Bi-LSTM+CRF用于序列标注
本文将介绍Bi-LSTM+CRF的相关问题,第一部分介绍Bi-LSTM+CRF用于序列标注的经典论文,第二部分介绍其中的一些细节。
文章目录
- 一、Bidirectional LSTM-CRF Models for Sequence Tagging
-
- 1 Introduction
- 2 Models
-
- 2.1 LSTM Networks
- 2.2 Bidirectional LSTM Networks
- 2.3 CRF networks
- 2.4 LSTM-CRF networks
- 2.5 BI-LSTM-CRF networks
- 3 Training procedure
- 4 Experiments
-
- 4.1 Data
- 4.2 Features
-
- 4.2.1 Spelling features
- 4.2.2 Context features
- 4.2.3 Word embedding
- 4.2.4 Features connection tricks
- 4.3 Results
-
- 4.3.1 Comparison with Cov-CRF networks
- 4.3.2 Model robustness(鲁棒性)
- 4.3.3 Comparison with existing systems
- 5 Discussions
- 6 Conclusions
- 二、模型细节
一、Bidirectional LSTM-CRF Models for Sequence Tagging
《 Bidirectional LSTM-CRF Models for Sequence Tagging 》
这是第一篇将Bi-LSTM+CRF用于序列标注,是统计机器学习方法和深度学习方法的转折点,发表于2015年。
在本文中,我们提出了多种基于长短期记忆(LSTM)的序列标签模型。这些模型包括LSTM网络,双向LSTM(BI-LSTM)网络,具有条件随机场(CRF)层的LSTM(LSTM-CRF)和具有CRF层的双向LSTM(BI-LSTM-CRF)。我们的工作是第一个将双向LSTM CRF(称为BI-LSTM-CRF)模型应用于NLP基准序列标记数据集的工作。我们证明,
-
由于双向LSTM组件,BILSTM-CRF模型可以有效地使用过去和将来的输入功能。
-
由于具有CRF层,它还可以使用句子级别的标签信息。
-
BI-LSTMCRF模型可以在POS,分块和NER数据集上产生最新(或接近)准确性。另外,与以前的观察相比,它是健壮的并且对词嵌入的依赖性较小。
1 Introduction
序列标记包括部分词性标记(pos)、分块和命名实体识别(ner)一直是一个经典的NLP任务。几十年来它引起了研究的关注。标记器的输出可用于下行应用程序。例如,可以使用经过用户搜索查询培训的命名实体识别器来识别哪些范围的文本是产品,从而触发某些产品广告。另一个示例是,搜索引擎可以使用这些标记信息来查找相关的网页。
现有的序列标记模型大多是线性统计模型,包括隐马尔可夫模型(HMM)、最大熵马尔可夫模型(MEMMS)(McCallum等人,2000年)和条件随机场(CRF)(Lafferty等人,2001年)。基于卷积网络的模型(collobertal.,2011)被重新提出以解决序列标记问题。我们将这种模型称为conv-crf, 因为它由卷积网络和输出上的crf层组成(原文中使用了句级对数似然(ssl)这一术语)。conv-crf模型在序列标记任务上产生了有希望的结果。
在语言理解社区,最近提出了基于递归神经网络(Mesnil等人,2013;Yao等人,2014)和卷积网络(Xu和Sarikaya,2013)的模型。其他相关工作包括(Graves等人,2005年;Graves等人,2013年),提出了词性标注的双向递归神经网络。
在本文中,我们提出了多种基于神经网络的模型来进行序列标记任务。这些模型包括LSTM网络,双向LSTM网络(BI-LSTM),具有CRF层的LSTM网络(LSTM-CRF)和具有CRF层的双向LSTM网络(BILSTM-CRF)。我们的贡献可以总结如下。
-
1)我们系统地比较上述模型在NLP标记数据集上的性能;
-
2)我们的工作是第一个将双向LSTM
CRF(称为BI-LSTM-CRF)模型应用于NLP基准序列标记数据集的工作。由于具有双向LSTM组件,该模型可以同时使用过去和将来的输入功能。另外,由于具有CRF层,该模型可以使用句子级别的标签信息。我们的模型可以在POS,分块和NER数据集上产生最先进(或接近)的准确性; -
3)我们证明,BI-LSTM-CRF模型是健壮的,并且与以前的观察相比,它对单词嵌入的依赖性较小(Collobert等,2011)。它可以产生准确的标记性能,而无需借助词嵌入。
2 Models
在本节中,我们描述了本文使用的模型:LSTM,BI-LSTM,CRF,LSTM-CRF和BI-LSTM-CRF。
2.1 LSTM Networks
在命名实体标签上下文中,x代表输入要素,y代表标签。图1说明了一个命名的实体识别系统,其中每个单词都用other (O)或四种实体类型之一标记:Person (PER), Location (LOC), Organization (ORG), and Miscellaneous (MISC).
