大数据之路:阿里巴巴大数据实践
文章目录
- 第1章:总述
- 第2章:日志采集
-
- 2.1 浏览器的页面日志采集
-
- 2.1.1 页面浏览日志采集流程
- 2.1.2 页面交互日志采集
- 2.1.3 页面日志的服务器端清洗和预处理
- 2.2 无线客户端的日志采集
-
- 2.2.1 页面事件
- 2.2.2 控件点击及其他事件
- 2.2.3 特殊场景
- 2.2.4 H5 & Native日志统一
- 2.2.5 设备标识
- 2.2.6 日志传输
- 2.3 日志采集的挑战
-
- 2.3.1 典型场景
- 2.3.2 大促保障
- 第3章:数据同步
-
- 3.1 数据同步基础
-
- 3.1.1 直连同步
- 3.1.2 数据文件同步
- 3.1.3 数据库日志解析同步
- 3.2 阿里数据仓库的同步方式
-
- 3.2.1 批量数据同步
- 3.2.2 实时数据同步
- 3.3 数据同步遇到的问题与解决方案
-
- 3.3.1 分库分表的处理
- 3.3.2 高效同步和批量同步
- 3.3.3 增量与全量同步的合并
- 3.3.4 同步性能的处理
- 3.3.5 数据漂移的处理
- 第4章:离线数据开发
-
- 4.1 数据开发平台
-
- 4.1.1 统一计算平台
- 4.1.2 统一开发平台
- 4.2 任务调度系统
-
- 4.2.1 背景
- 4.2.2 介绍
- 4.2.3 特点及应用
- 第5章:实时技术
-
- 5.1 简介
- 5.2 流式技术架构
-
- 5.2.1 数据采集
- 5.2.2 数据处理
- 5.2.3 数据存储
- 5.2.4 数据服务
- 5.3 流式数据模型
-
- 5.3.1 数据分层
- 5.3.2 多流关联
- 5.3.3 维表使用
- 5.4 大促挑战&保障
-
- 5.4.1 大促特征
- 5.4.2 大促保障
- 第6章:数据服务
-
- 6.1 服务架构演进
-
- 6.1.1 DWSOA
- 6.1.2 OpenAPI
- 6.1.3 SmartDQ
- 6.1.4 统一的数据服务层
- 6.2 技术架构
-
- 6.2.1 SmartDQ
- 6.2.2 iPush
- 6.2.3 Lego
- 6.2.4 uTiming
- 6.3 最佳实践
-
-
- 6.3.1 性能
- 6.3.2 稳定性
-
- 第7章:数据挖掘
-
- 7.1 数据挖掘概述
- 7.2 数据挖掘算法平台
- 7.3 数据挖掘中台体系
-
- 7.3.1 挖掘数据中台
- 7.3.2 挖掘算法中台
- 7.4 数据挖掘案例
-
- 7.4.1 用户画像
- 7.4.2 互联网反作弊
- 第8章:大数据领域建模综述
-
- 8.1 为什么需要数据建模
- 8.2 关系数据库系统和数据仓库
- 8.3 从OLTP和OLAP系统的区别看模型方法论的选择
- 8.4 典型的数据仓库建模方法论
-
- 8.4.1 ER模型
- 8.4.2 维度模型
- 8.4.3 Data Vault模型
- 8.4.4 Anchor 模型
- 8.5 阿里巴巴数据模型实践综述
- 第9章:阿里巴巴数据整合及管理体系
-
- 9.1 概述
-
- 9.1.1 定位及价值
- 9.1.2 体系架构
- 9.2 规范定义
-
- 9.2.1 名词术语
- 9.2.2 指标体系
- 9.3 模型设计
-
- 9.3.1 指导理论
- 9.3.2 模型层次
- 9.3.3 基本原则
- 9.4 模型实施
-
- 9.4.1 业界常用的模型实施过程
-
- 1. Kimball模型实施过程
- 2. Inmon 模型实施过程
- 3. 其他模型实施过程
- 9.4.2 OneData实施过程
