《算法导论》散列表与Go语言中的map
《算法导论》读书笔记:散列表(附-Go语言中的map)
参考书籍:《算法导论》散列表
参考博客:https://mp.weixin.qq.com/s/OJSxIXH87mjCkQn76eNQsQ
1. 直接寻址表
全域 U 直接到槽 K
但当全域 U 很大时,不可取
2. 散列表
装载因子
表示哈希表中元素的填满程度。它的计算公式:装载因子=填入哈希表中的元素个数/哈希表的长度。装载因子越大,填入的元素越多,空间利用率就越高,但发生哈希冲突的几率就变大。反之,装载因子越小,填入的元素越少,冲突发生的几率减小,但空间浪费也会变得更多,而且还会提高扩容操作的次数。装载因子也是决定哈希表是否进行扩容的关键指标
3. 散列函数
优秀的散列函数应包含以下特性:
- 均匀性:一个好的哈希函数应该在其输出范围内尽可能均匀地映射,也就是说,应以大致相同的概率生成输出范围内的每个哈希值。
- 效率高:哈希效率要高,即使很长的输入参数也能快速计算出哈希值。
- 可确定性:哈希过程必须是确定性的,这意味着对于给定的输入值,它必须始终生成相同的哈希值。
- 雪崩效应:微小的输入值变化也会让输出值发生巨大的变化。
- 不可逆:从哈希函数的输出值不可反向推导出原始的数据。
3.1 除法散列法
用关键字 k 除以 m,选择其余数
h ( k ) = k m o d m h(k) = k\mod m h(k)=kmodm
在 m 的选择上,应尽量避免选择 2 的幂,如此则 h(k) 就是 k 的 p 个最低位数,可能会造成分布不均
m 的较好选择是一个不太接近 2 的整数幂的素数
3.2 乘法散列法
乘法散列法包含两个步骤:
- 用关键字k 乘常数 A(0
- 用 m 乘以该值,并向下取整
h ( k ) = ⌊ m ( k a − ⌊ k a ⌋ ) ⌋ h(k) = \lfloor m(ka - \lfloor ka\rfloor)\rfloor h(k)=⌊m(ka−⌊ka⌋)⌋
其中 m 的选择没有除法散列这么苛刻
3.3 全域散列法
随机选择一个作为散列函数,使之独立于要存储的关键字
4. 开放寻址法
线性探查
h ( k , i ) = ( h ′ ( k ) + i ) m o d m h(k,i) = (h'(k) + i)\ mod \ m h(k,i)=(h′(k)+i) mod m
一次群集
二次探查
h ( k , i ) = ( h ′ ( k ) + c 1 i + c 2 i 2 ) m o d m h(k,i) = (h'(k) + c_1i + c_2i^2)\ mod \ m h(k,i)=(h′(k)+c1i+c2i2) mod m
二次群集
双重探查
5. 完全散列
二级散列表

定义一个一级散列函数:
h ( k ) = ( ( a k + b ) m o d p ) m o d m h(k) = ((ak + b)mod \ p)mod \ m h(k)=((ak+b)mod p)mod m
其中a,b,p,m都是事先定义好的,该散列函数将决定关键字k落到哪个槽中,再定义二级散列函数:
h j ( k ) = ( ( a j k + b j ) m o d p ) m o d m j h_j(k) = ((a_jk+b_j)mod \ p)mod \ m_j hj(k)=((ajk+bj)mod p)mod mj
其中aj,bj,mj均为事先定义好的二级参数,该散列函数将决定关键字k 落到第二级的哪个槽上
6. Go 语言中的 map
从此节开始,map 都指代 Go 语言中实现的 map
源码位置:src/runtime/map.go
在Go语言的map实现中,map中的数据被存放于一个数组中的,数组的元素是桶(bucket),每个桶至多包含8个键值对数据。哈希值低B位(low-order bits)用于选择桶,哈希值高8位(high-order bits)用于在一个独立的桶中区别出键。
注意:map中的键
Go中的 map 的键指定了不能是 slice,function ,map 和 包含 slice 的 struct 类型不可以作为 map 的键,否则会编译错误
究其根本,是因为在每个 bucket 中,对于哈希冲突使用了开放寻址法,通过比较 key 值,通过向后位移get-set元素,所以这里要求map 的键必须支持 ==和 !=
注意:map[math.NaN()]
详情可以参考:Go语言中的map[math.NaN()]
6.1 查找 Key
查找过程设计源码mapaccess1()和mapaccess2(), mapaccessk()的实现,内容大同小异,只是返回值不同,三者函数对应语言层面形式如下:
v := m[k]
v, ok := m[k]
for k,v := range m[k]

