Python数据可视化——Plotly绘制散点图、堆积柱状图、饼图、旭日图、分布图、箱线图、时间序列图、多子图、k线图
文章目录
-
- 一、数据来源
- 二、导入数据
- 三、散点图Scatter
- 四、堆积柱状图Stacked Bar
- 五、饼图
- 六、旭日图Sunburst
- 七、分布图Distplot
- 八、箱线图Boxplot
- 九、热点图Heatmap
- 十、.时间序列图 Time Series(使用时间序列选择器)
- 十一、多子图
- 十二、多图表Table and Chart Subplots
- 十三、k线图
- 十四、代码+数据集获取
一、数据来源
整理之前的代码,发现了之前使用plotly做数据可视化的代码,贴上来做个记录。
数据集为美国不同地区各个超市的不同商品的销量数据。
需要这份数据集的可以见文末的下载地址。
本文只列举了部分图形的可视化方法,更多的可以参看Plotly官方文档
二、导入数据
import pandas as pd
import plotly as py
import plotly.graph_objs as go
import numpy as np
data=pd.read_excel('Sample - Superstore.xls')
data.head()
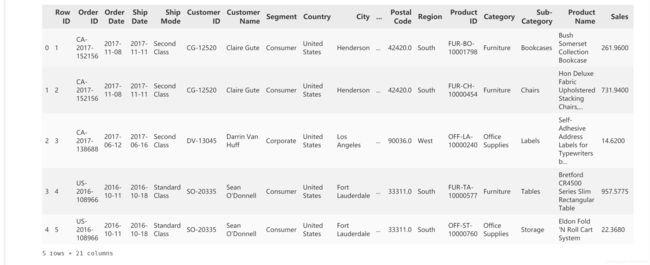
一共有21个特征值,具体的含义不做过多的描述,看字段名基本都能明白。
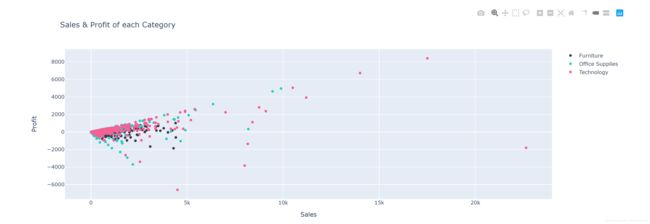
三、散点图Scatter
展示不同种类商品Category的售价Sales和利润Profit的关系
#Q1.散点图Scatter
#展示不同种类商品Category的售价Sales和利润Profit的关系
colors=['#393E46','#2BCDC2','#F66095']
labels=data['Category'].drop_duplicates(inplace=False)#获取种类数
X=[]
Y=[]
for i in labels:
X.append(data[data['Category']==i]['Sales'])
Y.append(data[data['Category']==i]['Profit'])
fig=go.Figure()
py.offline.init_notebook_mode()
for s,p,c,l in zip(X,Y,colors,labels):
fig.add_trace(go.Scatter(
x=s,
y=p,
mode='markers',
marker_color=c,
name=l
))
fig.update_layout(
title='Sales & Profit of each Category',
xaxis=dict(title='Sales'),
yaxis=dict(title='Profit'),)
py.offline.iplot(fig)
四、堆积柱状图Stacked Bar
#Q2.堆积柱状图Stacked Bar
#展示不同商品子类的Sub-Category中不同客户类别Segment的利润总和
data2=data.groupby(['Segment','Sub-Category'])['Profit'].sum()
fig=go.Figure()
for sg,cl in zip(data2.index.levels[0],colors):
fig.add_trace(
go.Bar(
x=data2[sg].index,
y=data2[sg].values,
name=sg,
marker=dict(color=cl,opacity=0.65)
)
)
fig.update(layout=dict(
title='Profit by Sub-Category & Segment',
xaxis=dict(title='Sub-Category'),
yaxis=dict(title='Profit'),
barmode='stack',
))
py.offline.iplot(fig)

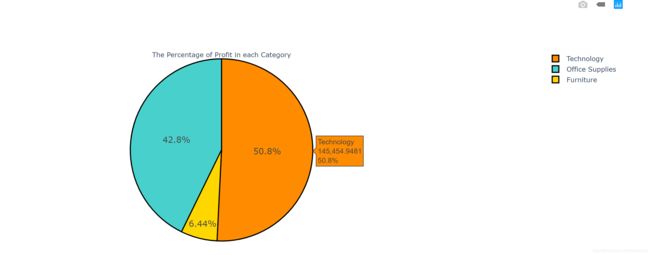
五、饼图
展示不同商品类的Category利润Profit占比
#Q3.饼图
#展示不同商品类的Category利润Profit占比
colors = ['gold', 'mediumturquoise', 'darkorange', 'lightgreen']
data3=data.groupby(['Category'])['Profit'].sum()
fig = go.Figure(data=[
go.Pie(
labels=data3.index,
values=data3)
])
fig.update_traces(
title='The Percentage of Profit in each Category',
hoverinfo='label+percent+value',
textfont_size=15,
