Spark Streaming运行原理与核心概念
Spark Streaming运行原理与核心概念
Spark streaming 简介
Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘。在“One Stack rule them all”的基础上,还可以使用Spark的其他子框架,如集群学习、图计算等,对流数据进行处理。
Spark Streaming运行原理
spark程序是使用一个spark应用实例一次性对一批历史数据进行处理,spark streaming是将持续不断输入的数据流转换成多个batch分片,使用一批spark应用实例进行处理。

Spark Streaming处理的数据流图

简单描述
Spark Streaming不断的从数据源获取数据(连续的数据流),并将这些数据按照周期划分为batch
Spark Streaming将每个batch的数据交给Spark Engine来处理(每个batch的处理实际上还是批处理,只不过批量很小,计算速度很快)
整个过程是持续的
详细描述
Spark的各个子框架,都是基于核心Spark的,Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如何协调生产速率和消费速率。
Spark Streaming 执行流程
Spark Streaming 是基于spark的流式批处理引擎,其基本原理是把输入数据以某一时间间隔批量的处理,当批处理间隔缩短到秒级时,便可以用于处理实时数据流。
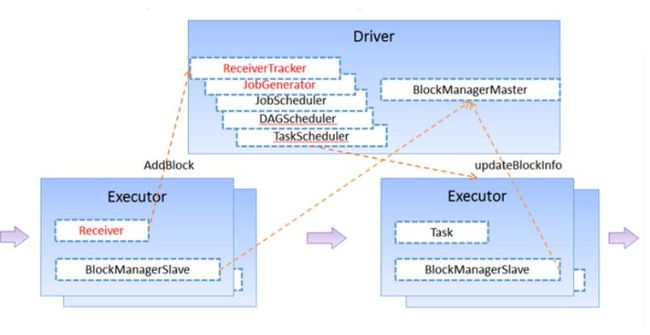
1、客户端提交作业后启动Driver,Driver是spark作业的Master。
2、每个作业包含多个Executor,每个Executor以线程的方式运行task,Spark Streaming至少包含一个receiver task。
3、Receiver接收数据后生成Block,并把BlockId汇报给Driver,然后备份到另外一个Executor上。
4、ReceiverTracker维护Reciver汇报的BlockId。
5、Driver定时启动JobGenerator,根据Dstream的关系生成逻辑RDD,然后创建Jobset,交给JobScheduler。
6、JobScheduler负责调度Jobset,交给DAGScheduler,DAGScheduler根据逻辑RDD,生成相应的Stages,每个stage包含一到多个task。
7、TaskScheduler负责把task调度到Executor上,并维护task的运行状态。
8、当tasks,stages,jobset完成后,单个batch才算完成。
Spark Streaming架构
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数据源(如Kdfka、Flume、Twitter、Zero和TCP 套接字)进行类似Map、Reduce和Join等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。
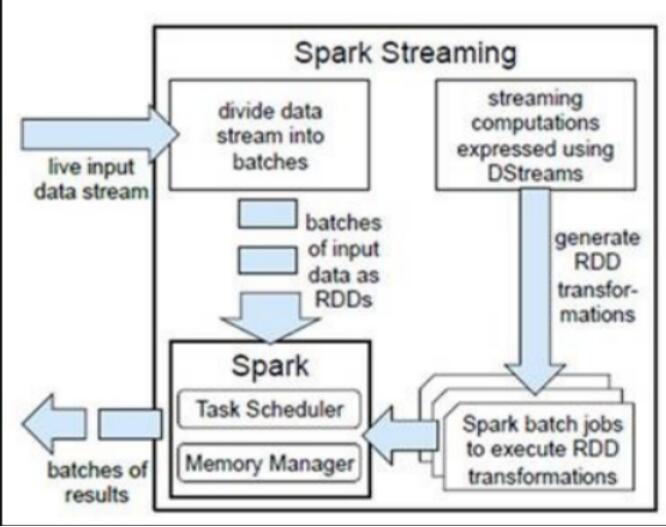
l计算流程:Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到外部设备。下图显示了Spark Streaming的整个流程。
Spark Streaming的高层抽象DStream?

为了便于理解,Spark Streaming提出了DStream抽象,代表连续不断的数据流
DStream 是一个持续的RDD 序列
可以从外部输入源创建DStream,也可以对其他DStream 应用进行转化操作得到新DStream
Dstream与RDD的关系
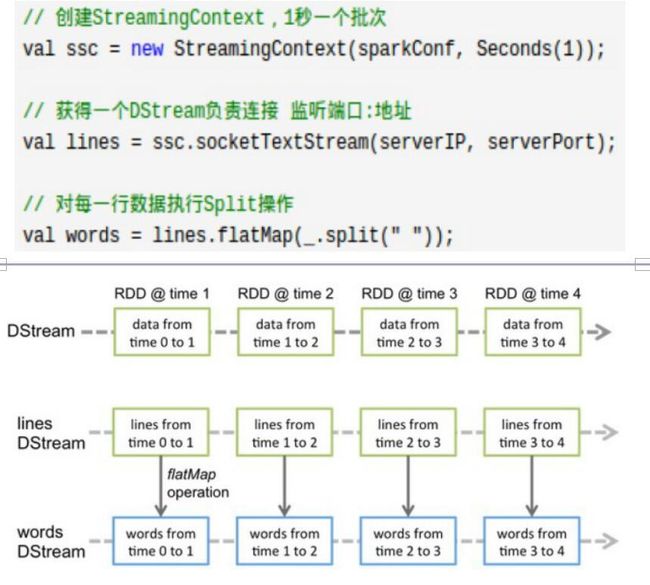
DStream 是一个持续的RDD 序列
对Dstream的转换操作最终会映射到内部随时间不断生成的RDD上Batch duration

Spark Streaming按照设定的batch duration来累积数据,周期结束时把周期内的数据作为一个RDD,并提交任务给Spark Engine
batch duration的大小决定了Spark Streaming提交作业的频率和处理延迟batch duration的大小设定取决于用户的需求,一般不会太大。