hadoop部署有三种方式:独立模式、伪分布式模式、集群模式。我们主要学的是集群模式。
Hadoop 开始安装:
前提步骤:
1.同步多台服务器时间。
date -s “2017-03-03 03:03:03”
或则同步网络时间: yum install ntpdate 然后 ntpdate cn.pool.ntp.org
2.设置主机名:
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node-1
3.配置 IP 、主机名 映射
vi /etc/hosts
192.168.33.101 node-1
192.168.33.102 node-2
192.168.33.103 node-3
4.配置 h ssh 免密登陆
#生成 ssh 免登陆密钥
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成 id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上
ssh-copy-id node-02
5.查看防火墙状态
Service iptables status
关闭防火墙:chkconfig iptables off(永久,开机关闭)或则 service iptables stop
7.jdk环境安装
安装hadoop 开始:
上传 Hadoop 解压
bin:Hadoop 最基本的管理脚本和使用脚本的目录
etc:Hadoop 配置文件所在的目录,包括 core-site,xml、hdfs-site.xml、
mapred-site.xml 等从 Hadoop1.0 继承而来的配置文件和 yarn-site.xml 等
Hadoop2.0 新增的配置文件。
include:对外提供的编程库头文件(具体动态库和静态库在 lib 目录中),
这些头文件均是用 C++定义的,通常用于 C++程序访问 HDFS 或者编写 MapReduce
lib:该目录包含了 Hadoop 对外提供的编程动态库和静态库,与 include 目
录中的头文件结合使用。
libexec:各个服务对用的 shell 配置文件所在的目录,可用于配置日志输
出、启动参数(比如 JVM 参数)等基本信息。
sbin:Hadoop 管理脚本所在的目录,主要包含 HDFS 和 YARN 中各类服务的
启动/关闭脚本。
share:Hadoop 各个模块编译后的 jar 包所在的目录。
要修改的配置文件
1.Hadoop-env.sh :配置java_home
vi hadoop-env.sh
export JAVA_HOME=/root/apps/jdk1.8.0_65
- core-site.xml :用来设置Hadoop的文件系统,由uri指定 以及配置Hadoop的临时目录。
- hdfs-site.xml :指定hdfs的副本数量,以及secondary namenode 所在主机的ip和端口
- mapred-site.xml :指定mr运行时框架,在yarn上。默认是local
- Yarn-site.xml :配置resourcemanager 和nodemanager
- Slaves :note1 note2 note3
7.Vi /etc/profile
export JAVA_HOME= /root/apps/jdk1.8.0_65
export HADOOP_HOME= /root/apps/hadoop-2.7.4
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin: H A D O O P H O M E / b i n : HADOOP_HOME/bin: HADOOPHOME/bin:HADOOP_HOME/sbin
保存配置文件,刷新配置文件:
source /etc/profile
Hadoop 环境首次搭建完成之后 ,hdfs需要格式化(可以理解为初始化)
在主机上 执行:hdfs namenode - format (切记:此操作只能在hadoop环境刚搭建完成后 执行,不然要跑路了,其主要目的就是初始化时建一些自己的文件目录)
结果会有这个地址:/export/data/hddata/dfs/name/current

???万一执行了多次 format 怎么办
到core-site.xml 中,将hadoop.tmp.dir指定的目录全部删除,在重新执行一下format
单节点一一启动:【一键启动只需要在那台主机上操作即可但单节点启动 则datanode 和se… 都需要在各自的机器上启动】
启动hdfs namenode :hadoop-daemon.sh start namenode
启动hdfs datanode :hadoop-daemon.sh start datanode
启动 yarn resourcemanager :yarn-daemon.sh start resourcemanager
启动 yarn nodemanager :yarn-daemon.sh start nodemanager
停止 将start 改为stop即可。
脚本一键启动: hdst 一键启动 :start-dfs.sh
Yarn 一键启动 :start-yarn.sh
整体hdsf和yarn 一键启动 :start-all.sh
停止的话:都是将 start 改为 stop 即可。
Hadoop 页面初级体验 通过webui 既浏览器
查看:nn(namenode所在机器ip+ 端口:50070)【相当于 hdfs文件存储系统查看】
查看:resourcemanager 所在机器ip+端口:8088 【相当于 yarn 资源调度系统查看】
在主机上:创建input目录命令:hadoop fs -mkdir -p /wordcount/input【此时hdfs文件系统 utilities 中可以看到创建的目录 note1:50070】
主机上也可以查看:hadoop fs -ls / 【/查看根目录下目录】
如何将linux系统中本地文件 上传到 hdfs文件系统中?
Hadoop fs -put /root/a.txt /wordcount/input 【/root/a.txt :Linux本地位置文件,/wordcount/input hdfs系统文件目录】
Hdfs前言:
Hdfs最核心的就是 namenode和 datanode 以及 SecondaryNameNode
Namenode : namenode是hdfs的核心,也叫master 。其仅存储元数据,不存储实际的数据,实际的数据存储在datanode中,namenode知道hdfs中任何给定文件块列表及其位置信息。
Namenode 对hdfs至关重要,当namenode关闭时,hdfs/hadoop 集群无法访问。
Datanode :datanode 负责将实际的数据存储在hdfs中,datanode 也叫slave. namenode和datanode 保持不断通信。Datanode启动时会将自己发不到namenode并汇报自己负责持有的块列表。当某个datanode关闭时不会影响数据或则集群的可用性。因为namenode将会安排其他的datanode 来负责管理当前关闭的datanode的块进行副本复制。Datanode所在机器需要配置大量的硬盘空间,因为实际数据存储在datanode中。
同时datanode会定期向namenode(dfs.heartbeat.interval 配置项配置,默认是 3 秒) 发送心跳,如果namenode长时间没有接收到datanode发送的心跳,namenode就是认为datanode失效。
Block汇报的时间间隔取决于参数dfs.blockreport.intervalMSec,参数如果未配置的话,默认时间的6小时。
Hdfs 初级体验
Namenode :任何访问操作都是通过namenode 发起的(namenode 保存了文件系统的元数据)
元数据:文件目录结构、文件跟block(分“块”存储)之间的对应信息可以理解为位置信息、跟datanode状态相关的信息(磁盘使用率和datanode生死)。
1.Hdfs 文件系统唯一访问路径: hadoop fs -ls hdfs://namenode:port/ (例如:hadoop fs -ls hdfs://namenode:9000) 【也可以默认:hadoop fs -ls /】【因为在hadoop 的core-site.xml中配置了fs.defaulfFS地址:hdfs://note1:9000】】
2.还有个note1:50070 这个是 webui 网页访问路径。
3.1中的hdfs 可以跟换成其他 如:file 代表访问本地Linux系统指定目录文件。
4.访问Linux本地 hadoop fs file:///root/
相关命令:
Hadoop fs -ls hdfs://note1:9000/ 【查看hdfs文件系统根目录文件】
Hadoop fs -ls file:///root/ 【查看linux本地根目录文件】
Hadoop fs -count file:///root/ 【查看Linux本地根目录下的文件(夹)数量及大小】 目录多少 ,文件数量,所有文件大小
Hadoop fs -count hdfs://note1:9000/ 【查看hdfs文件系统根目录下文件(夹)数量及大小】
同时还有以下 很多 shell命令 :
选项名称 使用格式 含义
-ls -ls <路径> 查看指定路径的当前目录结构
-lsr -lsr <路径> 递归查看指定路径的目录结构
-du -du <路径> 统计目录下个文件大小
-dus -dus <路径> 汇总统计目录下文件(夹)大小
-count -count [-q] <路径> 统计文件(夹)数量
-mv -mv <源路径> <目的路径> 移动
-cp -cp <源路径> <目的路径> 复制
-rm -rm [-skipTrash] <路径> 删除文件/空白文件夹
-rmr -rmr [-skipTrash] <路径> 递归删除
举例: hadoop fs -rm -r -skipTrash /wordcount
Hadoop fs -rm -r /wordcount/input/*
-put -put <多个 linux 上的文件>
-copyFromLocal -copyFromLocal <多个 linux 上的文件>
从本地复制
-moveFromLocal -moveFromLocal <多个 linux 上的文件>
从本地移动
-getmerge -getmerge <源路径>
-cat -cat
-text -text
-copyToLocal -copyToLocal [-ignoreCrc] [-crc] [hdfs
