
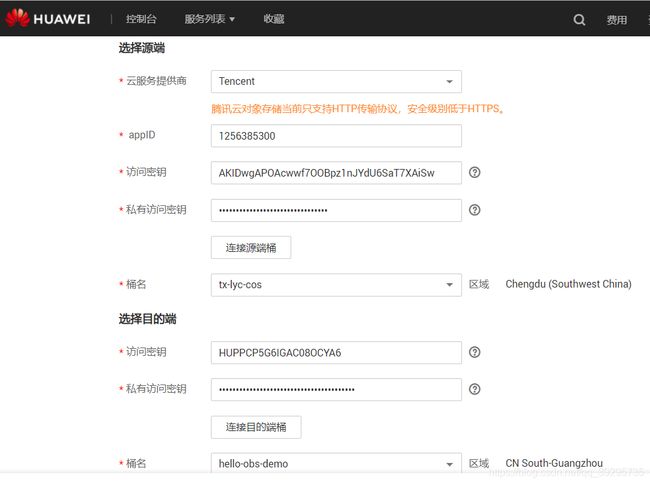
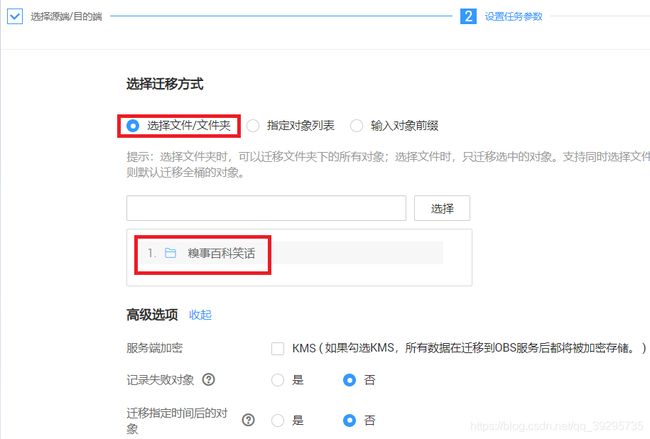

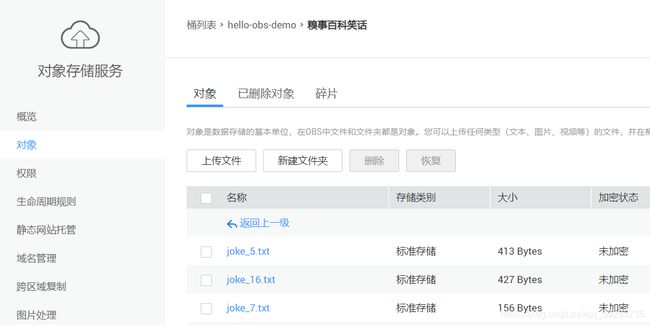
', "", joke) #删除多余标签 file_name = "joke_" + str(idx+1) + ".txt" file_path = '糗事百科笑话/' + file_name response = client.put_object(Bucket='tx-lyc-cos-1256385300',Body=joke,Key=file_path) print(response['ETag']) print(str(joke)) print("======") ###结束将笑话全部存放到腾讯云对象存储中###
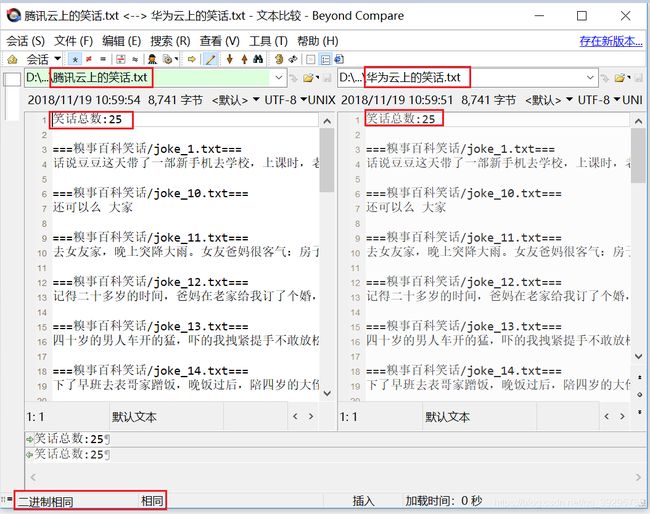
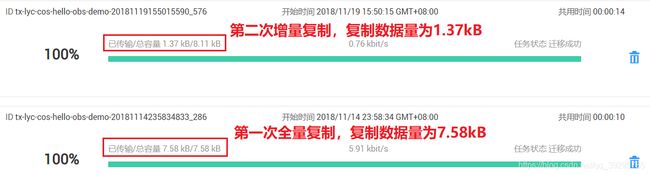
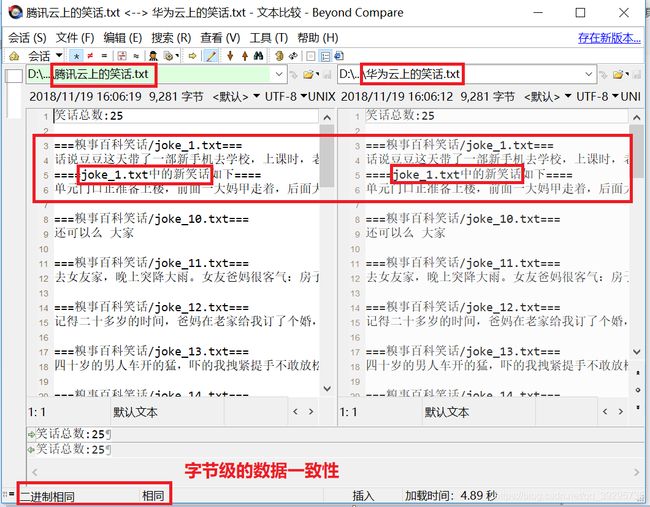
附录2:分别读取华为云和腾讯云的对象存储中的笑话,用于进行一致性对比。
#!/usr/bin/python3
#-*- coding: utf-8 -*-
import sys
#访问华为云对象存储所需的插件
from obs import ObsClient
from obs import *
#访问腾讯云对象存储所需的插件
from qcloud_cos import CosConfig
from qcloud_cos import CosS3Client
###开始 读取华为云中的笑话###
ak='HUPPCP5G6IGAC08Oxxxx'
sk='ql3wxcugPsA9sdczRYae2w87h84Uah72ryvPxxxx'
region ='https://obs.cn-south-1.myhwclouds.com'
obsClient = ObsClient(access_key_id = ak, secret_access_key= sk, server = region)
bucket = 'hello-obs-demo'
resp = obsClient.listObjects(bucketName=bucket, prefix='糗事百科笑话/joke')
files = resp.body.contents
fileCount = len(files)
#将这些文件中的笑话内容分别读出来,并写入名为“华为云上的笑话.txt”文件中
fo = open('华为云上的笑话.txt', 'wb')
fileCount = len(files)
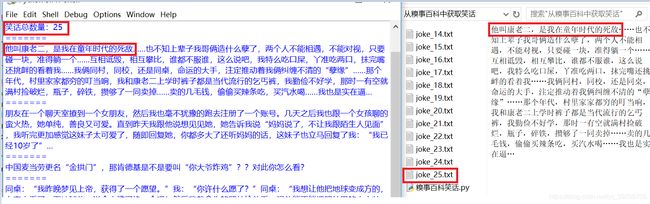
jokeInfo = '笑话总数:' + str(fileCount)
fo.write(jokeInfo.encode('utf-8', 'ignore'))
for idx in range(fileCount):
file = files[idx]
fileName = '\n\n===' + file.key + '===\n'
fo.write(fileName.encode('utf-8', 'ignore'))
fileBody = obsClient.getObject(bucketName=bucket, objectKey=file.key, loadStreamInMemory='True')
