Relational inductive biases, deep learning, and graph networks 论文导读,DeepMind图网络
Relational inductive biases, deep learning, and graph networks 论文导读
标题:《关系归纳偏好、深度学习和图网络》
一、推荐理由
简述:DeepMind联合谷歌大脑、MIT等机构的27位作者发表重磅论文,提出“图网络”(Graph network, GN)。

DeepMind作为行业标杆,其动向一直是AI业界的关注热点。最近,DeepMind将对“关系”产生了兴趣, 6月以来接连分布多篇“关系”主题的论文,比如:
- 《关系归纳偏置》(Relational inductive bias for physical construction in humans and machines)
- 《关系深度强化学习》(Relational Deep Reinforcement Learning)
- 《关系RNN》(Relational Recurrent Neural Networks)
而其中,最值得看的将要属这一篇《Relational inductive biases, deep learning, and graph networks》(《关系归纳偏好、深度学习和图网络》),此论文一出,引发业界的广泛讨论,普遍认为其有可能解决灵奖得主Judea Pearl指出的深度学习无法做因果推理的核心问题。
 图灵奖得主、贝叶斯网络之父Judea Pearl (PS:Judea Pearl在ArXiv上发布论文《机器学习理论障碍与因果革命七大火花》,指出当前的机器学习系统几乎完全以统计学或盲模型的方式运行,不能作为强AI的基础。他认为突破口在于“因果革命”,借鉴结构性的因果推理模型,能对自动化推理做出独特贡献。)
图灵奖得主、贝叶斯网络之父Judea Pearl (PS:Judea Pearl在ArXiv上发布论文《机器学习理论障碍与因果革命七大火花》,指出当前的机器学习系统几乎完全以统计学或盲模型的方式运行,不能作为强AI的基础。他认为突破口在于“因果革命”,借鉴结构性的因果推理模型,能对自动化推理做出独特贡献。)
根据ICLR 2019会议论文主题的热度排行榜(参考ICLR热点排行榜),图网络模型中的图神经网络(Graph neural network, GNN)排名为31,但是相比于2018年热度明显增大。
因此,趁着还不太挤,大家赶快搭上“图网络”通向“人类智能”的早班车,迎接下一个十年风口。
二、论文简读
1. 论文主题
作者认为目前的深度学习模型不能发展“人类智能”的主要原因是缺乏“归纳推广”能力;基于此,作者将图(比如知识图谱)与深度学习结合,继而提出图网络,图网络具备图的归纳推广能力与较强的关系归纳偏好,也具备深度学习“端到端”的样本灵活性。
作者写这篇论文的主要目的是建议大家关注图网络模型,同时为图网络模型设计统一框架,引导图网络发展方向。
2. 论文结构
The following is part position paper, part review, and part unification.
如原文所说,论文主要分为三部分,一部分是建议书,建议大家关注图网络模型;一部分是综述,综述现有的图网络模型;还有一部分是统一定义,为图网络模型定义了统一的框架与算法流程。
如果赶时间,可以直接阅读本文的第三部分:问题解决办法,或者论文的第3节:Graph networks。忽略前面两部分对理解图网路不太影响。
三、论文细读
1. 待解决的问题
现有的“端到端(End-to-end)”的深度学习模型不能实现人类智能的原因在于缺乏归纳推广(Combinatorial generalization)的能力,而实现归纳推广能力的关键是结构化表示与计算(Structured representations and computations)。