源路径] [linux 目的路径]
从本地复制
-moveToLocal -moveToLocal [-crc]
从本地移动
-mkdir -mkdir
-setrep -setrep [-R] [-w] <副本数> <路径> 修改副本数量
-touchz -touchz <文件路径> 创建空白文件
-stat -stat [format] <路径> 显示文件统计信息
-tail -tail [-f] <文件> 查看文件尾部信息
-chmod -chmod [-R] <权限模式> [路径] 修改权限
-chown -chown [-R] [属主][:[属组]] 路径 修改属主
-chgrp -chgrp [-R] 属组名称 路径 修改属组
-help -help [命令选项] 帮助
虚拟机 一台主机打不开 报:打不开磁盘“I:\xxx.vmdk”或它所依赖的某个快照磁盘
这是因为非正常关闭虚拟机造成的。在每次正常启动虚拟机时都会给每个虚拟磁盘加一个磁盘锁(也就是.lck文件夹 文件夹下有个文件 里面好像是uuid什么的),正常关闭时会将.lck文件夹自动删除,但非正常关闭不会自动删除.lck文件。 这时只需要将报错路径vmk对应的.lck文件夹删除即可。
工作机制:虚拟机为了防止有多台虚拟机共用一个虚拟磁盘(就是后缀为.vmdk那个文件)造成数据丢失和性能的 消弱,每次启动虚拟机时会给每个虚拟磁盘加一个磁盘锁
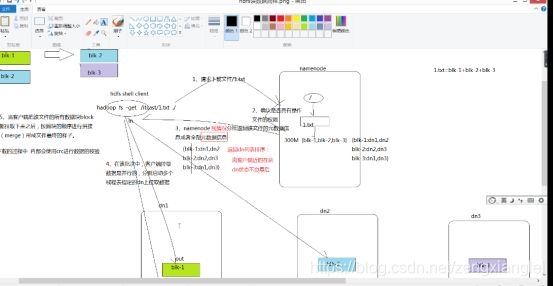
以上是 在node1主机上 有一个 1.txt文件 分成三块 备份副本数为2
Node1 : blk-1 ,blk-3
Node2 :blk-2,blk-1
Node3 :blk-3,blk-2
1.请求下载文件
2.确认是否具有操作文件的权限
3.Namenode 视情况分批返回该文件的元数据信息或者全部元数据信息。
4.在该批次中,客户端拉取数据是并行的,分别启动多线程提取指定的dn上拉取数据。
5.当客户端吧该文件的所有数据块block拉取下来之后,需要按照块的顺序进行拼接(merge)形成文件的最终样子。 【blk-1,blk-2,blk-3】
6.在拉取过程中 内部会使用crc进行校验。
Windom系统下 安装hadoop 并通过java代码操作hdfs (相当于windows 系统下 hdfs client)
1.首先配置全局JAVA_HOME ; PATH ;HADOOP_HOME;PATH (windows系统下安装hadoop时,给的有一个hadoop 包解压即可。已上传百度云)
2.查看hadoop是否安装成功 hadoop ;hadoop version
3.Hadoop version 不成功 ,一般是因为 到hadoop 安装目录下 etc/hadoop/hadoop-env.cmd 找到set JAVA_HOME=D:\PROGRA~1\Java\jdk1.8.0_141 即可。
代码:
创建 Maven 工程,引入 pom 依赖
org.apache.hadoop
hadoop-common
2.7.4
org.apache.hadoop
hadoop-hdfs
2.7.4
org.apache.hadoop
hadoop-client
2.7.4
配置maven仓库。配一下 (视频中没配)
创建包 cn.itcast
创建类 HdfsClient 主方法
直接使用 pom中 引入的 FIleSystem.get(new URI(“hdfs://note1:9000”),conf,”root”)
public class HDFSClient {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// conf.set("fs.defaultFS","hdfs://note1:9000");
FileSystem fs = FileSystem.get(new URI("hdfs://note1:9000"), conf, "root");
fs.mkdirs(new Path("/CreateByJava"));
fs.copyFromLocalFile(new Path("d://1.txt"),new Path("/CreateByJava"));
fs.copyToLocalFile(false,new Path("/CreateByJava/1.txt"),new Path("e:\\"),false);
fs.close();
}
}
在上传可以成功,但下载是个空文件 ,而且报一下错误:
Exception in thread “main” ExitCodeException exitCode=-1073741515:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:585)
at org.apache.hadoop.util.Shell.run(Shell.java:482)
红字错误:是因为缺失 api-ms-win-crt-string-l1-1-0.dll 丢失
然后在网上查找了:并下载 放置到了 c:\Windows\SysWOW64 下 并win+r 输入:regsvr32 c:\Windows\SysWOW64\api-ms-win-crt-string-l1-1-0.dll

Windows :ipconfig /all 可以查看机械码(也就是mac地址)
=========================================================
shell规范化编程:
- 定义跟本次shell运行相关的软件环境变量
- 定义本次shell当中的一些常量变量 比如:路径 时间 类名 属性等等 便于后期集中维护
- 本次shell的核心逻辑(要结合流程控制 做精准判断)
1.在linux中创建 一个shell文件: vi file2hdfs.sh
2.粘贴一下代码:
3.chomd 777 file2hdfs.sh
4.sh file2hdfs.sh
5.访问note1:50070 查看文件是否上传成功。
#!/bin/bash
#set java env
export JAVA_HOME=/usr/jdk
export JRE_HOME= J A V A H O M E / j r e e x p o r t C L A S S P A T H = . : {JAVA_HOME}/jre export CLASSPATH=.: JAVAHOME/jreexportCLASSPATH=.:{JAVA_HOME}/lib: J R E H O M E / l i b e x p o r t P A T H = {JRE_HOME}/lib export PATH= JREHOME/libexportPATH={JAVA_HOME}/bin:$PATH
#set hadoop env
export HADOOP_HOME=/export/servers/hadoop
export PATH= H A D O O P H O M E / b i n : {HADOOP_HOME}/bin: HADOOPHOME/bin:{HADOOP_HOME}/sbin:$PATH
#日志文件存放的目录
log_src_dir=/root/logs/log/
#待上传文件存放的目录
log_toupload_dir=/root/logs/toupload/
#日志文件上传到hdfs的根路径
date1=date -d last-day +%Y_%m_%d
hdfs_root_dir=/data/clickLog/$date1/
#打印环境变量信息
echo “envs: hadoop_home: $HADOOP_HOME”
#读取日志文件的目录,判断是否有需要上传的文件
echo “log_src_dir:”$log_src_dir
ls l o g s r c d i r ∣ w h i l e r e a d f i l e N a m e d o i f [ [ " log_src_dir | while read fileName do if [[ " logsrcdir∣whilereadfileNamedoif[["fileName" == access.log.* ]]; then
# if [ “access.log” = “$fileName” ];then
date=date +%Y_%m_%d_%H_%M_%S
#将文件移动到待上传目录并重命名
#打印信息
echo “moving l o g s r c d i r log_src_dir logsrcdirfileName to KaTeX parse error: Expected group after '_' at position 33: …xxxxx_click_log_̲fileName”$date"
mv l o g s r c d i r log_src_dir logsrcdirfileName KaTeX parse error: Expected group after '_' at position 33: …xxxxx_click_log_̲fileName"$date
#将待上传的文件path写入一个列表文件willDoing
echo KaTeX parse error: Expected group after '_' at position 33: …xxxxx_click_log_̲fileName"$date >> l o g t o u p l o a d d i r " w i l l D o i n g . " log_toupload_dir"willDoing." logtouploaddir"willDoing."date
fi
done
#找到列表文件willDoing
ls KaTeX parse error: Expected 'EOF', got '#' at position 89: … read line do #̲打印信息 echo "tou…line
#将待上传文件列表willDoing改名为willDoing_COPY_
mv l o g t o u p l o a d d i r log_toupload_dir logtouploaddirline l o g t o u p l o a d d i r log_toupload_dir logtouploaddirline"COPY"
#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名) ,此处的line 就是列表中的一个待上传文件的path
cat l o g t o u p l o a d d i r log_toupload_dir logtouploaddirline"COPY" |while read line