输入层表示T时的特征。它们可以是字特征、密集向量特征或稀疏特征的一种热编码。输入层的维数与特征尺寸相同。输出层表示时间t时标签上的概率分布。它与标签大小具有相同的维数。与前馈网络相比,RNN引入了前一隐藏状态与当前隐藏状态之间的联系(从而引入了重复的层权重参数)。这个循环层被设计用来存储历史信息。

2.2 Bidirectional LSTM Networks
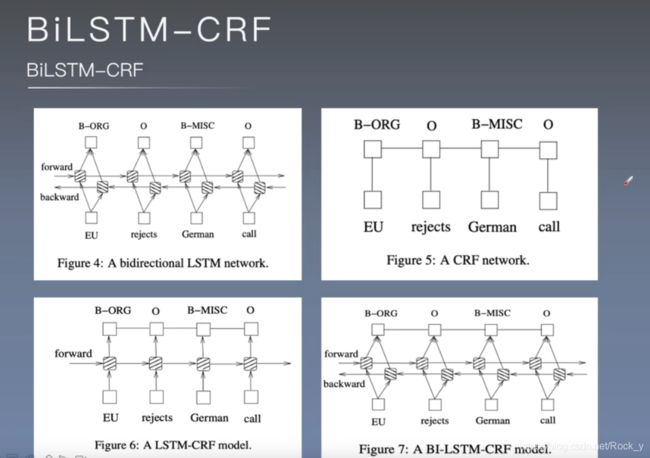
在序列标记任务中,我们可以在给定的时间内访问过去和将来的输入特征,因此我们可以使用双向LSTM网络(图4),如(Graves等人,2013年)中所提议的那样。这样做,我们可以有效地利用过去的特性(通过正向状态)和未来的特性(通过反向状态)在特定的时间范围内。我们使用时间反向传播(BPTT)来训练双向LSTM网络(Boden.,2002)。随着时间的推移,在展开的网络上的向前和向后传递以类似于常规网络向前和向后传递的方式进行,除了我们需要展开所有时间步长的隐藏状态。我们还需要在数据点的开头和结尾进行特殊处理。在我们的实现中,我们对整个句子进行向前和向后操作,我们只需要在每个句子结束时将隐藏状态重置为0。我们有批处理实现,可以同时处理多个句子。
2.3 CRF networks
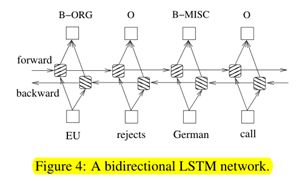
在预测当前标记时,有两种不同的方法可以利用相邻标记信息。第一种方法是每次预测标签的分布情况。然后利用类波束译码寻找最优的标签序列。最大参数分类器(Ratnaparkhi,1996)和最大熵马尔可夫模型(Memms)(McCallum等人,2000)的工作属于这一范畴。这些共有句集中在句子层面,而不是单个位置,因此导致了条件随机字段(CRF)模型(Laffertyetal.,2001)(图5)。注意,输入和输出是直接连接的,而不是使用内存单元/循环组件的LSTM和双向LSTM网络。
2.4 LSTM-CRF networks
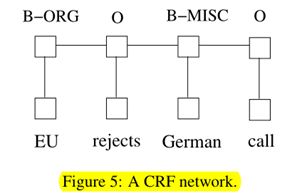
我们结合一个LSTM网络和一个CRF网络来形成一个LSTM-CRF模型,如图6所示。该网络可以通过lstm层有效地利用过去的输入特性,并通过crf层有效地利用句子级标记信息。crf层由连接连续输出层的线表示。CRF层有一个状态转换矩阵作为参数。有了这样一个层,我们就可以有效地利用过去和将来的标签来预测当前的标签,
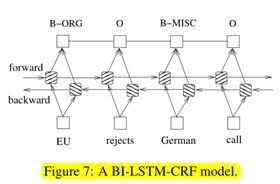
2.5 BI-LSTM-CRF networks
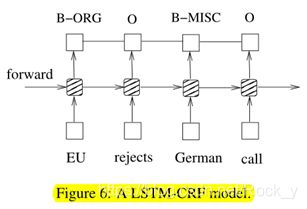
与LSTM-CRF网络相似,我们将双向LSTM网络和CRF网络结合起来,形成了BI-LSTM-CRF网络(图7)。除了LSTM-CRF模型中使用的过去输入功能和句子级别标签信息之外,BILSTM-CRF模型还可以使用将来的输入功能。正如我们将在实验中展示的那样,这些额外的特征可以提高标记的准确性。
3 Training procedure
4 Experiments
4.1 Data
在三个NLP标记任务上:Penn TreeBank(PTB)POS标记,CoNLL 2000分块和CoNLL 2003命名实体标记。
4.2 Features
