用python实战excel和word自动化
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
python实现excel和word自动化--批量处理
- 前言--需求
-
- 快要期末了需要,提交一个年级的学生成绩数据,也就是几百份。当前我们收集了一份excel表格,它里面有学生的班级、姓名、成绩等信息。
- 问题1: 每个学生一个docx要 有不同的文件名,要把文件名为 班级+姓名 (图片未改)
- 问题2: 每个docx文件中 需要填写一些不一样的东西 比如 文件里要填写
- 二、答案来了,艾佛森来了。于是我编写程序运行后就解决了这个问题:生成了全年级的成绩,并且文件名也按照excel表格的内容有序命名,然后文件里的班级姓名也自动更改成功
-
- 1.首先复制了需要的份数 -- 就是拿到一个docx样本,然后进行批量复制,文件名可以相同,这里没有出来,只是让他复制和execl表格一样的份数。
- 2.读入数据:就是去读xlsx中的数据,代码我已经详细加了注释。这里需要注意xlrd==1.2.0 ,下载这个版本的,然后运行的时候还有一个地方要稍微改下代码,网上搜索一下即可。这里有个函数就是operator_docx,我放到后面讲解。这段代码的意思就是从xlsx取相应的几列数据(我们要的),给生成一个特定的文件名,然后拼接好,将旧的文件名改为新的。同时调用operator_docx()函数,把文件里的内容也替换掉。
- 3.operator_docx():是我自己写的一个函数,然后这里有很多注释,代表打开docx文件,然后可以小时docx的段落以及表格。可以帮助我去定位想要的修改的内容,我就是这样精准的找到了,想要替换的内容。因为传进来的参数刚好是要修改的,所有此函数我放在了rename_from_excel()中调用,减少了一定的计算开销,提升了性能。
- 二、完整代码如下
-
- 1.完整代码:
- 2.运行结果:而且里面的内容也已经全部正确,就是班级和姓名 和文件名一一对应。
- 总结-- 有些操作可以放这里,大家可以更好的根据自己的需求,去出来自己的docx,然后批量生成。
- 1. 打开docx,查看内容
- 2. 打开docx后,如何修改我想要修改的那部分内容呢??
- 3. 打开xlsx,如何获取想要的数据??
- 4. 写在最后:主要我也最近着急交一份数据,然后有感而发,写的这份代码,希望可以对大家有所作用,我觉得python真的是一个很好用的工具,前几天也用它登录12306抢票成功了呢,大家可以去我的主页看看。我想继续学下去,每天进步一点点!重剑无锋,大巧不工。
前言–需求
提示:这里可以添加本文要记录的大概内容:
快要期末了需要,提交一个年级的学生成绩数据,也就是几百份。当前我们收集了一份excel表格,它里面有学生的班级、姓名、成绩等信息。
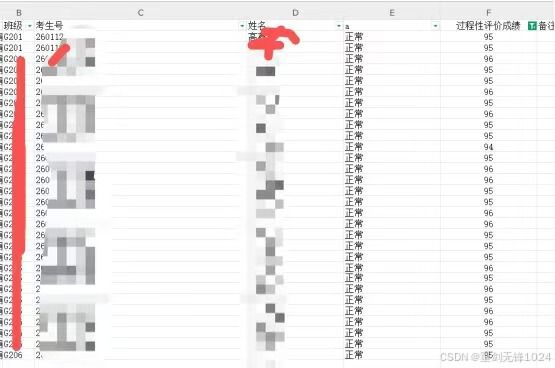
问题1: 每个学生一个docx要 有不同的文件名,要把文件名为 班级+姓名 (图片未改)
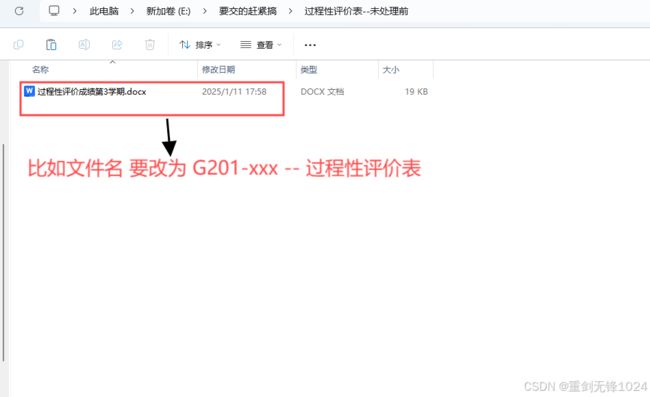
问题2: 每个docx文件中 需要填写一些不一样的东西 比如 文件里要填写
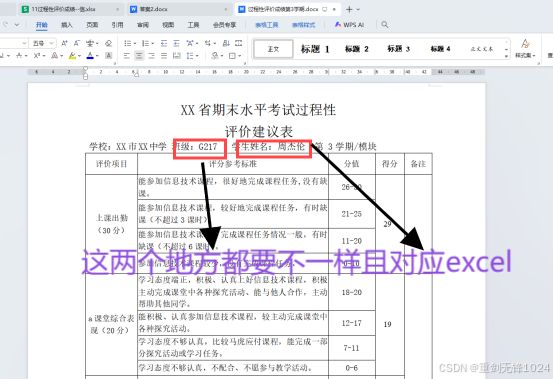
二、答案来了,艾佛森来了。于是我编写程序运行后就解决了这个问题:生成了全年级的成绩,并且文件名也按照excel表格的内容有序命名,然后文件里的班级姓名也自动更改成功
1.首先复制了需要的份数 – 就是拿到一个docx样本,然后进行批量复制,文件名可以相同,这里没有出来,只是让他复制和execl表格一样的份数。
def copy_files(original_file, num_copies):
# 获取原始文件的目录和文件名(不包括扩展名)
directory, file_base = os.path.split(original_file)
file_name, file_ext = os.path.splitext(file_base)
for i in range(1, num_copies + 1):
# 构建新文件名
new_file_name = f"{file_name}_copy{i}{file_ext}"
new_file_path = os.path.join(directory, new_file_name)
# 复制文件
shutil.copy2(original_file, new_file_path)
print(f"Copied to {new_file_path}")
if __name__ == "__main__":
# 指定要复制的文件路径
original_file_path = "E:\要交的赶紧搞\过程性评价表\G201-XXX.docx"
number_of_copies = 304
2.读入数据:就是去读xlsx中的数据,代码我已经详细加了注释。这里需要注意xlrd==1.2.0 ,下载这个版本的,然后运行的时候还有一个地方要稍微改下代码,网上搜索一下即可。这里有个函数就是operator_docx,我放到后面讲解。这段代码的意思就是从xlsx取相应的几列数据(我们要的),给生成一个特定的文件名,然后拼接好,将旧的文件名改为新的。同时调用operator_docx()函数,把文件里的内容也替换掉。
def rename_from_excel():
"""根据excel表格的内容批量修改文件名"""
# excel表格所在的位置
excel_path = r"E:\要交的赶紧搞\11过程性评价成绩--信.xlsx"
# 读取excel表:批量处理测试.xlsx
xlsx1 = xlrd.open_workbook(excel_path)
# 读取表格里第一个sheet(工作簿)
sheet = xlsx1.sheet_by_index(0)
# 获取表格第二列数据 -- 班级
class_list = list(sheet.col_values(1))