do
#打印信息
echo “puting… l i n e t o h d f s p a t h . . . . . line to hdfs path..... linetohdfspath.....hdfs_root_dir”
hadoop fs -mkdir -p $hdfs_root_dir
hadoop fs -put $line $hdfs_root_dir
done
mv l o g t o u p l o a d d i r log_toupload_dir logtouploaddirline"COPY" l o g t o u p l o a d d i r log_toupload_dir logtouploaddirline"DONE"
done
MapReduce
MapReduce 是一个分布式运算程序的编程框架,核心功能是将用户编写的业
务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在
Hadoop 集群上。
mapReduce 的核心思想是 分而治之。
Map 负责分,reduce 负责合。【map 分的原则是,数据不重复 数据不遗漏】
之所以分是为了并行计算 提高效率。
不见得都可以分:任务不可拆分的,以及有依赖关系的【比如 3依赖2 ,2依赖1 这样会影响效率我们的目的的并行执行提高效率】
Reduce 就是针对map阶段的结果进行汇总。
既然是做计算的框架,那么表现形式就是有个输入(input),MapReduce 操
作这个输入(input),通过本身定义好的计算模型,得到一个输出(output)。
一、Hadoop MapReduce 构思体现在如下的三个方面:
1.如何对付大数据处理:分而治之
2.构建抽象模型:Map 和 Reduce
Map: 对一组数据元素进行某种重复式的处理;
Reduce: 对 Map 的中间结果进行某种进一步的结果整理。
MapReduce 处理的数据类型是
3.统一构架,隐藏系统层细节
MapReduce 最大的亮点在于通过抽象模型和计算框架把需要做什么(what
need to do)与具体怎么做(how to do)分开了,为程序员提供一个抽象和高层的编
程接口和框架。
二、Mapreduce 框架结构:
一个完整的mapreduce 框架由三个实例进程:
1.MRAppMaster :负责整个程序的过程调度以及状态协调。
2.MapTask :负责map阶段的整个数据的处理。
3.ReduceTask :负责reduce阶段的整个数据的处理。
三、Mapreduce 的编写规范:
(1)用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行 mr 程
序的客户端)
Mapper 的输入数据是 KV 对的形式(KV 的类型可自定义)
(3)Mapper 的输出数据是 KV 对的形式(KV 的类型可自定义)
(4)Mapper 中的业务逻辑写在 map()方法中
(5)map()方法(maptask 进程)对每一个
(6)Reducer 的输入数据类型对应 Mapper 的输出数据类型,也是 KV
(7)Reducer 的业务逻辑写在 reduce()方法中
(8)Reducetask 进程对每一组相同 k 的
(9)用户自定义的 Mapper 和 Reducer 都要继承各自的父类
(10)整个程序需要一个 Drvier 来进行提交,提交的是一个描述了各种必要信
息的 job 对象
Mapreduce 的wrodcount 小程序:
1.创建maven工程 引入 pom.xml
org.apache.hadoop
hadoop-common
2.7.4
org.apache.hadoop
hadoop-hdfs
2.7.4
org.apache.hadoop
hadoop-client
2.7.4
org.apache.hadoop
hadoop-mapreduce-client-core
2.7.4
org.apache.maven.plugins
maven-jar-plugin
2.4
true
lib/
cn.itcast.mapreduce.WordCountDriver
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
2.创建一个wrodCountMapper 类 继承Mapper
KEYIN:map输入中的key
在默认读取数据的组件下textInputFormat(一行一行读)
Key:表示是该行的起始偏移量(就是光标所在的位置值)longwritable
Value:表示该行的内容
VALUEIN:map输入kv中的value
在默认读取数据的组件下TextInputFormat(一行一行读)
表明的是内容 (string—>text)
KEYOUT:map输出的kv中的key
在我们的需求中 把单词作为输出的key (string -->text)
VALUEOUT:map输出kv中的value
在我们的需求中 把单词的次数1作为输出的value (int–>intwritable)
简而言之:keyin 读取文本光标的偏移量,valuein:读取文本时该行文本的内容 相当于map输入中的key.keyout:map输出时的key ;valueout:map输出时的value:数值 intwritable
核心命令:
hadoop fs -mkdir -p /wordcount/input
hadoop fs -put -p /root/wenben/a.txt /wordcount/input
hadoop fs -ls /
hadoop fs -cat /wordcount/input/a.txt
Hadoop fs -rm -r /wordcount/output
Hadoop jar jar包 ;//hadoop 执行jar【在hadoop 集群上执行】
2.Mapreduce 统计单词数 案例:
创建maven 工程

1.* key:偏移量 没啥用
* value:map输入时读取文本文件其中的一行数据
* context:mapreduce 封装好的输出对象。
*
*
*
* */
public class WrodCountMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
String[] words = line.split(" ");
for (String word:words
) {
context.write(new Text(word),new IntWritable(1));
}
}
}
2./*
* key :就是每个单词
* values: 相当于处理后的单词 如:hadoop[1,1,1]
* context :是mapreduce 封装好的输出对象
* */
public class wordCountReduce extends Reducer{
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count=0;
for (IntWritable value :
values) {
count +=value.get();
}
context.write(key,new IntWritable(count));
}
3.public class WordCountDirver {
public static void main(String[] args) throws Exception {
Configuration conf= new Configuration();
conf.set("mapreduce.framework.name","yarn");
Job job = Job.getInstance(conf);
//指定本次mr程序运行的主类
job.setJarByClass(WordCountDirver.class);
//指定本次mr运行程序的mapper 和reducer
job.setMapperClass(WrodCountMapper.class);
//指定本次Mr程序的reducer
job.setReducerClass(wordCountReduce.class);
//指定本次mr程序map阶段的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定本次mr程序reducer阶段的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定要处理的数据所在位置
FileInputFormat.setInputPaths(job,new Path("hdfs://note1:9000/wordcount/input"));
FileOutputFormat.setOutputPath(job,new Path("hdfs://note1:9000/wordcount/output"));
//想yarn 集群提交job job.submit(); 这个我们看不到日志 一般不用 用下面job.waitForCompletion(true) true:代表监控并打印输出
job.waitForCompletion(true);
}
}
遇到的问题:
Yarn 网页端口: note1:8088 监控不到 原因:
修改集群配置文件yarn-site.xml,加上如下几句:
mapreduce.framework.name
yarn
遇到的问题二:结果成功输出 但报 inter… thread wait jion 等问题?
解决:在driver类中 添加 就是将mapreduce 提交到哪里去 也是yarn-site.xml 配置的 《property》
conf.set(“mapreduce.framework.name”,“yarn”);
同时这是指在yarn集群上运行
但是如果代码有问题,我们有需要重新打包 等一系列操作 太麻烦。
我们可以现在本地上运行,测试有没有bug
本地运行:只需要将conf.set(“mareduce.framework.name”,”local”)
还需要将 读取的文件路径和输出的路径改成windows本地地址即可。
Mapreduce 的分区:
第一阶段:逻辑切片
1.txt 200M 2.txt 100M split size=128m
0-128m;128m-200m;0-100m
问:mapreduce 的maptask的多少取决于什么?
1.待处理文件的个数;【举例:size=1G;三个文件都是1K;则maptask 有三个】
2.待处理文件的大小;
3.Split size的大小。
二、- 问:mapreduce 有多少个reducetask,取决于什么?