fo.write(fileBody.body.buffer)
fo.close()
obsClient.close()
print('读取华为云上的笑话结束,总数:' + str(fileCount))
###结束 读取华为云中的笑话###
###开始 读取腾讯云中的笑话###
secret_id = 'AKIDwgAPOAcwwf7OOBpz1nJYdU6SaT7Xxxx' # 替换为用户的secret_id
secret_key = 'MSIsCFMErDKCwUp142qRq20kHafW9xxx' # 替换为用户的secret_key
config = CosConfig(Region='ap-chengdu', SecretId=secret_id, SecretKey=secret_key, Token='')
client = CosS3Client(config)
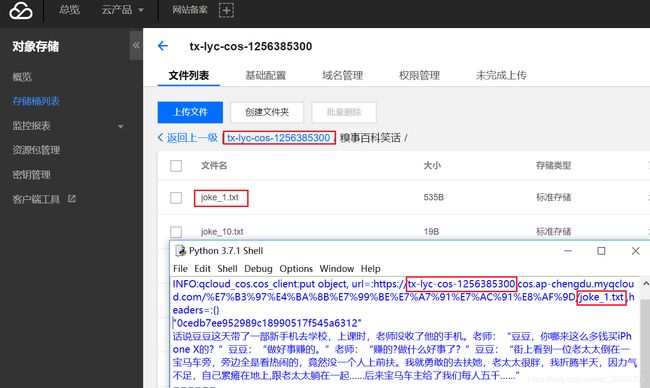
bucket = 'tx-lyc-cos-1256385300'
objList = client.list_objects(Bucket=bucket, Prefix='糗事百科笑话/joke')
files = objList['Contents']
#将这些文件中的笑话内容分别读出来,并写入名为“腾讯云上的笑话.txt”文件中
fo = open('腾讯云上的笑话.txt', 'wb')
fileCount = len(files)
jokeInfo = '笑话总数:' + str(fileCount)
fo.write(jokeInfo.encode('utf-8', 'ignore'))
for idx in range(fileCount):
file = files[idx]
fileName = '\n\n===' + file['Key'] + '===\n'
fo.write(fileName.encode('utf-8', 'ignore'))
fileBody = client.get_object(Bucket=bucket, Key=file['Key'])
fo.write(fileBody['Body'].get_raw_stream().read())
fo.close()
print('读取腾讯云上的笑话结束,总数:' + str(fileCount))
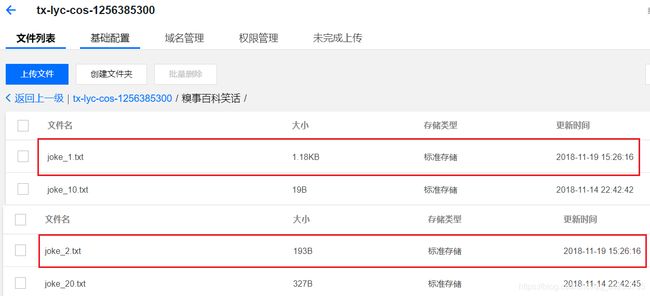
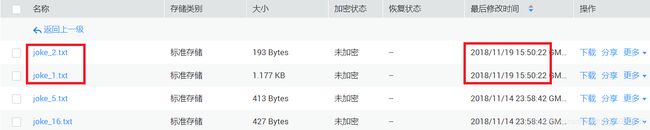
###结束 读取腾讯云中的笑话###附录3:测试笑话1文件追加最新的笑话(即存储新旧2个笑话),笑话2文件替换成新的笑话,其他文件保持不变。用于测试增量同步的情况。
#!/usr/bin/python3
#-*- coding: utf-8 -*-
import sys
#网络爬虫所需的插件
import urllib.request
import re
#腾讯云对象存储所需的插件
from qcloud_cos import CosConfig
from qcloud_cos import CosS3Client
###开始从糗事百科完整上爬取笑话内容###
#浏览器伪装池,将爬虫伪装成浏览器,避免被网站屏蔽
headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0")
opener = urllib.request.build_opener()
