领域驱动设计在爱奇艺打赏业务的实践
领域驱动设计(Domain-Driven Design,以下简称DDD)思潮的形成要追述到30几年前,17年前,Eirc Evans定义了领域驱动设计的概念。DDD一直为传统行业的软件工程师提供软件设计的方法论,但是在互联网行业却使用很少。直到近几年,DDD在互联网行业被重新认识,火了起来。究其原因有两点:
互联网的行业的业务越来越复杂,面临传统行业软件同样的问题;
微服务的流行带火了DDD,来解决微服务拆分问题。
本文主要对第一点“解决软件复杂性之道”进行讲解。
价值
详细讲解之前,我们先给出DDD为打赏业务带来的价值。
会员业务部门在打赏业务进行了DDD实践后,效率有显著提升:
新需求接入开发成本节约20%;
更换底层中间件开发成本节约20%;
项目熟悉成本节约30%(对DDD有基本了解为前提);
单测开发成本指数级降低;
上线风险、成本降低。
了解了DDD流行的背景及业务价值后,下面我们对DDD是什么、有哪些优势、项目中如何实践,以及几个关键问题进行叙述。
领域驱动设计是什么
讨论领域驱动设计是什么之前,我们先看下面一段代码:
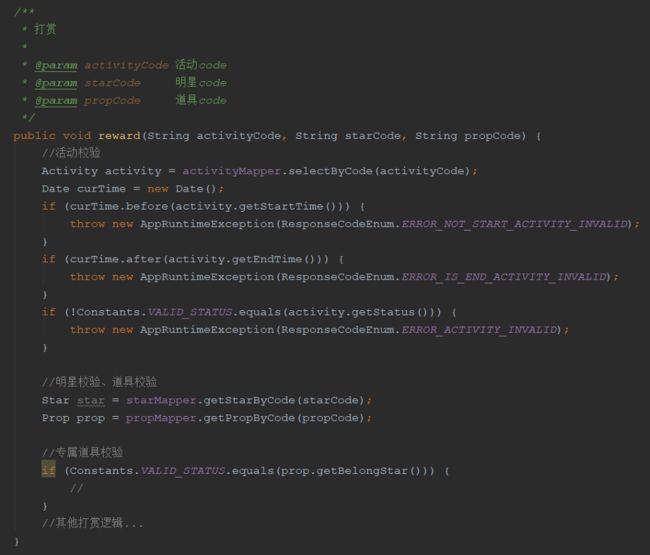
这是一个打赏接口定义,单看这个接口是没有问题的,用户基于活动,选择明星,选择道具进行打赏。
业务逻辑上没问题,但我们会发现一些代码的坏味道。
代码编译后方法的参数名会丢失。
![]()
在编码时如果将明星和道具的参数顺序传错一样可以通过编译,只有运行时才会报业务错误。当然这种问题发现成本不是很高,如果在编译时发现会规避一些风险,降低排查成本。上面方法参数的几个code可以唯一标识出实体,但却丢失了原有实体的实际业务领域意义,为某个明星打赏某种道具。
打赏业务逻辑掺杂了很多与业务核心逻辑无关的前置校验逻辑,影响代码可读性。全部逻辑堆叠在一个方法中,增加了测试用例编写复杂度。
对于以上代码,问题的根本原因是我们对业务的领域没有明确的划分,只是实现了一个操作流程,是需求的直接实现,缺乏领域抽象,方法的参数定义缺少业务领域含义。对于活动校验本质是活动的一些属性判断,活动是否有效是活动自身的属性决定的。可以抽象出活动校验类ActivityValidate,或在实体中增加validate方法,还可以更近一步,将校验逻辑直接放在活动的构造方法中,这样既达到了校验的目的,也避免了漏校验。对于单测的编写,如果我们能将一个大逻辑拆分为多逻辑单元,无疑会大大减少用例数量。优化后的代码如下:
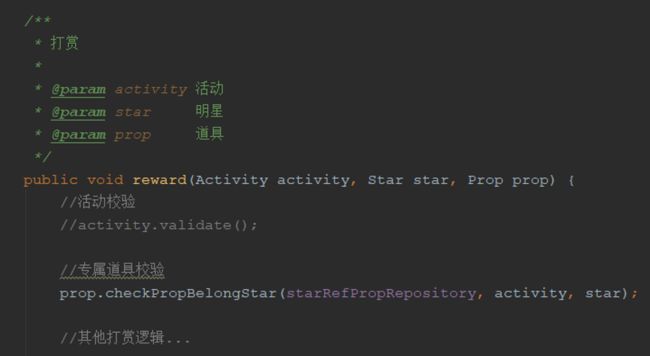
对于活动的校验,采用构造函数校验,因此打赏方法中无需再校验活动。活动的校验放到前置构造函数,减少了测试用例数量。
回到最初的问题,什么是领域驱动设计?