- job.setNumReduceTasks(N) 代码直接决定
同时者n 的多少 要考虑到 mapreduce 自身的一个分区接口。接口中自己可以根据自己的业务逻辑 将业务数据分成几个 如 手机号:《135,0》《136,1》《137,2》在接口中分成了3个,job.setNumReduceTasks(3)最合适。
若n =4.则产生4个文件,但有个文件为空。【reducetask >分区个数】
若n=2.则产生2个文件, 【reducetask <分区个数】
Mapreduce 的执行流程 还有俩个案例已经 在自己博客中写了

我们不用考虑 key的分组 排序 分区 这些都是mapreduce 内部已经帮我们处理好了。所以我们操作mapreduce 是简单。
Mapreduce 的序列化(Serialization):
序列化(Serialization):是指将结构化数据转化成字节流
下面做几个案例:
一、
Flume :
Flume 安装 上传包 解压
到 conf 目录下
flume.env.sh 配置 jdk 即可
vi netcat-logger.conf
# 定义这个 agent 中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = logger
# 描述和配置 channel 组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置 source channel sink 之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
简单测试案例:yum install telnet ;telnet localhost 44444; 输入 hello【前提 下面执行命令 已经执行】
执行命令:bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
Flume 案例二:
需求:服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,
就需要把文件采集到 S HDFS 中去
Vi spooldir-hdfs.conf
文件内容:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
##注意:不能往监控目中重复丢同名文件
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/logs
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是 Sequencefile,可用 DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
Mkdir logs2
Cp a.txt logs2 【前提执行flume命令,cp 后查看结果】
执行命令:
bin/flume-ng agent -c conf -f conf/spooldir-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
案例二结束
案例三:
需求:比如业务系统使用 j log4j 生成的日志,日志内容不断增加,需要把追
加到日志文件中的数据实时采集到 hdfs【简而言之:一个文件的内容在变化】
Vi tail-hdfs.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/test.log #数据源路径
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H%M/ #文件目录
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10 #10分钟产生一个文件夹
a1.sinks.k1.hdfs.roundUnit = minute #分钟
a1.sinks.k1.hdfs.rollInterval = 3 #时间间隔3秒 滚动一次
a1.sinks.k1.hdfs.rollSize = 20 #hdfs文件20k 滚动一次 默认1024k
a1.sinks.k1.hdfs.rollCount = 5 #数量为5个 滚动一次
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是 Sequencefile,可用 DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000 #【最多放1000个events】
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
企业中可能遇见的一个问题:spooldir 监控的目录文件 有重复名的话会报错且罢工!
在企业中如何控制文件的产生 文件名不同 我们20150109-01.log【我们文件名产生前用时间控制文件名 年月日小时 每一个小时的数据存储在一个文件中。这样就保证了 数据源文件名的不重复。
如何模拟一个不断变化的文件。 shell 循环
直接敲命名:while true;do date >> test.log;sleep 0.5;done
或者 写shell 脚本
#!/bin/bash
while true
do
date >> test.log
sleep 0.5
done
``
四 flume 的负载均衡 load-balance (负载均衡)
简单讲:一个agent 从服务器上获取数据源下沉到多个sink,多个sinK再由多个其他的agent1/agent2/agent3等来处理 然后sink 都到hdfs.
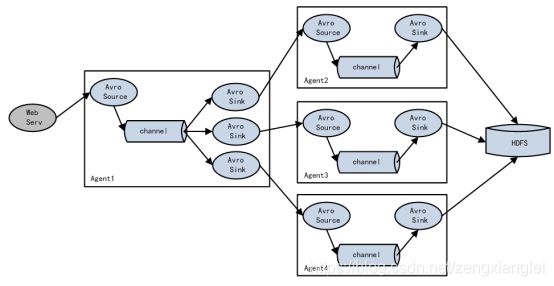
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2 k3
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true #如果开启,则将失败的 sink 放入黑名单
a1.sinkgroups.g1.processor.selector = round_robin # 另外还支持 random 随机round_robin 是轮训的意思
a1.sinkgroups.g1.processor.selector.maxTimeOut=10000 #在黑名单放置的超时时间,超时结
束时,若仍然无法接收,则超时时间呈指数增长
五 flume 的容错机制(failover)
Failover Sink Processor 能够实现 failover 功能。
Failover Sink Processor 维护一个优先级 Sink 组件列表,只要有一个 Sink
组件可用,Event 就被传递到下一个组件。故障转移机制的作用是将失败的 Sink
降级到一个池,在这些池中它们被分配一个冷却时间,随着故障的连续,在重试
之前冷却时间增加。一旦 Sink 成功发送一个事件,它将恢复到活动池。 Sink 具
有与之相关的优先级,数量越大,优先级越高。
例如,具有优先级为 100 的 sink 在优先级为 80 的 Sink 之前被激活。如果
在发送事件时汇聚失败,则接下来将尝试下一个具有最高优先级的 Sink 发送事
件。如果没有指定优先级,则根据在配置中指定 Sink 的顺序来确定优先级。
四/ load-balance 负载均衡案例:
首先将note1上的flume 分发的到note2和Note3上
命令:scp -r /export/servers/flume/ root@note2:/export/servers/
Scp -r /export/servers/flume/ root@note3:/export/servers/
Note1上 vi exec-avro.conf
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#set gruop
agent1.sinkgroups = g1
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /root/logs/123.log
# set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = note2
agent1.sinks.k1.port = 52020
# set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = note3
agent1.sinks.k2.port = 52020
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = load_balance
agent1.sinkgroups.g1.processor.backoff = true
agent1.sinkgroups.g1.processor.selector = round_robin
agent1.sinkgroups.g1.processor.selector.maxTimeOut=10000
Note2 上
Vi avro-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = note2 #这里在企业中有个坑 不能写localhost note1找note2ip找不到
a1.sources.r1.port = 52020
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
Note3上:
Vi avro-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = note3
a1.sources.r1.port = 52020
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动步骤:离source 远的先开启
bin/flume-ng agent -c conf -f conf/avro-logger.conf -n a1 -Dflume.root.logger=INFO,console
案例五 flume 容错机制(faliover )
Note1上:Vi failover-logger.cof
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#set gruop
agent1.sinkgroups = g1
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /root/logs4/456.log
# set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = note2
agent1.sinks.k1.port = 52020
# set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = note3
agent1.sinks.k2.port = 52020
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10 #优先级 权重 绝对值越大先使用 当此机器#不能正常运行时,会到下一个优先级高的执行
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 10000
Note2 上:可以使用案例四中的文件即可
Note3 上:同上
然后启动note2上的flume 和note3上的flume
最后启动note1上的flume
想456.Log文件中实时的写数据【while true;do date >456.log;sleep 0.5;done】,观察note2上有数据 note3上无数据 ;终止note2,再看note3 会发现note3有数据。
这就实现了容错 【note2挂了,还有note3上】
案例六.
flume 企业中的实例案例
案例场景:A、B 两台日志服务机器实时生产日志主要类型为 access.log、nginx.log、
web.log
需求:
把 A、B 机器中的 access.log、nginx.log、web.log 采集汇总到 C 机器上
然后统一收集到 hdfs 中。
但是在 hdfs 中要求的目录为:
/source/logs/access/20160101/**
/source/logs/nginx/20160101/**
/source/logs/web/20160101/**
你会想到什么?