1.1. “端到端”的深度学习模型:
在AI起步的年代,数据匮乏,计算机能力不足,人们倾向于提前设计出结构化方法(Structure approach),以实现对客观世界的结构化描述,进而降低样本复杂度,常见的结构化方法有图模型,贝叶斯模型,经典规划等。
但近年来由于计算资源与数据资源越来越廉价,端到端模型(常见的深度学习模型,比如DNN,CNN等都是端到端的)受到越来越多的关注,主张最小化先验表征与计算假设,同时避免显示结构与人工介入,直接从原始数据端到分类结果端。
1.2. 归纳推广(Combinatorial generalization)
人类的归纳推广能力就是将有限的经验(已学习到的)组合成无限的解决方案,进而推广到未知的场景中。比如,将已学习到的单词组合为各种各样的句子;再比如,将A地旅游的经验(怎么坐飞机,去哪儿吃饭等)应用到B地旅游上。
人类拥有归纳推广能力的原因在于我们在认知系统中建立了对应于真实世界的一个关系结构(Relation structure),学习过程就是建立与调整结构的过程。
以人类对“猫狗”建立的认知关系(本例子有“AI微刊”团队提供,不属于原文内容)。
以前我只知道“田园犬”一种狗,所以我认为“狗=田园犬”;后来我又见到了“二哈”,我就调整结构,将“狗”作为父系,将“田园犬”与“二哈”作为子系,并且还添加了很多待补充的子系;再后来,我看到了“金毛”,就直接把“金毛”加入到子系中。根据狗的经验,我见到“加菲猫”后就会直接建立一个类似于狗的认知结构,而不会认为“猫=加菲猫” 。
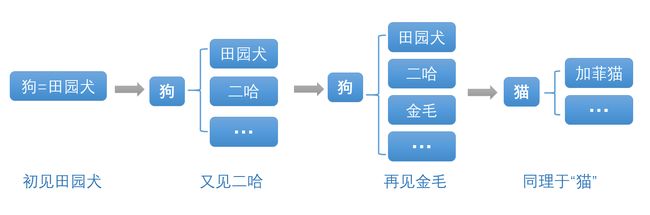 人类对“猫狗”的知识关系结构
人类对“猫狗”的知识关系结构
2 问题解决思路
作者认为,要让AI学会人类的归纳推广能力,就需要模仿人类建立关系结构(Relation structure),进行关系推理(Relational reasoning)。作者认为“端到端”模型与结构化方法都各有优点,应该将两者结合起来,实现提前设计(先天)与启发式学习(后天)兼顾。
2.1 先天与后天结合
结构化方法(先天)有较强的归纳推广能力,但是提前设计好结构,使得灵活性欠佳,不像端到端的深度学习模型灵活适应数据。
而端到端模型是启发式学习(后天),其归纳推广能力较差,在复杂场景理解,结构数据推理,少样本学习等方面表现不足。
因此我们不能走“二选一”的极端,应该将两者结合,就好像先天所得(结构化方法)与后天经验(端到端学习)结合一样。
2.2 关系推理(Relational reasoning)
首先,对于关系结构有:
结构(Structure)是由一堆已知子块构成;
- 结构化表示(Structured representations):子块构成结构的过程与方法(即元素排列);
- 结构化计算(Structured computations):对元素及其组合后的产物进行整体操作;
- 关系推理(Relational reasoning):基于组合规则利用实体与关系进行结构化表示过程。
结构中的主要包括实体,关系,以及规则:
- 实体(Entity)是具有属性的元素,比如具有尺寸与质量属性的物理实体;
- 关系(Relation)描述实体之间特征,比如两个物体一样大,不一样重,距离远等。
- 规则(Rule)是函数关系,能够将输入的实体与关系映射到输出的实体与关系,比如将A的尺寸大于B映射为A比B重。
举例说明:
图模型(Graphical models)就是典型的关系结构,其中的隐马尔可夫模型就是规定当前状态的只依赖于前一个状态,这种约束描述了现实世界的事物间稀疏的因果关系。
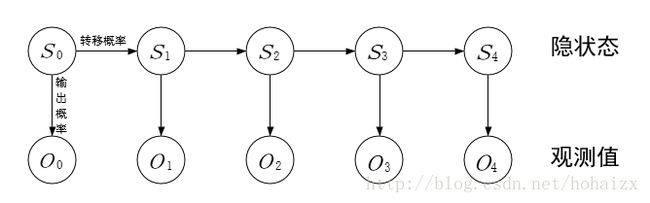
隐马尔科夫链
2.3 归纳偏好(Inductive biases)

