西瓜书~至臻笔记(二)——模型评估与选择(可直接享用)
文章目录
- 第二章 模型评估与选择
-
- 2.1 经验误差与过拟合
- 2.2 评估方法
-
- 2.2.1 留出法
-
- 分层采样
- 数据集中样本的顺序
- 数据集的大小比例
- 2.2.2 交叉验证法
-
- 数据集的样本顺序
- 留一法
- 2.2.3 自助法(可重复采样法)
- 2.2.4 调参与最终模型
-
- 范围调参
- 验证集引入
- 2.3 性能度量
-
-
- 均方误差
- 均方误差曲线
- 2.3.1 将错误率与精度
- 2.3.2 查准率、查全率与F1
-
- 查准率( P P P)
- 查全率( R R R)
- P-R曲线
- F1分数
- 宏查准、查全率以及宏 F 1 F1 F1
- 微查准、查全率以及微 F 1 F1 F1
- 2.3.3 ROC与AUC
- 2.3.4 代价敏感错误率与代价曲线
-
- 2.4 比较检验
-
- 2.4.1 假设检验
- 2.4.2 交叉验证t检验
- 2.4.3 McNemar检验
- 2.4.4 Friedman与Nemenyi后续检验
- 2.5 偏差与方差
- 第二章 阅读材料整理
- 第二章 概念单词
- 第二章 遗留问题
第二章 模型评估与选择
有问题可联系QQ:3020889729,微信:cjh3020889729
笔记中——模型等价于学习器,训练误差等价于经验误差!
2.1 经验误差与过拟合
错误率是指分类错误的样本数占样本总数的比例。
精度是指分类正确的样本数占样本总数的比例。
e g eg eg : i f if if 在 m m m 个样本中,存在 a a a 个样本分类错误,则:
-
错误率:
E = a m , E → m e a n s : e r r o r E=\frac{a}{m} \quad \quad, E \rightarrow means:error E=ma,E→means:error -
精度:
A = 1 − E = 1 − a m , A → m e a n s : a c c u r a c y A=1-E=1-\frac{a}{m} \quad \quad , A \rightarrow means:accuracy A=1−E=1−ma,A→means:accuracy
更一般地,我们可以将分类错误这种差异大致分为:训练误差、泛化误差。
- 前者是学习器在训练集上的预测输出真实输出(标记/标签)的差异
- 后者是用于全新的数据上是所表现的差异。【泛化误差往往更重要】
单词笔记:
- a c c u r a c y accuracy accuracy : 精度
- e r r o r error error : 误差/错误——错误率: e r r o r r a t e error \quad rate errorrate
- e m p i r i c a l e r r o r empirical \quad error empiricalerror : 经验误差
- g e n e r a l i z a t i o n e r r o r generalization \quad error generalizationerror : 泛化误差
无论是错误率、精度还是各种误差,都是为了服务于我们寻找一个“最满意”的学习器(模型)。因此,我们需要一个表现良好的学习器,但是怎么样的学习器才算好呢?训练误差小?训练集上表现很好?
N o No No,这还不够——我们通常期望的是——一个泛化误差小的学习器,即泛化能力强的学习器。因为这样的学习器能适应除训练集外的新预测环境,而不至于对于新样本一无所知,使学习器显得没有意义。
学习器的泛化误差大小怎么评估呢?常用的方法是将学习器应用于新样本上进行预测,再将预测结果与实际结果进行误差计算来评估的。这时我们就可能遇到两种截然不同的情况——过拟合、欠拟合。
- 过拟合:是指在训练集上的错误率比新样本上低、甚至低很多(也就是前者精度可能远高于后者)。
- 欠拟合:则是指在新样本上表现的结果已经比训练集上优异的,但是训练集上的误差还可以进一步优化。(即还可以继续让学习器从训练集中学习更多的信息/属性/特征)
在追求小泛化误差的学习器的路上,我们需要记住,过拟合是不可避免的,仅仅能通过有针对性的特定的办法来进行“缓解”,抑制过拟合程度。我们可以将过拟合不可避免问题简述为:
既 然 无 法 实 现 P = N P , 就 尽 可 能 使 得 P ≠ N P 的 可 能 性 降 低 P = N P , 表 示 预 测 与 真 实 情 况 一 致 , p ≠ N P , 表 示 预 测 与 真 实 情 况 不 一 致 。 既然无法实现P=NP,\quad 就尽可能使得P \neq NP的可能性降低 \\ P=NP,表示预测与真实情况一致, \\ p \neq NP,表示预测与真实情况不一致。 既然无法实现P=NP,就尽可能使得P=NP的可能性降低P=NP,表示预测与真实情况一致,p=NP,表示预测与真实情况不一致。
在现实生活中,往往很难找到最理想的模型(学习器),因为模型的学习能力、过拟合程度受到模型算法以及数据内涵所决定,因此我们只能多不同参数的模型进行选择——模型选择,是我们获得满意的学习器所不可或缺的。【通常,我们通过对不同参数的模型,或者不同模型的进行泛化误差的评定,选择泛化误差最小的模型作为相对最优模型。】
单词笔记:
- o v e r f i t t i n g overfitting overfitting : 过拟合
- u n d e r f i t t i n g underfitting underfitting : 欠拟合
- m o d e l s e l e c t i o n model \quad selection modelselection : 模型选择
PS:
- 欠拟合时的改进方法:增加训练轮次,或者增加模型复杂度等。
- 过拟合的改进方法:添加训练惩罚项等。
2.2 评估方法
从开始的泛化误差,我们可以知道,要想要比较好的模型,就需要我们对模型的泛化误差进行评估。此前,都是以新样本来说明,但是单个样本是无法用于有效的误差统计的,因此我们将所有用于测试的新样本组成一个数据集合,叫做“测试集”——并将测试集上的测试误差作为泛化误差的近似。
需要清楚一点的是,在数据划分时,通常存在一个假设——测试样本是真实的、独立同分布的。同时还需尽可能的使测试集中不包含训练集中的样本——即互斥。
我们清楚了模型评估需要一个测试集,此前模型训练又需要一个训练集,那么这样的数据应该从真是样本中如何划分呢?这就是下一步我们要学习的——对数据集进行有效合理的分割,即划分数据集。
即 : 从 D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) , 划 分 出 训 练 集 S 和 测 试 集 T . S = ( x 1 , y 1 ) , . . . , ( x i , y i ) , i = 1 , 2 , 3... M S T = ( x 1 , y 1 ) , . . . , ( x i , y i ) , i = 1 , 2 , 3... M T S ∩ T = ∅ , M S + M T = m 即:从D={(x_{1},y_{1}),(x_{2},y_{2}),...,(x_{m},y_{m})},划分出训练集S和测试集T. \\ S={(x_{1},y_{1}),...,(x_{i},y_{i})}\quad, i=1,2,3...M_{S} \\ T={(x_{1},y_{1}),...,(x_{i},y_{i})}\quad, i=1,2,3...M_{T} \\ S \cap T = \varnothing \quad, M_{S}+M_{T}=m\\ 即:从D=(x1,y1),(x2,y2),...,(xm,ym),划分出训练集S和测试集T.S=(x1,y1),...,(xi,yi),i=1,2,3...MST=(x1,y1),...,(xi,yi),i=1,2,3...MTS∩T=∅,MS+MT=m
2.2.1 留出法
留出法:是直接将数据集D划分为互斥的两个集合,分别为训练集 S S S和测试集 T T T。即: D = S ∪ T , S ∩ T = ∅ D=S\cup T \quad,S \cap T = \varnothing D=S∪T,S∩T=∅ .
- S S S :用于学习器学习
- T T T :用于评估学习器的泛化误差
e g eg eg : 以一个二分类问题来描述,假定 D D D含有样本 1000 1000 1000,利用留出法,留出 300 300 300个样本用于测试(即 T T T),因此余下的 S S S含有 700 700 700个样本。假设利用 S S S训练后,模型在 T T T上有 30 30 30个样本分类错误,那么其错误率为: ( 30 / 300 ) ∗ 100 (30/300)*100%=10% (30/300)∗100 , 即精度为: 1 − 10 1-10%=90% 1−10 .
