Spark源码解析1-通信框架与Standalone模式启动
Spark源码解析1-通信框架与Standalone模式启动
Spark 通讯架构
RPC
RPC 是远程过程调用, Netty 就是一种基于 Actor 模型的 RPC 框架.
在 Hadoop 中 NN 与 DN 要通信, HBase 中 HMaster 和 HRegionServer 要进行通信, 其实都是用 RPC 的通信方式, 只不过对比 Hadoop, Spark 不一样, 又进行了一层封装, 源码看起来更加友好.
RPC 通信基于服务端与客户端的通信方式, 比如 Hadoop 中 NN 与 DN 通信, DN 写成功要告诉 NN 更新元数据, 如果 NN 想给 DN 发消息, 那么 NN 里一定有 DN 的客户端对象, 或者叫 REF 引用对象, 再比如说到 API,我们一般在 Idea 中把数据写入 Kafka 或 HBase, 一般都会创建一个客户端对象, 比如 Kafka 的生产者和消费者, 就是 Kafka 的客户端对象. 在 Spark 中 Driver 跟 Executor 通信, Master 跟 Worker 通信也都是一样的. Master 想给 Worker 发消息, 那么 Master 里面一定有一个 Woker 的客户端(或引用对象 ref )对象.
Spark 通信架构概述
Spark中通信框架的发展:
- Spark 早期版本中采用Akka作为内部通信部件。
- Spark 1.3 中引入 Netty 通信框架,为了解决Shuffle的大数据传输问题使用
- Spark 1.6 中 Akka 和 Netty 可以配置使用. Netty 完全实现了 Akka 在 Spark 中的功能。
- Spark 2 系列中,Spark 抛弃 Akka,使用 Netty。
Spark 2.x 版本使用 Netty 通讯框架作为内部通讯组件。Spark 基于 Netty 新的 RPC 框架借鉴了 Akka 的中的设计,它是基于 Actor 模型,如下图所示:
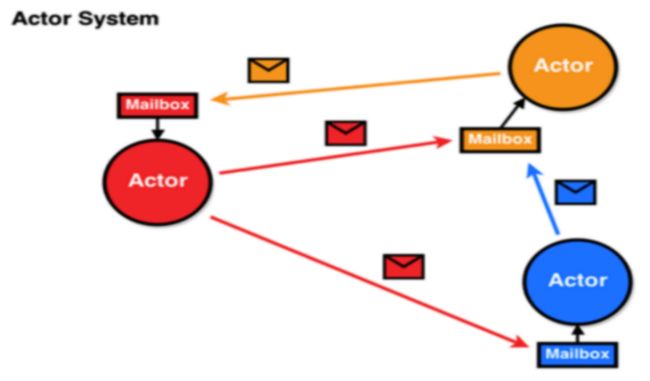
Spark通讯框架中各个组件(Client/Master/Worker)可以认为是一个个独立的实体,各个实体之间通过消息来进行通信。具体各个组件之间的关系图如下:
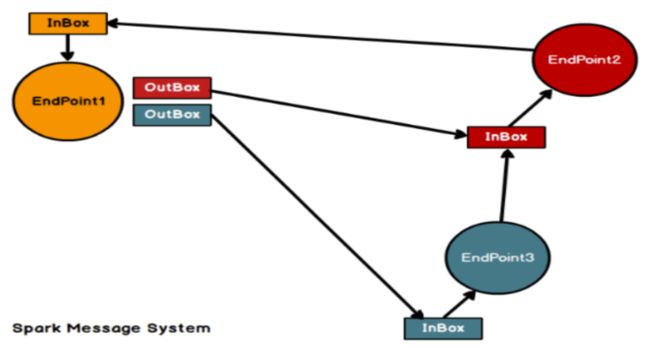
Spark通信终端
// Driver:
class DriverEndpoint extends IsolatedRpcEndpoint
// Executor:
class CoarseGrainedExecutorBackend extends IsolatedRpcEndpoint
Spark 通讯架构解析
Spark通信架构如下图所示:
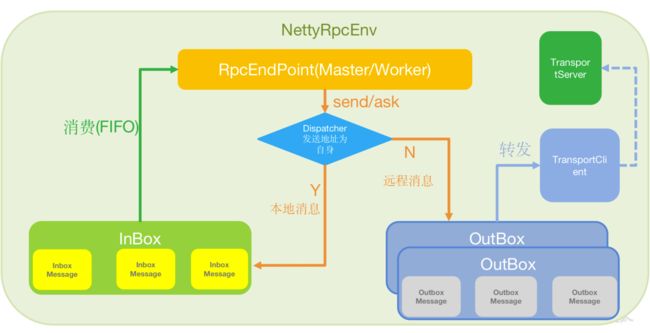
