网易数帆 Ceph EC 纠删码在线存储性能优化实践
写在前面
术语说明
EC 的全称是Erasure Code——纠删码,是一种编码理论,EC 介绍链接
如下是和本文档相关的一些术语:
- EC 策略:一般就是我们常说的(K+M),K 个数据块,M 个校验块
- 条带(stripe):和磁盘阵列中的条带类似,是把连续的数据分割成相同大小的数据块,把每块数据分别写入到 Ceph EC 中的不同磁盘上,EC 会针对这些数据块计算校验块,1 个条带包含多数据块和多个校验块,数据块的个数一般称为 K,校验块的个数称为 M,每个条带包含 (K + M) 块
- Ceph中 其他概念,包括:Monitor、OSD、scrub 等,可以参见 Ceph 官方文档:https://Ceph.io/
EC 的选择
- 选择 EC 的首要出发点是降低单位存储成本,比起传统的 3 副本存储方式,选择 8 + 3 EC 策略,存储副本数变为 1.375( 11 / 8),节约了 1.625 的存储副本
- 同时相比三副本的存储方式(不管是客户端直接写 3 副本,还是由复制组中的 master 节点接收数据后写两个 secondary 节点)写入流量减少将近 1 倍
近线存储实践
2019 网易数帆对象存储(内部代号 NOS)团队基于 Ceph EC 开发了近线存储引擎,针对原生的 Ceph EC 作了一系列优化,主要包括:
- 开发了 ECMgr 管控模块,负责分配 Ceph 写入 oid,配合 monitor 反向通知机制,解决 osd failover 和容量分布不均及降级写等问题
- 优化 librados 库,实现 smart-client-read 和 fast read 功能,在客户端做请求的分包、组包以及 EC 计算等,解决 master 压力过大和 IO 长尾问题
- 实现 dir-cache,在 Ceph 服务端对目录进行缓存,降低 IO 延迟
- 实现独立的 GC 模块,通过业务层的 rewrite 操作,实现底层 append Ceph 对象的空洞垃圾回收
近线存储是网易数帆使用 Ceph EC 的初次尝试,用于存储低频数据,满足了近线存储的要求;但整体上还存在两个比较严重的问题:
- 吞吐能力不足,IOPS 低 ,客户读带宽峰值 2GB / s 慢请求增多(常规读流量 500MB/s - 1GB/s)
- GC 效率低下,GC 过程需要通过读取所有数据片以反序列化对象信息,判断 Ceph 块是否可以回收,IOPS 和流量放大问题严重
不能满足在线存储场景,我们在近线存储优化的基础上针对在线存储场景也做了多项优化工作,本文介绍这些优化的实践、效果以及我们的心得。
小对象合并
从 NOS 的对象大小统计分布情况看,我们 80% 的对象大小都在 0 ~ 128KB 范围内,小对象的高占比是我们可以做对象合并的基础前提。
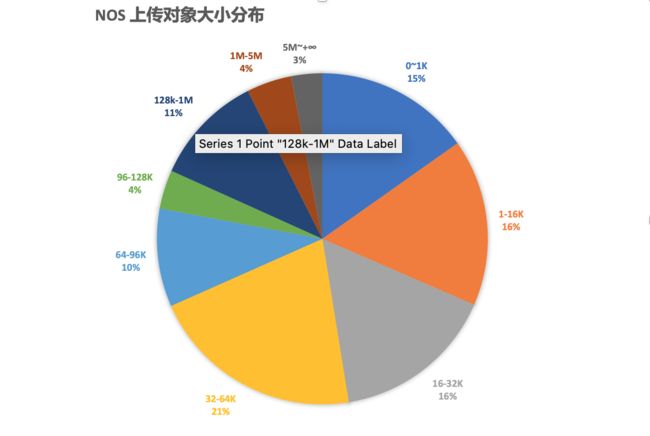
而从对象大小的角度来看在线存储比近线存储区别在于:
- 小对象:一般是低于 128KB 的,比如图片、文本,这一类对象,要求是 TPS
- 大对象:一般是大于 128KB 的文件,更重视整体的带宽吞吐