在 map 中查找一个 key 的大致流程为:
-
先将 key 通过 hash 函数进行序列化
-
用 hash 值低B位寻找对应 bucket
-
再用 hash 值高8位在 bucket 中顺序遍历 tophash 值
外层循环:遍历 bucket 以及 overflow bucket
内存循环:顺序遍历 bucket 中的 tophash
若 tophash 为空,则找不到
若 遍历完bucket 和 overflow bucket 都没找到,则找不到
若 遍历到了,则返回对应下标的 key 或 value
6.2 赋值 key
赋值 key 的相关源码为mapassign代码,其主要逻辑如下:
-
异常检测逻辑:竞态检测,是否有其他 goroutine 在写等
-
通过key和哈希种子,算出对应哈希值
-
根据 hash 找出对应第几号桶,并且若此时 map 正在搬迁,则对该桶进行搬迁工作(渐进式扩容);否则,求出 bucket 内存位置
-
进入主循环:顺序遍历桶中的8个 cell,主要逻辑如下:
if cell 的 tophash 值和当前 tophash 不等
若为空,则不先插入,先记录空的位置,因为可能后面能找到对应key,该空槽为之前删除导致
否则 continue
if cell 的 tophash 值和 当前 tophash 相等
还需要取 key 值做相等判断
if key 相等,更新
否则 continue
最终获取到要插入 key 的对应 value 的内存地址
若遍历完8个cell 还没找到,则去溢出桶中遍历
若溢出桶也找不到,跳出循环
-
在主循环中仍未找到合适的cell 供 key 插入,则会触发以下两种情况:
情况1:判断当前 map 装载因子是否达到设定的6.5阈值,或者当前 map 溢出桶数量过多,则进行扩容,调用 hashGrow 函数,goto 步骤3
情况2:在不满足情况1 的条件下,当前桶新建溢出桶,并将新 kv 插入到新桶的0号位置
赋值的最后一步实际上是编译器额外生成的汇编指令来完成的,可见靠 runtime 有些工作是没有做完的。所以,在go中,编译器和 runtime 配合,才能完成一些复杂的工作。同时说明,在平时学习go的源代码实现时,必要时还需要看一些汇编代码。
6.3 删除 key
删除 key 和 赋值 key 大同小异,都是要先找到 key 所在位置再进行操作,源码为mapdelete方法
6.4 遍历 map
源码位于mapiterinit()和mapiternext()方法逻辑中
结果就是:迭代 map 结果是无序的
无序的结果造成,有如下两部分原因:
- map 遍历的过程,其实是按序遍历 bucket 的,同时按需遍历 overflow;但是在 map 发送扩容之后,会发生 key 的搬迁,造成落在一个 bucket 中的 key,搬迁后可能落到其他 bucket 中,从而造成乱序
- Go 内部实现,为了保证遍历 map 结果无序,在 map 遍历时,不会固定地从第0号 bucket 开始遍历,每次遍历,取一个随机值序号 bucket,从该 bucket 开始遍历,按照桶序遍历下去,若有溢出桶,则遍历溢出桶,直到循环回到起始桶
- 上述描述是为扩容的 map ,若 map 处于扩容状态,老 bucket 数据可能会分裂到两个不同的 bucket 中,此时则会先从老 bucket 遍历数据,
6.5 扩容 map
针对两种情况,官方采取的策略也不同:分别为 增量扩容 和 等量扩容
增量扩容

问题场景
条件1:判断装载因子是否达到阈值,即元素个数 >= 桶(bucket)总数 * 6.5,这时候说明大部分的桶可能都快满了,即平均每个桶存储的键值对达到6.5个,如果插入新元素,有大概率需要挂在溢出桶(overflow bucket)上。
解决方案
将 B + 1,新建一个buckets数组,新的buckets大小是原来的2倍,然后旧buckets数据搬迁到新的buckets。该方法我们称之为增量扩容。
关于 bucketx 和 buckety
对于增量扩容而言,原本一个bucket中的key会被分裂到两个bucket中去,它们分别处于bucket x和bucket y中,它们之间存在关系bucket x + 2^B = bucket y(其中,B是老bucket对应的B值)。假设key所在的老bucket序号为n,那么如果key落在新的bucket x,则它应该置入 bucket x起始位置 + n*bucket的内存中去;如果key落在新的bucket y,则它应该置入 bucket y起始位置 + n*bucket的内存中去。因此,确定key落在哪个区间,这样就很方便进行内存地址计算,快速找到key应该插入的内存地址。
等量扩容

