python concat函数_利用Python分析泰坦尼克生存率

- 提出问题
如何用机器学习方法来对泰坦尼克号的数据进行生存概率分析?
- 理解数据
数据来源:
Your Home for Data Sciencewww.kaggle.com数据大小:train: 891行 12列
test:418行 11列
Age:年龄
Cabin:客舱号
Embarked:登船港口
Fare:船票价格
Name:名字
Parch:船上父母数、女子数
PassengerId:乘客编号
Pclass:客舱等级
Sex:性别
SibSp:船上兄弟姐妹数,配偶数
Survived:生存情况(1=存活,0=死亡)
Ticket:船票编号
使用工具:Python
1、首先对数据集train.csv 与test.csv 进行数据获
#导入处理数据包
import numpy as np
import pandas as pd
#训练数据集
train = pd.read_csv("C:/Users/zhao/Desktop/项目整理/泰坦尼克号预测/train.csv",engine='python')
#测试数据集
test = pd.read_csv('C:/Users/zhao/Desktop/项目整理/泰坦尼克号预测/test.csv',engine='python')
print('训练数据集:',train.shape, '测试数据集:',test.shape)2、数据合并成 full 变量对象
full = train.append( test, ignore_index=True)
print('合并后的数据集:',full.shape)3、对数据分别进行head()和describe 、info来理解数据集信息
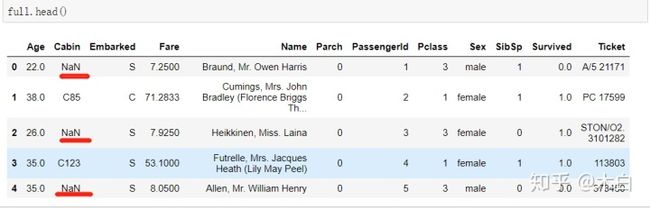

从中可以观察出字段 船票价格Fare 存在价格为0的异常值,同时Cabin字段存在空值NaN。
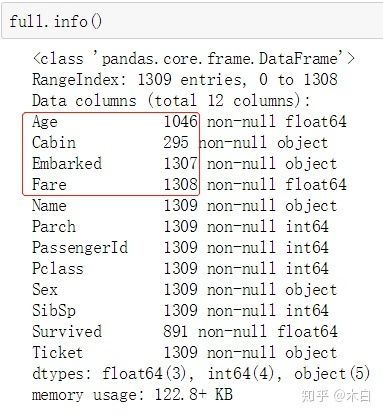
红色框标记处为缺失值字段。
说明:train.csv 与 test.csv中字段唯一的区别是 train.csv中多了一个Survived字段,由于测试集是为了让我们预测,所以 Survived在test中省略,让我们自己计算。
- 数据清洗
填补缺失值和异常值
#年龄补空值(float)
full['Age'] = full['Age'].fillna(full['Age'].mean())
#船票价格补空值(float)
full['Fare'] = full['Fare'].fillna(full['Age'].mean())
#登船港口补空值(object)
full['Embarked'] = full['Embarked'].fillna('S')
#船舱号补空值(object)
full['Cabin'] = full['Cabin'].fillna('U')- 特征工程
什么是特征?