当前 NOS 在线存储的性能指标要求:
- 整体 TPS:30000+,读写占比符合28定律:20%写请求,80%读请求
- 小对象 latency:读 < 100ms,写 < 200ms(90分位值)
- 大对象吞吐:读 > 10GBps,写 > 1GBps(总体带宽)
而基于固有的近线存储架构不可能满足上述要求。由于 EC 必须要条带对齐,对 NOS 小对象来说,独占条带会严重降低有效数据利用率,所以我们的优化目标是小对象合并,通过合并对象写入,降低写 IOPS。
- 横向搁置条带策略
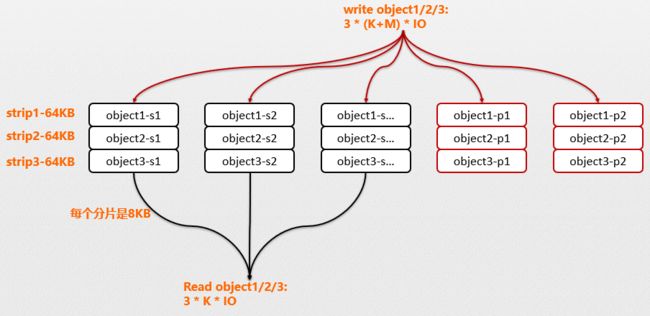
此方式在应用层累积对象,如 64kb 的条带,非合并方式下每个对象调用一次 write ;而在应用层累积多个对象后写入,如设置 1MB 的累积 buffer,当 buffer 写满后再批量调用 write ,按照平均大小 128KB 计算,可以将 8 个 IO 合并成 1 个,能显著降低写 IOPS 压力,如图(a) 所示。但此时一个对象仍然是分布在一个条带中,如图 (b) object-s1 - object-sn,读操作需要读取 n 个 osd。
- 纵向搁置条带策略
横向搁置条带合并写方式能显著降低写 IOPS, 但读对象时仍然需要读取对象所在条带的所有磁盘(osd),小对象的 IOPS 放大严重。而如果我们将条带大小由 64KB 调整为 1MB,则单个 osd 的 data chunk 变成 128KB,而我们 80% 的对象都是小对象,即单个对象可以直接存放在单个 osd 的 chu中;如果某个 osd 故障仍然可以通过条带中的其他 osd 通过 EC 计算恢复。只是此时用于 EC 恢复的数据是其他对象,而不像横向搁置条带中,数据的恢复由同一个对象的其他块完成。如下图 © 为纵向的条带搁置策略。
例如在横向搁置中对象 object1 分布在 s1- s3 三个 osd 上,如果 s1 osd 故障,则 object-s1 的数据块可以通过 object-s2/object/s2/object-p1/object-p2 恢复。而在纵向搁置中如果 object1 所在的 osd 故障,而通过 object2/object3/p1/p2 恢复。
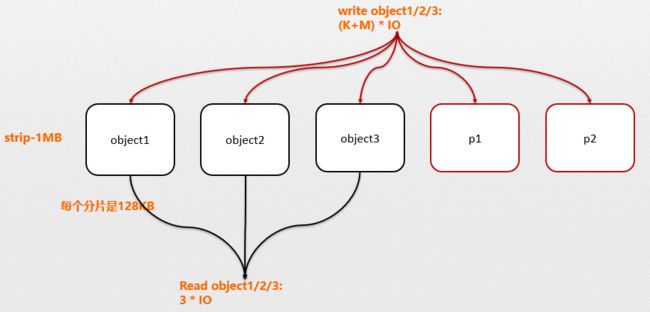
通过图 (b) 和 图(c) 对比:
- 横向搁置:写 k 个对象需要 (3 + 2) * k 个 IO,读 k 个对象需要 (3 + 2) * k 个 IO
- 纵向搁置:写 k 个对象需要 (3 + 2) 个 IO,读 k 个对象需要 3 个 IO
即通过调整对象的搁置策略,合并写对象,写有 k 倍的 IOPS 提升,读有有 3 + 2 倍的 IOPS 提升;虽然理想很丰满,但现实也很骨感,如上描述的小对象合并的过程不能用作用户的在线写 API,用户的 PUT 操作都是对象级别的,需要实时响应 PUT 状态,而上述模型需要多个小对象拼凑出一个完整的条带,需要一定的时间差,而极端情况下可能根本拼凑出一个条带;为此我们需要转变思路,引入第二个优化点离线写在线读。
离线写在线读
