K-means聚类算法【理论+案例演示】
K-means聚类算法
K-means聚类算法也称k均值聚类算法,时集简单和经典于一身的基于距离的聚类算法。它采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为类族是由距离靠近的对象组成的,取中心点作为质心,把靠近质心的归为一类。
K-means核心思想
K-means聚类算法是一种迭代求解的过程,是一种自学习算法,其步骤是先设定质心的个数,随机找质心位置,把每个点离各个质心的位置算出来,然后取最近的质心,该点归为该质心一类。然后再相同类里重新计算,再次找出新的质心,再进行第一步计算,重新进行分类,至于分类几次,也是可以设定的。不是越多越好,这个次数也是需要不断检验的。
数据样本
链接:数据样本
提取码:lyq6
算法图解
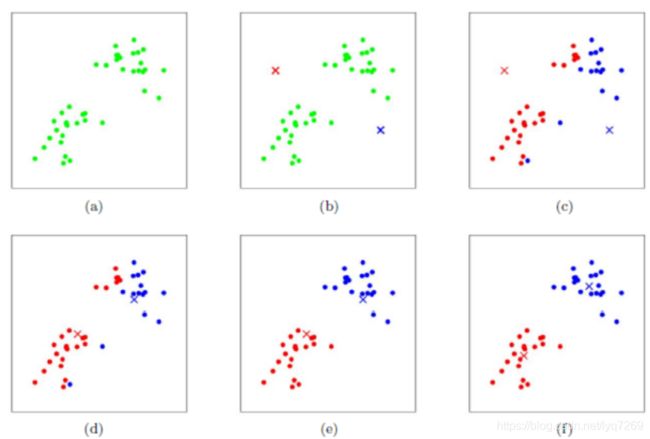
算法代码演示
导入jar包获取数据
# 导入jar包
import numpy as np
import pandas as pd
#获取数据
data = pd.read_csv("xigua.csv")
# 取数据的所有行和倒数两列
t = data.iloc[:,-2:]
# 展示数据
t
进行简单的样例演示(这步可以没有)
# 样例演示
# 样例数据
X = np.asarray([[1,2,3],[4,5,6],[7,8,9],[17,18,19],[14,15,16]])
display(X)
# 随机因子
np.random.seed(0)
# 0-5之间取两个数 , 5取不到
numarray = np.random.randint(0,len(X),2)
# 战术获取的随机数
display(numarray)
# 获取的数组中的随机元素
cluster = X[numarray]
# 展示获取成果
display(cluster)
# 定义label数组,记录X数据集中每一个样本所属的聚类
label_ = np.zeros(len(X))
display(label_)
# enumerate(X) 表示把 X数组的下标和数组内容全部进行循环
for index,x in enumerate(X): # 0 [1,2,3] [[14,15,16],[1,2,3]]
# 计算一个点到各个质心的距离
dis = np.sqrt(np.sum((x-cluster)**2,axis=1)) # [22.5166605,0]
display(dis)
# 取值最小的下标
label_[index] = dis.argmin()
display(label_)
# 分类
x1 = X[label_==0]
display(x1)
x2 = X[label_==1]
display(x2)
# 求平均
cluster1 = np.mean(x1,axis=0)
cluster2 = np.mean(x2,axis=0)
display(cluster1)
display(cluster2)
编写K-means类
class KMeans:
"""KMeans 算法实现"""
def __init__(self,k,times):
"""
k : int
质心的个数
times : int
聚类迭代次数
"""
self.k = k
self.times = times
def fit(self,X):
"""根据训练数据集,对模型进行训练,找到中k个质心
----
X :类数组类型
训练数据集
"""
X = np.asarray(X)
np.random.seed(1)
numarray = np.random.randint(0,len(X),self.k)
self.cluster_ = X[numarray]
# 定义标签
self.label_ = np.zeros(len(X))
for t in range(self.times):
for index,x in enumerate(X):
dis = np.sqrt(np.sum((x-self.cluster_)**2,axis=1))
self.label_[index] = dis.argmin()
# 找到新的质心
for i in range(self.k):
self.cluster_[i] = np.mean(X[self.label_==i],axis=0)
def predict(self,X):
"""预测 数据集"""
X = np.asarray(X)
result = np.zeros(len(X))
for index, x in enumerate(X):
dis = np.sqrt(np.sum((x - self.cluster_)**2,axis=1))
result[index] = dis.argmin()
return result
创建KMeans对象,处理数据进行分类
# 创建KMeans类对象
kmeans = KMeans(3,50)
# 调用fit方法
kmeans.fit(t)
display(kmeans.cluster_)
display(kmeans.label_)
display(t[kmeans.label_==0]) #类别1
display(t[kmeans.label_==1]) #类别2
display(t[kmeans.label_==2]) #类别3
# 预测,随机 创建三个样本,测试三个样本归为哪个类
test_X = np.asarray([[0.1,0.2],[0.5,0.7],[1.8,0.7]])
result = kmeans.predict(test_X)
display(result)
数据分类完成,进行可视化
import matplotlib as mpl
import matplotlib.pyplot as plt
# matplotlib 不支持中文,需要配置一下,设置一个中文字体
mpl.rcParams["font.family"] = "SimHei"
# 能够显示 中文 ,正常显示 "-"
mpl.rcParams["axes.unicode_minus"] = False
plt.figure(figsize=(10,10))
plt.scatter(t[kmeans.label_==0].iloc[:,0],t[kmeans.label_==0].iloc[:,1],label = "类别1")
plt.scatter(t[kmeans.label_==1].iloc[:,0],t[kmeans.label_==1].iloc[:,1],label = "类别1")
plt.scatter(t[kmeans.label_==2].iloc[:,0],t[kmeans.label_==2].iloc[:,1],label = "类别1")
plt.scatter(kmeans.cluster_[:,0],kmeans.cluster_[:,1],marker="+",s=300)
plt.title("kmeans 示例图")
plt.xlabel("质量")
plt.ylabel("甜度")
plt.legend()
plt.show()