Netty RPC 框架在 Actor 模型基础上进行了加工. 要能进行互相通信, 首先要处于同一个环境, 也就是同一个 RpcEnv 中, Endpoint 也就是各个需要通信的节点, 可能是 Master/Worker, 也可能是 Driver/Executor, 但都继承于 RpcEndpoint 接口或抽象类. 每个终端 Endpoint 拥有一个 Inbox 和 若干个 Outbox, Outbox 在源码中是一个 Map 集合, 前面要放对方的通信地址. 具体而言:
RpcEndpoint
RPC 通信终端。Spark 针对每个节点(Client/Master/Worker)都称之为一个 RPC 终端,且都实现 RpcEndpoint 接口,内部根据不同端点的需求,设计不同的消息和不同的业务处理,如果需要发送(询问)则调用 Dispatcher。在 Spark 中,所有的终端都存在生命周期:
- Constructor: 创建通信环境, 创建终端并设置进环境中
- onStart: 启动
- receive*: 阻塞进程, 长轮询接受处理收到的消息.
- onStop: 执行
bin/stop-all.sh时调用
RpcEnv
RPC 上下文环境,每个 RPC 终端运行时依赖的上下文环境称为 RpcEnv;在当前 Spark 版本中使用的 NettyRpcEnv.
Dispatcher
消息调度(分发)器,针对于 RPC 终端需要发送远程消息或者从远程 RPC 接收到的消息,分发至对应的指令 InBox(OutBox)。如果指令接收方是自己则存入 Inbox,如果指令接收方不是自己,则放入 OutBox;
Inbox
指令消息收件箱。一个本地 RpcEndpoint 对应一个收件箱,Dispatcher 在每次向 Inbox 存入消息时,都将对应 EndpointData 加入内部 ReceiverQueue 中,另外 Dispatcher 创建时会启动一个单独线程进行轮询 ReceiverQueue,进行收件箱消息消费.
RpcEndpointRef
RpcEndpointRef 是对远程 RpcEndpoint 的一个引用。当我们需要向一个具体的RpcEndpoint 发送消息时,一般我们需要获取到该 RpcEndpoint 的引用 Ref,然后通过该应用发送消息。
OutBox
指令消息发件箱。对于当前 RpcEndpoint 来说,一个目标 RpcEndpoint 对应一个发件箱,如果向多个目标 RpcEndpoint 发送信息,则有多个 OutBox。当消息放入 Outbox 后,紧接着通过 TransportClient 将消息发送出去。消息放入发件箱以及发送过程是在同一个线程中进行;
RpcAddress
表示远程的 RpcEndpointRef 的地址,Host + Port。
TransportClient
Netty 通信客户端,一个 OutBox 对应一个 TransportClient,TransportClient 不断轮询OutBox,根据 OutBox 消息的 receiver 信息,请求对应的远程 TransportServer;
TransportServer
Netty 通信服务端,一个 RpcEndpoint 对应一个 TransportServer,接受远程消息后调用Dispatcher 分发消息至对应收发件箱.