简言之,即我们不能根据用户的实时上传对象拼装 Ceph EC 条带,用户 PUT 上传仍然写三副本存储引擎,通过离线程序异步的扫描一定时间段之前的用户数据,执行条带拼装流程,拼装好的条带再写入 EC
- 写请求通过先写三副本,再通过离线中转程序迁移至 Ceph,实现离线合并写
- 读请求因为数据已经转入Ceph ,并且做了小对象合并,可以直接读取 Ceph
NOS 的对象元数据记录在分布式 mysql 数据库中,我们通过 Producer 模块扫描已经上传到三副本的对象推送给消息队列(Kafka), Consumer 端从消息队列拉取数据执行小对象合并流程,完成对象的生命周期转换,整体的架构图如下:
- Kafka 消息队列不仅解耦了小对象合并的数据流,同时也解耦非合并写和对象的垃圾回收等对象周期生命的数据流
- Kafka 的消息分布按照业务桶(Bucket)做 hash 聚合,保障相同桶的数据分配到相同的 Kafka partition 中
- 根据 Kafka 消费模型,一个 Kafka Partition 同时只能被一个消费者消费,保障相同桶的对象尽量被相同的消费者聚合合并
条带的拼装是一个静态的过程,简单的想法就是不停的从 Kafka 中取数据来填充一个 Ceph 条带,我们在权衡条带利用率和拼装成功率和工程实现等细节后,设计了一种分级队列的拼装方法,大概思路是在内存维护一个 MergeList 数据结构(类似 tcmalloc 中内存分配的分级队列结构),对大于 4M 的对象不需要合并:
- 初始化一个 MergeList 配置分级队列的个数(假设为 9 个,初始化条带大小,假设为 1M)
- 线程 A 不停从 Kafka 取对象,根据对象的 size 决定应该放置到分级队列的那个链表上,如果是 (80k, 96k] 则放置到 (80k, 96k] 对应的链表上
- 线程 A 判断当前 MergeList 的总的链接对象数达到了水位值(例如 1000) , 停止向 MergeList 链接对象
- 线程 B 开始从 MergeList 取对象填充条带(随机取一个链),判断需要多少个 128K 的块并填充(可能需要多个条带)
- 线程 B 根据填充完第一个随机对象后看当前 128K 的 chunk 还剩下多少空间,然后去对应大小的链上找对象填充,如果找不到去次优链去找填充对象
- 当线程 B 发现 MergeList 中的对象低于合并条带所需要的水位线时,重新将执行权交给线程 A 补充对象至 MergeList
- loop A ->B-> A
如下是执行合并的示意图:

执行小对象合并的几个权衡点:
- 减少对象跨 osd 占用:小对象的合并主要是该表条带的搁置策略,尽量让单个对象分布在尽量少的 osd 上,减少读对象时需要读取的 osd 数量;所以我们在拼装过程中每次从一个新的 osd 的起始位置随机填充一个对象,然后填充寻找能填充剩余空间的对象
- 提高条带利用率:对于大于 4M 的对象,已经直接在上层写 Ceph,不需要提交到拼装条带的队列,而小对象的合并过程中利用率是基本指标(80%+);一个条带拼装好后,如果在读写部分 object 时异常了,只要利用率达标,也提交这个条带,因为拼装一个条带是比较耗时的;另一方面如果拼装一个条带的前半部分时已经满足了利用率,则条带的后半部分也可以直接 padding