- 第10章:维度设计
-
- 10.1 维度设计基础
-
- 10.1.1 维度的基本概念
- 10.1.2 维度的基本设计方法
- 10.1.3 维度的层次结构
- 10.1.4 规范化和反规范化
- 10.1.5 一致性维度和交叉探查
- 10.2 维度设计高级主题
-
- 10.2.1 维度整合
- 10.2.2 水平拆分
- 10.2.3 垂直拆分
- 10.2.4 历史归档
- 10.3 维度变化
-
- 10.3.1 缓慢变化维
- 10.3.2 快照维表
- 10.3.3 极限存储
- 10.3.4 微型维度
- 10.4 特殊维度
-
- 10.4.1 递归层次
- 10.4.2 行为维度
- 10.4.3 多值维度
- 10.4.4 多值属性
- 10.4.5 杂项维度
- 第11章:事实表设计
-
- 11.1 事实表基础
-
- 11.1.1 事实表特性
- 11.1.2 事实表设计原则
- 11.1.3 事实表设计方法
- 11.2 事务事实表
-
- 11.2.1 设计过程
- 11.2.2 单事务事实表
- 11.2.3 多事务事实表
- 11.2.4 两种事实表对比
- 11.2.5 父子事实的处理方式
- 11.2.6 事实的设计准则
- 11.3 周期快照事实表
-
- 11.3.1 特性
- 11.3.2 实例
- 11.3.3 注意事项
- 11.4 累积快照事实表
-
- 11.4.1 设计过程
- 11.4.2 特点
- 11.4.3 特殊处理
- 11.4.4 物理实现
- 11.5 三种事实表的比较
- 11.6 无事实的事实表
- 11.7 聚集型事实表
-
- 11.7.1 聚集的基本原则
- 11.7.2 聚集的基本步骤
- 11.7.3 阿里公共汇总层
- 11.7.4 聚集补充说明
- 第12章:元数据
-
- 12.1 元数据概述
-
- 12.1.1 元数据定义
- 12.1.2 元数据价值
- 12.1.3 统一元数据体系建设
- 12.2 元数据应用
-
- 12.2.1 Data Profile
- 12.2.2 元数据门户
- 12.2.3 应用链路分析
- 12.2.4 数据建模
- 12.2.5 驱动ETL开发
- 第13章:计算管理
-
- 13.1 系统优化
-
- 13.1.1 HBO
- 13.1.2 CBO
- 13.2 任务优化
-
- 13.2.1 Map 倾斜
- 13.2.2 Join 倾斜
- 13.2.3 Reduce 倾斜
- 第14章:存储和成本管理
-
- 14.1 数据压缩
- 14.2 数据重分布
-
- 14.3 存储治理项优化
- 14.4 生命周期管理
-
- 14.4.1 生命周期管理策略
- 14.4.2 通用的生命周期管理矩阵
- 14.5 数据成本计量
- 14.6 数据使用计费
- 第15章:数据质量
-
- 15.1 数据质量保障原则
- 15.2 数据质量方法概述
-
- 15.2.1 消费场景知晓
- 15.2.2 数据加工过程卡点校验
- 15.2.3 风险点监控
- 15.2.4 质量衡量
- 第16章:数据应用
-
- 16.1 生意参谋
-
- 16.1.1 背景概述
- 16.1.2 功能架构与技术能力
- 16.1.3 商家应用实践
- 16.2 对内数据产昂平台
-
- 16.2.1 定位
- 16.2.2 产品建设历程
- 16.2.3 整体架构介绍
第1章:总述
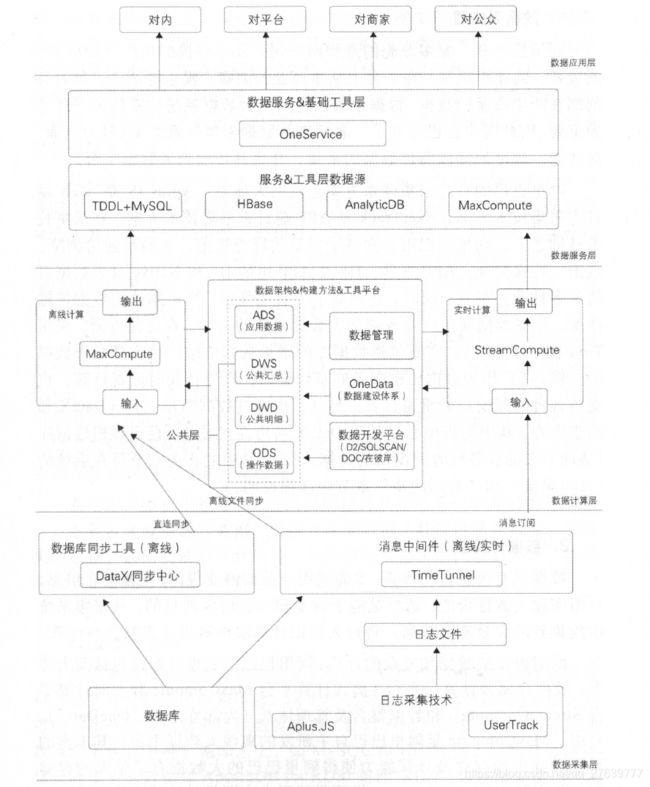
如果说在IT时代是以自我控制、自我管理为主,那么到了DT(Data Technology)时代,则是以服务大众、激发生产力为主。阿里巴巴大数据系统体系架构主要分为数据采集、数据计算、数据服务和数据应用四大层次。
