摘要:日志异常检测的核心是借助AI算法自动分析网络设备日志来发现并定位故障,根据送入检测模型的数据格式,日志异常检测算法模型分为序列模型和频率模型,其中序列模型又可以分为深度模型和聚类模型。
AIOps(Artificial Intelligence for IT Operations)即智能运维,将AI应用于运维领域,基于已有的运维数据(日志、监控信息、应用信息等),通过机器学习的方式来进一步解决自动化运维没办法解决的问题。华为AIOps使能服务沉淀了10+开箱即用的智能APP,覆盖网络维护、网络体验、网络规划、设备故障预测等应用领域,包含KPI异常检测、硬盘异常检测、故障识别及根因定位、日志异常检测等。其中日志异常检测(Log Anomaly Detection,LAD)实时监控日志,识别并推荐根因异常,辅助运维人员定位故障根因,提升运维效率。
1. 为什么需要日志异常检测?
通信网络中部署的大规模设备在运行过程中产生海量日志。如图1所示,日志是一种时序文本数据,由时间戳和文本消息组成,实时记录了业务的运行状态。通过收集并分析日志,可以发现或预知网络中已发生或潜在的故障。

图1 windows公开数据集中的部分日志样例[1]
目前日志规范不统一。如图2所示,不同类型的设备打印出的日志格式也不同,且日志数据呈现出非结构化的特点。主要体现在日志时间格式不统一,日志记录的级别不统一,不同厂家自定义的专业词汇或缩略语不统一。这些问题增加了日志分析的难度。
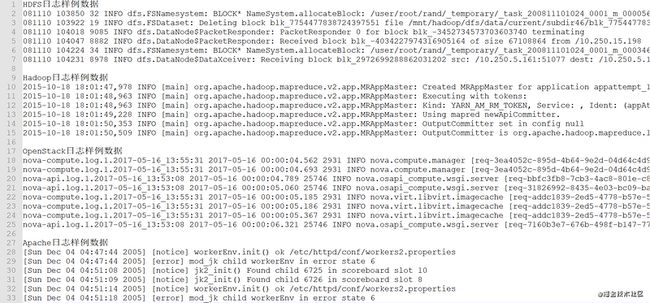
图2 四种不同规范的日志样例数据[1]
此外,现代网络系统规模庞大,每小时打印日志约50Gb(约1.2亿~ 2亿行)的量级[2],若依靠人工分析日志数据来识别网络中是否发生了故障则效率低下,因此有必要引入AI算法进行日志异常检测,以达到降低运维成本,显著提升业务体验的目的。
自2017年Min Du等人提出DeepLog以来[3],基于序列的深度学习建模逐渐成为近年来研究的热点。原始的DeepLog主要包括两个部分:模板序列异常检测模型(Log key anomaly detection model)和参数值异常检测模型(Parameter value anomaly detection model)。模板序列异常检测模型通过学习正常日志打印对应的工作流,然后对测试数据进行推理,以检测出是否存在违背工作流的异常日志。参数值异常检测模型则是对每一个模板(Log key或Template)构建一个模型,用推理出的参数值与实际参数值作对比,对比结果在置信区间内则认为是正常,否则为异常。模板序列异常检测模型的缺点在于对模板使用one-hot向量编码,无法学习出不同模板之间的语义相似性。参数值异常检测模型的缺点在于建模的数量太多,有多少个模板就要建立多少个模型,实现起来工作量较大。针对上述问题,2019年与2020年Weibin Meng等人先后提出Template2Vec和Log2Vec方法[4,5],可以学习出模板之间的语义相似性,并且能够解决新模板的在线学习问题。
2. 日志异常检测是如何实现的?
