Scrapy框架的安装和简单使用
Scrapy框架的安装和简单使用
- Scrapy框架的安装和简单使用
- 前言
- 一、环境准备
- 二、安装步骤
-
- 1.安装相关库
- 三、创建和简单介绍
- 总结
Scrapy框架的安装和简单使用
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- Scrapy框架的安装和简单使用
- 前言
- 一、环境准备
- 二、安装步骤
-
- 1.安装相关库
- 三、创建和简单介绍
- 总结
前言
工欲善其事,必先利其器。这是我第一次写文章,也算是记录一下自己的学习日常。
什么是Scrapy框架?
Scrapy是一个快速、高层次、轻量级的屏幕抓取和web抓取的python爬虫框架
Scrapy的用途:
Scrapy用途非常广泛,主要用于抓取特定web站点的信息并从中提取特定结构的数据,除此之外,还可用于数据挖掘、监测、自动化测试、信息处理和历史片段(历史记录)打包等
了解完Scrapy框架后,我们就来看看怎么安装和使用吧
一、环境准备
win64 位
python 3.8
二、安装步骤
1.安装相关库
由于Scrapy的安装涉及很多库,如果直接在控制台安装可能受网速影响会很慢亦或者安装失败,所以这里推荐使用将包下载到本地,然后再控制台安装;还有一个办法是使用国内的源。(不过笔者对于Twisted库国内的一直安装失败,是在https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 下载到本地然后安装的)
需要安装的库有:
1.wheel库
直接在控制台输入
pip install wheel -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
2.lxml库
直接在控制台输入
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
3.PyOpenssl库
直接在控制台输入
pip install PyOpenssl -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
4.Twisted库
两种方法:
(1) 在https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 上找到对应的版本下载到本地。
例如

由于笔者这里是python 3.8 ,win64,所以下载 Twisted‑20.3.0‑cp38‑cp38‑win_amd64.whl 这一个。下载完成后找到文件的位置复制它的路径,例如C:\Users\CODER\Downloads,然后在控制台安装。
pip install C:\Users\CODER\Downloads\Twisted-20.3.0-cp38-cp38-win_amd64.whl
(2)直接在控制台输入
pip install Twisted -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
5.Pywin32 库
直接在控制台输入
pip install Pywin32 -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
6.scrapy 库
直接在控制台输入
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
这样Scrapy框架就按照完成啦
如果以上库有按照失败的,都可以用Twisted库的安装方法,下载到本地再安装,方法命令同上。最后再推荐大家一个安装python 相关库的命令
pip install <包名> -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
其中
-i https://pypi.tuna.tsinghua.edu.cn/simple 表示使用清华源
–trusted-host pypi.tuna.tsinghua.edu.cn 表示添加信任
三、创建和简单介绍
1.首先是创建一个项目
在控制台,先进入你要创建项目的位置,然后输入执行
scrapy startproject <项目名>
例如

出现这样的提示即创建成功。
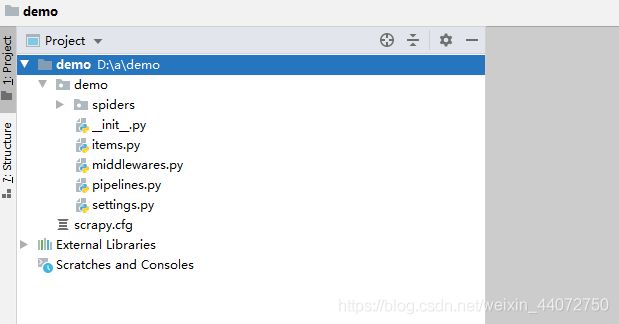
然后在pycharm中便可以打开这个项目
2.创建一个爬虫文件
我们的爬虫文件需要在 spiders目录中,所以我们需要先进入spiders路径,然后才能执行创建命令。
scrapy genspider <爬虫名> www.baidu.com
其中 www.baidu.com 为网站域名,这里用百度的域名作为示范。

出现这样的提示即创建成功。(必须先进入spiders路径哦!)

在项目中的spiders目录下即可看见刚刚创建的爬虫文件。
这样一个爬虫项目的创建便完成啦!
3.简单介绍
这里来解释一下各个文件的作用:
items.py:定义爬虫程序的数据模型
middlewares.py:定义数据模型中的中间件
pipelines.py:管道文件,负责对爬虫返回数据的处理
settings.py:爬虫程序设置,主要是一些爬虫速度并发和各优先级等等等等的设置(后面会专门写文章介绍)
scrapy.cfg:内容为scrapy的基础配置
总结
以上就是对于scrapy的安装及简单介绍,这是笔者第一次发表文章,希望对大家有所帮助,如有问题欢迎大家指出。后面我也会继续更新scrapy的相关使用,也算是一个个人学习笔记。