留出法缺点:
- 会受数据影响,不可避免的引入一些因训练样本规模不同而导致的估计偏差。
分层采样
但通常,我们并不是直接将数据进行比例划分,还需要保持数据分布的一致性——即数据划分前后,给类别/类型的数据分布比例不变。如:原数据中苹果占 1 5 \frac{1}{5} 51 ,那么划分后的S和T中苹果也相应的占各自数据样本总数的 1 5 \frac{1}{5} 51 .【这种划分方法通常叫做——分层采样】
可能你会有一个疑惑,为什么需要这样划分呢?这是因为如果数据分布改变,会对模型训练和评估引入额外的偏差。【你可以留意一下,通常机器学习应用较好的数据通常是那些分布如同正态分布一样的数据】
举一个不按分层采样来进行划分的示例,来更直观的理解为什么需要使用分层采样保持数据分布来避免引入额外的误差。
e g eg eg : 假设 D D D中含有 400 400 400个正例, 600 600 600个反例,不按分层采样划分,留出 200 200 200个正例和 100 100 100个反例为测试集T,余下为训练集 S S S。当利用训练集 S S S训练的模型用于测试集T时,出现 60 60 60个分类错误, 分别是预测正例 20 20 20项错误,反例 40 40 40项错误。那么此时在 T T T下的模型各分类的错误率为:
E 正 = 20 / 200 ∗ 100 % = 10 % E 反 = 40 / 100 ∗ 100 % = 40 % E_{正} = 20/200*100\%=10\% \\ E_{反} = 40/100*100\%=40\% E正=20/200∗100%=10%E反=40/100∗100%=40%
可以看出模型对假例预测的效果较差。此时,让我们利用分层采样的划分方法,对D进行按类别比例划分得到 S S S和 T T T, T T T为 120 120 120个正例和 180 180 180个反例, 于是各分类错误率如下(假设预测结果保持不变):
E 正 = 20 / 120 ∗ 100 % = 1 / 6 ∗ 100 % ≈ 16.7 % E 反 = 40 / 180 ∗ 100 % = 2 / 9 ∗ 100 % ≈ 22.2 % E_{正} = 20/120*100\%=1/6*100\% \approx{16.7\%} \\ E_{反} = 40/180*100\%=2/9*100\% \approx{22.2\%} E正=20/120∗100%=1/6∗100%≈16.7%E反=40/180∗100%=2/9∗100%≈22.2%
可以看出前后分类的评估情况大不相同,后者更稳定,误差不会偏向某一方,更倾向于实际的数据。前者之所以会在学习器上出现错误率差距如此大,是一方面是因为样本类别比例差异大,以及与原始数据的分布不相同导致的,从而使评估出现的偏差。【忽略S样本的一定影响,这里主要是为了表述分层抽样的必要性!】
数据集中样本的顺序
使用留出法时,除了要注意分层抽样以外,还要注意训练数据的顺序——要了解,单次使用留出法估计的结果往往不厚稳定可靠——需要将其划分的数据S和T,多次随机打乱后用于训练和评估。此时,每一次不同的随机顺序数据集,都会是模型产生不同的训练/评估结果,从而在对N次随机的结果取平均就可以得到较稳定的结果了。
数据集的大小比例
利用留出法时,还需要注意训练集S与测试集T之间的样本数目关系。如果训练集远大于测试集,此时模型的结果可能就会出现较大的偏差;因此,通常是取 [ 2 3 , 4 5 ] [\frac{2}{3} \quad , \frac{4}{5}] [32,54] 得样本作为训练集,剩余样本作测试集。
PS:
- 划分数据集的比例,也有例外。当数据集很大时,比如总样本为 100 万 100万 100万个,那么我们就不必留 [ 1 5 , 1 3 ] [\frac{1}{5}\quad, \frac{1}{3}] [51,31] 的样本作为测试集了,因为通常哪怕是 1 % − 2 % 1\% - 2\% 1%−2% 的样本作为测试集都已经足够我们用于模型的筛选了。
单词笔记:
- t e s t i n g e r r o r testing \quad error testingerror : 测试误差
- h o l d − o u t hold-out hold−out : “留出法”
- s t r a t i f i e d s a m p l i n g stratified \quad sampling stratifiedsampling : 分层采样
2.2.2 交叉验证法
交叉验证法:
- 先将数据集 D D D划分成 k k k个大小相似(尽量相同)且互斥的子集,即 D = D 1 ∪ D 2 . . . ∪ D k D=D_{1} \cup D_{2} ... \cup D_{k} D=D1∪D2...∪Dk , D i ∩ D j = ∅ D_{i} \cap D_{j}=\varnothing Di∩Dj=∅ .
- 每个子集都是通过分层采样得到
- 每次训练用 k − 1 k-1 k−1 个子集的并集作为训练集,余下一个子集作为测试集
- 这样就会得到 k k k组不同的训练/测试集合, k k k次不同的测试结果
- 最后取k次测试结果平均值作为模型结果
交叉验证法的一个优势,可以通过调节k的大小来调整最终评估结果的一个稳定性和保真性——但不是越大越好,因为k越大所消耗的时间越多,并且对模型最终评估结果可能并没有太多改善。不过,也正是因为 k k k值可调,交叉验证法也被称为“K折交叉验证”。【 k k k常用的值为 5 , 10 5,10 5,10等,即五折交叉验证、十折交叉验证】
交叉验证法缺点:
- 会受数据影响,不可避免的引入一些因训练样本规模不同而导致的估计偏差。
数据集的样本顺序
类似于留出法,交叉验证法也会因为训练样本的顺序不同而导致模型训练/评估结果不同。因此,类似的,进行 p p p次不同的划分顺序随机(子集中样本顺序随机)的k值不变的交叉验证,最后取 p p p次结果的平均值作为最终结果——此时的交叉验证叫做:p次k折交叉验证。
[ S , T ] i → λ i , λ i 为 第 i 次 验 证 的 评 估 结 果 λ = 1 p ∑ j = 0 p λ j , λ 为 p 次 验 证 后 的 平 均 评 估 结 果 [S\quad,T]_{i} \rightarrow \lambda_{i} \quad, \lambda_{i}为第i次验证的评估结果 \\ \lambda = \frac{1}{p}\sum_{j=0}^{p}\lambda_{j} \quad, \lambda为p次验证后的平均评估结果 [S,T]i→λi,λi为第i次验证的评估结果λ=p1j=0∑pλj,λ为p次验证后的平均评估结果
留一法
交叉验证中,有一种特殊情况,即数据集 D D D中仅含 m m m个样本,此时令 k = m k=m k=m ,使得交叉验证中的k个子集均只含有单个样本 ——这就叫做留一法。
此时的验证数据集不再受到随机样本划分方式的影响,因为 k ( m ) k(m) k(m)个子集中仅含有一个样本,不存在其它的排序方式。
留一法特点:
- 训练集仅仅比初始数据集少一个样本,也就是说训练集几乎代表了整个数据集的潜在分布(或者说几乎所有的数据特征)。
- 从而留一法的评估结果通常与使用数据集D进行训练的模型评估结果相似——因此,即T集下的评估结果与S集下的训练结果相似。【留一法时,通常只需要考虑训练结果即可】
- 留一法的评估结果往往更为精确【评估结果不是一定优于其它的数据划分方法】
留一法的缺点:
- 数据集较大时,因为将每一个样本当一个子集来划分,就会造成很大的计算(时间)开销。
单词笔记:
- f i d e l i t y fidelity fidelity : 保真性
- k − f o l d c r o s s v a l i d a t i o n k-fold \quad cross \quad validation k−foldcrossvalidation : ”K折交叉验证“