- 拼装成功率:当一个 128KB 的片写了一个对象,例如 96KB,还剩下 32kb, 需要按从大到小的顺序从 [16,32] [0,16]两个队列上取小于 32kb 的对象来填充剩余的 32kb,但此时很有可能取不到,所以需要设置一个超时时间,如果超时了则直接 padding,此时不考虑利用率
举例条带拼装过程,如上图(条带拼装示意图 - An 1MB Stripe with small file)
- 随机选取 (112k, 128k) 上的链,选取了一个 113k 对象放到 osd1的 o1 位置,还剩下 11k 空间(128KB chunk 大小 - 4KB header 大小 - 113 o1 大小)
- 从 (0, 16k) 选出一个对象填充至 11k 剩余位置(实际上在实现的时候可能取到大于 11k 的对象,不能填充)
- 开始填充 osd2,随机选取 (48k, 64k) 链,从上选择一个对象 o3 ,假设大小 63k,还剩有 65k 空间,此时可以继续从个 (48k, 64k) 链选取填充对象;而若此时 (48k, 64k) 链为空,可以从次有链 (32k, 48k) 链选取填充对象 o4
- 接下来选取了 o5,o5 占用了 2 个半 osd,而剩下的半个 osd 可以选择填充 o6
- loop 直到整个条带填充完毕
如上阐述了小对象合并的概要内容,实际工程实现中还要很多细节处理;即我们拼装一个条带的过程是根据对象的大小来决定其在一个 Ceph 条带中的分布位置,此时并没有发生真实的数据读写,只有当条带拼装成功后将该条带按批处理的方式提交给 submit 线程处理,submit 线程从三副本读取内容写 Ceph EC 再执行对象的元数据信息变更,如对细节感兴趣,欢迎和我们沟通。
优雅的 GC 设计
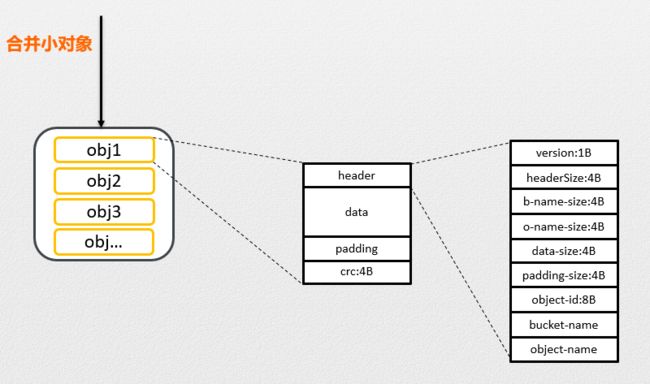
上节内容描述了小对象合并的概要实现,其中条带的头初始 4k 位置标记为 header,我们在上节没有说明;这部分的内容是为 Ceph Append 写方式实现垃圾回收而设计。原生的 Ceph 提供了的对象存储是 RGW,可以采用副本和 EC 模式,但粒度都是单对象级别的;即如果我们采用 Append 方式追加写到同一个 Ceph 对象,当该 Ceph 对象中部分小对象被删除形成空洞后,Ceph 在底层没有提供垃圾回收的机制;鉴于此,NOS 结合自身的业务特点设计了一套垃圾回收机制。
而结合业务层来实现 GC 需要被回收的块上记录有上层的业务信息,即上层的对象名信息,先看看我们在近线存储的中的 GC 方案:
- PutSmallObject 所示箭头表示我们将 X/Y/Z/N 4 个对象写入了一个 Ceph 大块文件中记忆为 oid1, 每个文件的结构如虚线展开所示;当 oid1 中 Y 和 Z 被删除后需要重写 X 和 N 后可以删除整块 oid1;Y 和 Z 的删除由业务层通过标记删除后累加记录 oid1 上已经删除的大小