首先要获取这三组文件,但是要根据access /nginx/web 来分别存储到对应的目录文件下
我们要解决的就是 在flume中 传递type 分别为 access/nginx/web
上传hdfs 打印时 我们动态获取这个type 指定hdfs上根据type来存放在不同的目录下。
话不多说 直接代码:
- 在note1上
vi exec_source_avro_sink.conf
# Name the components on this agent
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs6/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /root/logs6/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /root/logs6/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = note2
a1.sinks.k1.port = 41414
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
a1.sinks.k1.channel = c1
2.note2上
vi avro_source_hdfs_sink.conf
#定义agent名, source、channel、sink的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#定义source
a1.sources.r1.type = avro
a1.sources.r1.bind = note2
a1.sources.r1.port =41414
#添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义channels
a1.channels.c1.type = memory
a1.channels.c1.capacity = 2000
a1.channels.c1.transactionCapacity = 1000
#定义sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://note1:9000/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
#时间类型
#a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize =0
**a1.sinks.k1.hdfs.minBlockReplicas=1**
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
#批量写入hdfs的个数
a1.sinks.k1.hdfs.batchSize = 1
#flume操作hdfs的线程数(包括新建,写入等)
a1.sinks.k1.hdfs.threadsPoolSize=10
#操作hdfs超时时间
a1.sinks.k1.hdfs.callTimeout=30000
#组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3.分别启动note2和note1
bin/flume-ng agent -c conf -f conf/avro_source_hdfs_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
bin/flume-ng agent -c conf -f conf/exec_source_avro_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
4.在note1上自己创建对应的目录文件 然后持续添加数据
while true;do echo “access access…” >> /root/logs6/access.log;sleep 0.5;done
while true;do echo “web web…” >> /root/logs6/web.log;sleep 0.5;done
while true;do echo “nginx nginx…” >> /root/logs6/nginx.log;sleep 0.5;done
5.其中要注意一点 在小文件传输的过程中 同时会复制副本数 不配置默认是3
这可能导致我们的flume 不能正常运行 我们需要在 note2 中添加一行配置
a1.sinks.k1.hdfs.minBlockReplicas=1
即可。
数据仓库和数据库的区别
首先你要了解企业中的一个问题
比如:java人员 爬虫了一些数据,我们大数据拿来用 但是最终的结果出现了错误
这时大数据人员说 java爬的数据有问题 java人员说他爬的数据没有问题
是大数据的问题 这就是公司中出现的拉皮条显现【推卸责任】
企业数据文件管理的真谛:方便快速的存储和快速的提取。
方式:分类管理
--根据文件不同属性划分不同文件夹
–相同属性文件再根据日期继续划分
数据质量检查:在进行数据分析之前 需要通过相关的标准指标判断评估数据是否符合本次分析 数据的好坏不再于多少 在于数据是否符合你的分析需求
数据仓库和数据库的区别?
数据仓库(data warehouse) 可以简写为dw或者dwh.数*据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策和支持。它出于分析性报告和决策支持的目的而建设。
而且**数据仓库本身并不“生产数据”也不“消费数据”,**数据来源于外部开放于外部应用,这也就是为什么叫“仓库”而不叫“工厂”
数据仓库的主要特征:面向主题的/集成的/非易失的(不可更新的)/时变的数据集合,用于支持管理决策。
数据仓库的非易失:
操作型数据库主要服务于日常的业务操作,使得数据库需要不断地对数据实
时更新,以便迅速获得当前最新数据,不至于影响正常的业务运作。在数据仓库
中只要保存过去的业务数据,不需要每一笔业务都实时更新数据仓库,而是根据
商业需要每隔一段时间把一批较新的数据导入数据仓库。
重点解说:数据库和数据仓库的区别
数据仓库和数据库的区别 就是OLTP【on-line transaction processing】和OLAP【on-line analytical processing】的区别:联机事务处理/联机分析处理
数据库是面向事务的设计,数据仓库是面向主题的设计的。
数据库一般存储业务数据,数据仓库一般存储的是历史数据。
数据库是为了捕获数据而设计,数据仓库是为了分析数据而设计。
数据库看重的是响应 安全和高并发。
数据仓库:
–具备数据存储的能力
–具备数据(ETL)分析的能力
元数据(Meta Date),主要记录数据仓库中模型的定义、各层级间的映射关
系、监控数据仓库的数据状态及 ETL 的任务运行状态。
Hive 学习开始:
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为
一张数据库表,并提供类 SQL 查询功能。
本质是将 SQL 转换为 MapReduce 程序。
主要用途:用来做离线数据分析,比直接用 MapReduce 开发效率更高。
直接使用 Hadoop MapReduce 处理数据所面临的问题:
人员学习成本太高
MapReduce 实现复杂查询逻辑开发难度太大
使用 Hive :
操作接口采用类 SQL 语法,提供快速开发的能力
避免了去写 MapReduce,减少开发人员的学习成本
功能扩展很方便
Hive 组件:
用户接口:
元数据存储:
解释器/编译器/优化器/执行器/:生成的查询计划存储在hdfs,并在随后由mapreduce调用执行。
Hive和hadoop 的关系:
Hive 利用 HDFS 存储数据,利用 MapReduce 查询分析数据。
Hive 与传统数据库对比:hive只适合用来做批量数据统计分析。

Hive 数据类型:
Hive中所有的数据都存储在hdfs中,没有专门的存储格式。
在创建时指定数据中的分隔符,hive就可以映射成功,解析数据。
Hive 的安装与部署:
1 安装前需要安装好 jdk和hadoop 以及启动hadoop集群:start-all.sh
2.上传 hive包 解压 后到bin目录可以看见hive
Hive 根据元数据存储的介质不同 分为
1.derby版【属于内嵌模式 直接./hive 即可启动】【注意derby版 缺点:不同的路劲启动 就会在等级目录下 产生一个metastore_db 元数据,这就导致了无法共享 如:进去bin 后 ./hive 启动 和bin/hive 启动 创建的库表不能共享】
2.mysql版 【企业中用/生产环境用】
步骤:1.yum install mysql mysql-server mysql-devel 【安装mysql】
2./etc/init.d/mysqld start 【初始化mysql 并启动】
3.USE mysql;
4.UPDATE user SET Password=PASSWORD(‘hadoop’) WHERE user=‘root’; 【设置登录密码 用户】
.GRANT ALL PRIVILEGES ON . TO ‘root’@’%’ IDENTIFIED BY ‘hadoop’ WITH GRANT OPTION; 【给mysql所有权限】
6.FLUSH PRIVILEGES; 【刷新配置】
7.chkconfig mysqld on; 【设置mysql开机启动】
8.配置hive 中的mysql 到hive的conf目录 下编辑vi conf/hive-env.sh 配置: export HADOOP_HOME=/export/servers/hadoop
9.创建:vi hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://lnote1:3306/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
hadoop
password to use against metastore database
10.hive 的lib目录下缺失 mysql的连接驱动 上传jar包 启动hive即可【bin/hive 或者的到bin目录中 ./hive】
三 hive 的远程服务
1.将hive的插件 下发到其他机器 :scp -r /export/servers/hive root@note2:/export/servers scp -r /export/servers/hive root@note3:/export/servers
2.首先在note1上开启 hive 远程服务: 到hive 的目录下 bin/hiveserver2
3.在其他机器上【如:note3】 开启hive的客户端 ./beeline
4. 连接远程hive 命令: ! connect jdbc:hive2://note1:10000
5.输入 note1机器的root ;和note1机器的用户密码【不是mysql 用户密码】
6.连接完成后 测试是否连接成功 show databases;
hive的映射文件默认分隔符是‘\001’ 相当于文件中^A【ctrl+v,ctrl+A】不指定分隔符 也行。
创建表1:
create table peopeo(id int,name string,age int)row format delimited fields terminated by ‘,’
创建表2:create table complex_array(name string,work_locations array) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ COLLECTION ITEMS TERMINATED BY ‘,’;【如数据 张三 12,13,14,15】