- L e a v e − O n e − O u t Leave-One-Out Leave−One−Out : ”留一法“
2.2.3 自助法(可重复采样法)
自助法:
- 每次随机从数据集 D D D中挑选一个样本,将其拷贝放入 D ′ D' D′ 中
- 然后将该样本放回数据集 D D D,使得下一次采样仍然可能抽取到该样本
- 重复以上步骤 m m m次,就得到了包含 m m m个样本的训练集 D ‘ D‘ D‘ ——即自助采样的结果
自助法特点:
-
D中的一部分样本可能多次出现 D ′ D' D′ 中,而有的样本不出现在 D ′ D' D′ 中。
-
减少训练样本规模不同造成的估计偏差影响
自助法中样本是否被抽样,可以用一个简单的估计来计算——设单个样本被采样的概率为 1 m \frac{1}{m} m1 ,则不被采样的概率为 1 − 1 m 1-\frac{1}{m} 1−m1 ,即一个 0 , 1 分 布 0,1分布 0,1分布。因此,(任意)单个样本m次采样的都没采样到的概率为 ( 1 − 1 m ) m (1-\frac{1}{m})^{m} (1−m1)m ——即初始数据集 D D D在m次采样中单个样本不被采样的概率。
因此,将公式中 m m m扩展到 ∞ \infty ∞ 就得到初始数据集D中单样本不被采样的概率:
由: lim x → 0 ( 1 + x ) 1 x = e \lim_{x\rightarrow{0}}{(1+x)^{\frac{1}{x}}=e} limx→0(1+x)x1=e 有:
令 x = − 1 m x=-\frac{1}{m} x=−m1 , 原式变为:
x → 0 , 即 m → ∞ : l i m m → ∞ ( 1 − 1 m ) − m = e x\rightarrow{0}\quad, 即m\rightarrow{\infty}:\quad lim_{m\rightarrow{\infty}}{(1-\frac{1}{m})^{-m}}=e \\ x→0,即m→∞:limm→∞(1−m1)−m=e
此时,变换式略微变换一下:
lim m → ∞ ( 1 − 1 m ) − m = e → lim m → ∞ ( ( 1 − 1 m ) m ) − 1 = e \lim_{m\rightarrow{\infty}}{(1-\frac{1}{m})^{-m}}=e \quad \rightarrow \quad \lim_{m\rightarrow{\infty}}{((1-\frac{1}{m})^{m})^{-1}}=e \\ m→∞lim(1−m1)−m=e→m→∞lim((1−m1)m)−1=e
此时再对其求一个倒数,就能得到 m m m趋于 ∞ \infty ∞ 的未采样概率:
lim m → ∞ ( ( 1 − 1 m ) m ) − 1 = lim m → ∞ 1 ( 1 − 1 m ) m = e ↓ lim m → ∞ ( 1 − 1 m ) m = 1 e ≈ 0.368 \lim_{m\rightarrow{\infty}}{((1-\frac{1}{m})^{m})^{-1}}=\lim_{m\rightarrow{\infty}}\frac{1}{(1-\frac{1}{m})^{m}}=e \\ \downarrow \\ \lim_{m\rightarrow{\infty}}{(1-\frac{1}{m})^{m}} = \frac{1}{e} \approx 0.368\\ m→∞lim((1−m1)m)−1=m→∞lim(1−m1)m1=e↓m→∞lim(1−m1)m=e1≈0.368
因此,我们就得出了,自助采样时,初始数据集 D D D中约有 36.8 % 36.8\% 36.8% 的样本不被采样到——即不会出现在采样数据集 D ’ D’ D’中。所以,通过自助法,我们可以将 D ′ D' D′ 作为训练集,而 D / D ′ D/D' D/D′ 作为测试集。【 D / D ′ , 指 D 中 除 D ‘ 以 外 的 样 本 D/D', 指D中除D‘以外的样本 D/D′,指D中除D‘以外的样本】
因为初始数据集 D D D中约有 36.8 % 36.8\% 36.8% 的样本未被采样过,不曾出现在训练集中,可以直接将这部分数据样本用于评估——这样的评估结果,称为“包外估计”。
自助法优点:
- 数据集较小时、难以有效划分训练/测试集时,自助法因 1 3 \frac{1}{3} 31 的特性,而可以很好的有效划分数据(总能有 1 3 \frac{1}{3} 31 的不曾出现在训练集中的数据可以作为测试集 )。
- 自助法因为随机性,可以产生多个不同的不交叉的训练集和测试集。
自助法缺点:
- 虽然对小数据集也能很好的划分,但是却会改变初始数据集 D D D的分布,从而引入估计偏差
- 在数据集较大时,通常采用留出法或者交叉验证更为方便或有效。
单词笔记:
- b o o t s t r a p p i n g bootstrapping bootstrapping : ”自助法“
- b o o t s t r a p s a m p l i n g bootstrap \quad sampling bootstrapsampling : “自助采样法”
- o u t − o f − b a g e s t i m a t e out-of-bag \quad estimate out−of−bagestimate : 包外估计
2.2.4 调参与最终模型
大多数学习算法的结果与其参数设定息息相关,不同的参数配置,学习到的潜在分布/特征就会有不同的差异,其最终的模型往往就有显著的差别。因此,再进行模型评估和选择前,除了选择学习算法(模型算法)外,我们还需要对算法参数进行设定——即参数调节,简称调参。
范围调参
为参数选择一定的范围,和变化步长。 e g eg eg: 设定参数的调节范围 [ 0 , 0.2 ] [0,0.2] [0,0.2] ,并以 0.05 0.05 0.05 作为步长,则训练该参数就需要训练 0.2 / 0.05 + 1 = 4 + 1 = 5 0.2/0.05 + 1= 4 + 1 =5 0.2/0.05+1=4+1=5 次, 然后从这 5 5 5个候选值中选择最满意的一个参数值。【虽然这样产生的参数结果不一定最优,但是确是一个计算开销和性能估计的折中方法】
PS:
- 参数调得好坏往往决定着最终模型的性能
验证集引入
为了加以区分各种训练集的作用,现在将之前用于评估的数据集从测试集 T T T重新定义为验证集V,将验证集上表现的模型性能来进行模型选择和调参。
基本数据集的划分:
- 训练集:用于模型训练的数据集
- 验证集:用于模型评估的数据集
- 测试集:用于模拟模型实际测试的数据集
单词笔记:
- p a r a m e t e r parameter parameter : 参数
- p a r a m e t e r t u n i n g parameter \quad tuning parametertuning : 调参
2.3 性能度量
所谓性能度量,就是衡量模型泛化能力的标准。
此前,我们仅仅是将错误率直接用于计算评估误差,这通常是不足够的。一般地,我们对不同的任务,会使用不同的性能度量方法,从而导致不同的训练结果。【这也意味着,模型”好坏“是相对的】
模型“好坏”的相关因素:
- 算法
- 数据
- 任务需求
这里列举一项在预测中使用较多的性能度量方法,均方误差——通常用于回归预测这样的连续预测任务。
均方误差
均方误差定义如下:
E ( f ; D ) = 1 m ∑ i = 1 m ( f ( x i ) − y i ) 2 E(f;D)=\frac{1}{m}\sum_{i=1}^{m}(f(x_{i})-y_{i})^{2}\\ E(f;D)=m1i=1∑m(f(xi)−yi)2
其中, m m m 是预测样本总数, f ( x i ) f(x_{i}) f(xi) 是预测结果, y i y_{i} yi 是真实标记/标签.