- GC 程序周期性扫描 oid1 对象,当发现 oid1 上的删除大小超过 75% 表示该对象空洞率过高,需要将未删除的对象 rewirte 到其他空间,释放 oid1 空间
- 而执行 rewrite 的过程需要通过 Ceph read 接口将 oid1 块上的上层对象信息反序列化出来(header 中的 bucket-name 和 object-name),而按照下图的结构布局,则需要将整个条带的内容读出来(读放大严重)
- 将 oid1 块上的对象信息反序列化出来后,通过查询业务层元数据信息判断该对象是否存在,不在的即是已经删除的对象,而存在的则是需要 rewrite 的对象
- 将 oid1 上所有需要 rewrite 的对象都重写后,oid1 即可执行删除操作,完成 GC 过程
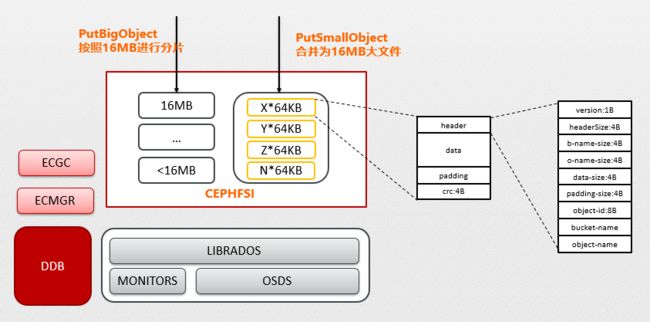
从我们近线存储的 GC 流程中可知,GC 的过程由于反序列化获取业务层对象信息消耗了大量的 IO 和带宽,读写流量甚至比用户的读写还高,GC 的内耗注定了整个集群的负载能力差;而由于没有小对象合并写能力,header 信息也才能采取这种妥协折中的方式。
当我们引入小对象合并写特性后,发现世界突然变得不一样了,我们可以将一个条带中的 header 信息集中存储在条带的最开始的 4KB 位置处,如下图:
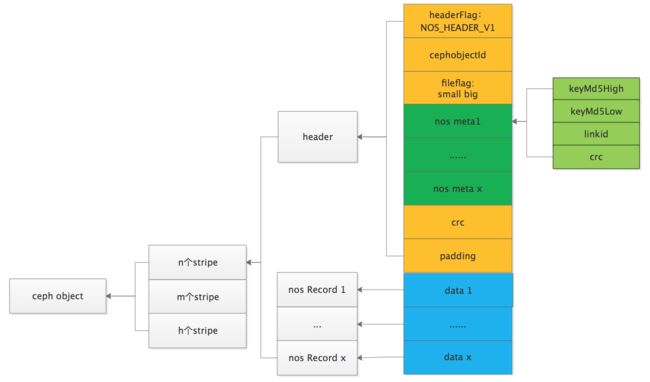

该方案的核心变更点:
- header 集中存储在条带的 osd1 上,反序列化只需要读取 osd1 上的部分数据
- header 中将 objectname 和 bucketname 替换成了 keymd5high 和 keymd5low;因为 objectname 是字符串,长度不定,如果在 header 部分存储完整的 objectname 一个是 header 长度不能确定,二是占用空间大(nos 平均对象名长达 60+ 字节)。而将对象名 hash 后拆分成 2 个 8 字节的 long 型记录解决上述问题(需要业务层数据记录映射关系)。
现在当 GC 程序需要反序列化 Ceph 块上的对象信息时,只需要读取首个 osd0 上的 meta 部分,在代码实现中我们是读取了 osd0 的前 4M 内容( Ceph 块大小为 32M,条带大小为1M,一个 Ceph 块上有 32 个条带),按照 header 格式将对象信息反序列化,而这 4M 内容在 osd0 上是连续存储的,只需要一个大 IO 就可以读取完毕。
利器 bluestore
除了上层业务的一些优化改进,我们同时引入了 BlueStore 引擎。BlueStore 最早在 Jewel 版本中引入,用于取代传统的 FileStore,作为新一代高性能对象存储后端。BlueStore 将索引元数据的 DB 引擎由 LevelDB 替换为 RocksDB(RocksDB 基于 LevelDB 发展而来,并针对直接使用 SSD 作为后端存储介质的场景做了大量优化)。FileStore 因为仍然需要通过操作系统自带的本地文件系统间接管理磁盘,所以所有针对 Rados 层的对象操作,都需要预先转换为能够被本地文件系统识别、符合 POSIX 语义的文件操作,这个转换的过程及其繁琐,效率低下。