Spark Standalone 模式集群启动
启动与通信机制

- start-all.sh 脚本,实际是执行
java -cp Master和java -cp Worker; - Master 启动时首先创建一个 RpcEnv 对象,负责管理所有通信逻辑;
- Master 通过 RpcEnv 对象创建一个 Endpoint,Master 就是一个 Endpoint,Worker 可以与其进行通信;
- Worker 启动时也是创建一个 RpcEnv 对象;
- Worker 通过 RpcEnv 对象创建一个 Endpoint;
- Worker 通过 RpcEnv 对象建立到 Master 的连接,获取到一个 RpcEndpointRef 对象,通过该对象可以与 Master 通信;
- Worker 向 Master 注册,注册内容包括主机名、端口、CPU Core 数量、内存数量;
- Master 接收到 Worker 的注册,将注册信息维护在内存中的 Table 中,其中还包含了一个到 Worker 的R pcEndpointRef 对象引用;
- Master 回复 Worker 已经接收到注册,告知 Worker 已经注册成功;
- Worker 端收到成功注册响应后,开始周期性向 Master 发送心跳。
通信机制源码分析 Master
Master 启动部分:
// org.apache.spark.deploy.master.Master
/*
RpcEndpoint:
life-cycle:constructor -> onStart -> receive* -> onStop
send/ask === receive/receiveAndReply
*/
// Master.scala 1122
//1.启动通信环境 RpcEnv 并启动自身 Endpoint
val (rpcEnv, _, _) = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, conf)
// Master.scala 1138
//2.创建通信环境 NettyRpcEnv
val rpcEnv = RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr)
// Master.scala 1139
//3.构建 "Master" Endpoint 对象并设置进环境中
val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME,
new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
// Master.scala 141
//4.启动, 见下面注意 5
onStart()
// Master.scala onStart() 153
//5.以固定的频率给自身 Master 发送校验消息, 校验 Worker 是否下线
checkForWorkerTimeOutTask = forwardMessageThread.scheduleAtFixedRate(
self.send(CheckForWorkerTimeOut)
)
// Master.scala receive() 428 → 1053
//6.处理消息. 检查和移除那些超时的 Workers
case CheckForWorkerTimeOut =>
timeOutDeadWorkers(){
val toRemove = workers.filter(_.lastHeartbeat < currentTime - workerTimeoutMs).toArray
}
注意:
- 3 中, 如下图, NettyRpcEnv 里面有 Dispatcher, OutBox, TansportServer 等, 它们是与环境绑定的, 不是 Endpoint 的一个属性:
- 5 中, 发送消息
self.send(CheckForWorkerTimeOut), 这里是 Master 的 Endpoint 调用send()方法, 怎么实现呢? 代码中, 无论 Master 还是 Worker Endpoint 对象, 都是 NettyRpcEndpointRef 类的对象:
// NettyRpcEnv.scala 的内部类 NettyRpcEndpointRef 188
private[netty] def send(message: RequestMessage): Unit = {
val remoteAddr = message.receiver.address
if (remoteAddr == address) {
// Message to a local RPC endpoint.
try {
dispatcher.postOneWayMessage(message)
} catch {
case e: RpcEnvStoppedException => logDebug(e.getMessage)
}
} else {
// Message to a remote RPC endpoint.
postToOutbox(message.receiver, OneWayOutboxMessage(message.serialize(this)))
}
}
通过以上代码, 终端对象来判断是给自己还是给其他终端发送消息. 每个对象有它自己的属性 address, 即这个对象是 Master 还是 Worker, 判断 This (这里是 Master) 的 address 和消息的 remoteAddr 判断是否相等, 相等说明是给自己发消息, 不等说明是给其他终端.
代码中也可以看到, 相等的话, 由 Dispatcher 调用 postOneWayMessage(message) 放入 Inbox, 不相等放入 Outbox: postToOutbox(...). 这也正是 Spark 通信架构图的消息发送过程.
