windows10环境下载labelImg及使用方法
在图像检测中涉及到SSD(一种识别算法,不是那个固态硬盘hhh)的时候,打标签的方式变了。之前使用的caffe的框架,直接在txt中在图像名后面写上标签就可以,但SSD中需要先建立xml文件。这个xml里面存储了什么呢?其实可以通过文本形式打开文件,里面存储就是图像中框出特定区域的坐标以及你为该图片打的标签,也是一种标签文件。
好了,废话不多说,进入正题,怎么在windows10下下载labelImg~*(ai !这个小写的L和大写的i怎么长一样。。。。)
一、labelImg的下载
本文介绍的方法使用到了Anaconda3,但Anaconda3的下载网上教程普遍较多,本文不再赘述。没有下载的朋友可以下载之后再回来看本篇教程。
1.在Anaconda Prompt中下载一些安装包
#注意:大小写一定要区分,完全按照下面的输入
pip install PyQt5
pip install pyqt5-tools
pip install lxml #在正常下载anaconda3的情况下,lxml应该已经具备
pip install labelImg 可能有人不知道Anaconda Prompt在哪里?其实就是一个python终端。打开左下角“开始”,位置如图(就是Anaconda3 (64 -bit)目录下的第三个):
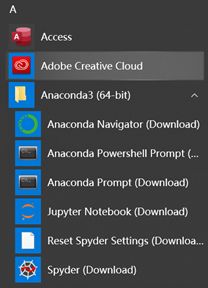
2.重新打开Anaconda Prompt输入IabelImg
前面的下载可能需要花费一段时间,但只要按照顺序安装完上面的安装包。再此输入labelImg,就像下面这样:

就会弹出如下的框框:

到此为止,labelImge就下载完成啦!!!下面说说这个软件怎么用吧!
二、labelImg的使用
1.labelImg界面介绍
其实labelImg就是把指定图片的指定区域打上标签,存储在xml文件中。首先了解下它的工作界面吧!
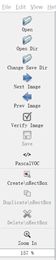
这里面我介绍部分工作键,因为我就用到了几个(嘿嘿,其他的我也不知道是干啥的~)
下面的格式就是图在上,描述在下。

open的作用就是打开一张图片,并且打开的图片会显示在中间的工作区,像下面这样:

open dir是为了方便批量处理,可以选择一个图片文件夹,选择之后,文件夹中图片列表都会在右下角File List显示,就像这样:


生成的xml文件总要需要一个保存的位置吧,就是通过这个设置保存路径的。

当以列表形式导入的时候,点这个更换下一张。

当以列表形式导入的时候,点这个回到上一张。

save保存当前生成的xml文件

需要框出指定区域,Create\nRectBox就是做这个的,Delete\nRectBox是删除框格(第二个的话,我也没用过,也不知道~)
2.做标签的方法
做标记也比较容易,按照前面框格的方法,选出指定区域。就会弹出下面的框:
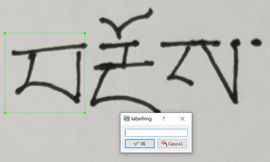
在框中输入你想做的标签名字就可以了。
3.常用快捷键
难道我几百张图片要一个一个点吗?那手不没了吗?当然了,labelImg有快捷键,可以加快我们的工作效率
1.ctrl+s 作用:保存生成的xml文件
2.w 作用:框矩形
3.d 作用:换下一张
4.a 作用:回到上一张4.注意:
在整个labelImg的使用的过程中,Anaconda prompt是不可以关闭的,里面会有文件的记录,像下面图这样:

其实这个软件的使用还是比较容易上手的,多多自己实践操作就很快掌握了。
这么复杂的的东西,我怎么可能直接会呢?自然少不了网上优秀资料的参考。感谢资料的上传者:
labelImg的安装:https://jingyan.baidu.com/article/5225f26ba428fee6fa090829.htmllink
labelImg的使用:https://blog.csdn.net/qq_34108714/article/details/89316097link
以上安装过程作者亲测有效,如有疑问之处可在下方评论区进行讨论交流。