该性能度量就是通过计算模型预测输出与真实标签之间的距离,然后利用这个“误差距离”对进行模型修正。
对于连续的数据分布 D D D ,可以将上式转换为关于概率密度函数 p ( ⋅ ) p(·) p(⋅) 的形式:
E ( f ; D ) = ∫ x ∼ D ( f ( x ) − y ) 2 p ( x ) d x E(f;D)=\int_{x \sim D}{(f(x)-y)^{2}p(x)}dx E(f;D)=∫x∼D(f(x)−y)2p(x)dx
即:将 ∑ \sum ∑ 换 ∫ \int ∫ ,同时将原来的等概率 1 m \frac{1}{m} m1 换成关于x分布的概率密度函数 p ( x ) p(x) p(x) 。
为了理解清晰,这里将以 x x x 轴为 ( f ( x i ) − y i ) (f(x_{i})-y_{i}) (f(xi)−yi) 的误差值, y y y 轴为 E ( f ; D ) E(f;D) E(f;D) 。
均方误差曲线
可以看出, M S E MSE MSE 均方误差对于离群点,也就是损失较大时,计算的误差值越大,且梯度也越大,使得数据向离群点方向靠近的趋势更明显,这一点在后边学习梯度下降法之后会更加清晰。【因此,数据中包含大量离群点时,可能MSE并不适合作为一个好的性能度量】
单词笔记:
- p e r f o r m a n c e m e a s u r e performance \quad measure performancemeasure : 性能度量
- m e a n s q u a r e d e r r o r mean \quad squared \quad error meansquarederror : 均方误差
【接下来介绍的度量方法,均与分类任务有关】
2.3.1 将错误率与精度
将前面提到错误率与精度, 进行一定形式的转换,引入一个指示函数来表征预测是否正确。
I I ( ⋅ ) , 在 ⋅ 为 真 时 值 为 1 , ⋅ 为 假 时 值 为 0 II(·),在·为真时值为1,·为假时值为0 II(⋅),在⋅为真时值为1,⋅为假时值为0
所以错误率表示为:
E ( f ; D ) = 1 m ∑ i = 1 m I I ( f ( x i ) ≠ y i ) E(f;D)=\frac{1}{m}\sum_{i=1}^{m}II(f(x_{i})\neq{y_{i}}) E(f;D)=m1i=1∑mII(f(xi)=yi)
精度为:
a c c ( f ; D ) = 1 m ∑ i = 1 m I I ( f ( x i ) = y i ) = 1 − E ( f ; D ) acc(f;D)=\frac{1}{m}\sum_{i=1}^{m}II(f(x_{i}) = y_{i})=1 - E(f;D) acc(f;D)=m1i=1∑mII(f(xi)=yi)=1−E(f;D)
同样的,对于连续数据分布 D D D, 可以表示为:
E ( f ; D ) = ∫ x ∼ D I I ( f ( x ) ≠ y ) p ( x ) d x a c c ( f ; D ) = ∫ x ∼ D I I ( f ( x ) = y ) p ( x ) d x = 1 − E ( f ; D ) E(f;D)=\int_{x \sim D}II(f(x)\neq{y})p(x)dx \\ acc(f;D)=\int_{x \sim D}II(f(x)={y})p(x)dx=1-E(f;D) \\ E(f;D)=∫x∼DII(f(x)=y)p(x)dxacc(f;D)=∫x∼DII(f(x)=y)p(x)dx=1−E(f;D)
2.3.2 查准率、查全率与F1
对于二分类问题,类别组合划分:
- 真正例( T P TP TP):预测为正例,标签为正例
- 假正例( F P FP FP):预测为正例,标签为反例
- 真反例( T N TN TN):预测为反例,标签为反例
- 假反例( F N FN FN):预测为反例,标签为正例
名称规律为——:
- 真假( T / F T/F T/F):对应标签与结果是否一致,一致为真( T r u e True True)
- 正反( P / N P/N P/N):对应预测正反例( P o s i t i v e , N e g a t i v e Positive, Negative Positive,Negative)
- 标签结果在前,预测结果在后进行表示
分类混淆矩阵:(左侧对应真实情况,上侧对应预测情况)
| 正例 | 反例 | |
|---|---|---|
| 正例 | y y y 与 f ( x ) f(x) f(x) 一致为真,预测结果为正:真正例 | y y y 与 f ( x ) f(x) f(x) 不一致为假,预测结果为反:假反例 |
| 反例 | y y y 与 f ( x ) f(x) f(x) 不一致为假,预测结果为正:假正例 | y y y 与 f ( x ) f(x) f(x) 一致为真,预测结果为假:真反例 |
所以,判断分类组合,先看后项——是什么例,然后看前项,真还是假即可判断实际分类情况了。
e g eg eg :
- 真反例:反例意味着:预测为反例,真意味着标签与预测一致,所以可以判断标签和预测都是反例。
- 假反例:反例意味着:预测为反例,真意味着标签与预测不一致,所以可以判断标签是正例。
单词笔记:
- t r u e p o s i t i v e true \quad positive truepositive : 真正例
- f a l s e p o s i t i v e false \quad positive falsepositive : 假正例
- t r u e n e g a t i v e true \quad negative truenegative : 真负例
- f a l s e n e g a t i v e false \quad negative falsenegative : 假负例
- c o n f u s i o n m a t r i x confusion \quad matrix confusionmatrix : 混淆矩阵
所以,分清楚组合情况后,我们就可以开始讨论查准率、查全率以及 F 1 F1 F1分数了。
查准率( P P P)
查准率,也叫准确率。
定义为:
P = T P T P + F P T P : 真 正 例 F P : 假 正 例 P=\frac{TP}{TP+FP} \\ TP:真正例 \\ FP:假正例 \\ P=TP+FPTPTP:真正例FP:假正例
即, 模型预测结果的真正例数占真正例与假正例之和的比例。
也就是模型预测结果中,预测为正例时,正确分类正例所占的比例——真正例,即标签与预测一致,分类正确;而FP则标签与预测不一致,预测为正例,分类错误。【即预测为正时的分类准确率】
因此,可以发现, P P P 越大,那么预测正例正确的可能性越大。【主要对预测结果而言】
查全率( R R R)
查全率,也叫召回率。
定义为:
R = T P T P + F N T P : 真 正 例 F N : 假 反 例 R=\frac{TP}{TP+FN} \\ TP:真正例 \\ FN:假反例 \\ R=TP+FNTPTP:真正例FN:假反例
即,模型预测结果的真正例数占真正例与假反例之和的比例。
也就是模型预测结果中,标签为正例时,预测与标签一致所占的比例——假反例,即预测为反例,标签为正例。【即标签为正时的分类准确率】
因此,可以发现, R R R 越大,那么正例正确的可能性越大。【主要对标签而言】
查准率与查全率是一对矛盾量——往往一者高,另一者就低。不过也有例外,比如在一些简单的分类任务(西瓜的好坏)中,可能两者都比较高。
单词笔记:
- p r e c i s i o n precision precision : ”查准率“
- r e c a l l recall recall : ”查全率“
P-R曲线
因此,我们将模型预测“最可能”是正例的样本排在前面,将“最不可能”是正例的样本排在后面,然后按此顺序依次计算出当前的 P 、 R P、R P、R——然后将所有计算的P、R值组成有序实数对 ( P , R ) (P,R) (P,R) ,然后绘制出图形,就得到了我们的“ P − R 曲 线 P-R曲线 P−R曲线” 。
如图,将 R R R 查全率作为横坐标, P P P 查准率作为纵坐标:
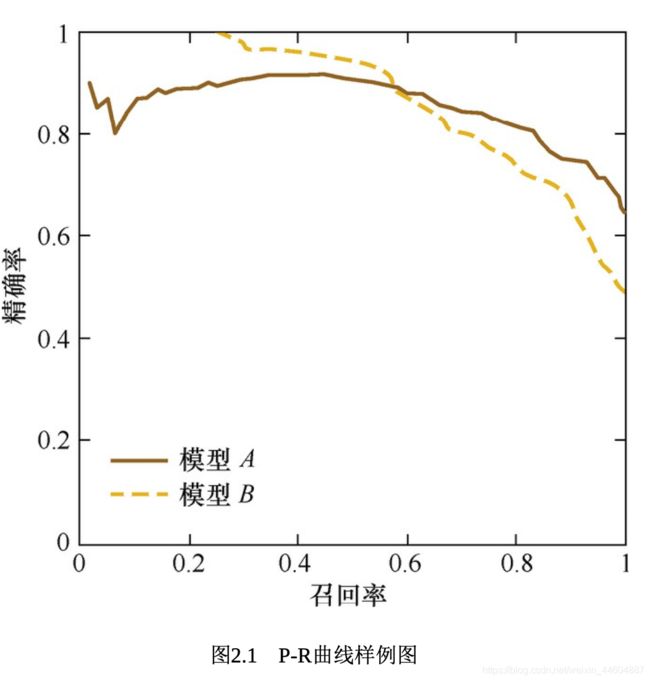
图中的两条 P − R 曲 线 P-R曲线 P−R曲线 ,没有出现明显的包含关系,因此无法做出直接的判断,需要进一步的分析。
F1分数
分析" P − R 曲 线 P-R曲线 P−R曲线" 对于模型选择的帮助主要从这些方面入手:
-
如果一个模型的的 P − R 曲 线 P-R曲线 P−R曲线完全包住另一个模型的 P − R 曲 线 P-R曲线 P−R曲线,则可以说前者性能更优异。
-
如果模型有交叉,则需要具体问题具体分析:
-
比较P-R曲线下面积大小,但是不好估算
-
平衡点( B E P BEP BEP):即查准率等于查全率时的取值,越大性能越好
-
F 1 F1 F1度量: F 1 F1 F1分数越大越好
