基于Scrapy的链家二手房爬虫
摘要
本项目是python课程的期末练手项目,在简要学习完python和爬虫相关的Scrapy框架后,基于这两者的运用最终完成了对于链家网站二手房页面的信息进行爬取,并将爬取的数据存放于MongoDB之中,使用Studio 3T进行查看。
1引言
1.1背景
在本学期的python课程中,通过网课粗略的掌握了python的基础知识之后,老师提出通过运用python的模块进行附加的学习,于是我选择了Scrapy框架的学习,由此为基础对于链家网站的信息进行了爬取数据的操作,并将爬取的数据保存。
1.2意义
这个项目提高了我的python编程水平,使得我对于爬虫技术的了解更加深入,粗略掌握了如何使用Scrapy框架进行爬虫操作,懂得了python的附加模块的强大之处,也激发了继续学习编程的兴趣。
1.3相关研究
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。之前在基础学习的时候使用的是Python的request模块也能对网站页面的数据进行爬取,但是request属于页面级爬虫,重点在于页面下载,并发考虑不足,性能较差。
2.系统结构
该项目是基于Scrapy框架来进行的,因此整体的框架如图1所示。由于Scrapy本身封装了大量的内容操作使得代码编写者可以简化自己的代码量。由于大量的封装,在本次项目中只需要修改SPIDERS模块和ITEM PIPELINES模块。
SPIDERS模块是该项目的python模块。在此放入代码。它解析Downloader返回的响应(Response)产生爬取项(scraped item)。产生额外的爬取请求(Request)
ITEM PIPELINES模块,以流水线的方式处理Spider产生的爬取项。由一组操作顺序组成,类似流水线,每个操作都是一个item Pipeline类型。它的操作包括:清理、检验、和查重爬取的HTML数据、将数据存储到数据库。


3实现代码
3.1建立工程和Spider模板
scrapy startproject lianjia
建立名为lianjia的工程
scrapy genspider lianjiacrawl lianjia.com
创建一个名为lianjiacrawl的爬虫,搜索的域名范围是lianjia.com
3.2编写Spider
这一部分主要是配置lianjiacrawl.py文件,修改对返回页面的处理,修改对新增URL爬取请求的处理。首先通过对https://sz.lianjia.com/ershoufang/pg{}网页进行信息提取,获取每个二手房的详情链接网址,再通过yield关键字不断提取详情链接网址中的信息。这里信息的提取这里使用的是xpath。
通过游览器查看网页源代码可以详细去查看view-source:https://sz.lianjia.com/ershoufang/pg1/的代码,然后可以发现div class=“info clear”>
在通过游览器查看网页源代码可以详细去查看每个二手房的详情的源代码可知,二手房的详细信息在如下图所示的标签之中,使用xpath进行一一提取即可。


# -*- coding: utf-8 -*-
import scrapy
class LianjiacrawlSpider(scrapy.Spider):
name = 'lianjiacrawl'#这个爬虫的识别名称,必须是唯一的
allowed_domains = ['lianjia.com']#是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略
start_urls = ['https://sz.lianjia.com/ershoufang/pg{}/'.format(i) for i in range(1,100)]#要爬取的网址页面
def parse(self, response):#解析的方法,每个初始URL完成下载后将被调用
urls = response.xpath('//div[@class="info clear"]/div[@class="title"]/a/@href').extract()#获取每个二手房的详情链接网址,并保存在列表中
for url in urls:
yield scrapy.Request(url,callback=self.parse_info)#返回一个包含服务器资源的Response对象,由于用了yield,每次运行完函数才会接着产生下一个
def parse_info(self,response):
#extract_first():这个方法返回的是一个string字符串,是list数组里面的第一个字符串
total_price = response.xpath('concat(//span[@class="total"]/text(),//span[@class="unit"]/span/text())').extract_first()
#返回总价格
unit_price = response.xpath('string(//span[@class="unitPriceValue"])').extract_first()
#返回单价
residential_district = response.xpath('//a[contains(@class,"info")]/text()').extract_first()
#contains包含函数
#返回小区
district = response.xpath('string(//div[@class="areaName"]/span[@class="info"])').extract_first()
#返回所在区域
base1 = response.xpath('//div[@class="base"]//ul')
#返回基本信息的整个集合
apartment = base1.xpath('./li[1]/text()').extract_first()
#返回户型
floor = base1.xpath('./li[2]/text()').extract_first()
#返回楼层
area = base1.xpath('./li[3]/text()').extract_first()
#返回建筑面积
architecture =base1.xpath('./li[4]/text()').extract_first()
#返回户型结构
orientation = base1.xpath('./li[7]/text()').extract_first()
#返回朝向
renovation = base1.xpath('./li[9]/text()').extract_first()
#返回装修情况
tihu_ration = base1.xpath('./li[10]/text()').extract_first()
#返回梯户比例
property_right_year = base1.xpath('./li[last()]/text()').extract_first()
#配备电梯
base2 = response.xpath('//div[@class="transaction"]//ul')
#返回交易属性的整个集合
purpose = base2.xpath('./li[4]/span[2]/text()').extract_first()
#返回用途
property_right = base2.xpath('./li[6]/span[2]/text()').extract_first()
#返回产权所属
yield {
'总价': total_price,
'单价': unit_price,
'小区': residential_district,
'区域': district,
'户型': apartment,
'楼层': floor,
'面积': area,
'户型结构': architecture,
'朝向': orientation,
'装修情况': renovation,
'梯户比例': tihu_ration,
'产权年限': property_right_year,
'用途': purpose,
'产权所属': property_right,