1、领域驱动设计基于领域建模而非数据建模
上面例子中,代码重构前activity实体只有基本的属性和get/set方法,即“失血模型”,从而导致activity这个领域对象退化为数据对象,只用作orm组件的crud,失血模型在项目代码中随处可见。究其原因,跟对象-关系映射(ORM,比如hibernate)持久化机制的流行是有直接关系的,使用ORM将每个类映射到一张数据表,通过实体对象完成crud,久而久之实体成为了orm框架的专用名词,即丧失了领域能力。进行项目设计时,我们应该从业务领域角度出发思考问题,而不应该从数据库角度,我们将在战略设计部分详细讨论。
2、满足六边形架构设计
六边形架构在后文进行详细介绍,洋葱架构、干净架构与六边形架构类似。
满足以上两点,并对DDD的一些概念进行映射实践,那么你的系统已经符合DDD了。总结,DDD不是一套全新的特殊架构,是任何项目代码经过重构,满足高可维护性、高可扩展性、高可测试性、代码结构清晰之后必将达到的终点。
DDD打赏业务实践
1、打赏业务简介
观看视频时,选择明星、礼物进行打赏;
打赏后屏幕有气泡提示;
打赏数据在排行榜进行显示;
累计一定的打赏获得某种奖励。
2、战略设计
提到战略设计,不得不提的是战略设计的几个核心概念:领域、子域、限界上下文、架构分层。
领域:从广义上讲,领域即是一个组织所做的事情以及其中包含的一切。每个公司或组织都有它自己的业务范围和做事方式,这个业务范围以及其在其中所进行的活动便是领域。当你为某个公司开发软件时,你面对的便是这个公司的领域。这个领域对于你来说应该是明确的,因为你在这个领域中工作。
对于打赏这种业务,打赏本身便是领域,即打赏领域。无论你的打赏对象是一位主播、一部电影或者一篇博文,又无论你的打赏道具是RMB、虚拟币、火箭等等,打赏都是这个领域的核心。
子域:对于领域模型包含“领域”这个词,我们可能会认为整个业务系统创建一个单一的、内聚的、功能全能式的模型。然后这并不是我们使用DDD的目标。正好相反,在DDD中,一个领域被分成若干小的域,这些若干的小的域即子域。事实上,在开发一个领域模型时,我们关注的通常只是这个业务系统的某个方面,对领域的拆分将有助于我们成功。
限界上下文:一个由显示边界限定的特殊职责。领域模型存在于边界之内,在边界内,每一个模型概念,包括它的属性和操作,都具有特殊的含义。
打赏系统搭建之初,需求比较简单,随着业务发展,需求越来越复杂,迭代及领域拆分过程如下:
运营及产品需求非常简单,只要实现免费打赏并在界面实现打赏气泡,基于此,只有一个领域;
经过一阶段的试水,活动效果很好,需要能同时支持多场打赏活动,增加活动支撑子域;
需求方又有了新想法,用户完成一定打赏后给用户发放一些奖品,引入奖励子域;
为了提升用户参与感,增加排行功能,引入排行子域。
最终领域划分如下图:

打赏核心子域:完成打赏操作。