marker=dict(colors=colors, line=dict(color='#000000', width=2)))
py.offline.iplot(fig)
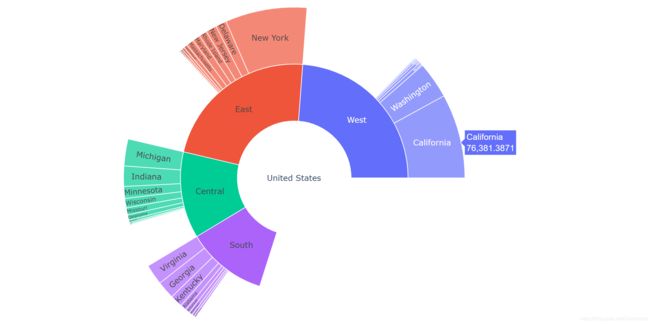
六、旭日图Sunburst
展现美国各个地区Region各个州State的利润情况
#Q4.旭日图Sunburst
#展现美国各个地区Region各个州State的利润情况
Labels=['United States','South','West','East','Central']
Region=['South','West','East','Central']
Parents=['','United States','United States','United States','United States']
data4=data[['Region','State','Profit']]
data4_1=np.array(data4)
Values=[data4['Profit'].sum(),
data4[data4['Region']=='South']['Profit'].sum(),
data4[data4['Region']=='West']['Profit'].sum(),
data4[data4['Region']=='East']['Profit'].sum(),
data4[data4['Region']=='Central']['Profit'].sum()
]
for i in data4_1:
if i[1] not in Labels:
Labels.append(i[1])
Parents.append(i[0])
Values.append(data4[data4['State']==i[1]]['Profit'].sum())
fig=go.Figure(
go.Sunburst(
labels=Labels,
parents=Parents,
values=Values,
))
fig.update_layout(
margin = dict(t=1, l=1, r=1, b=10)
)
py.offline.iplot(fig)
七、分布图Distplot
展现商品类别Category的质量Quantity分布情况
#Q5.分布图Distplot
#展现商品类别Category的质量Quantity分布情况
import plotly.figure_factory as ff
Category=data['Category'].drop_duplicates(inplace=False).tolist()
# Add histogram data
x1 =data[data['Category']==Category[0]]['Quantity']
x2 = data[data['Category']==Category[1]]['Quantity']
x3 = data[data['Category']==Category[2]]['Quantity']
# Group data together
hist_data = [x1, x2, x3]
group_labels = Category
# Create distplot with custom bin_size
fig = ff.create_distplot(hist_data, group_labels, bin_size=[.1, .25, .5])
fig.update(layout=dict(
title='The Quanlity of Each Category ',
))
py.offline.iplot(fig)
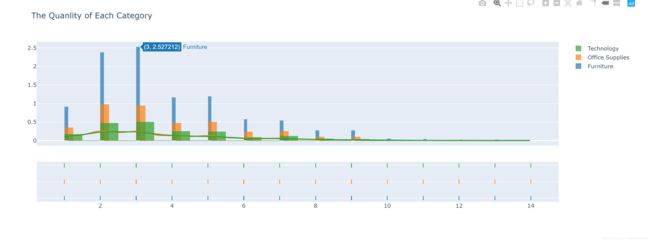
八、箱线图Boxplot
展现商品类别Category的折扣Discount分布情况
#Q6.箱线图Boxplot
#展现商品类别Category的折扣Discount分布情况
fig = go.Figure()
for i in Category:
fig.add_trace(go.Box(
y=data[data['Category']==i]['Discount'],
name=i))
fig.update(layout=dict(
title='Dicount Distribution ',
))
py.offline.iplot(fig)
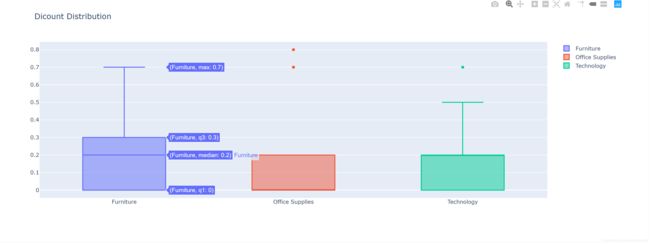
九、热点图Heatmap
展现商品类别Category在不同地区Region的利润Profit的相关性
#Q7.热点图Heatmap
#展现商品类别Category在不同地区Region的利润Profit的相关性
Z=[]
for i in Category:
Y=[]
data_0=data[data['Category']==i]
for j in Region:
Y.append(data_0[data_0['Region']==j]['Profit'].sum())