# 获取表格第四列数据 -- 姓名
name_list = list(sheet.col_values(3))
print(class_list)
print(name_list)
# 获取该文件夹下所有的文件(包括文件夹)
original_file_path = "E:\要交的赶紧搞\过程性评价表"
i = 0
file_names = os.listdir(original_file_path)
for file_name in file_names:
original_rename = os.path.join(original_file_path, file_name) # 获取所有文件的路径
directory, file_base = os.path.split(original_file_path)
file_name, file_ext = os.path.splitext(file_base)
print('original_rename',original_rename)
print('directory',directory)
print('file_base',file_base)
print('file_name',file_name)
print('file_ext',file_ext)
file_name = class_list[i] + '-' + name_list[i] + '-信息技术过程性评价成绩第3学期.docx'
new_file_path = os.path.join(original_file_path, file_name+file_ext)
print('new_file_path',new_file_path)
os.rename(original_rename, new_file_path)
operator_docx(new_file_path, class_list[i], name_list[i])
i = i + 1
3.operator_docx():是我自己写的一个函数,然后这里有很多注释,代表打开docx文件,然后可以小时docx的段落以及表格。可以帮助我去定位想要的修改的内容,我就是这样精准的找到了,想要替换的内容。因为传进来的参数刚好是要修改的,所有此函数我放在了rename_from_excel()中调用,减少了一定的计算开销,提升了性能。
def operator_docx(file_path,class_name, all_name):
"""自动化操作--docx"""
# 打开一个现有的Document对象
doc = Document(f'{file_path}')
# paras = list(doc.paragraphs)
# print('==============')
# 遍历所有段落并打印其内容
# for para in doc.paragraphs:
# print(para.text)
# print(doc.paragraphs[3].text)
doc.paragraphs[3].text = f'学校:XXX中学 班级:{class_name} 学生姓名:{all_name} 第 3学期/模块'
doc.save(f'{file_path}')
# print(type(para))
# print(type(paras))
# print('===========================')
# 遍历所有表格并打印其内容 -- 你可以去看看里面的内容
# for table in doc.tables:
# for row in table.rows:
# for cell in row.cells:
# print(cell.text, end='\t')
# print()
二、完整代码如下
1.完整代码:
import os
import shutil
import xlrd
from docx import Document
import pandas
def copy_files(original_file, num_copies):
# 获取原始文件的目录和文件名(不包括扩展名)
directory, file_base = os.path.split(original_file)
file_name, file_ext = os.path.splitext(file_base)
for i in range(1, num_copies + 1):
# 构建新文件名
new_file_name = f"{file_name}_copy{i}{file_ext}"
new_file_path = os.path.join(directory, new_file_name)
# 复制文件
shutil.copy2(original_file, new_file_path)
print(f"Copied to {new_file_path}")
def rename_from_excel():
"""根据excel表格的内容批量修改文件名"""
# excel表格所在的位置
excel_path = r"E:\要交的赶紧搞\11过程性评价成绩--信.xlsx"
# 读取excel表:批量处理测试.xlsx
xlsx1 = xlrd.open_workbook(excel_path)
# 读取表格里第一个sheet(工作簿)
sheet = xlsx1.sheet_by_index(0)
# 获取表格第二列数据 -- 班级
class_list = list(sheet.col_values(1))
# 获取表格第四列数据 -- 姓名
name_list = list(sheet.col_values(3))
print(class_list)
print(name_list)
# 获取该文件夹下所有的文件(包括文件夹)
original_file_path = "E:\要交的赶紧搞\过程性评价表"
i = 0
file_names = os.listdir(original_file_path)