问题场景
条件2:判断溢出桶是否太多,当桶总数 < 2 ^ 15 时,如果溢出桶总数 >= 桶总数,则认为溢出桶过多。当桶总数 >= 2 ^ 15 时,直接与 2 ^ 15 比较,当溢出桶总数 >= 2 ^ 15 时,即认为溢出桶太多了。
等量扩容发生在对一个 map 频繁 增删的情况,会造成溢出桶过多,但 bucket 内部的 cell 并不紧凑,有一些是空的
解决方案
不扩大容量,buckets数量维持不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。该方法我们称之为等量扩容。
极端情况注意
对于等量扩容:若插入 map 的 key 哈希出来结果几乎一样,则会落到同一个 bucket 中,超过 8 个又会 overflow,这是哈希表退化成一个链表。
但是 Go 中每一个 map 在初始化阶段makemap中的哈希种子都是随机定制的,所以造成这种冲突是很难的
扩容相关源码为hashGrow()和growWork()函数,其中hashGrow()函数分配新 buckets,并将 原来的 buckets 挂到 oldbuckets 上;growWork()才是真正搬迁操作,每次mapassign()和mapdelete()都会判断是否处于搬迁状态然后调用growWork()。
hashGrow()主要逻辑如下:
- 若满足条件1,则B值加1,相当于扩容2倍,否则为条件2,等量扩容,B不变
- 记录老的 buckets,申请新的 buckets 空间
- 设置搬迁进度为0,新的 overflow 的 buckets 数为0
- 若 hmap 中的键值对是inline的,即小于128字节,即通过 extra 字段存储 overflow bucket,则
h.extra.overflow将其置为 nil
growWork()主要逻辑如下:
- 执行
evacuate()函数 - 判断是否完成扩容,未完成就再次调用
evacuate()再搬迁一个 bucket
evacuate()函数中的流程较长,可以参考博客:https://mp.weixin.qq.com/s/OJSxIXH87mjCkQn76eNQsQ
这里即每次至多搬迁两个 bucket
bucket 序号在扩容中的变化
增量扩容:B 值加一,导致 hash 后的低位取值发生变化,会取后 B 位,根据新加的那一位取0或1,将会导致是放置在新桶原号 bucket 上还是在 n+2^旧B 上
等量扩容则序号不变
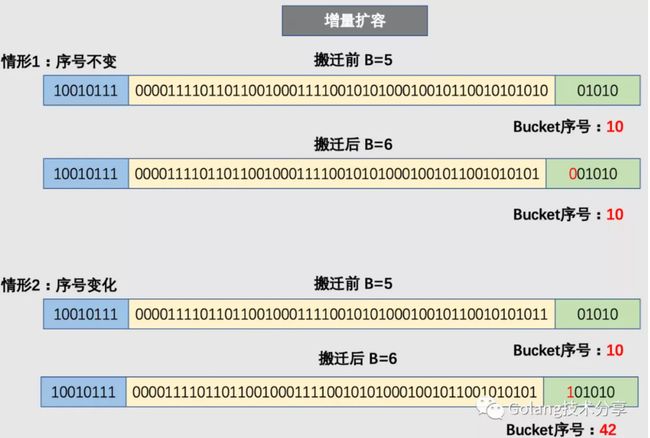
上述 map 扩容的流程如下图:

6.6 总结
Go 的 map 底层就是使用哈希表实现,用链地址法解决哈希冲突,数组加链表
map中定义了2的B次方个桶,每个桶中能够容纳8个key。根据key的不同哈希值,将其散落到不同的桶中。哈希值的低位(哈希值的后B个bit位)决定桶序号,高位(哈希值的前8个bit位)标识同一个桶中的不同 key。
当向桶中添加了很多 key,造成元素过多,超过了装载因子所设定的程度,或者多次增删操作,造成溢出桶过多,均会触发扩容。
扩容分为增量扩容和等量扩容。
- 增量扩容,会增加桶的个数(增加一倍),把原来一个桶中的 keys 被重新分配到两个桶中。
- 等量扩容,不会更改桶的个数,只是会将桶中的数据变得紧凑。
不管是增量扩容还是等量扩容,都需要创建新的桶数组,并不是原地操作的。
扩容过程是渐进性的,主要是防止一次扩容需要搬迁的 key 数量过多,引发性能问题。触发扩容的时机是增加了新元素, 桶搬迁的时机则发生在赋值、删除期间,每次最多搬迁两个 桶。查找、赋值、删除的一个很核心的内容是如何定位到 key 所在的位置,需要重点理解。
map 不是并发安全的数据结构,且遍历无序
另外需要注意map[math.NaN()]