spring boot整合spark,集群模式或local模式运行,http请求调用spark API,启动job任务配置、优化spark配置等
需求描述:前后端分离系统,用SpringBoot整合Spark API,调用大量数据(几百GB,上TB)进行处理计算,单机环境难以达到性能要求,此,需整合直接调用spark跑程序,且在集群跑…
在此,一台测试服务器模拟,搭建伪分布spark集群,用standalone模式运行。
文章目录
- 一、集群环境
-
- 二、项目配置环境
一、集群环境
包版本:
1.java1.8
2.spark 2.3.1
3.scala 2.11
4.CentOS Linux release 7.3.1611 (Core)
1、查看服务配置信息,包括内存、磁盘、CPU,spark任务会用到
[root@tycloud-x86-testserver ~]# free -h
total used free shared buff/cache available
Mem: 62G 33G 2.2G 31M 26G 28G
Swap: 31G 594M 30G
[root@tycloud-x86-testserver ~]# df -lh
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/cl-root 94G 80G 9.2G 90% /
devtmpfs 32G 0 32G 0% /dev
tmpfs 32G 84K 32G 1% /dev/shm
tmpfs 32G 18M 32G 1% /run
tmpfs 32G 0 32G 0% /sys/fs/cgroup
/dev/sda1 976M 142M 767M 16% /boot
/dev/mapper/cl-home 1.5T 360G 1.1T 25% /home
tmpfs 6.3G 16K 6.3G 1% /run/user/42
shm 64M 0 64M 0% /home/var/lib/docker/containers/ce39e6a0ea16e708a5f8d79c0f78643a2a9a197738aa2b546bc2e02b6320db1c/shm
shm 64M 0 64M 0% /home/var/lib/docker/containers/9d9f34fdd554a33a8a5e5c9752c1fb74e3c1b091e8422a2d247c06f36305d121/shm
shm 64M 0 64M 0% /home/var/lib/docker/containers/0ba5dc4159c3191f329f67e1de2bf30d5db8edd34fe5582a771a493c9ea0d050/shm
shm 64M 8.0K 64M 1% /home/var/lib/docker/containers/4071c651e6186522cd5efe0eaed4483000136c89855f6050725b431794f56464/shm
tmpfs 6.3G 0 6.3G 0% /run/user/0
查看CPU信息(型号)
[root@tycloud-x86-testserver ~]# cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
40 Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
物理封装的处理器的id,查看物理CPU个数
[root@tycloud-x86-testserver]# cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
2
位于相同物理封装的处理器中的内核数量,每个物理CPU中core的个数(即核数)
[root@tycloud-x86-testserver ~]# cat /proc/cpuinfo| grep "cpu cores"| uniq
cpu cores : 10
查看逻辑CPU的个数
[root@tycloud-x86-testserver ~]# cat /proc/cpuinfo| grep "processor"| wc -l
40
2、spark伪分布集群配置(省略很多,起来就行…)
下载的spark包,拷贝到服务器上,进入conf目录下
- cp spark-env.sh.template spark-env.sh
export JAVA_HOME=/opt/java
export SPARK_MASTER_IP=10.11.100.120
export SPARK_MASTER_HOST=tycloud-x86-testserver
export SPARK_MASTER_PORT=7077 #-- master主节点端口
export SCALA_HOME=/opt/scala
export SPARK_HOME=/opt/spark2.31
export SPARK_WORKER_MEMORY=40g
export SPARK_WORKER_OPTS="
-Dspark.worker.cleanup.enabled=true
-Dspark.worker.cleanup.interval=1800
-Dspark.worker.cleanup.appDataTtl=3600"
- cp spark-defaults.conf.template spark-defaults.conf
spark.master spark://tycloud-x86-testserver:7077
- vim slaves
localhost
- cd …/sbin ./start-all.sh 启动MASTER和WORKER进程
访问Spark UI界面 10.11.100.120:8080

二、项目配置环境
1、创建SpringBoot项目。
