2021-01-07
Python爬虫进阶之正则提取–宅男女神
文章目录
-
- Python爬虫进阶之正则提取--宅男女神
- 关于正则提取HTML
- 一、网站及分析
-
- 1.网站链接
- 2.使用requests请求获取网页源码
- 2.正则提取
- 3.图片地址分析及构造
- 网站的反扒--防盗链/重定向
- 二、图片下载保存
- 三、再加一个多线程
- 完整代码
- 总结
关于正则提取HTML
正则表达式作为一种通用的字符匹配,
应用于html的文本数据解析、提取还是十分的方便的。
同时python也内置re模块,来支持使用正则。
使用的时候只需要导入,即可import re
通常的匹配方法是re.findall()
匹配字符则需要使用万能的正则通配符(.*?)
匹配的模式选择re.S # 多行(跨行)匹配文本
impore re
html = html # html文档
text_list = re.findall('文本.*?文本(.*?)文本', html, re.S) # 匹配到的所有文本 返回一个列表
一、网站及分析
1.网站链接
[XIUREN] 2020.02.14 陆萱萱

2.使用requests请求获取网页源码
import requests
url = 'https://www.nvshens.org/g/32194/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'
}
response = requests(url=url, headers=headers)
html = response.text
2.正则提取
这里所要提取的信息(文本),包括专辑名称、图片张数、图片链接。
分别作为–要保存的文件夹名、和请求图片数据的url

path = re.findall('id="htilte">(.*?)', html, re.S)[0] # 文件夹名
page = re.findall(
r"(\d+).*", # 张数
html,
re.S)[0]
url = re.search('.alt='</span) , html).group()[10:-13] # 图片url
, html).group()[10:-13] # 图片url
3.图片地址分析及构造



通过查看分析,得出图片url的规律。
分为四种情况,0、>10、>100 和>10<100
通过if...elif...else来判断
def download(y):
if y == 0:
url1 = url + "0.jpg"
elif y < 10:
url1 = url + "00" + str(y) + ".jpg"
elif y >= 100:
url1 = url + str(y) + ".jpg"
else:
url1 = url + "0" + str(y) + ".jpg"
# print(url1)
网站的反扒–防盗链/重定向
经过大量的爬取测试,网站的部分专辑是有反扒的。其中通过浏览器开发者模式抓包分析,qq浏览器给的是专辑浏览页的url,谷歌浏览器的是主站(不得不是chrome好用)
这里选择主站就好,大部分的反盗链/referer都是主站

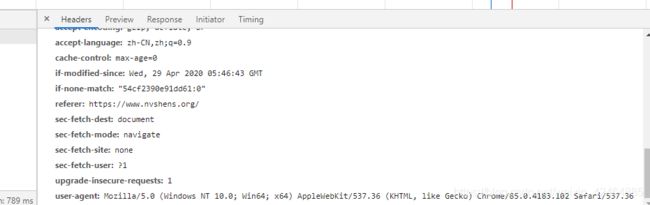
需要加到请求头里面
还有一个是请求是会报错需要设置在requests.get()参数里面allow_redirects=False 这个就是重定向
headers = {
'Referer': 'https://www.nvshens.org/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'
}
二、图片下载保存
首先创建文件夹
使用os模块 这两行可以当成模板,首先判断是否存在,不存在就创建
if not os.path.exists(path1):
os.mkdir(path1)
然后通过with...open.. 语句来保存 也是一个固定的格式
with open(path1 + str(y) + '.jpg', 'wb') as fp:
fp.write(img_data)
print('下载成功', str(y), '-----')
三、再加一个多线程
固定用法 要用到时直接复制
from multiprocessing.dummy import Pool
# 实例化线程池对象,开启了4个线程
pool = Pool(12) # 线程数量 不需要太多自己尝试,也可以不输/默认
pool.map(download, list1) # map函数里面 第一个参数是一个要执行的函数 第二个是函数的参数传入一个列表
pool.close() # 关闭
pool.join() # 等待主线程结束
完整代码
import re
import requests
import time
import os
from multiprocessing.dummy import Pool
html_url = 'https://www.nvshens.org/g/34642/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'
}
s = requests.Session()
html = s.get(html_url, headers=headers).text
print(html)
path = re.findall('id="htilte">(.*?)', html, re.S)[0]
page = re.findall(
r"(\d+).*",
html,
re.S)[0]
url = re.search(', html).group()[10:-13]
print(url)
path1 = './' + path + '/'
print(path1)
if not os.path.exists(path1):
os.mkdir(path1)
m = int(page)
list1 = []
headers = {
'Referer': 'https://www.nvshens.org/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'
}
def download(y):
if y == 0:
url1 = url + "0.jpg"
elif y < 10:
url1 = url + "00" + str(y) + ".jpg"
elif y >= 100:
url1 = url + str(y) + ".jpg"
else:
url1 = url + "0" + str(y) + ".jpg"
# print(url1)
img_data = s.get(url=url1, headers=headers, allow_redirects=False).content
start = time.time()
for i in range(0, m):
list1.append(i)
# 实例化线程池对象,开启了4个线程
pool = Pool(12)
pool.map(download, list1)
pool.close()
pool.join()
end = time.time()
print(end - start)
总结
项目总体难度不大,包括了很多爬虫及python基础。特别适合练练,自己也是尝试了很多的,完全是自己设计。后边有什么想法继续改进,包括TK应用已经实现。用于简单的爬虫练习还是可以的,当然也是波福利了。