特征工程就是最大限度地从原始数据中提取特征,以供机器学习算法和模型使用。
1、特征提取
特征提取分为如下结构:
数值类型 —> 直接使用
时间序列 —> 转换成单独 年、月 、日
分类数据 —> 用数值代替类别 One - hot 编码
根据对数据理解中的 info属性得到各字段的类型可以分为如下:
数值类型
(Age、Fare 、PassengerId、SibSp、Parch )
分类数据(有类别)
(Sex、Embarked、Pclass)
分类数据(字符串)
(Name、Cabin、Ticket)
- 分类特征提取
这里分别对(Sex、Embarked、Pclass、Name、Cabin、Ticket)
(1)性别 Sex
#使用map函数对每个数据进行映射转换
sex_mapDict = {'male':1,
'female':0}
sex = full['Sex'].map(sex_mapDict)
#与full数据集合并
full = pd.concat([full,sex],axis=1)
full.drop('Sex',axis=1,inplace=True)(2)登船港口 Embarked
#创建一个表格空容器
embarkedDf = pd.DataFrame()
#利用 get_dummies()函数对其进行编码,实现One-hut,即对分类数据进行1和0之间的编码,
有登陆的编码为1,没有的编码为0
embarkedDf = pd.get_dummies(full['Embarked'],prefix='Embarked')
embarkedDf.head()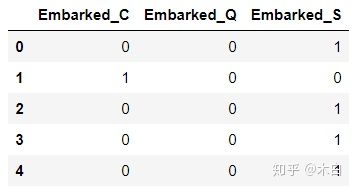
full = pd.concat([full,embarkedDf],axis=1)
full.drop('Embarked',axis=1,inplace=True)(3)客舱等级 Pclass
pclassDF = pd.DataFrame()
pclassDF = pd.get_dummies(full['Pclass'],prefix='Pclass')
full = pd.concat([full,pclassDf],axis=1)
full.drop('Pclass',axis=1,inplace=True)(4)姓名 Name
full['Name'].head()
发现每个人的名字格式都是由 名 + 头衔 + 姓组成
#定义函数
#从姓名中取头衔,使用函数 split( )进行字符串分解
def getTitle(name):
str1 = name.split(',')[1] # 取Mr. Owen Harris
str2 = str1.split('.')[0] # 取 Mr
str3 = str2.strip() # 去掉空格
return str3
titleDf = pd.DataFrame() #存放提取后的特征
titleDf['Title'] = full['Name'].map(getTitle)
titleDf.head()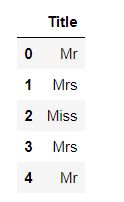
#查询所有特征,去除重复特征,使用 drop_duplicates 去除重复值
B = titleDf.drop_duplicates(subset='Title')
B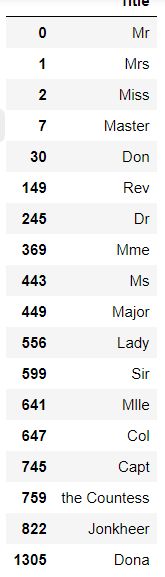
'''
定义以下几种头衔类别:
Officer政府官员
Royalty王室(皇室)
Mr已婚男士
Mrs已婚妇女
Miss年轻未婚女子
Master有技能的人/教师
'''
title_mapDict = {
'Mr':'Mr',
'Mrs':'Mrs',
'Miss':'Miss',
'Master':'Master',
'Don':'Royalty',
'Rev':'Officer',
'Dr':'Officer',
'Mme':'Mrs',
'Ms':'Mrs',
'Major':'Officer',
'Lady':'Royalty',
'Sir':'Royalty',
'Mlle':'Miss',
'Col':'Officer',
'Capt':'Officer',
'the Countess':'Royalty',
'Jonkheer':'Royalty',
'Dona':'Royalty'
}
titleDf['Title'] = titleDf['Title'].map(title_mapDict)
titleDf = pd.get_dummies(titleDf['Title'])
full = pd.concat([full,titleDf],axis=1)
full.drop('Name',axis=1,inplace=True)(4)客舱号 Cabin
#先看下Cabin数据
full['Cabin'].head()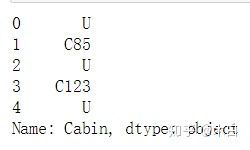
可以发现数据的首部都带有大写字母,我们利用匿名函数 --> lambda 进行提取首部字母
cabinDf = pd.DataFrame()
full['Cabin'] = full['Cabin'].map(lambda c: c[0])
full['Cabin'].head()
#进行one-hot 编码
cabinDf = pd.get_dummies(full['Cabin'], prefix = 'Cabin')
full = pd.concat([full,cabinDf],axis=1)
full.drop('Cabin',axis=1,inplace=True)(5)家庭类别 Parch & SibSp