日志异常检测的核心是借助AI算法自动分析网络设备日志来发现并定位故障,根据送入检测模型的数据格式,日志异常检测算法模型分为序列模型和频率模型,其中序列模型又可以分为深度模型和聚类模型。本期主要分享近年来研究的热点:深度模型。
2.1 日志解析
非结构化的日志数据直接处理非常困难。通常的做法是通过日志解析得到日志的模板,然后再对模板进行异常检测。模板相当于日志的“摘要”,日志可以视作模板加参数得到。例如,模板Send Bytes to ,加上参数size=120, block=blk4612,使用打印函数print()可以得到一条具体的日志Send 120 Bytes to blk4612。改变参数值size=256, block=blk3768,可以得到另一条日志Send 256 Bytes to blk3768。日志解析相当于日志打印的逆过程,由日志反向处理得到模板。以Pinjia He等人提出的Drain方法为例[6],简单说明日志解析的过程。Drain认为具有相同长度的(即模板中token个数)日志,其业务含义具有相似性,因此长度是模板提取的一个重要判据。此外,特定的关键字也代表了特定的业务含义。变量一般认为是纯数字或者数字与字母等其他符号的组合。日志解析如图3所示,首先将变量token转换为,然后根据长度区分类别,最后根据关键字区分类别,最终得到一个模板。例如Receive from node blk_3587经过处理后得到模板Receive from node 。提取完模板内容后,会分配一个唯一的ID。
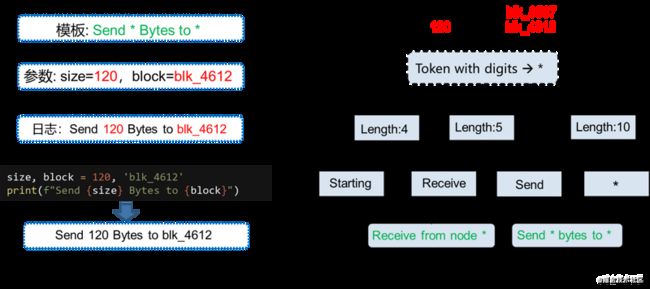
图3 模板与日志的关系以及日志解析原理图
2.2 异常检测
2.2.1 DeepLog模型
以DeepLog的Log key anomaly detection model为例,网络结构如图3所示,其中LSTM原理可以参看文献[3]。输入 为one-hot编码形式(备注:此处不用one-hot编码也是可以的,直接输入从0开始编码的模板ID即可),h为窗口长度,即x为t时刻之前的h个模板组成的序列。 表示第t个时刻出现的模板,假设模板ID的集合为{0,1, …,M},则 ,DeepLog采用两层LSTM,之后接全连接网络(FC),经过softmax函数处理后,输出各个模板的概率分布 ,其中_n_为模板的个数。

图4 DeepLog网络结构图
在训练态,收集设备正常运行时产生的日志获取训练集,具体步骤如下:
Step1: 取设备正常运行时打印的日志,通过日志解析得到模板序列;
Step2: 按task_id(或线程号、任务号)提取模板序列;

Step4: 使用训练数据和梯度下降法等算法训练神经网络。
从上述收集训练数据的过程中可以发现,整个过程只要求训练数据来自于系统正常运行或故障占比很小的日志。数据标签不需要人工标注,因此该模型可以认为是一个无监督的深度学习模型。
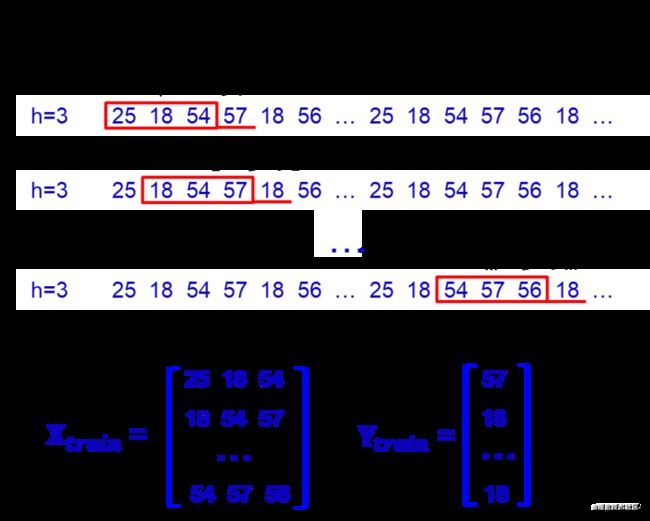