我们为三个数据集提取相同类型的特征。这些功能可以分为拼写特征和上下文特征。结果,我们分别提取了POS,分块和NER数据集的401K,76K和341K特征。这些特征类似于从斯坦福大学NER工具提取的特征(Finkel等,2005; Wang和Manning,2013)。请注意,除了使用Senna嵌入(请参阅第4.2.3节)外,我们没有为POS和分块任务使用额外的数据。对于NER任务,我们使用拼写和上下文特征以及词嵌入和地名词典特征1来报告性能。
4.2.1 Spelling features
4.2.2 Context features
4.2.3 Word embedding
4.2.4 Features connection tricks
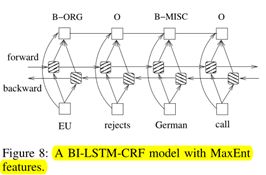
我们可以将拼写和上下文特征与单词特征一样对待。也就是说,网络的输入包括单词,拼写和上下文特征。但是,我们发现,从拼写和上下文特征到输出的直接连接会加快训练速度,并且它们会导致非常相似的标记准确性。图8示出了该网络,其中特征直接连接到网络的输出。我们将使用此连接报告所有标记的准确性。我们注意到,这种使用特征具有与(Mikolov等,2011)中所使用的最大熵特征相同的风味。不同之处在于,由于采用了特征哈希技术,可能会发生特征碰撞(Mikolov等,2011)。由于序列标记数据集中的输出标签少于语言模型的标签(通常为数十万),因此我们可以承受要素与输出之间的完全连接,从而避免潜在的要素冲突。
4.3 Results
我们为每个数据集训练LSTM,BI-LSTM,CRF,LSTM-CRF和BI-LSTM-CRF模型。我们有两种初始化单词嵌入的方法:Random和Senna。我们在第一个类别中随机初始化单词嵌入向量,并在第二个类别中使用Senna单词嵌入。POS任务是通过计算每个单词的准确性来评估的,而块和NER任务是通过计算块上的F1分数来评估的。
4.3.1 Comparison with Cov-CRF networks
4.3.2 Model robustness(鲁棒性)
4.3.3 Comparison with existing systems
5 Discussions
我们的工作接近(Collobert等人,2011年)的工作,因为他们都利用深层神经网络进行序列标记。他们的工作使用卷积神经网络,而我们的工作使用双向LSTM网络。我们的工作也接近(Hammerton,2003;Yao等人,2014)的工作,因为他们都使用LSTM网络进行标记。在(Hammerton,2003)的表现并不令人印象深刻。中的工作(Yao等人,2014)没有使用双向LSTM和CRF层,因此可能会影响标记的准确性。最后,我们的工作与(Wang和Manning,2013)的工作有关,后者得出结论,非线性体系结构在高维离散特征空间中没有任何好处。我们发现,与具有相同特征集的单一CRF模型相比,使用双向LSTM CRF模型,我们始终获得了更好的标记精度。
6 Conclusions
本文系统地比较了基于LSTM网络的序列标记。我们介绍了将一个bi-lstm-crf模型应用于NLP基准序列标记数据的第一项工作。我们的模型可以在POS、分块和NER数据集上产生最先进(或接近)的准确性。此外,我们的模型是稳健的,与中的观察相比,它对嵌入单词的依赖性较小(Collobert等人,2011年)。它可以在不使用嵌入词的情况下实现精确的标记精度。
二、模型细节