F 1 = 2 × P × R P + R , P = T P T P + F P , R = T P T P + F N ↓ F 1 = 2 × T P T P + F P × T P T P + F N T P T P + F P + T P T P + F N = 2 × T P 样 例 总 数 + T P − T N 样 例 总 数 : T P + T N + F P + F N F1=\frac{2 \times P \times R }{P+R}, \quad P=\frac{TP}{TP+FP}, \quad R=\frac{TP}{TP+FN} \\ \downarrow \\ F1=\frac{2 \times \frac{TP}{TP+FP} \times \frac{TP}{TP+FN}}{\frac{TP}{TP+FP} + \frac{TP}{TP+FN}} = \frac{2 \times TP}{样例总数+TP-TN} \\ 样例总数: TP+TN+FP+FN \\ F1=P+R2×P×R,P=TP+FPTP,R=TP+FNTP↓F1=TP+FPTP+TP+FNTP2×TP+FPTP×TP+FNTP=样例总数+TP−TN2×TP样例总数:TP+TN+FP+FN
-
其中 F 1 F1 F1度量是一个常用的评估量,其形式本身来自于, P P P 与 R R R 的调和平均: 1 F 1 = 1 2 ( 1 P + 1 R ) \frac{1}{F_{1}}=\frac{1}{2}(\frac{1}{P} + \frac{1}{R}) F11=21(P1+R1) 。
虽然现在的 F 1 F1 F1表现已经显得比较优美了,但是我们还可以通过对调和平均进行一个加权操作,使得它满足实际训练过程中对查准率与查全率的要求不同的情况。【 F 1 F1 F1 中 P P P 与 R R R 重要性相同!】
加权调和平均定义为:
1 F β = 1 1 + β 2 ( 1 P + β 2 R ) \frac{1}{F_{\beta}} = \frac{1}{1+\beta^{2}}(\frac{1}{P} + \frac{\beta^{2}}{R}) \\ Fβ1=1+β21(P1+Rβ2)
因此,更一般的 F 1 F1 F1度量标准, F β F_{\beta} Fβ 定义为:
F β = ( 1 + β 2 ) × P × R ( β 2 × P ) + R F_{\beta}=\frac{(1+\beta^{2}) \times P \times R }{(\beta^{2} \times P)+R} \\ Fβ=(β2×P)+R(1+β2)×P×R
(通常要求 β > 0 \beta > 0 β>0 ,但是为了更一般的形式,且原式中使用 β 2 \beta^{2} β2参与计算,所以,以 ∣ β ∣ |\beta| ∣β∣表示 β > 0 \beta > 0 β>0)
【 ∣ β ∣ | \beta| ∣β∣ 表征了查全率对查准率的相对重要性】
根据 ∣ β ∣ |\beta| ∣β∣ 的不同:
- ∣ β ∣ < 1 |\beta|<1 ∣β∣<1, 查准率有更大的影响
- ∣ β ∣ = 1 |\beta|=1 ∣β∣=1, 即退化为 F 1 F1 F1 ,查全率与查准率一样重要
- ∣ β ∣ > 1 |\beta|>1 ∣β∣>1, 查全率有更大影响
在执行多分类任务等时,我们拥有 n n n 个二分类的混淆矩阵,此时我们就需要从 n n n 个二分类混淆矩阵中综合考察 P P P 、 R R R 和 F 1 F1 F1。
宏查准、查全率以及宏 F 1 F1 F1
一种综合考察的方法:
-
先计算各混淆矩阵的查准率与查全率,并记为 ( P 1 , R 1 ) , ( P 2 , R 2 ) , . . . , ( P n , R n ) (P_{1},R_{1}), (P_{2},R_{2}),...,(P_{n},R_{n}) (P1,R1),(P2,R2),...,(Pn,Rn)
-
然后取其所有查准率与查全率的平均值
-
最有利用查准率与查全率的平均值计算F1
-
此时的平均查准率、平均查全率和F1,分别表示为:
宏 查 准 率 : m a c r o − P = 1 n ∑ i = 1 n P i 宏 查 全 率 : m a c r o − R = 1 n ∑ i = 1 n R i 宏 F 1 度 量 : m a c r o − F 1 = 2 × m a c r o − P × m a c r o − R m a c r o − P + m a c r o − R 宏查准率:macro-P=\frac{1}{n}\sum_{i=1}^{n}P_{i} \\ 宏查全率:macro-R=\frac{1}{n}\sum_{i=1}^{n}R_{i} \\ 宏F1度量:macro-F1=\frac{2 \times macro-P \times macro-R}{macro-P+macro-R} \\ 宏查准率:macro−P=n1i=1∑nPi宏查全率:macro−R=n1i=1∑nRi宏F1度量:macro−F1=macro−P+macro−R2×macro−P×macro−R
微查准、查全率以及微 F 1 F1 F1
另一种综合度量多个二分类混淆举证的方法:
-
直接计算 T P 、 F P 、 T N 、 F N TP、FP、TN、FN TP、FP、TN、FN 的平均值: T P ‾ , F P ‾ , T N ‾ , F N ‾ \overline{TP}, \overline{FP}, \overline{TN}, \overline{FN} TP,FP,TN,FN
-
利用平均分类情况计算查准率、查全率和F1
-
此时的查准率、查全率和F1的表示为:
微 查 准 率 : m i c r o − P = T P ‾ T P ‾ + F P ‾ 微 查 全 率 : m i c r o − R = T P ‾ T P ‾ + F N ‾ 微 F 1 度 量 : m i c r o − F 1 = 2 × m i c r o − P × m i c r o − R m i c r o − P + m i c r o − R 微查准率:micro-P= \frac{\overline{TP}}{\overline{TP} + \overline{FP}}\\ 微查全率:micro-R= \frac{\overline{TP}}{\overline{TP} + \overline{FN}}\\ 微F1度量:micro-F1=\frac{2 \times micro-P \times micro-R}{micro-P+micro-R} \\ 微查准率:micro−P=TP+FPTP微查全率:micro−R=TP+FNTP微F1度量:micro−F1=micro−P+micro−R2×micro−P×micro−R
单词笔记:
- m a c r o − P macro-P macro−P , m a c r o − R macro-R macro−R , m a c r o − F 1 macro-F1 macro−F1 : ”宏查准率“,”宏查全率“,”宏F1“
- m i c r o − P micro-P micro−P , m i c r o − R micro-R micro−R , m i c r o − F 1 micro-F1 micro−F1 : ”微查准率“,”微查全率“,”微F1“
- B r e a k − E v e n P o i n t Break-Even \quad Point Break−EvenPoint : 平衡点
2.3.3 ROC与AUC
在实际模型中,大多数模型对预测样本的输出都是一个实数值或者概率值,然后对模型的输出值进行一个分类阈值的比较:
- 输出值 > 分类阈值,则为正例
- 输出值 < 分类阈值,则为反例
比如,在神经网络分类中,借助 s i g m o i d sigmoid sigmoid 和 s o f t m a x softmax softmax 函数的特性进行分类预测输出时,总是一个在 [ 0 , 1.0 ] [0,1.0] [0,1.0] 之间的一个实值,然后将这个值与设定的分类阈值进行比较;假设分类阈值为 0.5 0.5 0.5 ,则当 f ( x ) > 0.5 f(x)>0.5 f(x)>0.5 时,判断该预测输出为正例,反之为反例。
通常,这个实值的好坏,直接决定学习器的泛化能力。因此,我们可以按照输出的实值大小进行排序,大的在前,小的在后,此时相当于将预测“最可能”为正例的排在前,预测“最不可能”为正例的排在后。此时,分类过程就相当于是在这个排序中选择一个**“截断点”**将所有样本分为两部分,截断点前的样本部分判为正例,截断点后的样本部分判为反例。
在前面有提到过,样本的排序会对模型的好坏起到影响。因此,提出利用 R O C 曲 线 ROC曲线 ROC曲线描述模型“一般情况下”泛化性能的好坏程度。
ROC:即受试者工作特征曲线。
在绘制 R O C 曲 线 ROC曲线 ROC曲线前,需要满足以下条件:
- 首先对学习器的预测结果进行排序
- 然后把排序好的结果按则正例进行评估(即标签均为正例,然后比较预测是否也为正例)
- 注意:此时的预测结果仅仅是实值,而不是分类结果。
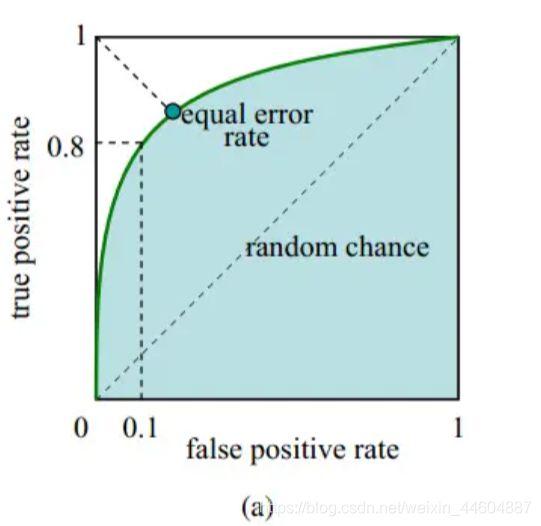
R O C 曲 线 ROC曲线 ROC曲线的绘制:
-
计算真正例率和假正例率:
T P R = T P T P + F N , 即 : 标 签 为 正 例 时 的 正 确 分 类 比 例 F P R = F P F P + T N , 即 : 标 签 为 反 例 时 的 错 误 分 类 比 例 TPR=\frac{TP}{TP+FN} \quad, 即:标签为正例时的正确分类比例 \\ FPR=\frac{FP}{FP+TN} \quad, 即:标签为反例时的错误分类比例 \\ TPR=TP+FNTP,即:标签为正例时的正确分类比例FPR=FP+TNFP,即:标签为反例时的错误分类比例 -