通知子域:实现界面气泡通知能力。
奖励子域:奖励策略匹配,奖励发放。
排行子域:完成排行功能。
活动子域:活动、明星、道具管理。
用户子域:完成用户查询、校验等通用能力。
领域的拆分过程并没有上面描述的那么顺利,经历了很多推翻重来的过程,正是经历了这些过程,我们对领域的理解才能更深入,更符合领域建模。
架构分层:分层架构的一个重要原则是——每层只能与位于其下方的层发生聚合。

为了实现接口的定义与实现解耦,接口定义在领域层,实现定义在基础设施层。但这样违背了由顶至底的单项依赖原则。为了解决这个问题,我们此处采用依赖倒置原则,依赖倒置原则内容——高层模块不应该依赖于低层模块,两者都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。根据此原则,结构调整如下:

我们将基础设施层放在所有层的最上方,这样它可以实现所有其它层定义的接口。
当我们在分层架构中采用依赖倒置原则时,我们可能会发现,事实上已经不存在分层的概念了。无论是高层还是底层,它们都只依赖于抽象,好像把整个分层推平了一样。推平之后,客户通过“平等”的方式与系统交互。加入新的客户也只是不同的输入、输出,以及不同的展现形式而已,这既是我们即将了解的另一个架构,六边形架构。

六边形架构
在我们的代码中,有很多直接的外部依赖和实现细节。如mybatis的mapper类、httpclient注入、rocketmq的监听、缓存的直接操作等等。这样的实现有两个比较明显问题,一是当底层更换基础组件时对业务逻辑有直接影响,更换代码改动量及测试范围大大增加。二是不利于功能的复用,如果其他业务有类似逻辑,做不到直接移植复用。
2005年Alistair Cockburn提出了六边形架构,又被称为端口和适配器架构。观察上图我们发现,对于核心的应用程序和领域模型来说,其他的底层依赖或实现都可以抽象为输入和输出两类。组织关系变为了一个二维的内外关系,而不是上下结构。每个io与应用程序之前均有适配器完成隔离工作,每个最外围的边都是一个端口。基于六边形架构设计的系统是DDD追求的最终形态。六边形架构的实践在“DDD的优势”部分进行讲解。
先给出基于六边形架构实践后,项目模块结构:
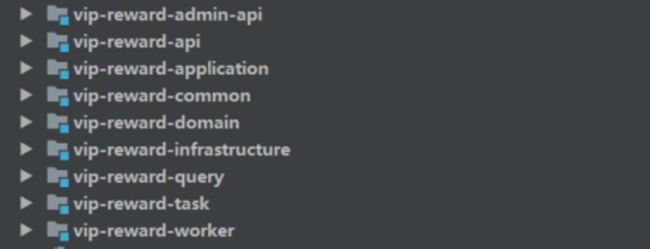
模块 |
说明 |
Admin-api |
配置后台相关 |
api |
对外用户接口 |
application |
应用 |
domain |
领域 |
infrastructure |
基础设施 |
query |
查询模块 |
task |
与使用的中间件相关,可忽略 |
worker |
处理事件消息模块 |
common |
基础包 |
3、战术设计
经过战略设计后,领域已经有了清晰的边界,下面我们聊下战术设计。首先对DDD的几个基本概念进行业务映射。