根据原文(上图标绿部分),归纳偏好的作用是引导算法学习实体及其实体间的关系。
根据周志华的《机器学习》,归纳偏好是算法在学习过程中对某种类型假设的偏好。
归纳偏好就是在算法设计时直接或者间接带来的假设、约束等,这些假设与约束反映了算法如何与真实世界连接。学习过程是从解空间中搜寻满足要求的解的过程,但是往往有多个解满足要求,这是就要归纳偏好来选择其中一个更优解。因此,归纳偏好作用是引导算法进行学习。
算法都具有归纳偏好,比如朴素贝叶斯分类器假设“所有属性之间相互独立”,这导致分类结果偏好于训练样本较多的类别。再比如,二次函数拟合算法偏好于将数据你何为二次曲线。
归纳偏好分为关系归纳偏好(Relational inductive biases),比如层次结构带来逐层处理的偏好,使得信息之间的交互距离越来越长,以及非关系归纳偏好(Non-relational inductive biases),比如非线性激活、归一化等都是对学习轨迹的约束。
2.4. 深度学习模型的关系归纳偏好
深度学习算法的各个模块也具有关系归纳偏好:
1. 全连接层(Fully connected layer):
实体是神经元,关系是全部到全部(All-to-all)(层与层之间全连接),规则有权值与偏置值指定。因为是全连接,本层的所有神经元都可以相互作用以确定下一层任何单元的输出值,因此关系归纳偏好非常弱。
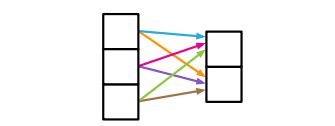 Fully connected layer
Fully connected layer
2. 卷积层(Convolutional layers):
实体是神经元(或者像素)。关系是局部性(Locality,卷积核局部感知)与平移不变性(Translation invariance,同一层中卷积核参数共享)。
 Convolutional layer
Convolutional layer
3. 递归层(Recurrent layers):
实体是每一步的输入和隐藏状态;关系是当前的隐藏状态对前一步隐藏状态和当前输入的依赖性,规则就是跟新隐藏状态的方式。具有时间不变性的偏好(Temporal invariance)。
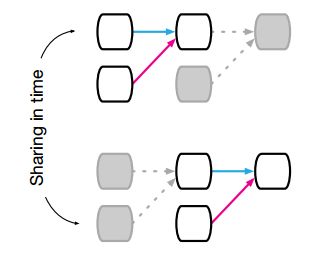 Recurrent layer
Recurrent layer
总结为:
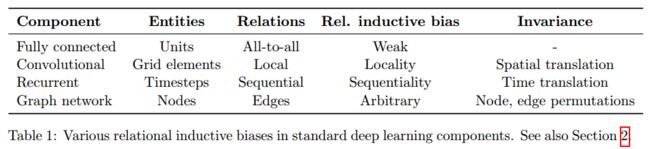 深度学习模型的关系归纳偏见
深度学习模型的关系归纳偏见
3. 问题解决办法
作者将之前已出现过的类似模型,比如图神经网络(Graph neural network,GNN),图卷积网络(Graph convolutional network,GCN))等,统一定义为图网络(Graph networks),并设计了图网络的框架。
3.1. 图网络框架
论文中定义了图网络的框架:
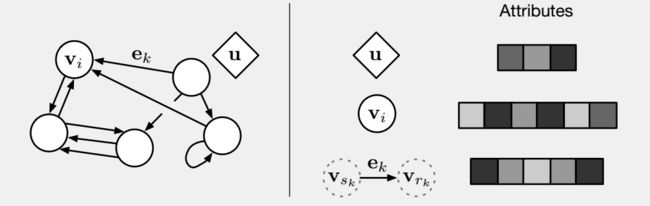 图网络框架
图网络框架
如图,图网络包括有向的属性图,实体是节点(Node),关系是边(Edge),并且具有全局属性(Global attribute)
1. 节点:代表具有属性的实体,属性可以用向量、集合等表示;
2. 边:表现实体之间的关系,是单向边,从发射节点(Sender node)指向接受节点(Receiver node);
3. 全局属性:表现当前系统的状态。
3.2. 图网络算法
一个图网络可以用三元函数表示:G=(u,V,E),其中u是全局属性,V={vi}是节点的属性(为避免node首字母n太重复,使用vertex:顶点的首字母v表示),E={(ek, rk, sk)}表示一条边,ek是边的属性,rk,sk分别是发射结点与接收节点的坐标。