然后将 T P R TPR TPR作为纵轴, F P R FPR FPR作为横轴,如图:
-
-
R O C 曲 线 ROC曲线 ROC曲线分析:
- 图中对角线对应着“随机猜测”模型,也就是正例和反例的概率是相等的。
- 在点 ( 0 , 1 ) (0,1) (0,1)处, T P R = 1 TPR=1 TPR=1, F P R = 0 FPR=0 FPR=0,即对应将所有正例都排在反例前面的“理想模型”——因为截断点 ( F P R , T P R ) (FPR,TPR) (FPR,TPR)无论取 R O C 曲 线 ROC曲线 ROC曲线上哪一点,都满足 F P R ≥ 0 FPR \geq 0 FPR≥0 , 所以满足(0,1)点的“理想模型”中正例总是排在前面,即预测分类总是正确的。【不要忘了前面的条件哦——正例总排在前,意味着模型输出的实值总与正例对应,因此,此时截断点无论取面积内哪一个点,结合标签为正,都可判断该理想模型对排在前面的预测结果是正确的。】
-
不过,实际任务中的ROC曲线并不是这么平滑的,因为样本总是有限的,因此,实际的ROC曲线通常是由离散的点进行相邻连接得到的。但,构成ROC曲线的点却不是随意得到的,而是有一定的规律:
- 假设给定了 m + m^{+} m+ 个正例和 m − m^{-} m− 个反例,并对学习器的预测结果进行排序
- 首先将分类阈值设置为 0 0 0,此时的 T P R TPR TPR(真正例率)与 F P R FPR FPR(假正例率)均为零,于是在 ( 0 , 0 ) (0,0) (0,0)处标一个点
- 然后将分类阈值往后移动,依次设置为后面的每一个预测结果——即依次将每一个样本划分为正例来判断
- 在确定分类阈值后,标记点坐标按照以下规则逐一标定:
- 首先确定作为分类阈值的样本的前一个样本的坐标: ( x , y ) (x, y) (x,y)
- 然后判断前一个样本的情况:
- 若为正例,则所作标记点坐标为 ( x , y + 1 m + ) (x, y+\frac{1}{m^{+}}) (x,y+m+1) ,即沿着TPR轴移动
- 若为反例,则所作标记点坐标为 ( x + 1 m − , y ) (x+\frac{1}{m^{-}},y) (x+m−1,y) ,即沿着FPR轴移动
- 可以发现,所做的偏移大小与所属类别大小有关。
- 最后,将做好的所有标记点按相邻点连接起来。
R O C 曲 线 ROC曲线 ROC曲线的分析:
- 如果多个学习器的ROC曲线存在完全包含关系,那么被包含的学习器性能要差一些。
- 如果存在曲线交叉,那么就需要做一定的分析才可以判断性能高低,而常用的 A U C AUC AUC分析。
A U C AUC AUC分析:即 R O C 曲 线 ROC曲线 ROC曲线下面积分析—— A U C AUC AUC越大,学习器性能越好。
A U C AUC AUC的计算:
-
令组成 R O C 曲 线 ROC曲线 ROC曲线的有序点坐标依次为: { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } \{(x_{1},y_{1}), (x_{2},y_{2}),..., (x_{m},y_{m})\} { (x1,y1),(x2,y2),...,(xm,ym)} ,且 x 1 = 0 , x m = 1 x_{1}=0, x_{m}=1 x1=0,xm=1
-
此时的 A U C AUC AUC计算公式为:
A U C = 1 2 ∑ i = 1 m − 1 ( x i + 1 − x i ) ⋅ ( y i + y i + 1 ) AUC=\frac{1}{2}\sum_{i=1}^{m-1}(x_{i+1}-x_{i})·(y_{i}+y_{i+1}) \\ AUC=21i=1∑m−1(xi+1−xi)⋅(yi+yi+1)
AUC的结果也与样本预测的排序质量有关。因此,引入一个排序损失来说明AUC与样本预测的排序质量。
排序损失:
-
假设给定 m + m^{+} m+ 个正例和 m − m^{-} m− 个反例,并满足:
D + 包 含 所 有 的 正 例 ( m + ) , 即 正 例 集 D − 包 含 所 有 的 反 例 ( m − ) , 即 反 例 集 D^{+}包含所有的正例(m^{+}),即正例集 \\ D^{-}包含所有的反例(m^{-}),即反例集 D+包含所有的正例(m+),即正例集D−包含所有的反例(m−),即反例集 -
此时的排序损失:
ℓ r a n k = 1 m + m − ∑ x + ∈ D + ∑ x − ∈ D − ( I I ( f ( x + ) < f ( x − ) ) + 1 2 I I ( f ( x + ) = f ( x − ) ) ) \ell_{rank}=\frac{1}{m^{+}m^{-}}\sum_{x^{+}\in D^{+}}\sum_{x^{-}\in D^{-}} \left( II(f(x^{+}) -
该损失计算会考虑每一对正反例,若正例预测值小于反例预测值,就意味着将反例拍到了正例的前面,此时记一个“罚分”;若正例预测值与反例预测值相等,意味着反例可能刚好在分割临界处或也排到正例前面了( f ( x i + ) = f ( x i − ) > f ( x i + 1 + ) f(x_{i}^{+}) = f(x_{i}^{-}) > f(x_{i+1}^{+}) f(xi+)=f(xi−)>f(xi+1+) ),此时记半个“罚分”。
-
该损失的计算值与 A U C AUC AUC一样总是小于 1 1 1的,且刚好对应 R O C 曲 线 ROC曲线 ROC曲线之上的面积,满足:
A U C = 1 − ℓ r a n k AUC=1-\ell_{rank} \\ AUC=1−ℓrank
PS:
- 在 R O C 曲 线 ROC曲线 ROC曲线上的点 ( x , y ) (x, y) (x,y) ,其中 x x x 表示排序在此之前的样本中反例占的比例; y y y 表示正例的比例。【请结合 T P R TPR TPR与 F P R FPR FPR理解】
单词笔记:
- c u t p o i n t cut \quad point cutpoint : 截断点
- R O C ROC ROC : 受试者工作特征曲线—— R e c e i v e r O p e r a t i n g C h a r a c t e r i s t i c Receiver \quad Operating \quad Characteristic ReceiverOperatingCharacteristic
- T r u e P o s i t i v e R a t e True \quad Positive \quad Rate TruePositiveRate : 真正例率
- F a l s e P o s i t i v e R a t e False \quad Positive \quad Rate FalsePositiveRate : 假正例率
- A U C AUC AUC : ROC曲线面积—— A r e a U n d e r R O C C u r v e Area \quad Under \quad ROC \quad Curve AreaUnderROCCurve
2.3.4 代价敏感错误率与代价曲线
在现实分类任务中,不同的分类错误的价值是不同的,比如对于疾病预测,如果分类错了造成的结果差异是巨大的。比如,一个健康人被判定为生病,偶尔的这样错误或许还可以接受;但是如果一个生病很重的,却被判断为健康,可能使得患者错失治疗的最佳时机,甚至死亡,这样的分类错误造成的影响就很大。因此,为了区分不同影响程度或者说对不同错误的忍受度不同,我们引入非均等代价来考量。
比如:
将 健 康 判 为 生 病 : 代 价 为 1 将 生 病 判 为 健 康 : 代 价 为 ∞ 将健康判为生病: 代价为1 \\ 将生病判为健康: 代价为\infty 将健康判为生病:代价为1将生病判为健康:代价为∞
这就是两个不均等的代价,很明显,我们很不希望将生病判为健康,因此设定了很大的代价来提醒模型/学习器。
接下来还是以二分类为例,讨论不均等代价——首先引入代价矩阵:
| 第0类 | 第1类 | |
|---|---|---|
| 第0类 | c o s t i i = 0 cost_{ii}=0 costii=0 | c o s t 01 cost_{01} cost01 |
| 第1类 | c o s t 10 cost_{10} cost10 | c o s t i i = 0 cost_{ii}=0 costii=0 |
- c o s t i i cost_{ii} costii 表示将第 i i i类样本预测为第 i i i类,及预测正确,代价为 0 0 0
- c o s t 01 cost_{01} cost01 表示将第 0 0 0类样本预测为第 1 1 1类,预测错误,所以存在代价
- c o s t 10 cost_{10} cost10 表示将第 1 1 1类样本预测为第 0 0 0类,预测错误,所以存在代价
- 如果 c o s t 01 > c o s t 10 cost_{01}>cost_{10} cost01>cost10, 意味着将0误判为1的错误更被重视。
我们来回顾一下文章一开始提到的错误率:
E ( f ; D ) = a m , a 为 错 误 样 本 数 , m 为 总 样 本 数 可 以 看 出 每 一 个 错 误 样 本 对 错 误 率 的 贡 献 都 是 一 样 的 ( 1 m ) E(f;D)=\frac{a}{m},\quad a为错误样本数,\quad m为总样本数 \\ 可以看出每一个错误样本对错误率的贡献都是一样的(\frac{1}{m}) \\ E(f;D)=ma,a为错误样本数,m为总样本数可以看出每一个错误样本对错误率的贡献都是一样的(m1)
在这里,我们将引入代价敏感(即不均等代价)到错误率中:
-
设0类对应正例,1类对应反例
D + 包 含 所 有 的 正 例 ( m + ) , 即 正 例 集 D − 包 含 所 有 的 反 例 ( m − ) , 即 反 例 集 D^{+}包含所有的正例(m^{+}),即正例集 \\ D^{-}包含所有的反例(m^{-}),即反例集 D+包含所有的正例(m+),即正例集D−包含所有的反例(m−),即反例集 -
带入 E ( f ; D ) E(f;D) E(f;D), 得**”代价敏感“错误率** :
E ( f ; D ; c o s t ) = 1 m ( ∑ x i ∈ D + I I ( f ( x i ) ≠ y i ) × c o s t 01 + ∑ x i ∈ D − I I ( f ( x i ) ≠ y i ) × c o s t 10 ) c o s t 01 : 将 正 例 判 断 为 反 例 的 代 价 c o s t 10 : 将 反 例 判 断 为 正 例 的 代 价 E(f;D;cost)=\frac{1}{m}\left( \sum_{x_{i} \in D^{+}}II(f(x_{i})\neq{y_{i}})\times cost_{01} + \sum_{x_{i} \in D^{-}}II(f(x_{i})\neq{y_{i}}) \times cost_{10}\right) \\ cost_{01}: 将正例判断为反例的代价 \\ cost_{10}: 将反例判断为正例的代价 \\ E(f;D;cost)=m1(xi∈D+∑II(f(xi)=yi)×cost01+xi∈D−∑II(f(xi)=yi)×cost10)cost01:将正例判断为反例的代价cost10:将反例判断为正例的代价
此时的错误率对不同的类别错误有不同的忍受程度。
从错误率的代价引入,我们已经初步了解了代价敏感是怎么回事儿了。
接下来,我们将了解一下代价曲线——即基于分布定义的代价敏感错误率表示。
代价曲线是为了反应学习器在不均等代价下的期望总体代价,此时的ROC曲线已经不能满足此时模型的评估需要了。
代价曲线图的组成:
-
将正例概率代价作为横轴:
P ( + ) c o s t = p × c o s t 01 p × c o s t 01 + ( 1 − p ) × c o s t 10 p 为 样 例 为 ( 标 签 ) 正 例 的 概 率 c o s t 01 : 正 例 误 判 为 反 例 的 代 价 c o s t 10 : 反 例 误 判 为 正 例 的 代 价 P(+)_{cost}=\frac{p \times cost_{01}}{p\times{cost_{01}+(1-p)\times{cost_{10}}}} \\ p为样例为(标签)正例的概率 \\ cost_{01}: 正例误判为反例的代价 \\ cost_{10}: 反例误判为正例的代价 \\ P(+)cost=p×cost01+(1−p)×cost10p×cost01p为样例为(标签)正例的概率cost01:正例误判为反例的代价cost10:反例误判为正例的代价 -
而纵轴取的是归一化代价——与 F N R 和 F P R FNR和FPR FNR和FPR相关:
c o s t n o r m = F N R × p × c o s t 01 + F P R × ( 1 − p ) × c o s t 10 p × c o s t 01 + ( 1 − p ) × c o s t 10 F P R 为 假 正 例 率 , F N R = 1 − F P R , F N R 为 假 反 例 率 cost_{norm}=\frac{FNR \times p \times cost_{01} + FPR \times (1-p) \times cost_{10}} {p \times cost_{01} + (1-p) \times cost_{10}} \\ FPR为假正例率, \\ FNR=1-FPR, FNR为假反例率 \\ costnorm=p×cost01+(1−p)×cost10FNR×p×cost01+FPR×(1−p)×cost10FPR为假正例率,FNR=1−FPR,FNR为假反例率
代价曲线的绘制:
- R O C 曲 线 ROC曲线 ROC曲线上的每一个点(FPR,TPR),都对应一条代价曲线
- 该代价曲线即代价平面上 ( 0 , F P R ) (0,FPR) (0,FPR) 和 ( 1 , F P R ) (1,FPR) (1,FPR) 两点连成的直线
- 然后逐次绘制 R O C 曲 线 ROC曲线 ROC曲线上的其它点对应的代价曲线即可
- 绘制好所有曲线后,此时,所有代价曲线的公共下界面积——即为所有条件下学习器的期望总体代价
代价曲线示意图:
单词笔记:
- u n e q u a l c o s t unequal \quad cost unequalcost : 非均等代价,又是也叫非等价代价
- c o s t m a t r i x cost \quad matrix costmatrix : 代价矩阵
- c o s t − s e n s i t i v e cost-sensitive cost−sensitive : 代价敏感
- c o s t c u r v e cost \quad curve costcurve : 代价曲线
- c o s t − s e n s i t i v e l e a r n i n g cost-sensitive \quad learning cost−sensitivelearning : 代价敏感学习
2.4 比较检验
(待补充)
2.4.1 假设检验
(待补充)
2.4.2 交叉验证t检验
(待补充)
2.4.3 McNemar检验
(待补充)
2.4.4 Friedman与Nemenyi后续检验
(待补充)
2.5 偏差与方差
(待补充)
第二章 阅读材料整理
【link名称为作者姓名等,可点击前往查看相关论文。】
- 自助采样法: E f r o n a n d T i b s h i r a n i , 1993 Efron \quad and \quad Tibshirani \quad, 1993 EfronandTibshirani,1993
- ROC曲线: S p a c k m a n , 1989 Spackman \quad, 1989 Spackman,1989
- AUC: B r a d l e y , 1997 Bradley \quad,1997 Bradley,1997 ,B站AUC解读教学视频
- ROC曲线用途综述: F a w c e t t , 2006 Fawcett \quad, 2006 Fawcett,2006
- 代价曲线: D r u m m o n d a n d H o l t e , 2006 Drummond \quad and \quad Holte \quad, 2006 DrummondandHolte,2006
- 代价敏感学习: E l k a n , 2001 Elkan \quad, 2001 Elkan,2001
- 交叉验证法: D i e t t e r i c h , 1998 Dietterich \quad, 1998 Dietterich,1998
- 比较检验: D e m s a r , 2006 Demsar \quad, 2006 Demsar,2006
- 偏差-方差-协方差分解: G e m a n e t a l . , 1992 Geman \quad et \quad al. \quad, 1992 Gemanetal.,1992
- 对偏差和方差的估计实验: K o n g a n d D i e t t e r i c h , 1998 Kong \quad and \quad Dietterich \quad, 1998 KongandDietterich,1998
第二章 概念单词
- ⋆ \star ⋆ a c c u r a c y accuracy accuracy : 精度
- ⋆ \star ⋆ e r r o r error error : 误差/错误——错误率: e r r o r r a t e error \quad rate errorrate
- e m p i r i c a l e r r o r empirical \quad error empiricalerror : 经验误差
- g e n e r a l i z a t i o n e r r o r generalization \quad error generalizationerror : 泛化误差
- ⋆ \star ⋆ o v e r f i t t i n g overfitting overfitting : 过拟合
- ⋆ \star ⋆ u n d e r f i t t i n g underfitting underfitting : 欠拟合
- m o d e l s e l e c t i o n model \quad selection modelselection : 模型选择