针对 FileStore 的上述缺陷,BlueStore 选择绕开本地文件系统,由自身接管裸盘设备,直接进行对象操作,不再进行对象和文件之间的转换,从而使得整个对象存储的 I/O 路径大大缩短,性能有了质的飞跃。我们对单 OSD FileStore 和 BlueStore 性能做了简单测试。
测试环境
- 机器:Intel® Xeon® CPU E3-1220 v3 @ 3.10GHz 4核心 / 32 RAM / 36 * ST4000NC001-1FS168 4T 5900RPM
- 集群:10节点360 OSDs
表格说明
- 列项前缀 **B ** 代表 BlueStore,前缀 F 代表 FileStore
- 列项后缀 Meta 表示元数据全缓存,后缀 NoCache 表示元数据几乎无缓存(测试前重启OSD,drop_caches=3,测试时间为20s)
- 客户端 x * y Read/Write : x 表示压测客户端个数,y 表示每个客户端的并发数, read 表示读,write 表示写
- 压测时磁盘 util 基本 100%,BlueStore cpu 100%,内存未达到瓶颈
BlueStore Usage 37% vs FileStore 37%
物理池已用容量为37%左右时,BlueStore与FileStore的性能对比
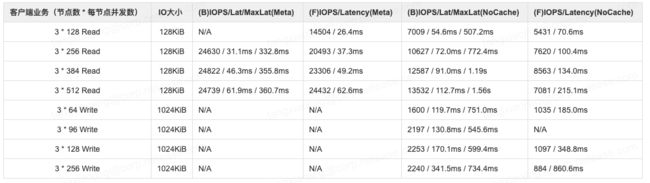
可见:
- 元数据全缓存时,两者读性能几乎一致
- 无元数据缓存时,BlueStore 读性能高约30%
- BlueStore 写性能高约100%
BlueStore Usage 37% vs BlueStore Usage 5%
以下表格记录BlueStore在物理池已用容量为37%和5%时的性能对比:
可见:
- 元数据全缓存时,两者读性能几乎一致
- 无元数据缓存时,37% 容量读性能下降了约 12%
- 写性能变化不大,甚至 37% 容量时还略有提升
在线 metric 对比
上述的所有优化目前已应用于生产环境,下面就我们线上一个 8 + 4 集群给出一些 metric 数据。
集群信息
- 操作系统: Debian 3.10.0-327.el7.x86_64
- 机器信息:Intel® Xeon® Silver 4114 CPU @ 2.20GHz 40 核心 / 128G RAM / WDC WUH721414ALE6L4 7200RPM * 36
- Ceph 集群:432 osds / 4084pgs / 3.3PB 逻辑空间
写性能
-
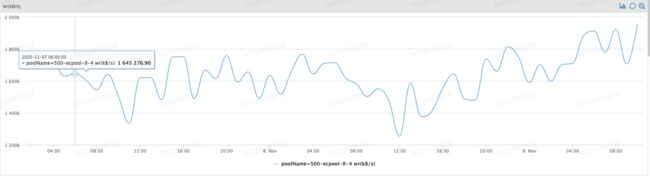
写带宽
执行离线写入阶段,控制集群的整体写入速度 2GB/s 左右,而实际我们使用 rados bench 工具压测时写入峰值可达 6GB/s+
-
写条带延时
在【条带合并】部分我们介绍了条带合并算法,而一次条带合并的过程可能会合并成多个条带,例如一个 3.3M 的对象和一个 128KB 的对象会拼成 4 个条带(条带大小 1M),此时向 Ceph 写对象的时候是一次写 4 个条带,耗时会比单条带要长,但对每个 osd 而言其实是做了 io 合并,减小了写的 IOPS。