- 4 中, onStart 是什么时候调用的呢? 其实起一个 Endpoint 就会创建一个 Inbox, 构建 Inbox 时就会自动发第一条 OnStart 消息:
// Master.scala 1139
val masterEndpoint = rpcEnv.setupEndpoint(...)
// NettyRpcEnv 136
dispatcher.registerRpcEndpoint(name, endpoint)
// Dispatcher 77
sharedLoop.register(name, endpoint)
// MessafeLoop 149
val inbox = new Inbox(name, endpoint)
这里注意, RpcEnv 内有 Dispatcher, Dispacher 通过 sharedLoop: SharedMessageLoop 来注册 RpcEndpoint, sharedLoop 注册时会先 new 一个 Inbox, new 的时候就添加了一个 OnStart 消息:
private[netty] class Inbox(val endpointName: String, val endpoint: RpcEndpoint)
extends Logging {
@GuardedBy("this")
protected val messages = new java.util.LinkedList[InboxMessage]()
...
// OnStart should be the first message to process
inbox.synchronized {
messages.add(OnStart)
}
之后调用 Inbox 的 process() 方法处理 OnStart 消息, 即 endpoint.onStart().
通信机制源码分析 Worker
Worker 部分:
首先其构造方法:
package org.apache.spark.deploy.worker
import ...
private[deploy] class Worker(
override val rpcEnv: RpcEnv,
webUiPort: Int,
cores: Int,
memory: Int,
masterRpcAddresses: Array[RpcAddress],
endpointName: String,
workDirPath: String = null,
val conf: SparkConf,
val securityMgr: SecurityManager,
resourceFileOpt: Option[String] = None,
externalShuffleServiceSupplier: Supplier[ExternalShuffleService] = null)
extends ThreadSafeRpcEndpoint with Logging {...}
多了几个属性, 核数 cores, 内存 memory 和 masterRpcAddresses, 它是一个 Array[RpcAddress], 也就是高可用配置.
//org.apache.spark.deploy.worker.Worker
/*
RpcEndpoint:
life-cycle:constructor -> onStart -> receive* -> onStop
send/ask === receive/receiveAndReply
*/
//1.main()
//Worker 826
//2.启动通信环境 RpcEnv 并启动自身 Endpoint ↓
val rpcEnv = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, args.cores,
args.memory, args.masters, args.workDir, conf = conf,
resourceFileOpt = conf.get(SPARK_WORKER_RESOURCE_FILE))
//Worker 858
//3.创建通信环境 RpcEnv
val rpcEnv = RpcEnv.create(systemName, host, port, conf, securityMgr)
//4.获取Master通信地址
val masterAddresses = masterUrls.map(RpcAddress.fromSparkURL)
//5.创建自身对象并将自身设置进环境中
// new Worker() 调用 Worker 的构造方法, 生成 Worker 的 Endpoint
rpcEnv.setupEndpoint(ENDPOINT_NAME, new Worker(rpcEnv, webUiPort, cores, memory,
masterAddresses, ENDPOINT_NAME, workDir, conf, securityMgr, resourceFileOpt))
//6.启动
// 同上面 Master 一样是在 rpcEnv.setupEndpoint(...) 时调用的, 所以这里直接查看 Worker.scala 这个 Endpoint 的 onStart() 方法即可, 因为最终调用还是 endpoint.onStart()
// Worker class 199 ↓
onStart()
// Worker class 207 ↓
//7.向Master进行注册
registerWithMaster()
// Worker class 385 ↓
//8.尝试与所有Master(高可用)进行注册
tryRegisterAllMasters()
// Worker class 277 ↓
// 获得 master 终端客户端或引用
val masterEndpoint = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
sendRegisterMessageToMaster(masterEndpoint)
// Worker class 408 ↓
//9.向Master发送注册消息
// 调用 Master 终端引用发送 RegisterWorker() 消息
sendRegisterMessageToMaster(masterEndpoint){
masterEndpoint.send(RegisterWorker(...))