第2章:日志采集
阿里巴巴的日志采集体系方案包括两大体系:Aplus.JS是Web端(基于浏览器)日志采集技术方案:UserTrack是APP端(无线客户端)日志采集技术方案。
2.1 浏览器的页面日志采集
浏览器的页面型产品/服务的日志采集可分为如下两大类。
- 页面浏览(展现)日志采集。
- 页面交互日志采集。
2.1.1 页面浏览日志采集流程
在HTML文档内增加一个日志采集节点,当浏览器解析时将自动触发一个特定的HTTP请求到日志采集服务器。主要过程如下:
- 客户端日志采集。在HTML文档内植入日志采集脚本的动作可以由业务服务器在响应业务请求时动态执行,也可以在开发页面时由开发人员手动植入。
- 客户端日志发送。采集脚本执行时,会发起一个日志请求,以将采集到的数据发送到日志服务器。
- 服务器端日志收集。日志服务器接收到请求后,立即向浏览器发回一个请求成功的响应,以免对页面的正常加载造成影响。
- 服务器端日志解析存档。服务器接收到的浏览日志进人缓冲区后,会被一段专门的日志处理程序顺序读出并按照约定的日志处理逻辑解析。
阿里巴巴的页面浏览日志采集框架,不仅指定了上述的采集技术方案,同时也规定了PV日志的采集标准规范,其中规定了PV日志应采集和可采集的数据项,并对数据格式做了规定。
2.1.2 页面交互日志采集
在阿里巴巴,通过一套名为“黄金令箭”的采集方案来解决交互日志的采集问题。“黄金令箭”是一个开放的基于HTTP协议的日志服务,采集步骤如下。
- 业务方在“黄金令箭”的元数据管理界面依次注册需要采集交互日志的业务、具体的业务场景以及场景下的具体交互采集点,在注册完成之后,系统将生成与之对应的交互日志采集代码模板。
- 业务方将交互日志采集代码植入目标页面,并将采集代码与需要监测的交互行为做绑定。
- 当用户在页面上产生指定行为时,采集代码和正常的业务互动响应代码一起被触发和执行。
- 采集代码在采集动作完成后将对应的日志通过HTTP协议发送到日志服务器,日志服务器接收到日志后,对于保存在HTTP请求参数部分的自定义数据,即用户上传的数据,原则上不做解析处理,只做简单的转储。
2.1.3 页面日志的服务器端清洗和预处理
在大部分场合下,经过上述解析处理之后的日志并不直接提供给下游使用,一般还需要进行相应的离线预处理。
- 识别流量攻击、网络爬虫和流量作弊(虚假流量)。
- 数据缺项补正。
- 无效数据剔除。
- 日志隔离分发。
2.2 无线客户端的日志采集
在阿里巴巴内部,多使用名为UserTrack的SDK来进行无线客户端的日志采集。UserTrack(UT)把事件分成了几类,常用的包括页面事件和控件点击事件等。
2.2.1 页面事件
每条页面事件日志记录三类信息:①设备及用户的基本信息;②被访问页面的信息;③访问基本路径。UT提供了透传参数功能,即把当前页面的某些信息,传递到下一个页面甚至下下一个页面的日志中。
2.2.2 控件点击及其他事件
交互类的行为呈现出高度自定义的业务特征,因此UT提供了一个自定义埋点类,其包括:①事件名称;②事件时长;③事件所携带的属性;④事件对应的页面。UT还提供了一些默认的日志采集方法,比如可以自动捕获应用崩溃,并且产生一条日志记录崩溃相关信息。
2.2.3 特殊场景
随着业务的不断发展,业务的复杂性不断提高,采集需要处理的特殊场景也层出不穷。比如,为了平衡日志大小,减小流量消耗、采集服务器压力、网络传输压力等,采集SDK提供了聚合功能。
2.2.4 H5 & Native日志统一