图网络中用到两类函数,分别是更新函数(Aggregation function)与聚合函数(Aggregation function)。更新函数用于更新节点、边、全局的属性值,聚合函数用于计算对被更新对象有影响的边、节点、全局的属性聚合值(实际上是一个中间值)。
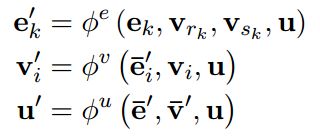 标题更新函数
标题更新函数
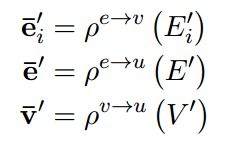 聚合函数
聚合函数
如下图,更新边时,需要用到阈值相连的节点与全局的属性值;更新节点时,需要用到所有指向该节点的边以及全局的属性值;更新全局属性时,需要用到全图的边与节点的属性值。
 节点、边、全局属性更新图示
节点、边、全局属性更新图示
具体更新算法如下:
 更新算法
更新算法
3.3. 图网络的优点
关系归纳偏好与归纳推广能力:
图网络由于较强的关系归纳偏好,这有助于图网络学习关系。
首先,在设计网络结构,实体之间的边数与方向就天然带来归纳偏好;此外,实体与实体之间的关系是用集合表示的,因此集合给图网络带来了“顺序不变性”的偏好。
此外,图网络有天然的归纳推广能力。更新边与节点的函数的在所有边与节点上复用的,这就天然带来了归纳推广能力。
除此之外,图网络还具有其他优点:
1. 灵活的表征(Flexible representation):图结构灵活多变,并且边、节点、全局的属性可以事向量、张量、集合、图等。
2. 模块内部结构可更改(Configurable within-block structure):模块内部的结构可根据需要定义。
3. 多模块结构(Composable multi-block artchitectures):网络可以用多个模块组合而成,可以根据需要配置网络结构。
3.4. 图网络模型举例
作者引用文献,举例说明了现有的图网络模型,比如:图神经网络(GNN),图卷积网络(GCN),message-passing neural network (MPNN),non-local neural network (NLNN)。并且,用文中提出的图网络框架对这些模型进行了分析:
 典型的图网络模型结构分析
典型的图网络模型结构分析
每一种模型都值得认真研究,考虑到文章篇幅的原因,就不在此详述了。
感兴趣的读者可以研读这篇论文后面的相关模型算法介绍。
全文完
关注公众号“AI微刊”,后台发送“图网络”,即可获得Deepmind关于Relation的论文包以及本论文的源代码资源包。
 AI微刊公众号
AI微刊公众号
参考
[1] “【CNN已老,GNN来了】DeepMind、谷歌大脑、MIT等27位作者重磅论文,图网络让深度学习也能因果推理”,搜狐
https://www.sohu.com/a/235703807_473283;
[2] “隐马尔科夫(HMM)模型”,CSDN
https://blog.csdn.net/hohaizx/article/details/78266785;
[3] “《Relational inductive biases, deep learning, and graph networks》图网络 论文解读”,CSDN
https://blog.csdn.net/qq_32201847/article/details/80708193;
[4] “GNN新作《Relational inductive biases,deep learning,and graph networks》读书笔记”,CSDN
https://blog.csdn.net/Trasper1/article/details/81475667;
[5] “《Relational inductive biases, deep learning, and graph networks》论文解读(转载)”,CSDN
https://blog.csdn.net/weixin_38569817/article/details/80741779。