图5 训练态收集训练数据

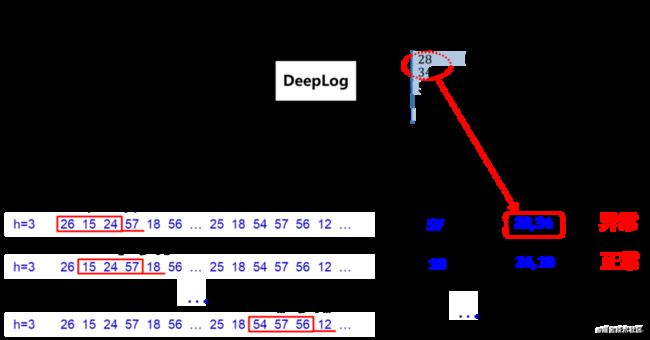
图6 推理态示意图
推理态步骤如下:
Step1: 取待检测的推理日志,通过日志解析得到模板序列;
Step2: 按task_id(或线程号、任务号)提取模板序列;
Step3: 加载训练后的模型,对各个task_id对应的序列滑动窗口依次检测;

DeepLog输入数据的编码方式为one-hot,所以无法学习出两个模板之间的语义相似度,例如,假如模板数据库的表中共有3个模板,如表1所示。从模板ID或者one-hot编码无法学习出1号模板与2号模板业务意义相反,也学不到1号模板与3号模板业务意义相近。因此,原始的DeepLog的学习能力是有局限性的。
表1 模板的one-hot编码示例

2.2.2 Template2Vec模型
为了学习出模板的业务含义或语义,Weibin Meng等人在使用DeepLog之前,设计了一个Template2Vec向量编码。核心思想是参照Word2Vec[7]的设计思路,提出了模板向量Template2Vec。Template2Vec将模板编码成语义向量,以代替原始DeepLog中的模板索引或one-hot编码。对于新出现的模板,则将其转换为一个最接近的已有模板。Template2Vec原理如图7所示:
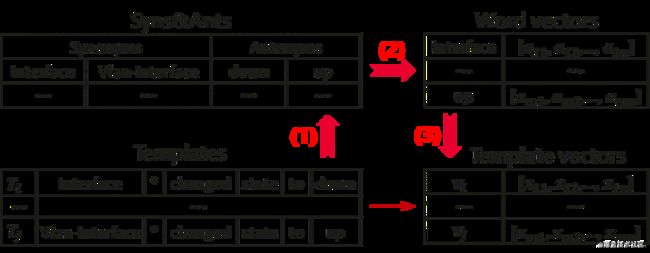
图7 Template2Vec原理
具体步骤如下:
Step 1 : 在WordNet[8]中对模板内容中的自然语言单词进行同义词和反义词搜索(如图7中的down和up),之后,运维人员再对具有业务知识的词汇识别同义词和反义词(如图中的Interface和Vlan-Interface),并将其转化为正常的自然语言词汇。
Step 2: 应用dLCE [9]生成模板中单词的词向量,如图7中的Word vectors。
Step 3: 模板向量是模板中单词的词向量的加权平均值。如图中的Templates vectors
Template2Vec结合了运维人员的专业领域知识和自然语言处理中的dLCE模型,以便准确生成模板向量。例如对模板Receiving blk src dest的Template2Vec求解过程如下。
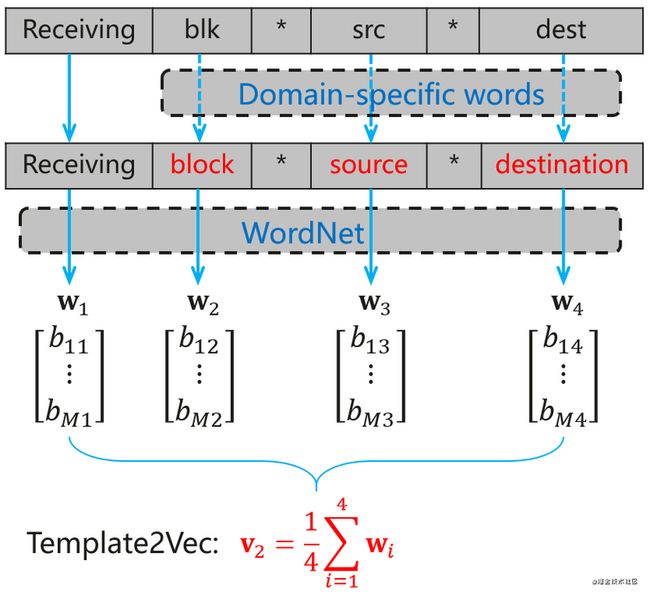
图8 Template2Vec计算过程示意图
借助Template2Vec将模板序列转换为语义向量序列,之后送入DeepLog即可进行日志异常检测。
2.2.3 Log2Vec模型
Template2Vec存在一个较大的问题:不能在运行态或推理态处理日志中词汇表外(OOV)的新词汇。为了解决这一问题,提出了Log2Vec方法。Log2Vec主要包含两部分:日志专用的词嵌入(log-specific word embedding, LSWE)和新词处理器(OOV Word processor).