考虑到后续日志数据处理的便捷性、计算成本、数据的合理性及准确性,我们需要对Native和H5日志进行统一处理。在阿里巴巴集团,我们选择Native部署采集SDK的方式。原因有二: 一是采用采集SDK可以采集到更多的设备相关数据;二是采集SDK处理日志,会先在本地缓存,而后借机上传,在网络状况不佳时延迟上报,保证数据不丢失。具体的流程如下:
- H5页面浏览和页面交互的数据,在执行时通过加载日志采集的JavaScript脚本,采集当前页面参数,包括浏览行为的上下文信息以及一些运行环境信息。
- 在浏览器日志采集的JavaScript脚本中实现将所采集的数据打包到一个对象中,然后调用Web View框架的JSBridge接口,调用移动客户端对应的接口方法,将埋点数据对象当作参数传入。
- 移动客户端日志采集SDK,封装提供接口,实现将传入的内容转换成移动客户端日志格式。
2.2.5 设备标识
互联网产品的基本指标访客数(Unique Visitors, UV),对于登录用户,可以使用用户ID来进行唯一标识,但是很多日志行为并不要求用户登录。PC端一般使用Cookie信息来作为设备的唯一信息。阿里巴巴集团无线设备唯一标识使用UTDID,就是每台设备一个ID作为唯一标识。
2.2.6 日志传输
无线客户端日志的上传,不是产生一条日志上传一条,而是无线客户端产生日志后,先存储在客户端本地,然后再伺机上传。服务器端处理上传请求,对请求进行相关校验,将数据追加到本地文件中进行存储,存储方式使用Nginx的access_log, access_log的切分维度为天,即当天接收的日志存储到当天的日志文件中。阿里巴巴集团主要使用消息队列(TimeTunel, TT)来实现从日志采集服务器到数据计算的MaxCompute。
2.3 日志采集的挑战
各类采集方案提供者所面临的主要挑战是如何实现日志数据的结构化和规范化组织,实现更为高效的下游统计计算,提供符合业务特性的数据展现,以及为算法提供更便捷、灵活的支持等方面。
2.3.1 典型场景
- 日志分流与定制处理:在日志解析和处理过程中必须考虑业务分流、日志优先级控制,以及根据业务特点实现定制处理。通过尽可能靠前地布置路由差异,就可以尽可能早地进行分流,降低日志处理过程中的分支判断消耗,并作为后续的计算资源调配的前提,提高资源利用效率。
- 采集与计算一体化设计:要求日志采集方案必须将来集与计算作为一个系统来考量,进行一体化设计。目前阿里已成功实现规范制定一元数据注册一日志采集一自动化计算一可视化展现全流程的贯通。
2.3.2 大促保障
首先,端上实现了服务器端推送配置到客户端,且做到高到达率;其次,对日志做了分流,结合日志的重要程度及各类日志的大小,实现了日志服务器端的拆分;最后,在实时处理方面,也做了不少的优化以提高应用的吞吐量。
第3章:数据同步
不同系统间的数据流转。
3.1 数据同步基础
同步方式可以分为三种:直连同步、数据文件同步和数据库日志解析同步。
3.1.1 直连同步
直连同步是指通过定义好的规范接口API和基于动态链接库的方式直接连接业务库。这种方式配置简单,实现容易,比较适合操作型业务系统的数据同步。但是业务库直连的方式对源系统的性能影响较大,虽然可以从备库抽取数据,但是当数据量较大时,采取此种抽取方式性能较差,不太适合从业务系统到数据仓库系统的同步。
3.1.2 数据文件同步
数据文件同步通过约定好的文件编码、大小、格式等,直接从源系统生成数据的文本文件,由专门的文件服务器,如FTP服务器传输到目标系统后,加载到目标数据库系统中。当数据源包含多个异构的数据库系统(如MySQL、Oracle、SQL Server、DB2 等)时,用这种方式比较简单、实用。