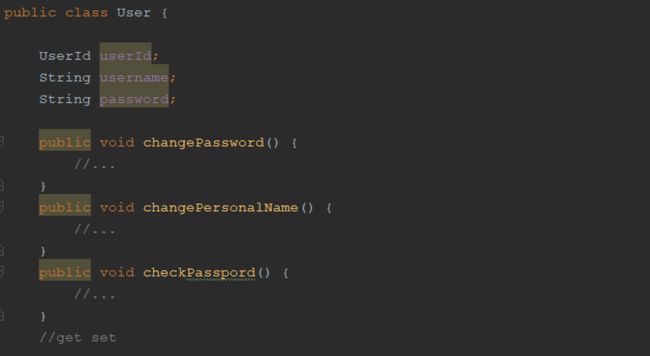
实体:由属性和行为组成,具有唯一标识。
在设计系统时,我们趋向于将重点放在数据上,而不是领域上。对于DDD开发者来说也是如此,因为软件开发中,数据库依然占据着主导地位。首先考虑的是数据的属性和关联关系,而不是富有行为的领域概念。这样做的结果是将数据模型直接反映在对象模型上,导致实体只包含get/set方法,这不是DDD的做法。
只有get/set实体需配合service使用,内聚性、可维护性,以及复用迁移成本均明显高于DDD的做法。

值对象:没有唯一标识,具有可度量或可描述,并满足不变性的对象。
我们应该尽量使用值对象来建模而不是实体对象,因为相比实体,我们可以非常容易地对值对象进行创建、测试、使用、优化和维护。
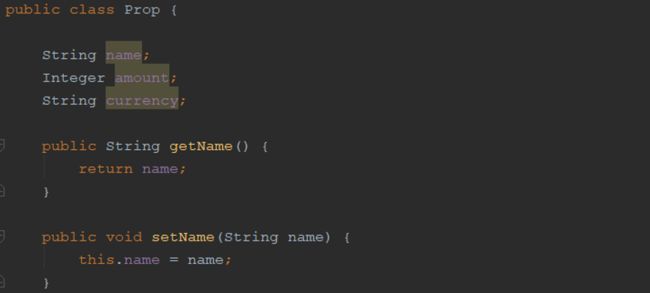
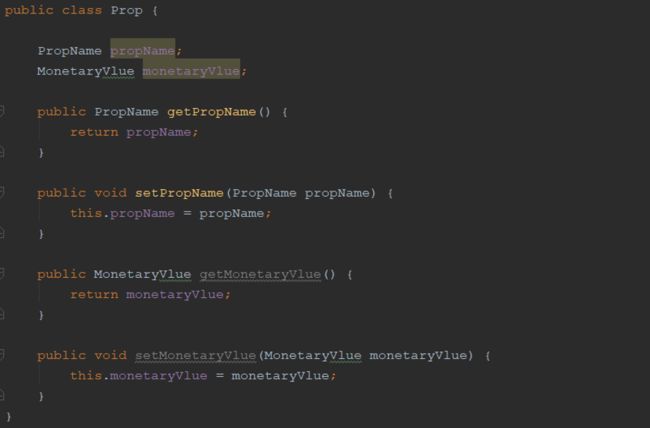
对于第一种实现,用户必须知道需要同时使用amount和currency,并且应该知道如何使用这两个属性,原因在于这两个属性并没有组成一个概念整体。对于PropName值对象的定义,可以带来一些扩展性,如需要对道具名称做大小写转换,此操作可以在PropName的内部实现,对外name的逻辑泄漏到Prop中。
领域服务:领域服务表示一个无状态的操作,它用于实现特定于某个领域的任务。
当某个操作不适合放在聚合和值对象上时,最好的方式便是使用领域服务了。
例如“用户认证”,一种方式是我们可以简单地将认证操作放在实体上。对于这种设计,存在两个问题。首先,用户类需要知道某些认证细节,其次,这种方法也不能显示的表达通用语言。这里我们询问的是一个User“是否被认证了”,而没有表达出“认证”这个过程。在有可能的情况下,我们应该尽量使用建模术语直接地表达出交流语言。
领域事件:领域专家所关心的发生在领域中的一些事件。我们通常将领域事件用于维护事件的一致性,这样可以消除两阶段提交(全局事务)。
聚合:聚合是一组相关对象的组合,作为一个整体被外界访问,聚合根是这个聚合的根节点。
聚合是一个非常重要的概念,核心领域往往都是用聚合来表达。其次,聚合在技术上也有非常高的价值,可以指导详细设计。聚合由根实体、实体、值对象组成。
工厂:工厂提供一个创建对象的接口,该接口封装了所有创建对象的复杂操作过程,同时,它并不需要客户去引用实际被创建的对象。

对于上面例子中方法参入为什么传入资源库对象,我们将在下面六边形架构部分讲解。
DDD的优势
应用DDD的系统符合六边形架构,我们实现了以下目标:
独立于框架:架构不应该依赖某个外部的库或者框架,不应该被框架的结构所束缚;
独立于UI:前台展示的样式可能会随时发生变化,但是底层架构不应该随之而变化;
独立于底层数据源:软件架构不应该因为不同的底层数据存储而产生巨大改变;