LSWE可以看作在Template2Vec的基础上,加入了关系三元组,即增加了关联信息。具体做法是:(1) 对于通用的关系三元组采用Dependence Trees[10]方法进行语义向量转化,(2) 对于业务领域范围内的三元组,加入专家经验来识别处理。
新词处理器则采用MIMICK [11] 来处理运行中出现的OOV单词。使用方法如图9所示。首先,在已有的词汇数据集上训练出可用的MIMICK模型。然后,使用该模型在OOV单词上将其转换为一个唯一的向量。
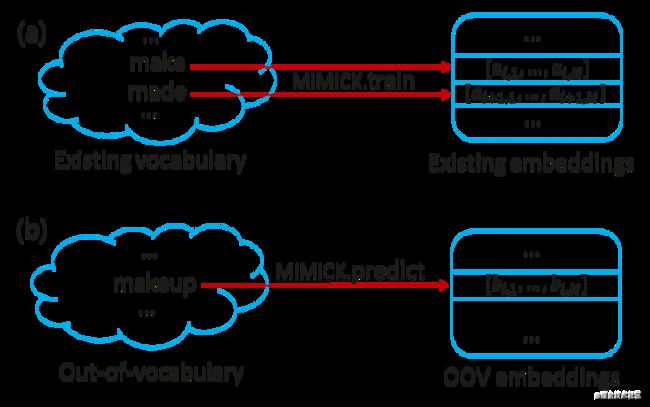
图9 新词处理器原理图
3. AIops中的日志异常检测效果展示
NAIE的AIOps中的日子异常检测模型服务,能够实时监控日志,识别并推荐根因异常。内置多种类型算法,无需定制即可支持不同网元日志的异常检测;具备在线学习能力,持续提升检测精度,辅助运维人员定位故障根因,提升运维效率。
例如,对某个网元的某个计算节点的日志监控过程中,如图10所示,实时统计出现的异常量,给出各个异常对应的关键日志。若算法报出的结果存在误报,如图11所示,用户可以加入业务反馈,反馈的误报异常点将会被在以后的检测中被过滤掉。由于日志包含了丰富的领域业务知识,如图12所示,每条关键日志都会给出上下文,辅助运维人员定位具体的异常内容。
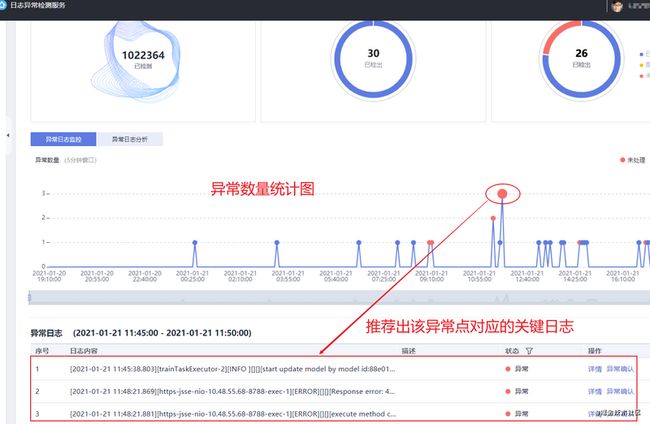
图10 异常检测与关键日志推荐
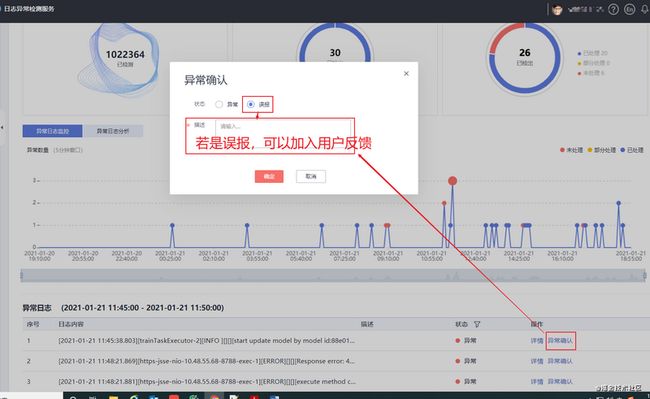
图11 可以加入用户反馈
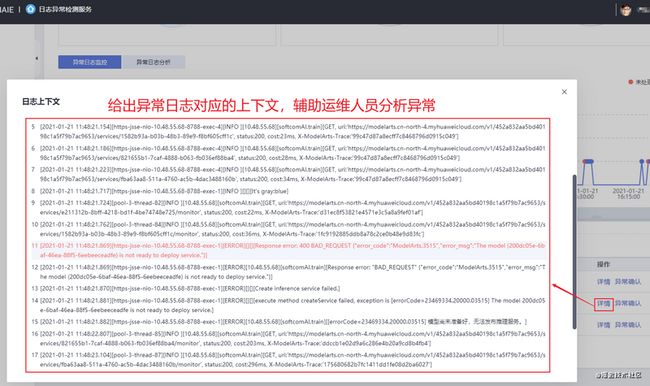
图12 异常日志上下文
本文作者在1月22日20:00在DevRun开发者沙龙直播详细介绍日志异常检测,直播间有众多互动奖品等候大家,点击直播

参考文献
[1] https://github.com/logpai/loghub
[2] Shilin He, Jieming Zhu, Pinjia He, Michael R. Lyu. Experience Report: System Log Analysis for Anomaly Detection, IEEE International Symposium on Software Reliability Engineering (ISSRE), 2016. (ISSRE Most Influential Paper).
[3] Min Du, Feifei Li, Guineng Zheng, Vivek Srikumar. DeepLog: Anomaly Detection and Diagnosis from System Logs through Deep Learning. CCS-2017