for file_name in file_names:
original_rename = os.path.join(original_file_path, file_name) # 获取所有文件的路径
directory, file_base = os.path.split(original_file_path)
file_name, file_ext = os.path.splitext(file_base)
print('original_rename',original_rename)
print('directory',directory)
print('file_base',file_base)
print('file_name',file_name)
print('file_ext',file_ext)
file_name = class_list[i] + '-' + name_list[i] + '-信息技术过程性评价成绩第3学期.docx'
new_file_path = os.path.join(original_file_path, file_name+file_ext)
print('new_file_path',new_file_path)
os.rename(original_rename, new_file_path)
operator_docx(new_file_path, class_list[i], name_list[i])
i = i + 1
def operator_docx(file_path,class_name, all_name):
"""自动化操作--docx"""
# 打开一个现有的Document对象
doc = Document(f'{file_path}')
# paras = list(doc.paragraphs)
# print('==============')
# 遍历所有段落并打印其内容
# for para in doc.paragraphs:
# print(para.text)
# print(doc.paragraphs[3].text)
doc.paragraphs[3].text = f'学校:深圳市红岭教育集团大鹏华侨中学 班级:{class_name} 学生姓名:{all_name} 第 3学期/模块'
doc.save(f'{file_path}')
# print(type(para))
# print(type(paras))
# print('===========================')
# 遍历所有表格并打印其内容 -- 你可以去看看里面的内容
# for table in doc.tables:
# for row in table.rows:
# for cell in row.cells:
# print(cell.text, end='\t')
# print()
if __name__ == "__main__":
# 指定要复制的文件路径
original_file_path = "E:\要交的赶紧搞\过程性评价表\G201-蔡承君.docx"
number_of_copies = 304
# 1.批量复制文件
copy_files(original_file_path, number_of_copies)
# 2.用excel的行名得到想要的文件名 --> 自动化操作函数operator_docx
rename_from_excel()
2.运行结果:而且里面的内容也已经全部正确,就是班级和姓名 和文件名一一对应。
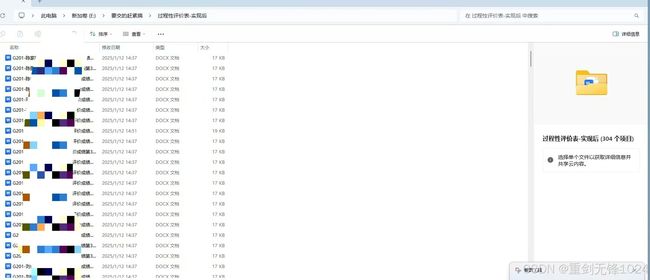
总结-- 有些操作可以放这里,大家可以更好的根据自己的需求,去出来自己的docx,然后批量生成。
1. 打开docx,查看内容
from docx import Document
# 打开一个现有的Document对象
doc = Document('demo.docx')
# 遍历所有段落并打印其内容
for para in doc.paragraphs:
print(para.text)
# 遍历所有表格并打印其内容
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
print(cell.text, end='\t')
print()
2. 打开docx后,如何修改我想要修改的那部分内容呢??
# 假设我们要修改第2个段落的内容
target_paragraph_index = 1 # 注意索引从0开始,所以第2个段落的索引是1
# 确保文档中有足够的段落
if len(doc.paragraphs) > target_paragraph_index:
# 修改第2个段落的内容
doc.paragraphs[target_paragraph_index].text = '这是新的段落内容。'
# 保存修改后的文档
doc.save('modified_by_index_example.docx')
3. 打开xlsx,如何获取想要的数据??
# excel表格所在的位置
excel_path = r"E:\要交的赶紧搞\11过程性评价成绩--信.xlsx"
# 读取excel表:批量处理测试.xlsx
xlsx1 = xlrd.open_workbook(excel_path)
# 读取表格里第一个sheet(工作簿)
sheet = xlsx1.sheet_by_index(0)
# 获取表格第二列数据 -- 班级
class_list = list(sheet.col_values(1))
# 获取表格第四列数据 -- 姓名
name_list = list(sheet.col_values(3))
print(class_list)
print(name_list)
# 获取该文件夹下所有的文件(包括文件夹)
original_file_path = "E:\要交的赶紧搞\过程性评价表"