Z.append(Y)
fig = go.Figure(data=go.Heatmap(
z=Z,
x=Region,
y=Category,
hoverongaps = False))
fig.update(layout=dict(
title='Profit in Different Regions of Three Categories ',
))
py.offline.iplot(fig)

十、.时间序列图 Time Series(使用时间序列选择器)
展现各个年份每月的利润Profit情况。底部的时间序列选择器可以通过拖动展示指定时间区间的数据。
#Q9 .时间序列图 Time Series(使用时间序列选择器)
#展现各个年份每月的利润Profit情况
fig = go.Figure()
for value,year,color in zip(Y,Year,colors):
fig.add_trace(go.Scatter(
x=Month,
y=value,
name=year,
line_color=color))
fig.update_layout(
title_text='Time Series with Rangeslider',
xaxis=dict(title='Month'),
yaxis=dict(title='Profit'),
xaxis_rangeslider_visible=True)
py.offline.iplot(fig)

十一、多子图
各个商品子类Sub-Category的利润Profit
#Q10.多子图Subplots
#各个商品子类Sub-Category的利润Profit
fig = go.Figure()
trace1 = go.Bar(
x=data2[sg].index,
y=data.groupby(['Sub-Category'])['Sales'].sum(),
name='Sales'
)
trace2 = go.Scatter(
x=data2[sg].index,
y=data.groupby(['Sub-Category'])['Profit'].sum(),
name='Profit',
xaxis='x',
)
data = [trace1, trace2]
layout = go.Layout(
title='Profit & Sales of each Sub-Category',
yaxis2=dict(anchor='x', overlaying='y', side='right')#设置坐标轴的格式,一般次坐标轴在右侧
)
fig=go.Figure(data=data,layout=layout)
py.offline.iplot(fig)
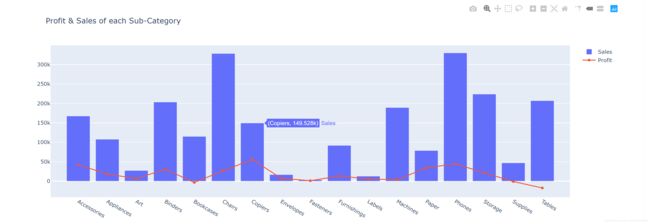
十二、多图表Table and Chart Subplots
表格展现订单时间Order Date销售的物品名称Product Name以及对应的利润Profit
#Q11.多图表Table and Chart Subplots
#表格展现订单时间Order Date销售的物品名称Product Name以及对应的利润Profit
from plotly.subplots import make_subplots
data11=data[['Order Date','Product Name','Profit']]
va=data11.sort_values('Order Date')
fig = make_subplots(
rows=2, cols=1,
shared_xaxes=True,
vertical_spacing=0.03,
specs=[[{
"type": "table"}],
[{
"type": "scatter"}]]
)
fig.add_trace(
go.Scatter(
x=va["Order Date"],
y=va["Profit"],
mode="lines",
name="hash-rate-TH/s"
),
row=2, col=1
)
fig.add_trace(
go.Table(
header=dict(
values=['Order ID','Product Name','Profit'],
font=dict(size=10),
align="left"
),
cells=dict(
values=[va[k].tolist() for k in va.columns],
align = "left")
),
row=1, col=1
)
fig.update_layout(
height=800,
showlegend=False,
title_text="Profits from 2015 to 2018",
xaxis=dict(title='Year'),
yaxis=dict(title='Profit'),
)
fig.show()
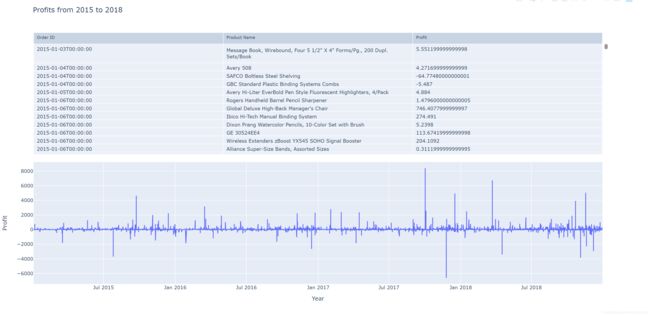
十三、k线图
十四、代码+数据集获取
关注以下公众号回复"0040"即可get√