从下图可以看出,我们有 1 - 4 个条带合并写的情形,但条带的写入延时在 400ms 左右,4 条带的写入延时在 1600ms 左右;即对于 1M的数据写底层 12 (8 +4) 个 osd 平均耗时在 400ms,因为我们是离线写入,latency 在可接受范围内。
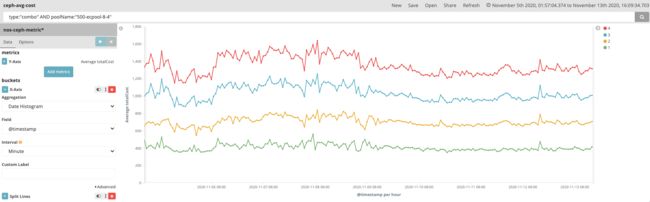
-
条带利用率
条带利用率是一个 1M 的 Ceph 条带中有效数据和条带大小的占比,利用率直接反馈了存储空间利用率情况,通过【条带合并】算法,我们的业务场景下,条带利用率平均 83%(只有小对象才需要合并写入,即对于小对象有 17%的空间浪费);对大对象我们采取独占 Ceph 块的方式,不需要合并写也没有空间的浪费。因此整体上 Ceph 的空间利用率是高于 83% 的。
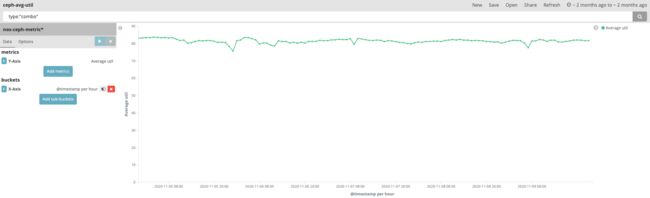
读性能
-
首包时间
首包时间反馈 Ceph 集群处理请求返回首个字节的时间,特别是对于 IOPS 压力较大情形下的负载能力:
NEFS(三副本): 40 - 60 ms
CephFs(8 +4EC):40 - 50ms目前从我们业务统计数据分析看 Ceph 的首包响应时间和 NEFS (小文件存储系统)持平,甚至更短,得益于我们的条带放置策略,对 80% 情形,对象小于 128KB 分布在单个 OSD 上,因此我们读取数据时也只需要读取单个 OSD 上的 chunk 数据。
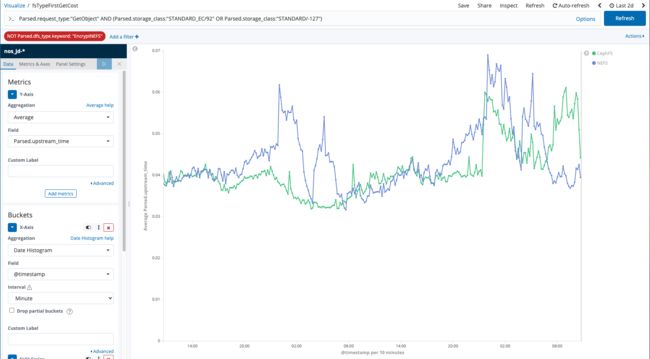
-
平均时延
而平均延时是整个对象的下载时间,和首包响应一样大多数情况下优于三副本时间,但出现突刺现象,如下图有 300ms;突刺的产生可能源于读取分布在多个 OSD 上的相对较大对象,而当某个 OSD 异常或者 util 较高时造成 IO 长尾效应。
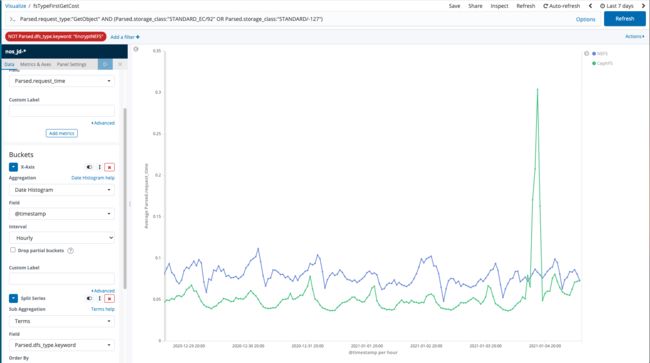
GC性能
GC 的过程需要读取源文件写新文件,同时产生读写流量,我们对空洞率达 75%的 Ceph 块对象会执行 GC 操作,GC 的瓶颈即集群的读写瓶颈,因我们是离线写入,保障用户读不受影响的情况下可以尽量提高 GC 的速度;目前 GC 程序日峰值可清理千万+对象,日回收空间峰值 100TB+。
总结
本文总结了网易数帆对象存储团队在推进在线 EC 存储中遇到的一些问题和对应的优化手段,包括小对象合并、离线写在线读、优雅的 GC 设计以及引入 BlueStore 引擎等。当然 NOS 在实际生产环境中的问题不止这些,还包括诸如:
- rados master 读压力过大问题
- EC 分片的个别 OSD 带来的长尾读问题
- BlueStore 的 LSM 架构下 compaction 向下合并过程中造成的上层写超时
对于这些问题我们也做了相应的优化和改进,欢迎和我们交流。同时鉴于笔者对存储引擎、Ceph 等知识的掌握水平有限,如有表述不当或者错误之处,欢迎指正。
作者:
网易数帆 - 对象存储(NOS)团队