可手动搭建框架结构,初学者可访问(https://start.spring.io/)来页面配置导出Spring项目。
2、添加pom.xml依赖,强调此处spark依赖必须和集群版本一致,否则会报错,此处不看错误,单纯配置,后续我会复现错误,给大家展示分析错误问题
4.0.0
com.analysis
yl
1.0-SNAPSHOT
yl
war
org.springframework.boot
spring-boot-starter-parent
2.1.6.RELEASE
1.8
1.1.9
1.2.0
2.3.1
2.1.6.RELEASE
2.9.2
org.springframework.boot
spring-boot-starter-web
com.alibaba
druid-spring-boot-starter
${druid.version}
org.mybatis.spring.boot
mybatis-spring-boot-starter
${mybatis.version}
org.springframework.boot
spring-boot-starter-tomcat
${spring.boot.version}
provided
org.apache.spark
spark-core_2.11
${spark.version}
org.apache.spark
spark-sql_2.11
${spark.version}
org.scala-lang
scala-library
2.11.8
com.databricks
spark-xml_2.11
0.11.0
mysql
mysql-connector-java
5.1.47
org.springframework.boot
spring-boot-configuration-processor
true
${spring.boot.version}
io.springfox
springfox-swagger2
${swagger.version}
io.springfox
springfox-swagger-ui
${swagger.version}
org.apache.hadoop
hadoop-common
2.7.7
org.slf4j
slf4j-log4j12
org.apache.hadoop
hadoop-mapreduce-client-core
2.7.7
org.slf4j
slf4j-log4j12
io.netty
netty-all
4.1.17.Final
net.sf.json-lib
json-lib
2.4
jdk15
org.projectlombok
lombok
1.16.10
provided
yl
org.springframework.boot
spring-boot-maven-plugin
true
org.scala-tools
maven-scala-plugin
2.15.2
compile
testCompile
org.apache.maven.plugins
maven-compiler-plugin
1.8
1.8
UTF-8
org.apache.maven.plugins
maven-war-plugin
2.6
false
org.apache.maven.plugins
maven-dependency-plugin
copy-dependencies
compile
copy-dependencies
${project.build.directory}/${project.build.finalName}/WEB-INF/lib
system
3、配置SparkConf,以及一些配置参数,部分参数是在运行中由于环境问题等因素,加以限制,也可以作为优化spark任务的参数配置
若有感兴趣的同学可关注,咨询博主,具体参数曾出现过什么问题?
package com.analysis.yl.config;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.support.PropertySourcesPlaceholderConfigurer;
import org.springframework.core.env.Environment;
@Configuration
public class SparkConfig {
@Value("${spark.app.name}")
private String appName;
@Value("${spark.home}")
private String sparkHome;
@Value("${spark.master.uri}")
private String sparkMasterUri;
@Value("${spark.driver.memory}")
private String sparkDriverMemory;
@Value("${spark.worker.memory}")
private String sparkWorkerMemory;
@Value("${spark.executor.memory}")
private String sparkExecutorMemory;
@Value("${spark.executor.cores}")
private String sparkExecutorCores;
@Value("${spark.num.executors}")
private String sparkExecutorsNum;
@Value("${spark.network.timeout}")
private String networkTimeout;
@Value("${spark.executor.heartbeatInterval}")
private String heartbeatIntervalTime;
@Value("${spark.driver.maxResultSize}")