}
//10.注册成功,以固定频率给自己发送消息(向Master发送心跳信息), 具体见下解释.
forwardMessageScheduler.scheduleAtFixedRate(
self.send(SendHeartbeat)
)
//11.维持心跳, 见下解释
sendToMaster(Heartbeat(workerId, self))
masterRef.send(message)
Master 接收处理 Worker 注册的请求具体, 如下:
// Master class 246
case RegisterWorker(
id, workerHost, workerPort, workerRef, cores, memory, workerWebUiUrl,
masterAddress, resources) =>
logInfo("Registering worker %s:%d with %d cores, %s RAM".format(
workerHost, workerPort, cores, Utils.megabytesToString(memory)))
if (state == RecoveryState.STANDBY) {
workerRef.send(MasterInStandby)
} else if (idToWorker.contains(id)) {
workerRef.send(RegisteredWorker(self, masterWebUiUrl, masterAddress, true))
} else {
val workerResources = resources.map(r => r._1 -> WorkerResourceInfo(r._1, r._2.addresses))
val worker = new WorkerInfo(id, workerHost, workerPort, cores, memory,
workerRef, workerWebUiUrl, workerResources)
if (registerWorker(worker)) {
persistenceEngine.addWorker(worker)
workerRef.send(RegisteredWorker(self, masterWebUiUrl, masterAddress, false))
schedule()
} else {
val workerAddress = worker.endpoint.address
logWarning("Worker registration failed. Attempted to re-register worker at same " +
"address: " + workerAddress)
workerRef.send(RegisterWorkerFailed("Attempted to re-register worker at same address: "
+ workerAddress))
}
}
- 251 行如果当前 Master 是 STANDBY 状态, 则向 Worker 发送
workerRef.send(MasterInStandby), Worker 端接收什么都不干, 因为是向好多个 Master 注册, 所以直接注册下一个就好了. - 253 行意思是如果已经注册过了, 那么发送已经注册的信息. 这是什么情况呢? 比如我们不小心把一台节点的 Spark 文件全部发送给另一台, 那么他们的 WorkerId 相同, 就会出现这种情况.
- 不是以上情况, 正常注册. Worker 将注册信息维护在内存中的 Table 中,其中还包含了一个到 Worker 的 RpcEndpointRef 对象引用, 最后给 Worker 发送已经注册成功的消息.
- Worker 端接收被注册状态消息是调用:
// Worker class 467
override def receive: PartialFunction[Any, Unit] = synchronized {
case msg: RegisterWorkerResponse =>
handleRegisterResponse(msg)
// Worker class 421
private def handleRegisterResponse(msg: RegisterWorkerResponse): Unit = synchronized {
msg match {
case RegisteredWorker(masterRef, masterWebUiUrl, masterAddress, duplicate) =>
val preferredMasterAddress = if (preferConfiguredMasterAddress) {
masterAddress.toSparkURL
} else {
masterRef.address.toSparkURL
}
// there're corner cases which we could hardly avoid duplicate worker registration,
// e.g. Master disconnect(maybe due to network drop) and recover immediately, see
// SPARK-23191 for more details.
if (duplicate) {
logWarning(s"Duplicate registration at master $preferredMasterAddress")
}
logInfo(s"Successfully registered with master $preferredMasterAddress")
registered = true
changeMaster(masterRef, masterWebUiUrl, masterAddress)
forwardMessageScheduler.scheduleAtFixedRate(
() => Utils.tryLogNonFatalError { self.send(SendHeartbeat) },
0, HEARTBEAT_MILLIS, TimeUnit.MILLISECONDS)
if (CLEANUP_ENABLED) {
logInfo(
s"Worker cleanup enabled; old application directories will be deleted in: $workDir")
forwardMessageScheduler.scheduleAtFixedRate(
() => Utils.tryLogNonFatalError { self.send(WorkDirCleanup) },
CLEANUP_INTERVAL_MILLIS, CLEANUP_INTERVAL_MILLIS, TimeUnit.MILLISECONDS)
}
val execs = executors.values.map { e =>
new ExecutorDescription(e.appId, e.execId, e.cores, e.state)
}
masterRef.send(WorkerLatestState(workerId, execs.toList, drivers.keys.toSeq))
...