独立于外部依赖:无论外部依赖如何变更、升级,业务的核心逻辑不应随之而大幅变化。
实现以上几个目标,六边形架构(洋葱架构、干净架构与此类似)是个不错的选择,下面结合打赏具体业务实现,讲解如何实现以上目标。
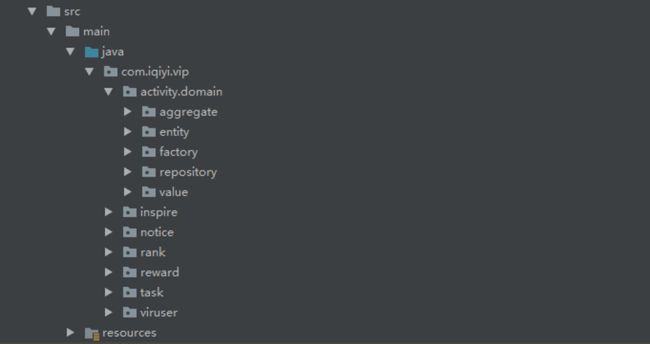
先给出项目某个模块的代码包结构:
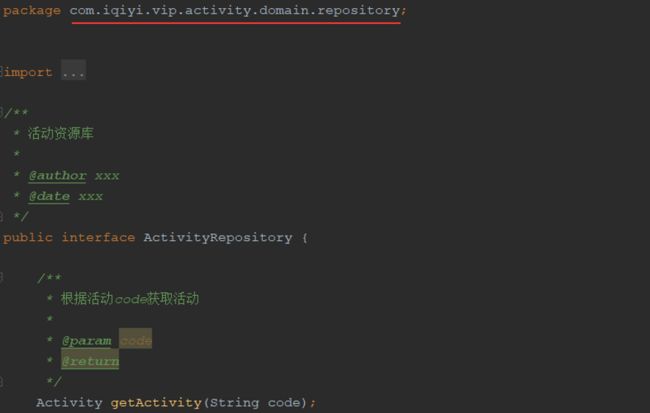
资源库:对于资源库,我们的实践是资源库作为业务与数据的隔离层,屏蔽底层数据表细节,同时完成PO与DO的转化。DO与PO的转化带来的好处是领域层不会直接依赖底层实现,便于后续更换底层实现或功能迁移。资源库接口定义在领域层,接口实现在基础设施层。
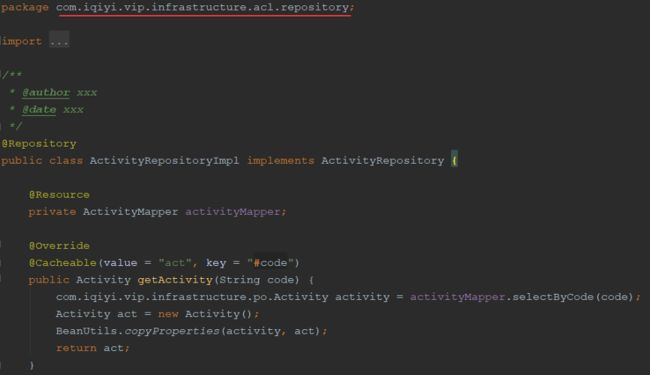
RPC:RPC部分的结构拆分与资源库类似,区别是以领域服务的存在。接口定义放在领域层,具体实现在基础设施层。
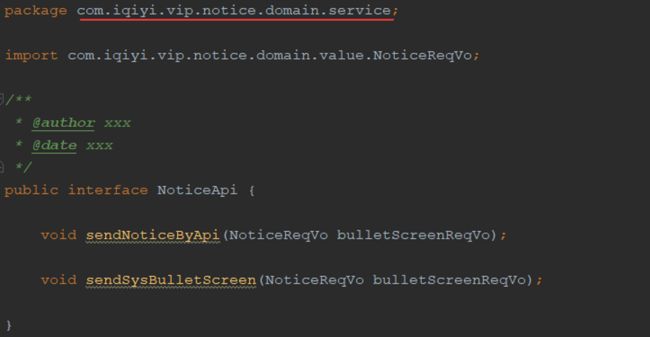
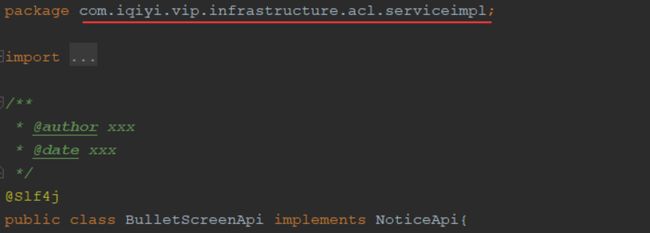
在遵循六边形架构的大原则下,其他边的拆分也变得清晰简单了,此处不再赘述。
几个关键问题
1、事务
在上文中“聚合”章节,我们描述了事务,一个事务内只操作一个聚合实例。如果发现一次事务内逻辑过多,可以考虑剥离出独立的聚合,采用最终一致性。基于这个基础,最适合声明事务的层是应用层。
2、查询
CQRS 在 DDD 中是一种常常被提及的模式,它的用途在于将领域模型与查询功能进行分离,让一些复杂的查询摆脱领域模型的限制,以更为简单的 DTO 形式展现查询结果。同时分离了不同的数据存储结构,让开发者按照查询的功能与要求更加自由的选择数据存储引擎,CQRS的具体实践可以自行查找资料。
3、框架无关
基于六边形架构设计,已经做到了与底层实现、框架、中间件无关。但还有一个最大的框架依赖spring,我们的做法是领域内使用的spring bean通过传参方式,实现领域层框架解耦。
4、成本
成本是我们实践DDD时需要考虑的一个很重要的问题,学习成本、改造成本、兼容成本等等都是需要特别关注的。在动手实践之前,建议优先评估好成本。
结束语
DDD不是一套全新的特殊架构,是应对软件复杂性的一套方法论。是面向领域建模,基于六边形架构,项目代码经过重构,满足高可维护性、高可扩展性、高可测试性、代码结构清晰之后必将达到的终点。
DDD缺少权威性的实践指导和代码约束,因此应用过程中会碰到很多问题,爱奇艺会员团队通过几个月的实践积累了一定的经验,欢迎交流。

也许你还想看
领域驱动设计框架Axon实践
爱奇艺首发互动视频标准 5G、AI驱动娱乐产业进化
 扫一扫下方二维码,更多精彩内容陪伴你!
扫一扫下方二维码,更多精彩内容陪伴你!