- t e s t i n g e r r o r testing \quad error testingerror : 测试误差
- h o l d − o u t hold-out hold−out : “留出法”
- s t r a t i f i e d s a m p l i n g stratified \quad sampling stratifiedsampling : 分层采样
- f i d e l i t y fidelity fidelity : 保真性
- ⋆ \star ⋆ k − f o l d c r o s s v a l i d a t i o n k-fold \quad cross \quad validation k−foldcrossvalidation : ”K折交叉验证“
- L e a v e − O n e − O u t Leave-One-Out Leave−One−Out : ”留一法“
- b o o t s t r a p p i n g bootstrapping bootstrapping : ”自助法“
- b o o t s t r a p s a m p l i n g bootstrap \quad sampling bootstrapsampling : “自助采样法”
- o u t − o f − b a g e s t i m a t e out-of-bag \quad estimate out−of−bagestimate : 包外估计
- ⋆ \star ⋆ p a r a m e t e r parameter parameter : 参数
- ⋆ \star ⋆ p a r a m e t e r t u n i n g parameter \quad tuning parametertuning : 调参
- v a l i d a t i o n s e t validation \quad set validationset : 验证集
- ⋆ \star ⋆ p e r f o r m a n c e m e a s u r e performance \quad measure performancemeasure : 性能度量
- ⋆ \star ⋆ m e a n s q u a r e d e r r o r mean \quad squared \quad error meansquarederror : 均方误差
- ⋆ \star ⋆ p r e c i s i o n precision precision : ”查准率“
- ⋆ \star ⋆ r e c a l l recall recall : ”查全率“
- m a c r o − P macro-P macro−P , m a c r o − R macro-R macro−R , m a c r o − F 1 macro-F1 macro−F1 : ”宏查准率“,”宏查全率“,”宏F1“
- m i c r o − P micro-P micro−P , m i c r o − R micro-R micro−R , m i c r o − F 1 micro-F1 micro−F1 : ”微查准率“,”微查全率“,”微F1“
- ⋆ \star ⋆ t r u e p o s i t i v e true \quad positive truepositive : 真正例
- ⋆ \star ⋆ f a l s e p o s i t i v e false \quad positive falsepositive : 假正例
- ⋆ \star ⋆ t r u e n e g a t i v e true \quad negative truenegative : 真负例
- ⋆ \star ⋆ f a l s e n e g a t i v e false \quad negative falsenegative : 假负例
- ⋆ \star ⋆ c o n f u s i o n m a t r i x confusion \quad matrix confusionmatrix : 混淆矩阵
- B r e a k − E v e n P o i n t Break-Even \quad Point Break−EvenPoint : 平衡点
- c u t p o i n t cut \quad point cutpoint : 截断点
- ⋆ \star ⋆ R O C ROC ROC : 受试者工作特征曲线—— R e c e i v e r O p e r a t i n g C h a r a c t e r i s t i c Receiver \quad Operating \quad Characteristic ReceiverOperatingCharacteristic
- ⋆ \star ⋆ T r u e P o s i t i v e R a t e True \quad Positive \quad Rate TruePositiveRate : 真正例率
- ⋆ \star ⋆ F a l s e P o s i t i v e R a t e False \quad Positive \quad Rate FalsePositiveRate : 假正例率
- ⋆ \star ⋆ A U C AUC AUC : ROC曲线面积—— A r e a U n d e r R O C C u r v e Area \quad Under \quad ROC \quad Curve AreaUnderROCCurve
- u n e q u a l c o s t unequal \quad cost unequalcost : 非均等代价,又是也叫非等价代价
- ⋆ \star ⋆ c o s t m a t r i x cost \quad matrix costmatrix : 代价矩阵
- ⋆ \star ⋆ c o s t − s e n s i t i v e cost-sensitive cost−sensitive : 代价敏感
- ⋆ \star ⋆ c o s t c u r v e cost \quad curve costcurve : 代价曲线
- c o s t − s e n s i t i v e l e a r n i n g cost-sensitive \quad learning cost−sensitivelearning : 代价敏感学习
- h y p o t h e s i s t e s t hypothesis \quad test hypothesistest : 假设检验
- ⋆ \star ⋆ b i n o m i a l d i s t r i b u t i o n binomial \quad distribution binomialdistribution : 二项分布
- b i n o m i a l t e s t binomial \quad test binomialtest : 二项检验
- t − t e s t t-test t−test : T检验
- p a i r e d t − t e s t s paired \quad t-tests pairedt−tests : 成对t检验
- p o s t − h o c t e s t post-hoc \quad test post−hoctest : 后续检验
- c o n f i d e n c e confidence confidence : 置信度
- c o n t i n g e n c y t a b l e contingency \quad table contingencytable : 列联表
- B i l a t e r a l h y p o t h e s i s Bilateral \quad hypothesis Bilateralhypothesis : 双边假设
- b i a s − v a r i a n c e d e c o m p o s i t i o n bias-variance \quad decomposition bias−variancedecomposition : 偏差-方差分解
- b i a s − v a r i a n c e d i l e m m a bias-variance \quad dilemma bias−variancedilemma : 偏差-方差窘境
- b i a s − v a r i a n c e − c o v a r i a n c e d e c o m p o s i t i o n bias-variance-covariance \quad decomposition bias−variance−covariancedecomposition : 偏差-方差-协方差分解
第二章 遗留问题
【关于遗留问题,会在后期单独整理后发布。】
- 深入了解并分析 A U C AUC AUC计算的原理,讨论 ℓ r a n k \ell_{rank} ℓrank 的意义。
- 深入了解代价曲线的计算原理和意义。
- 深入了解常用检验方法—— t t t 检验、 M c N e m a r McNemar McNemar 检验、 F r i e d m a n Friedman Friedman 检验以及 N e m e n n y i Nemennyi Nemennyi 后检验等。
如果对你有所帮助,不妨点个赞加个关注,你的鼓励是我创作的动力!做更多更好的笔记!