Python爬虫自学系列(五)
文章目录
-
- 前言
- 数据集
- 知识储备
- 正主:Python大并发爬虫
-
- 1.0版本:原始版
- 2.0版本,加上时间处理、缓存
- 批量下载
-
- 图片批量下载
- 批量音频下载
- 视频下载
- 开多少线程/进程合适?
前言
emmmm,又到了单数篇。
不知道为什么,我居然会觉得,这个系列,单数篇必是精品,双数篇基本划水。。
好,废话不多说,本篇我们进入了大并发时代,看看我们的大并发爬虫。
数据集
什么是大并发?几千个量?几万个量?几十万个?好意思吗?
这波我找了近两万个数据集(好吧,小是小了点,本来有个一百万网址的数据集,但是大部分都是国外网址,爬不来)
太大了放不下,大家扫一下左边侧栏的那个二维码,回复“爬虫大并发”拿一下数据集,我准备了csv格式、Excel格式、还有最原始的数据集以及清洗代码,看你喜欢哪种了。
知识储备
大并发编程嘛,不是跟你开玩笑的啊。
Python都封装的很好了,但是你要是仅仅满足于Python的封装呢,那你跳过这一段吧。
在我这里,要给你知其然知其所以然。
东西太多了,接下来每篇都基本是万字长文,做好准备了吗?

都是我写的,看起来也不会无聊
进程·全家桶(这篇还被CSDN的公众号选中了)
Posix线程 它们那一大家子事儿,要觉得好你就收藏进被窝里慢慢看 (1)
Posix线程 它们那一大家子事儿,要觉得好你就收藏进被窝里慢慢看 (2)
【C++】勉强能看的线程池详解
Python爬虫自学系列(三)(缓存系列,redis的链接太多了,就用这篇吧)
消息队列:解耦、异步、削峰,现有MQ对比以及新手入门该如何选择MQ?
这些东西要是都用文字堆上来,那好像有点喧宾夺主了
正主:Python大并发爬虫
1.0版本:原始版
哪里有一蹴而就的好事儿啊,先来个最原始的版本吧。
import threadpool
import requests
def get_data():
op = open('CSDN_xml.txt')
s = op.read()
s = s.strip().split(' ')
datalist = s[::4]
return datalist
def outdata(url):
try:
print('succeed'+url)
requests.get(url)
except:
print('failed'+url)
def Thread_Pool(outdata,datalist = None,Thread_num = 5):
'''
线程池操作,创建线程池、规定线程池执行任务、将任务放入线程池中、收工
:param outdata: 函数指针,线程池执行的任务
:param datalist: 给前面的函数指针传入的参数列表
:param Thread_num: 初始化线程数
:return: 暂无
'''
pool = threadpool.ThreadPool(Thread_num) # 创建Thread_num个线程
tasks = threadpool.makeRequests(outdata, datalist) # 规定线程执行的任务
# outdata是函数名,datalist是一个参数列表,线程池会依次提取datalist中的参数引入到函数中来执行函数,所以参数列表的长度也就是线程池所要执行的任务数量。
[pool.putRequest(req) for req in tasks] # 将将要执行的任务放入线程池中
pool.wait() # 等待所有子线程执行完之后退出
datalist = get_data()
Thread_Pool(outdata,datalist=datalist)
当有 URL 可爬取时,上面代码中的循环会不断创建线程,直到达到线程池的最大值。在爬取过程中,如果当前队列中没有更多可以爬取的 URL时,线程会提前停止。
2.0版本,加上时间处理、缓存
这里的时间处理可不是说睡眠时间,还有计时器,因为后面我们要进行不同版本的测试嘛。
缓存嘛,虽然不会那啥,但是还是加一下吧。
改动的地方:
1、把那些零零碎碎的指令放一块儿了
def main():
start = time.perf_counter()
requests_cache.install_cache('bf_cache')
requests_cache.clear()
datalist = get_data()
Thread_Pool(outdata,datalist=datalist)
delta = time.perf_counter() - start
print('共用时:'+ str(delta))
2、函数指针中的修改:
def outdata(url):
try:
# print('succeed'+url)
res = requests.get(url)
if res.from_cache:
print('从缓存中获取:'+url)
except:
print('failed'+url)
# finally:
# time.sleep(2)
这要真两秒下去,那怕是没了。。
然后上面我调成1000了,两万太久了。。

我觉得是不是假了点啊,我等了这么久,跟我说就一分钟!!
开十个线程看看:Thread_Pool(outdata,datalist=datalist[:1000],Thread_num = 10)
看看效果是否对折了。

好,可以看到,花了43秒,大概折了四分之一。
那是不是说线程越多越好呢?是不是开足够多的线程,就可以在一秒内解决战斗呢?
兄弟,前面的链接看了就不会有这个想法了,开线程,是要耗费资源的,虽然没有进程耗费的那么大,而且管理线程也需要资源和时间的,何况这还是Python。
我刚刚测试了20个线程,花了40秒。多开无益。
先到2.0版本吧,如果日后发现有新的需求再加。
批量下载
图片批量下载
上边那个框架其实已经差不多了,只要改一下数据源,然后函数指针里面微调一下就好啦。
def outdata(data):
'''
这是一个处理数据的函数,即将被送入线程池
:param data: 这是一个字典,以图片名为键,图片链接为值
:return: 无
'''
item_list = data.items()
for item in item_list:
try:
res = requests.get(item[1])
if res.from_cache :
print('从缓存中获取:'+item[1])
else:
f = open(item[0],'wb+')
f.write(res.content)
except:
print('failed'+item[1])
# finally:
# time.sleep(2)
批量音频下载
其实吧,这里就改一下数据源就行了,其他都可以复用。
那这个数据源哪里找呢?
打开酷狗,或者其他音乐软件,然后找后缀为音乐的(mp3啥的)。

有看到不?
我不知道是网页版的酷狗没有VIP限制还是说因为我本身是有VIP的,我找了首APP上听要VIP才给听的歌,也可以直接听。
视频下载
视频也差不多改一下数据来源的函数就行,不过视频要注意那个网址弧没有后缀,所以可以用模块定位法(Xpath那一套)找到链接位置。
然后手动添加上后缀,就写成mp4就好啦。
开多少线程/进程合适?
看一下人家的测试数据吧:
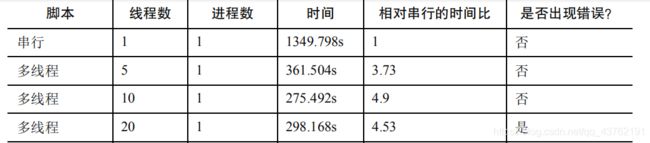
本来想讲讲多进程的,但是我本身不是很喜欢拿进程来做这种大量并发的。
进程,拿来做集群分布式就好了。