解析后 表数据为: 张三 [12,13,14,15]
若文件中数据没有和建表时的数据字段类型没有有对应上 则该字段数据为null,对应上的字段数据正常。
而且自己验证:在hdfs上表的位置里放几个文件都行,不管id会不会重复 都会将所有文件的数据映射成一张表的数据。
ROW FORMAT DELIMITED 【delimited :使用hive的内置分隔符,】
[FIELDS TERMINATED BY char]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char] | SERDE serde_name 【使用自定义分隔符】
[WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value,…)]
小总:以上要求需要将对应的文件放到 hdfs上对应的建表位置中 叫做内置表 ,其实也可以不将文件放在对应的建表位置中,下面介绍一下外部表。
内部表、外部表
建内部表
create table student(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ‘,’;
建外部表
create external table student_ext(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ‘,’ location ‘/文件所在的目录’;
内部表和外部表最大的区别:
内部表:删除hive 中定义的表数据的同时,还会删除结构化数据文件。
外部表:删除表时 ,只会删除表hive中的表信息,不会删除结构化数据文件。
需求:比如一个建表目录下 有多个文件 会映射成一张表,但我们查询的时候会对所有的数据进行查询得到符合条件的数据,【当映射的数据量过大时 这时就会影响我们效率】这时我们引出一个分区的概念。用分区来解决这个需求。
简单举例:现在有三个地区的数据文件
China.txt
Usa.txt
Japan.txt
创建分区表:注意 分区字段不能和表字段重复
create table t_user_p (id int, name string,country string) partitioned by (guojia string) row format
delimited fields terminated by ‘,’;
分区表导入数据:
LOAD DATA local INPATH ‘/root/hivedata/china.txt’ INTO TABLE t_user_p partition(guojia='zhongguo);
LOAD DATA local INPATH ‘/root/hivedata/usa.txt’ INTO TABLE t_user_p partition(guojia=‘meiguo’);
LOAD DATA local INPATH ‘/root/hivedata/japan.txt’ INTO TABLE t_user_p partition(guojia=‘riben’);
【自我理解:首先在创建一个分区表时添加一个分区字段,然后在导入数据文件时给不同的文件加一个不同的分区标识】
分区表又分为单分区表和双分区表【目前最多支持俩个分区字段】
双分区表:
create table day_hour_table (id int, content string) partitioned by (dt string, hour string);
LOAD DATA local INPATH ‘/root/hivedata/11.txt’ INTO TABLE day_hour_table PARTITION(dt=‘2017-07-07’, hour=‘08’);
Load …
常见的有
月–天【常有】
天–小时【很少】
省–市【常有】
clustered by(xxx) into num_buckets buckets
字面上:按照xxx把数据分成num_buckets桶。
本质上:按照指定的字段把结构化数据文件分成几个部分。
例如:clustered by(sex) into 2 buckets
根据谁分: clustered by(xxx) xxx就是表中某个字段
分成几个部分: num_buckets
分的规则: hashfun
如果分桶的字段是数值类型 hashfun(xxx)–>xxx xxx%num_buckets 取余 余数为几就去哪桶
如果分桶字段是字符串类型 hashfun(xxx)–>xxx.hashcode xxx.hashcode%num_buckets
分桶表的创建:
create table stu_buck(Sno int,Sname string,Sex string,Sage int,Sdept string)
clustered by(Sno)
into 4 buckets
row format delimited
fields terminated by ‘,’;
分桶之前 需要以下俩个操作:
开启分桶功能:set hive.enforce.bucketing = true;
设置reduce个数等于分桶的个数:set mapreduce.job.reduces=4;
分桶表如何导入数据:
创建一个中间表【就是创建一张表 然后把数据映射到这张表中 然后通过 insert select 中间表 来向分桶表中添加数据】
insert overwrite table stu_buck
select * from student cluster by(Sno);
分桶的出现就是减少jion 的笛卡儿积。
增加分区:
ALTER TABLE table_name ADD PARTITION (dt=‘20170101’) location
‘/user/hadoop/warehouse/table_name/dt=20170101’; //一次添加一个分区
ALTER TABLE table_name ADD PARTITION (dt=‘2008-08-08’, country=‘us’) location
‘/path/to/us/part080808’ PARTITION (dt=‘2008-08-09’, country=‘us’) location
‘/path/to/us/part080809’; //一次添加多个分区
删除分区
ALTER TABLE table_name DROP IF EXISTS PARTITION (dt=‘2008-08-08’);
ALTER TABLE table_name DROP IF EXISTS PARTITION (dt=‘2008-08-08’, country=‘us’);
修改分区
ALTER TABLE table_name PARTITION (dt=‘2008-08-08’) RENAME TO PARTITION (dt=‘20080808’);
添加列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name STRING);
注: ADD 是代表新增一个字段,新增字段位置在所有列后面 (partition 列前 )
REPLACE 则是表示替换表中所有字段。
修改列
test_change (a int, b int, c int);
ALTER TABLE test_change CHANGE a a1 INT; //修改 a 字段名
// will change column a’s name to a1, a’s data type to string, and put it after column b. The new
table’s structure is: b int, a1 string, c int
ALTER TABLE test_change CHANGE a a1 STRING AFTER b;
// will change column b’s name to b1, and put it as the first column. The new table’s structure is:
b1 int, a ints, c int
ALTER TABLE test_change CHANGE b b1 INT FIRST;
表重命名
ALTER TABLE table_name RENAME TO new_table_name
显示命令
show tables;
显示当前数据库所有表
show databases |schemas;
显示所有数据库
show partitions table_name;
显示表分区信息,不是分区表执行报错
show functions;
显示当前版本 hive 支持的所有方法
desc extended table_name;
查看表信息
desc formatted table_name;
查看表信息(格式化美观)
describe database database_name;
查看数据库相关信息
Select
基本的 Select 操作
语法结构
SELECT [ALL | DISTINCT] select_expr, select_expr, …
FROM table_reference
JOIN table_other ON expr
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list]
]
[LIMIT number]
说明 :
1、order by 会对输入做全局排序,因此只有一个 reducer,会导致当输入规模较大时,
需要较长的计算时间。
2、sort by 不是全局排序,其在数据进入 reducer 前完成排序。因此,如果用 sort by 进
行排序,并且设置 mapred.reduce.tasks>1,则 sort by 只保证每个 reducer 的输出有序,不保
证全局有序。
3、distribute by(字段)根据指定字段将数据分到不同的 reducer,分发算法是 hash 散列。
4、Cluster by(字段) 除了具有 Distribute by 的功能外,还会对该字段进行排序。
如果 distribute 和 sort 的字段是同一个时,此时,cluster by = distribute by + sort by
Hive join
Hive 中除了支持和传统数据库中一样的内关联、左关联、右关联、全关联,还支持 LEFT
SEMI JOIN 和 CROSS JOIN,但这两种 JOIN 类型也可以用前面的代替
join 时,每次 map/reduce 任务的逻辑:
reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将
结果序列化到文件系统。这一实现有助于在 reduce 端减少内存的使用量。实践中,应该
把最大的那个表写在最后(否则会因为缓存浪费大量内存)。
Join 发生在 WHERE 子句 之前。
SELECT a.val, b.val FROM a
LEFT OUTER JOIN b ON (a.key=b.key)
WHERE a.ds=‘2009-07-07’ AND b.ds=‘2009-07-07’
. Hive 命令行
输入$HIVE_HOME/bin/hive –H 或者 –help 可以显示帮助选项:
说明:
1、 -i 初始化 HQL 文件。
2、 -e 从命令行执行指定的 HQL
3、 -f 执行 HQL 脚本
4、 -v 输出执行的 HQL 语句到控制台
5、 -p connect to Hive Server on port number
6、 -hiveconf x=y Use this to set hive/hadoop configuration variables.