其中第 18 行, 如果重复了, 也就是上面第二种情况, 打印警告信息.
到 31 行, 即之前 Worker 源码那题提到的第 10 点: 注册成功后, 先以固定频率给自己发送消息通知自己需要给 Master 发送心跳消息 (32 行 self.send(WorkDirCleanup)), 然后自己收到消息然后再给 Master 发送心跳消息, 即上面的 11:
// Worker class 471
case SendHeartbeat =>
if (connected) { sendToMaster(Heartbeat(workerId, self)) }
// Worker class 712
masterRef.send(message)
最后在 Master 处理:
// Master class
case Heartbeat(workerId, worker) =>
idToWorker.get(workerId) match {
case Some(workerInfo) =>
workerInfo.lastHeartbeat = System.currentTimeMillis()
case None =>
if (workers.map(_.id).contains(workerId)) {
logWarning(s"Got heartbeat from unregistered worker $workerId." +
" Asking it to re-register.")
worker.send(ReconnectWorker(masterUrl))
} else {
logWarning(s"Got heartbeat from unregistered worker $workerId." +
" This worker was never registered, so ignoring the heartbeat.")
}
}
这段代码两个关键点:
一, case Some(workerInfo) => 是 Master 中记录了 Worker 信息.
这里面关键的第 5 行, 将相应 Worker 的 lastHeartbeat 属性更新为当前的系统时间.
所以, Worker 以固定的评率给 Master 发心跳信息, Master 对 lastHeartbeat 定期更新, 那么 Master 主动校验 Worker 是否下线的时候就不会过时 (Master 源码 5). 如果 Worker 真的挂掉了, 那么这里最后心跳时间就不会更新, 那么随着时间的退役, Master 以固定的频率给自身 Master 发送校验消息, 校验 Worker 是否下线这个过程就会校验到超过阈值 60s 的 Worker. 比如 NN 和 DN 之间的心跳, 比如 RM 和 NM, 比如 HMaster 和 HRegionServer 之前的通信都是这样的.
二, case None =>, 即没有 Worker 信息.
比如, 本来成功注册, 然后 Worker 与 Master 之间的通信挂掉了, 然后由于 Master 固定频率对 Worker 的校验导致该 Worker 超时被移除, 等待一段时间恢复通信, Worker 发送的心跳到 Master 这边, Master 进行处理时就会发现找不到这个被 remove 的 Worker, 然后如果判断 Workers 文件里有这个 Worker, 就进行一个重连.
里最后心跳时间就不会更新, 那么随着时间的退役, Master 以固定的频率给自身 Master 发送校验消息, 校验 Worker 是否下线这个过程就会校验到超过阈值 60s 的 Worker. 比如 NN 和 DN 之间的心跳, 比如 RM 和 NM, 比如 HMaster 和 HRegionServer 之前的通信都是这样的.
二, case None =>, 即没有 Worker 信息.
比如, 本来成功注册, 然后 Worker 与 Master 之间的通信挂掉了, 然后由于 Master 固定频率对 Worker 的校验导致该 Worker 超时被移除, 等待一段时间恢复通信, Worker 发送的心跳到 Master 这边, Master 进行处理时就会发现找不到这个被 remove 的 Worker, 然后如果判断 Workers 文件里有这个 Worker, 就进行一个重连.
之后 Master 与 Worker 之间分别维护自己的长轮询, Master 这边不断地校验 Worker 是否在线, Worker 这边不断地向 Master 发送心跳消息.