Kmeans聚类分析
Kmeans聚类
聚类算法的常用场景
- 数据的探索性建模分析
- 对用户不是很了解的情况下,可以先通过kmeans聚类看看
使用kmeans的时候需要注意的地方:
- 需要处理异常值
- 如果建模的特征中,量纲差距比较大,需要做归一化/标准化
- 聚类之后每一个类别,不要都是用户量比较小
Kmeans使用的时候可以调整的参数
- n_cluster=i 聚类个数
- init=“k-means++” 选初始点的时候,找距离上一个初始点比较远的的点
评价kmeans究竟分几个类合适
- kmeans.inertia #inertia簇内误差平方和
聚类经常用Kmeans。数据量过大,不建议直接使用Kmeans. MiniBatchKMeans可以替代
Kmeans随机选几个点,然后开始算距离,距离离得近的属于一类,给每个类别打上标签,算出聚类中心。离的很近或者小于阈值,聚类结束。
Kmean++ 第一个随机选择。n+1是选择离第一个远的距离。
MiniBatchKMeans是一种能有效应对海量数据,尽量保持聚类准确性并且大幅度降低计算耗时的聚类算法
z-score 标准化 -均值(mean)和标准差(standard deviation)进行数据的标准化:
z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。
新数据=(原数据-均值)/标准差
年龄与收入分群
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
#加载数据
ageinc_df=pd.read_csv('ageinc.csv')
ageinc_df.info()
#两列数据,年龄与收入
income age
0 101743 58
1 49597 27
2 36517 52
3 33223 49
4 72994 53
输出显示
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 2 columns):
income 1000 non-null int64
age 1000 non-null int64
dtypes: int64(2)
memory usage: 15.7 KB
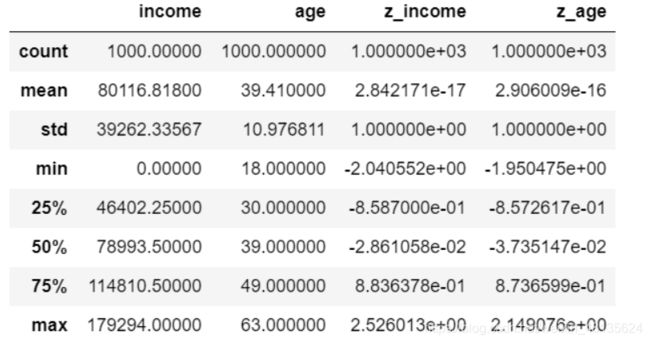
查看数据基本统计信息
ageinc_df.describe()

标准化和归一化都可以,在这里用标准化
标准化公式:新数据=(原数据-均值)/标准差
z-score 标准化 均值(mean)和标准差(standard deviation)进行数据的标准化
需要对数据进行标准化
ageinc_df['z_income']=(ageinc_df['income']-ageinc_df['income'].mean())/ageinc_df['income'].std()
#(收入-收入均值)/收入标准差
ageinc_df['z_age']=(ageinc_df['age']-ageinc_df['age'].mean())/ageinc_df['age'].std()
#(年龄-年龄均值)/年龄标准差
ageinc_df.describe()
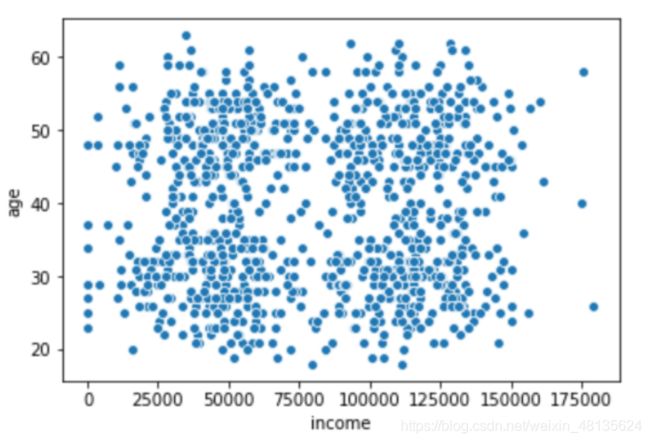
初步进行数据可视化
sns.scatterplot(x='income',y='age',data=ageinc_df)`在这里插入
进行聚类分析
from sklearn import cluster
model=cluster.KMeans(n_clusters=3,random_state=10)
model.fit(ageinc_df[['z_income','z_age']])
#导入sklearn中的cluster
#将群体分成3层
#用标准化的收入与年龄来拟合模型
#KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
# n_clusters=3, n_init=10, n_jobs=1, precompute_distances='auto',
# random_state=10, tol=0.0001, verbose=0)
#为用户打上标签
ageinc_df['cluster']=model.labels_
#查看用户的分群情况
ageinc_df.head(50)
将分群结果可视化
sns.scatterplot(x='age',y='income',hue='cluster',data=ageinc_df)
#横轴为年龄,纵轴为收入,分类为用户分群标签
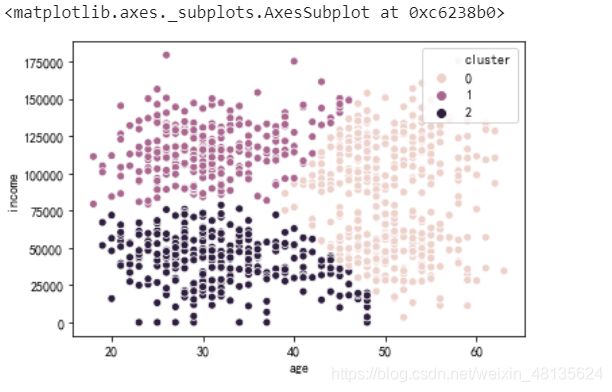
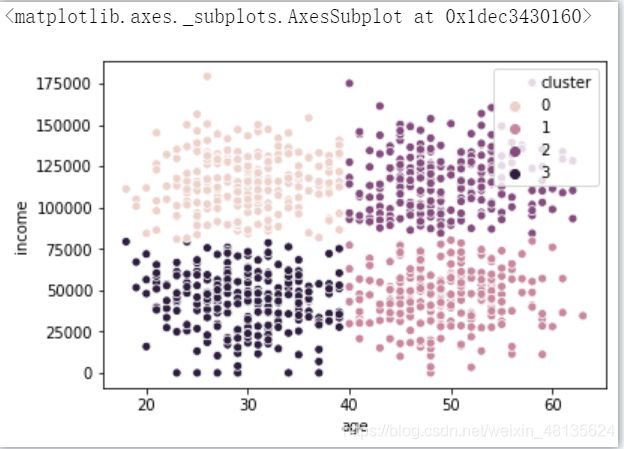
将用户分为4层
from sklearn import cluster
model=cluster.KMeans(n_clusters=4,random_state=10)
model.fit(ageinc_df[['z_income','z_age']])
#导入sklearn中的cluster
#将群体分成4层
#用标准化的收入与年龄来拟合模型
ageinc_df['cluster']=model.labels_
sns.scatterplot(x='age',y='income',hue='cluster',data=ageinc_df)
#横轴为年龄,纵轴为收入,分类为用户分群标签
可视化
将用户分为6层
from sklearn import cluster
model=cluster.KMeans(n_clusters=6,random_state=10)
model.fit(ageinc_df[['z_income','z_age']])
#导入sklearn中的cluster
#将群体分成6层
#用标准化的收入与年龄来拟合模型
ageinc_df['cluster']=model.labels_
sns.scatterplot(x='age',y='income',hue='cluster',data=ageinc_df)
#横轴为年龄,纵轴为收入,分类为用户分群标签
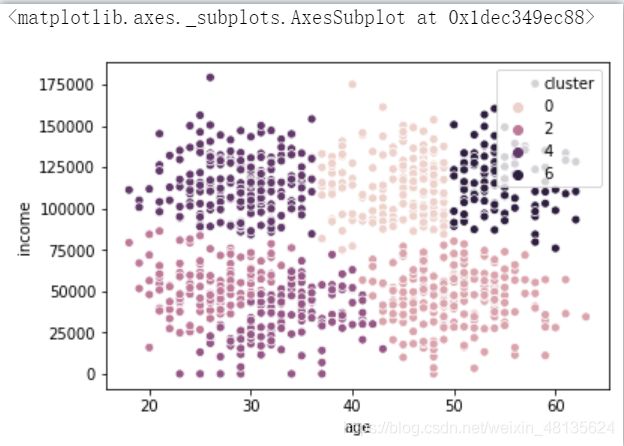
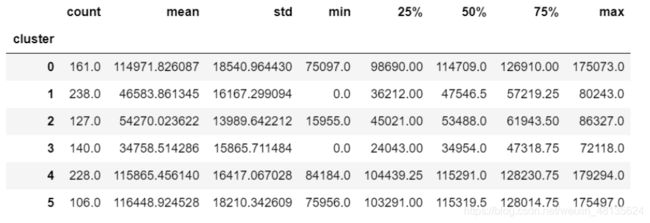
查看不同层用户的收入数据
#使用groupby函数,将用户按照所在群分组,统计收入的数据
ageinc_df.groupby(['cluster'])['income'].describe()
分析用户为4层的收入与年龄数据
from sklearn import cluster
model=cluster.KMeans(n_clusters=4,random_state=10)
model.fit(ageinc_df[['z_income','z_age']])
#导入sklearn中的cluster
#将群体分成4层
#用标准化的收入与年龄来拟合模型
ageinc_df['cluster']=model.labels_
#收入
ageinc_df.groupby(['cluster'])['income'].describe()
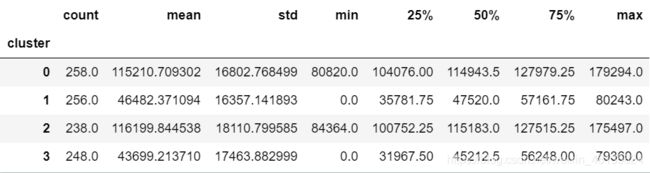
发现收入分为2档,一档0-8w,一档8-18w
#年龄
ageinc_df.groupby(['cluster'])['age'].describe()
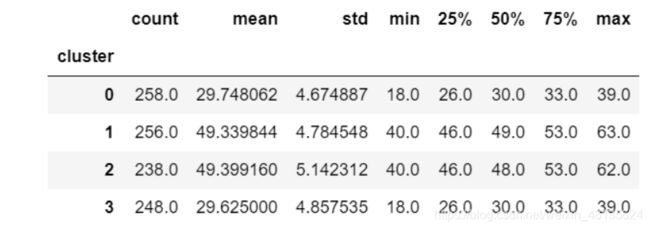
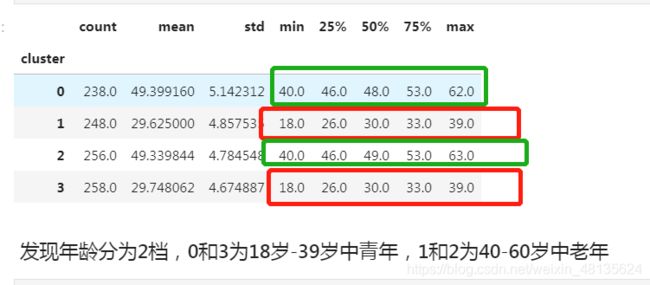
发现年龄分为2档,0和3为18岁-39岁中青年,1和2为40-60岁中老年