[4] Meng W, Liu Y, Zhu Y, et al. LogAnomaly: Unsupervised Detection of Sequential and Quantitative Anomalies in Unstructured Logs[C]//IJCAI. 2019: 4739-4745.
[5] Meng W, Liu Y, Huang Y, et al. A semantic-aware representation framework for online log analysis[C]//2020 29th International Conference on Computer Communications and Networks (ICCCN). IEEE, 2020: 1-7.
[6] Pinjia He, Jieming Zhu, Zibin Zheng, and Michael R. Lyu. Drain: An Online Log Parsing Approach with Fixed Depth Tree. ICWS'2017
[7] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
[8] George A Miller. Wordnet: a lexical database for english. Communications of the ACM, 38(11):39–41, 1995.
[9] Kim Anh Nguyen, Sabine Schulte im Walde, and Ngoc Thang Vu. Integrating distributional lexical contrast into word embeddings for antonym-synonym distinction. arXiv preprint arXiv:1605.07766, 2016.
[10] Katrin Fundel, Robert K¨uffner, and Ralf Zimmer. Relex—relation extraction using dependency parse trees. Bioinformatics, 23(3):365–371, 2007.
[11] Yuval Pinter, Robert Guthrie, and Jacob Eisenstein. Mimicking word embeddings using subword rnns. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 102–112, 2017.