例如:
$HIVE_HOME/bin/hive -e ‘select * from tab1 a’
$HIVE_HOME/bin/hive -f /home/my/hive-script.sql
$HIVE_HOME/bin/hive -f hdfs://:/hive-script.sql
$HIVE_HOME/bin/hive -i /home/my/hive-init.sql
$HIVE_HOME/bin/hive -e ‘select a.col from tab1 a’
–hiveconf hive.exec.compress.output=true
–hiveconf mapred.reduce.tasks=32
. Hive 参数配置方式
对于一般参数,有以下三种设定方式:
配置文件 (全局有效)
命令行参数 (对 hive 启动实例有效)
参数声明 (对 hive 的连接 session 有效)
1.配置文件
用户自定义配置文件: H I V E C O N F D I R / h i v e − s i t e . x m l 默 认 配 置 文 件 : HIVE_CONF_DIR/hive-site.xml 默认配置文件: HIVECONFDIR/hive−site.xml默认配置文件:HIVE_CONF_DIR/hive-default.xml
用户自定义配置会覆盖默认配置。
另外,Hive 也会读入 Hadoop 的配置,因为 Hive 是作为 Hadoop 的客户端启动的,
Hive 的配置会覆盖 Hadoop 的配置。
配置文件的设定对本机启动的所有 Hive 进程都有效。
2.命令行参数
启动 Hive(客户端或 Server 方式)时,可以在命令行添加-hiveconf 来设定参数
例如:bin/hive -hiveconf hive.root.logger=INFO,console
设定对本次启动的 Session(对于 Server 方式启动,则是所有请求的 Sessions)有效。
3.可以在 HQL 中使用 SET 关键字设定参数,这一设定的作用域也是 session 级的。
比如:
set hive.exec.reducers.bytes.per.reducer= 每个 reduce task 的平均负载数据量
set hive.exec.reducers.max= 设置 reduce task 数量的上限
set mapreduce.job.reduces= 指定固定的 reduce task 数量
但是,这个参数在必要时<业务逻辑决定只能用一个 reduce task> hive 会忽略上述三种设定方式的优先级依次递增。即参数声明覆盖命令行参数,命令行参数覆盖配置文件设定。注意某些系统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因为那些参数的读取在 Session 建立以前已经完成了。
Hive 函数:
create table dual(id string);
select substr(‘angelababy’,2,3) from dual;
. Hive 自定义函数和 Transform
当 Hive 提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
UDF 开发实例
hive 的udf(user defined function)自定义函数
1.新建java maven 项目
2.pom.xml 中引入
org.apache.hadoop
hadoop-common
2.7.4
org.apache.hive
hive-exec
1.2.1
3.写一个 java 类,继承 UDF,并重载 evaluate 方法【注意:udf类中并没有evaluate()方法,hive的内部机制会自动调用 evaluate()方法;同时自己创建的java类中可以定义多个evaluate()方法 如: public Text evaluate(Text s) {} public String evaluate(int end){}】【重写的evaluate()方法必须有返回值 不能用void修饰】
4.需求:定义一个自定义函数 将大写转换成小写 代码如下:
package cn.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Lower extends UDF {
public Text evaluate(Text s) {
if (s == null) {
return null;
}
return new Text(s.toString().toLowerCase());
}
5.将项目打包 打包后 放到linux系统hive的默认目录【不需要上传到hdfs】【默认目录:/opt/molute/jars/ (没有的话自己创建目录)
6.将jar包 添加到hive的classpath 【进入hive命令】【此步骤也相当于在hive上注册jar包】
hive> add jar /opt/molute/jars/udf.jar;
若执行成功 显示如下:
hive> add jar /opt/module/jars/udf.jar;
Added [/opt/module/jars/udf.jar] to class path
Added resources: [/opt/module/jars/udf.jar]
7.创建临时函数与开发好的 java class 关联
create temporary function toLowerCase as ‘cn.hive.Lower’; [【’’ 里是java类的路径 toLoweCase 是起的函数名 temporary是临时的】
8.测试 :show functions; 看我们刚才创建的hive 的自定义函数 toLowerCase 有没有
有的话 ,我们使用toLoweCase() 函数查询我们的一张表peopeo数据试试 如:
select toLoweCase(name) from peopeo; 结果成功 。ok 结束。
9.再举个例子:需求: 输入一个数字,输出从1到该数字的一个列表
代码:
自我理解udf自定义函数:1.可以使用java中现有的方法 ,在evaluate(参数)方法中调用,并返回我们想要的数据即可。2.或者我们在java中自定义一个方法 写自己的业务实现功能,然后定义evaluate()方法时 传递适合的参数 调用我们自定义的方法 并evaluate 返回我们需要的数据 也行。
小总:打好的包 不需要上传到hdfs上,有默认的路径 :/opt/molute/jars/ 【没
有自己手动创建即可】上面创建的只是临时自定义函数 【对于每一行输入都会调用到evaluate()函数。而evaluate()函数处理后的值会返回给Hive。】,如果想创建永久自定义函数 我们需要
在 hive-site.xml 文件中添加
hive.aux.jars.path
file:///opt/module/hive/lib/json-serde-1.3.8-jar-with-dependencies.jar,file:///opt/module/jar/udf.jar
这里相当于添加了多个jar
永久注册
hive (default)>create function getdaybegin AS ‘com.lzl.hive.Lower’;
删除函数
hive (default)>drop function getdaybegin;
链接:https://blog.csdn.net/liangzelei/article/details/81206012
网站流量日志分析系统:
点击流数据模型
点击流:是指用户持续访问浏览网站的轨迹。
点击流数据是由散点状的点击日志数据梳理所得。点击流数据在数据建模时存在俩张模型表 Pageviews 和visits
1.首先有一张:原始访问日志表 时间戳/ip地址/请求的url/referal/响应码/。。。
2.页面点击流模型的 pageviews 表 session/ip地址/时间/访问的url/停留时长/第几步
3.点击流模型 visits 表(按session聚集的页面访问信息) session/起始时间/结束时间/进入页面/离开页面/访问的页面数/ip/referal
如何进行网站流量分析:整个过程似一个金字塔

而且明确一点:流量并不是越多越好,还要看流量的质量,换句话讲就是流量可以给我们带来多少收入。

Bd(bd流量是指商务拓展流量)
细分:多维度 如:时间粒度/地理位置/目标页面/新老访客
对于所有的网站来说,页面可以划分为三个类别:导航页/功能页/内容页
导航页的目的是引导访问者找到信息,功能页的目的是帮助访问者完成特定
任务,内容页的目的是向访问者展示信息并帮助访问者进行 决策。
导航页有:首页/列表页
功能页有:搜索页面/注册表单页面/购物车页面等
内容页有:
网站转化和漏斗分析(转化分析)
即放文件在各环节递进访问的过程中慢慢流失的现象。【访问者的流失和迷失】
指标是网站分析的基础,用来记录和衡量访问者在网站的各种行为。
一 骨灰级指标:
1.ip:1天内,访问网站的不重复ip数。
2.Pageview(简称 PV)一个用户多次打开同一个网站就累加多次。通俗的讲就是页面被加载的次数。
3.Unique pageview:一天内同一访客多次访问网站只被计算 1 次。
二 基础级指标:
1.访问的次数:指访问者从进入网站到离开网站 记为1次,也称为会话(session),一次会话可能包含多个pv
2.网站的停留时间:访问者在网站上花费的时间。
3.页面停留时间:访问者在某个特定的页面停留的时间。
三 复合级指标:
1.人均浏览页数:平均每个独立访客产生的pv。人均浏览页数=浏览次数/独立访客
2.跳出率:在一次访问中访问者进入网站后只访问了一个页面就离开的数量
3.退出率:指访问者离开网站的次数
基于以上的指标,我们就可以从不同的角度进行分析
一 基础分析:pv/ip/uv
二 来源分析: 来源分类/ 搜索引擎/搜索词
三 受访分析:受访的域名/受访的页面/受访升级榜/热点图/用户视点/访问轨迹
四 访客分析:地区运营商/终端详情/新老访客/忠诚度/活跃度
五 转化路径分析:
网站流量日志分析是纯粹的数据分析项目
数据处理的流程可分为一下几个步骤:数据采集/数据预处理/数据入库/数据分析/数据展现
1.数据采集:数据从无到有的过程如:web服务器打印日志/自定义采集的日志等 另一方面也可以把通过使用flume等工具把数据采集到指定位置的过程叫做数据采集。
2.数据预处理:通过mapreduce程序对采集到的原始日志数据进行预处理,比如:清洗/格式整理/过滤脏数据等,并梳理成点击流模型数据。
3.数据入库:将预处理后的数据导入到hive仓库中相应的的库和表中。