private String maxResultSize;
@Value("${spark.rpc.message.maxSize}")
private String sparkRpcMessageMaxSize;
@Bean
public SparkConf sparkConf() {
SparkConf sparkConf = new SparkConf()
.setAppName(appName)
.setMaster(sparkMasterUri)
.set("spark.driver.memory",sparkDriverMemory)
.set("spark.driver.maxResultSize",maxResultSize)
.set("spark.worker.memory",sparkWorkerMemory) //"26g"
.set("spark.executor.memory",sparkExecutorMemory)
.set("spark.executor.cores",sparkExecutorCores)
.set("spark.executor.heartbeatInterval",heartbeatIntervalTime)
.set("spark.num.executors",sparkExecutorsNum)
.set("spark.network.timeout",networkTimeout)
.set("spark.rpc.message.maxSize",sparkRpcMessageMaxSize);
// .set("spark.shuffle.memoryFraction","0") //默认0.2
return sparkConf;
}
@Bean
@ConditionalOnMissingBean(JavaSparkContext.class)
public JavaSparkContext javaSparkContext(){
return new JavaSparkContext(sparkConf());
}
@Bean
public SparkSession sparkSession(){
return SparkSession
.builder()
.sparkContext(javaSparkContext().sc())
.appName(appName)
.getOrCreate();
}
@Bean
public static PropertySourcesPlaceholderConfigurer propertySourcesPlaceholderConfigurer(){
return new PropertySourcesPlaceholderConfigurer();
}
}
4、配置好Conf后,需要在application.yml文件中配置参数,具体配置如下:
注释部分是曾出现的问题,就顺手写上了,并不代表别的参数没出现过问题~~
spark:
app:
name: yl
home: 127.0.0.1
master:
uri: spark://tycloud-x86-testserver:7077
driver:
memory: 4g
maxResultSize: 4g
worker:
memory: 40g
#cores 5 、num 8 、memory 5g 才是最完美的,报错,加参数限制
executor:
cores: 10
memory: 9g
heartbeatInterval: 1000000
num:
executors: 4
network:
timeout: 1474830
rpc:
message:
maxSize: 1024 #默认值是128MB,最大2047MB
#输序列化数据应该是有大小的限制,此错误消息意味着将一些较大的对象从driver端发送到executors
#Job aborted due to stage failure: Serialized task 5829:0 was 354127887 bytes, which exceeds max allowed:spark.rpc.message.maxSize (134217728 bytes)
5、编写测试spark程序,用springboot接口调用(ServiceImpl)
public class TestServiceImpl implements TestService {
private Logger logger = LoggerFactory.getLogger(TestServiceImpl .class);
//SparkSession 在Conf里面已经加载SparkConf配置 @Autowired
private SparkSession sparkSession;
//TODO 程序处理逻辑调用Spark代码
}
细节问题:肯定要在服务器和自己的电脑上相互配好主机名映射了,不然联调问题一大堆了。。。。。
6、编译打包程序,部署到服务器上测试
此处Spark程序使用scala代码编写,所以就不能像纯springBoot一样打包了,需先编译scala程序,然后再编译打包。。。
mvn clean scala:compile compile package

7、丢到tomcat里,启动,查看后台日志,没错!
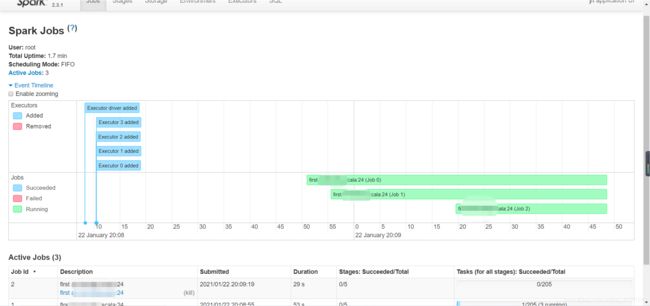
查看Spark UI界面、Spark Job已经启动,成功!!!!!!

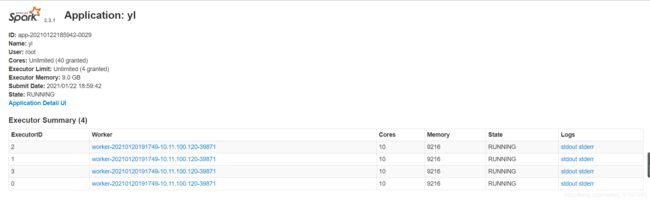
executors个数、每个executor中cores个数都是依据application.yml配置生成的。
8、 接下来接口调用测试spark程序了…
在之前的项目中,曾经SpringBoot也整合过hadoop、hive、hbase,有需要的学者,可留言找博主,后续也会分享~~~
有不足之处,欢迎各位留言反馈,错误经验下节分享。