import csv
import matplotlib.pyplot as plt
import numpy as np
import xlrd
from sklearn import preprocessing
from mpl_toolkits.mplot3d import Axes3D
from xlsxwriter import worksheet
def normalize(X, axis=-1, p=2):
lp_norm = np.atleast_1d(np.linalg.norm(X, p, axis))
lp_norm[lp_norm == 0] = 1
return X / np.expand_dims(lp_norm, axis)
def euclidean_distance(one_sample, X):
one_sample = one_sample.reshape(1, -1)
X = X.reshape(X.shape[0], -1)
distances = np.power(np.tile(one_sample, (X.shape[0], 1)) - X, 2).sum(axis=1)
return distances
class Kmeans():
"""Kmeans聚类算法.
Parameters:
-----------
k: int
聚类的数目.
max_iterations: int
最大迭代次数.
varepsilon: float
判断是否收敛, 如果上一次的所有k个聚类中心与本次的所有k个聚类中心的差都小于varepsilon,
则说明算法已经收敛
"""
def __init__(self, k=4, max_iterations=500, varepsilon=0.0001):
self.k = k
self.max_iterations = max_iterations
self.varepsilon = varepsilon
def init_random_centroids(self, X):
n_samples, n_features = np.shape(X)
centroids = np.zeros((self.k, n_features))
for i in range(self.k):
centroid = X[np.random.choice(range(n_samples))]
centroids[i] = centroid
return centroids
def _closest_centroid(self, sample, centroids):
distances = euclidean_distance(sample, centroids)
closest_i = np.argmin(distances)
return closest_i
def create_clusters(self, centroids, X):
n_samples = np.shape(X)[0]
clusters = [[] for _ in range(self.k)]
for sample_i, sample in enumerate(X):
centroid_i = self._closest_centroid(sample, centroids)
clusters[centroid_i].append(sample_i)
return clusters
def update_centroids(self, clusters, X):
n_features = np.shape(X)[1]
centroids = np.zeros((self.k, n_features))
for i, cluster in enumerate(clusters):
centroid = np.mean(X[cluster], axis=0)
centroids[i] = centroid
return centroids
def get_cluster_labels(self, clusters, X):
y_pred = np.zeros(np.shape(X)[0])
for cluster_i, cluster in enumerate(clusters):
for sample_i in cluster:
y_pred[sample_i] = cluster_i
return y_pred
def predict(self, X):
centroids = self.init_random_centroids(X)
for _ in range(self.max_iterations):
clusters = self.create_clusters(centroids, X)
former_centroids = centroids
centroids = self.update_centroids(clusters, X)
diff = centroids - former_centroids
if diff.any() < self.varepsilon:
break
return self.get_cluster_labels(clusters, X)
data = []
wk = xlrd.open_workbook(r'D:\用kmeans算法的排名.xlsx')
sheets = wk.sheet_by_name('sheet1')
ws = wk.sheet_by_index(0)
nrows = ws.nrows
for i in range(1, nrows):
row = sheets.cell_value(i, 0)
row1 = sheets.cell_value(i, 1)
row2 = sheets.cell_value(i, 2)
data.append([row, row1, row2])
min_max_scaler = preprocessing.MinMaxScaler(feature_range=(0,1))
A = np.array(data)
X=min_max_scaler.fit_transform(A)
num, dim = X.shape
clf = Kmeans(k=4)
y_pred = clf.predict(X)
print(y_pred)
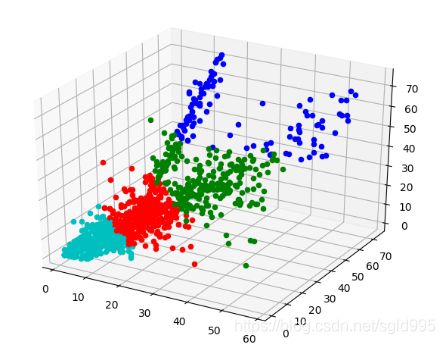
color = ['r', 'g', 'b', 'c', 'y', 'm', 'k']
ax = plt.subplot(111, projection='3d')
f = open('D:\结果.csv', 'w', encoding='utf-8', newline='')
csv_writer = csv.writer(f)
for p in range(0,num):
y=y_pred[p]
csv_writer.writerow([y])
ax.scatter(int(A[p, 0]), int(A[p, 1]), int(A[p, 2]), c=color[int(y)])
f.close()
plt.show()