4.数据分析:项目的核心内容,即根据需求开发etl分析语句,得出各种统计结果。
5.数据展现:将分析所得的数据结果进行可视化,一般通过图表进行展示。
系统架构:数据采集–>数据预处理–>导入hive仓库–>etl–>报表统计–>结果导出到mysql–>数据可视化
数据采集:定制开发采集程序,或使用开源框架 Flume
数据预处理:定制开发 mapreduce 程序运行于 hadoop 集群
数据仓库技术:基于 hadoop 之上的 Hive
数据导出:基于 hadoop 的 sqoop 数据导入导出工具
数据可视化:定制开发 web 程序(echarts)
整个过程的流程调度:hadoop 生态圈中的 azkaban 工具
流程如图:

工作调度器:azkaban
工作流调度系统产生的背景:一个完整的数据分析系统都是由大量的任务单元组成 如:shell 脚本程序 /java程序 /mapreduce 程序/hive脚本程序等 并且各个任务单元之间存在时间先后依赖关系,为了更好的执行复杂计划 需要有一个工作流调度系统来调度执行。
简单的任务调度:
直接使用 linux 的 crontab 来定义,但是缺点也是比较明显,无法设置依赖。
复杂的任务调度:
自主开发调度平台
使用开源调度系统,比如 azkaban、ooize、Zeus 等
其中知名度比较高的是apache ooize,但是其配置工作流的过程是编写大量的xml,而且代码复杂度比较高,不易于二次开发。
了解一下azkaban:
Azkaban 是由 Linkedin 公司推出的一个批量工作流任务调度器,用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban 使用 job 配置文件建立任务之间的依赖关系,并提供一个易于使用的 web 用户界面维护和跟踪你的工作流。
Azkaban 的功能特点:
1.提供了简单易用的web ui 界面
2.提供job配置文件 快速建立了任务与任务之间的关系
3.提供了模块化以及可插拔的机制 ,原生支持:command /java /hive /pig /hadoop
4.基于java开发,代码结构清晰,易于二次开发
azkaban安装部署:
首先azkaban由以下三部分组成:azkaban web server /azkaban executor server /mysql
mysql 服务器:用于存储项目、日志或者执行计划之类的信息
web 服务器:使用 Jetty 对外提供 web 服务,使用户可以通过 web 页面方便管理
executor 服务器:负责具体的工作流的提交、执行。
同时azkaban有俩种部署方式: 单机版和集群版
单机版:webserver 和executor server运行在同一个进程中,进程名是azkabansingserver.适用于小规模的使用。
集群版:webserver 和executorserver 运行在不同的进程中,该模式适用于大规模应用。
azkaban 安装开始:
1.创建一个目录 azkaban 将三个包上传并解压改名
cd /export/servers/
mkdir azkaban
上传:

分别改名为:webserver executorserver 剩下那个就不改名了其是sql脚本
2.mysql -u root -p
hadoop
mysql> create database azkaban;
mysql> use azkaban;
Database changed
mysql> source /export/servers/azkaban/azkaban-2.5.0/create-all-sql-2.5.0.sql;【注意:这里的路径是create-all-sql-2.5.0.sql的sql脚本的路径】
3.创建 SSL 配置 (https )
命令: keytool -keystore keystore -alias jetty -genkey -keyalg RSA
运行此命令后,会提示输入当前生成 keystor 的密码及相应信息,输入的密码请劳记,
so 我们在 /export/servers/azkaban/ 下执行 :keytool -keystore keystore -alias jetty -genkey -keyalg RSA
信息如下:
输入 keystore 密码:
再次输入新密码:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
北京市昌平区建材城西路金燕龙办公楼一层 电话:400-618-9090
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的州或省份名称是什么?
[Unknown]:
该单位的两字母国家代码是什么
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN 正确吗?
[否]: y
输入的主密码
(如果和 keystore 密码相同,按回车):
再次输入新密码:
完成上述工作后,将在当前目录生成 keystore 证书文件,将 keystore 拷贝
到 azkaban web 服务器根目录中.如:cp keystore azkaban/webserver
【这里的密码很重要 要牢记 我的是hadoop 这个密码待会要与 属性文件中的密码一致否则后期启动web会报错】
4.随便一个路径下 中执行:
Asia/Shanghai
tzselect
拷贝该时区文件,覆盖系统本地时区配置【首先看下 /usr/share/zoneinfo 路径中有没有/Asia/Shanghai】
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
5.进入webserver 修改 azkaban.properties
主要修改:
default.timezone.id=Asia/Shanghai #默认时区,已改为亚洲/上海 默认为美国
database.type=mysql #数据库类型
mysql.port=3306 #端口号
mysql.host=note1 #数据库连接 IP
mysql.database=azkaban #数据库实例名
mysql.user=root #数据库用户名
mysql.password=hadoop #数据库密码
mysql.numconnections=100 #最大连接数
6.进入webserver azkaban-users.xml
添加管理员用户:
7.进入executor 修改 azkaban.properties
default.timezone.id=Asia/Shanghai #时区
database.type=mysql #数据库类型(目前只支持 mysql)
mysql.port=3306 #数据库端口号
mysql.host=note1 #数据库 IP 地址
mysql.database=azkaban #数据库实例名
mysql.user=root #数据库用户名
mysql.password=hadoop #数据库密码
mysql.numconnections=100 #最大连接数
8.以上所有的配置完成 。下面开始启动 web
在 azkaban web 服务器目录下执行启动命令
bin/azkaban-web-start.sh
最后一行表示成功:INFO [AzkabanWebServer] [Azkaban] Server running on ssl port 8443.
9.web启动成功后 我们再启动 executor
bin/azkaban-executor-start.sh
10.进入azkaban web页面 访问地址:https://note1:8443
账号:admin
密码:admin
这里的密码要与 azkaban-web-2.5.0/conf/azkaban.properties 中设置的密码相同,否则会报错Keystore was tampered with, or password was incorrect。
Azkaban:自总博客地址
模块开发—数据仓库设计
1.维度建模:专门用于分析性数据库【还有数据仓库/数据集市建模的方法】的设计。 数据集市可以理解为一种小型的数据仓库。
维度表(dimension):就是分析事物的某个角度 数据量不大 精确度高 如:“昨天下午我在星巴克花费 200 元喝了一杯卡布奇诺” 从这句话中我们可以划分三个维度:时间维度;地点维度;商品维度
事实表(fact table):表示对分析主题的度量。事实表包含了 与各维度表相关联的外键,并通过jion方式与维度表关联。事实表的度量一般是数值类型,且记录数会不断增加,表规模迅速增长。比如上面消费的例子
消费事实表:prod_id(引用商品的维度表);timekey(引用时间维度表);place_id(引用地点维度表),Unit(销售量)
总的来说:数据仓库不需要严格遵守规范化设计原则。因为数据仓库的主导功能是面向主题,以查询为主,不涉及到数据更新操作。同时事实表的设计是以能够正确记录历史信息为准则,维度表的设计是能够以合适的角度聚合主题内容为准则。
维度建模的三种方式:
1.星型模式(star schema)最常用的维度建模模式:星型模式是以事实表为中心,所有的维度表直接连接在事实表上,像星星一样。
特点:a.维度表只和事实表关联,维度表之间没有关联。
b.每个维度表主键为单列,且该主键放置在事实表中,作为俩边连接的外键。
C.以事实表为核心,维度表围绕核心呈现星星分布

2.雪花模式(snowflake schema):是对星型模式的扩展。雪花模式的的维度表可以拥有其他维度表的但是由于这种模型维护成本太高,而且性能方面需要关联多层维度表,性能也比星型模型低。所以一般不常用。
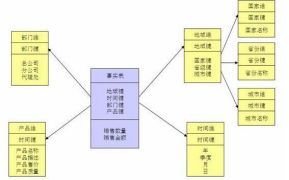
3.星座模式:星座模式是由星型模式延伸而来,星型模式是基于一张事实表而星座模式是基于多张事实表,而且共享维度表信息。
在业务发展后期,绝大部分维度建模都采用的是星座模式

举例:采用星型模式设计数据仓库
1.事实表设计:


2.维度表设计:

注意:
维度表的数据一般要结合业务情况自己写脚本按照规则生成,也可以使用工具生成,方便后续的关联分析。比如一般会事前生成时间维度表中的数据,跨度从业务需要的日期到当前日期即可.具体根据你的分析粒度,可以生成年,季,月,周,天,时等相关信息,用于分析。
二 模块开发: ETL
Etl 工作的实质就是从各个数据源提取数据,对数据进行转换,并最终加载填充数据到数据仓库维度建模后的表中。只有当这些维度/事实表被填充好,ETL工作才算完成。
本项目的数据分析过程在hadoop集群上实现,主要应用hive数据仓库工具,因此,采集并经过预处理后的数据,需要加载到hive数据仓库中,已进行后续的分析过程。