opener.addheaders = [headers]
urllib.request.install_opener(opener)
#获取糗事百科首页中的第1个和第2个笑话
webUrl = "http://www.qiushibaike.com/8hr/page/1"
webContent=urllib.request.urlopen(webUrl).read().decode("utf-8", "ignore")
matchPat = '.*?(.*?)'
jokes = re.compile(matchPat, re.S).findall(webContent)
joke1 = re.sub(r'\n', "", str(jokes[0])) #删除换行符
joke1 = re.sub(r'
', "", joke1) #删除多余标签
joke2 = re.sub(r'\n', "", str(jokes[1])) #删除换行符
joke2 = re.sub(r'
', "", joke2) #删除多余标签
###结束获取笑话###
###开始将笑话全部存放到腾讯云对象存储中###
secret_id = 'AKIDwgAPOAcwwf7OOBpz1nJYdU6SaT7Xxxxx' # 替换为用户的secret_id
secret_key = 'MSIsCFMErDKCwUp142qRq20kHafWxxxx' # 替换为用户的secret_key
region = 'ap-chengdu' # 替换为用户的region
token = None # 使用临时秘钥需要传入Token,默认为空,可不填
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key, Token=token) # 获取配置对象
client = CosS3Client(config)
bucket = 'tx-lyc-cos-1256385300'
#下载第一个笑话的内容到joke_1.txt中
fp = open('joke_1.txt', "wb")
jokeBody = client.get_object(Bucket=bucket, Key='糗事百科笑话/joke_1.txt')
fp.write(jokeBody['Body'].get_raw_stream().read())
print("下载旧的笑话")
#将新爬取的笑话1,追加到joke_1.txt中
sepString = '\n====joke_1.txt中的新笑话如下====\n'
fp.write(sepString.encode('utf-8', 'ignore'))
fp.write(joke1.encode('utf-8', 'ignore'))
fp.close()
rsp = client.put_object_from_local_file(Bucket='tx-lyc-cos-1256385300', LocalFilePath='joke_1.txt', Key='糗事百科笑话/joke_1.txt' )
print("写入新的笑话1")
#将新爬取的笑话2,直接覆盖腾讯云对象存储中的joke_2.txt中
rsp = client.put_object(Bucket='tx-lyc-cos-1256385300', Body=joke2,Key='糗事百科笑话/joke_2.txt' )
print("写入新笑话2")
###结束将笑话全部存放到腾讯云对象存储中###