3.2编写Pipelines
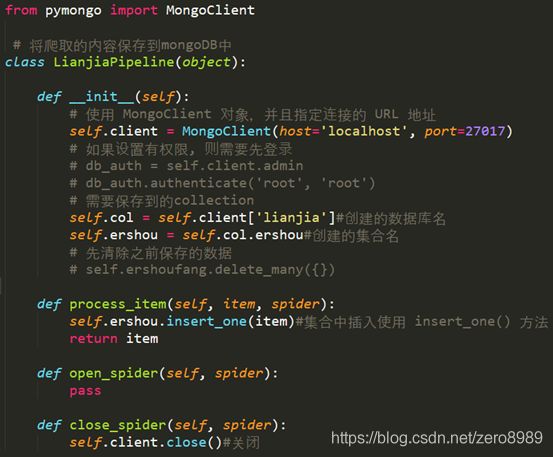
这一部分主要是配置pipelines.py文件,主要定义对LianjiaPipeline处理类以及通过setting.py文件配置ITEM_PIPLINES选项。这里主要是将爬取的数据放入MongoDB的数据库之中,首先连接本地的服务器,然后再创建数据库和集合,最后再将爬取的数据进行插入。
from pymongo import MongoClient
# 将爬取的内容保存到mongoDB中
class LianjiaPipeline(object):
def __init__(self):
# 使用 MongoClient 对象,并且指定连接的 URL 地址
self.client = MongoClient(host='localhost', port=27017)
# 如果设置有权限, 则需要先登录
# db_auth = self.client.admin
# db_auth.authenticate('root', 'root')
# 需要保存到的collection
self.col = self.client['lianjia']#创建的数据库名
self.ershou = self.col.ershou#创建的集合名
# 先清除之前保存的数据
# self.ershoufang.delete_many({})
def process_item(self, item, spider):
self.ershou.insert_one(item)#集合中插入使用 insert_one() 方法
return item
def open_spider(self, spider):
pass
def close_spider(self, spider):
self.client.close()#关闭
这里是setting.py要修改的部分,让框架能够找到我们在piplines中新建的类
ITEM_PIPELINES = {
‘lianjia.pipelines.LianjiaPipeline’: 300,
}

4.实验
4.1首先命令行下运行命令行下运行 MongoDB 服务器
为了从命令提示符下运行 MongoDB 服务器,你必须从 MongoDB 目录的 bin 目录中执行 mongod.exe 文件
mongod –dbpath \data\db

4.2然后使用Stdio 3T连接MongoDB服务器


4.3运行爬虫代码
scrapy crawl lianjiacrawl1

4.4查看数据库
在Studio 3T中查看数据库结果
5. 总结和展望
在这次Python语言程序设计课程的个人项目当中我对于爬虫有了更加深入的了解,主要是对于如何应用Scrapy框架从无到有到完成一个项目的有了整体的认识,有助于对于以后去尝试别的爬虫,在完成这个项目的过程中我也加强了自己的编程能力,对于Python这门语言有了更深刻的认识。这一个项目的完成也有一些不足的地方,对于已经爬取的数据没有进行图形化展示或者进行深入的数据分析,还是流于爬取这一过程,我希望在以后的学习过程中能对此进行完善。