首先我们对 Parch字段和SibSp字段进行组合,组合成新字段为 ‘FamilySize’字段。
familyDf = pd.DataFrame()
familyDf['FamilySize'] = full['Parch'] + full['SibSp'] + 1
#这里的 1 是自己,因为Parch 和 SipSp 里没有囊括自身数量对familyDf进行家庭规模区分,分为大,中,小家庭,并且利用匿名函数结合条件
familyDf['Family_Single'] = familyDf['FamilySize'].map(lambda s: 1 if s == 1 else 0)
familyDf['Family_Small'] = familyDf['FamilySize'].map(lambda s: 1 if 2 <= s <= 4 else 0)
familyDf['Family_Large'] = familyDf['FamilySize'].map(lambda s: 1 if 5 <= s else 0)
#这里的lambda 函数的意思是 如果数据值大于,小于,等于限定条件,则为1,否则为0
familyDf.head()
full = pd.concat([full,familyDf],axis=1)
- 特征相关性
corrDf = full.corr()
corrDf
这里我们想要得到的是Survived生存率和什么特征相关系数最高,所以用corr()函数获得,并对特征相关性从高到低进行排序
corrDf['Survived'].sort_values(ascending=False)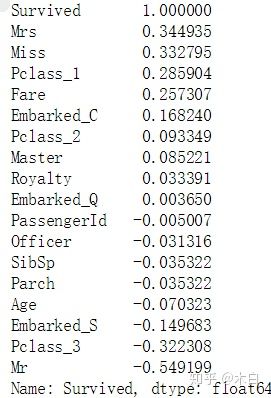
如上图结果所示,根据正负相关性选取特征进行重组新对象集合,以便下面构建模型算法
full_X = pd.concat([titleDf,
pclassDf,
familyDf,
full['Fare'],
cabinDf,
embarkedDf,
full['Sex']],axis=1)
full_X.columns
- 构建模型
1、模型特征区分与选取
sourceRow = 891 #这个是原始数据集的行数
source_X = full_X.loc[0:sourceRow - 1,:] #取full_X特征集里的所有行,这里的sourceRow - 1意味
着原始数据集是从0开始算起的,到890行,所以 -1。
source_y = full.loc[0:sourceRow - 1,'Survived'] #取原始数据集里的Survived标签,这里注意
原始数据集被赋值为 ‘full’,原始特征集为‘full_X’.
pred_X = full_X.loc[sourceRow:,:] #取full_X特征集里的特征作为预测特征,这里是从891开始取,
到最后一行
print('样本数据集特征:',source_X.shape)
print('样本预测数据集标签:',source_y.shape)
print('预测数据集特征:',pred_X.shape)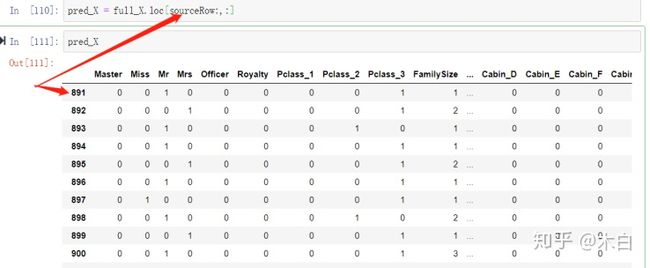

- 首先,就是要分清楚用于训练的特征数据source_x和标签数据source_y,这俩必须含有上述特征和标签Survived数据,全部属于样本数据。
- 同时full中还含有test.csv的数据,这一部分数据没有Survived列。本文正是要预测这一部分Survived情况,因此将full中test.csv部分提取出来,重命名为预测数据特征pre_x,以备后面预测用。
训练数据和测试数据集建立
from sklearn.cross_validation import train_test_split #导入训练数据和测试数据集的模块
train_X,test_X,train_y,test_y = train_test_split(source_X, #样本数据集特征
source_y, #样本预测数据集标签
train_size=0.8)
print('样本数据集特征:',source_X.shape,
'样本训练数据集特征:',train_X.shape,
'样本测试数据集特征:',test_X.shape)
print('样本数据集标签:',source_y.shape,
'样本训练数据集标签:',train_y.shape,
'样本测试数据集标签:',test_y.shape)
- 训练模型
#导入算法 --> 逻辑回归算法
from sklearn.linear_model import LogisticRegression
model = LogisticRegression() #创建模型,逻辑回归模型
model.fit(train_X, train_y) #训练模型
#对模型进行准去率评分
model.score(test_X, test_y)- 进行预测
pred_Y = model.predict(pred_X) #使用predict 方法进行预测pred_Y 标签
pred_Y = pred_Y.astype(int) #float 转换int
passenger_id = full.loc[sourceRow:,'PassengerId'] #截取原始数据集里的891到最后预测数据乘客ID
predDf = pd.DataFrame({'PassengerId':passenger_id,
'Survived': pred_Y}) #对要预测的乘客ID与预测结果进行组合
结论:
以上为利用逻辑回归算法对泰坦尼克号的生存率数据分析过程,日后深入学习后,还需对此进行完善。