为了确保数据文件同步的完整性,通常除了上传数据文件本身以外,还会上传一个校验文件,以供下游目标系统验证数据同步的准确性。另外,在从源系统生成数据文件的过程中,可以增加压缩和加密功能,传输到目标系统以后,再对数据进行解压缩和解密, 这样可以大大提高文件的传输效率和安全性。
3.1.3 数据库日志解析同步
解析日志文件这种读操作是在操作系统层面完成的,不需要通过数据库,因此不会给源系统带来性能影响。然后可通过网络协议,实现源系统和目标系统之间的数据文件传输。数据文件被传输到目标系统后,可通过数据加载模块完成数据的导入,从而实现数据从源系统到目标系统的同步。
数据库日志解析同步方式实现了实时与准实时同步的能力,延迟可以控制在毫秒级别,并且对业务系统的性能影响也比较小,目前广泛应用于从业务系统到数据仓库系统的增量数据同步应用之中。通过数据库日志解析进行同步的方式性能好、效率高,对业务系统的影响较小。但是它也存在如下一些问题:
- 数据延迟。例如,业务系统做批量补录可能会使数据更新量超出系统处理峰值,导致数据延迟。
- 投入较大。采用数据库日志抽取的方式投入较大,需要在源数据库与目标数据库之间部署一个系统实时抽取数据。
- 数据漂移和遗漏。数据漂移,一般是对增量表而言的,通常是指该表的同一个业务日期数据中包含前一天或后一天凌晨附近的数据或者丢失当天的变更数据。
3.2 阿里数据仓库的同步方式
3.2.1 批量数据同步
对于离线类型的数据仓库应用,需要将不同的数据源批量同步到数据仓库,以及将经过数据仓库处理的结果数据定时同步到业务系统。阿里巴巴的DataX就是这样一个能满足多方向高自由度的异构数据交换服务产品。对于不同的数据源,DataX 通过插件的形式提供支持,将数据从数据源读出并转换为中间状态,同时维护好数据的传输、缓存等工作。数据在DataX中以中间状态存在,并在目标数据系统中将中间状态的数据转换为对应的数据格式后写入。
DataX采用Framework + Plugin的开放式框架实现,Framework处理缓冲、流程控制、并发、上下文加载等高速数据交换的大部分技术问题,并提供简单的接口与插件接入。插件仅需实现对数据处理系统的访问,编写方便,开发者可以在极短的时间内开发一个插件以快速支持新的数据库或文件系统。数据传输在单进程(单机模式)/多进程(分布式模式)下完成,传输过程全内存操作,不读写磁盘,也没有进程间通信,实现了在异构数据库或文件系统之间的高速数据交换。
3.2.2 实时数据同步
建立一个日志数据交换中心,通过专门的模块从每台服务器源源不断地读取日志数据,或者解析业务数据库系统的binlog或归档日志,将增量数据以数据流的方式不断同步到日志交换中心,然后通知所有订阅了这些数据的数据仓库系统来获取。
阿里巴巴的TimeTunnel(TT)是一种基于生产者、消费者和Topic消息标识的消息中间件,将消息数据持久化到HBase的高可用、分布式数据交互系统。Time Tunnel支持主动、被动等多种数据订阅机制,订阅端自动负载均衡,消费者自己把握消费策略。对于读写比例很高的Topic,能够做到读写分离,使消费不影响发送。同时支持订阅历史数据,可以随意设置订阅位置,方便用户回补数据。
3.3 数据同步遇到的问题与解决方案
3.3.1 分库分表的处理
阿里巴巴的TDDL (Taobao Distributed Data Layer)就是这样一个分布式数据库的访问引擎,通过建立中间状态的逻辑表来整合统一分库分表的访问。TDDL是在持久层框架之下、JDBC驱动之上的中间件,它与JDBC规范保持一致,有效解决了分库分表的规则引擎问题,实现了SQL解析、规则计算、表名替换、选择执行单元并合并结果集的功能,同时解决了数据库表的读写分离、高性能主备切换的问题,实现了数据库配置信息的统一管理。
3.3.2 高效同步和批量同步
阿里巴巴数据仓库研发了OneClick产品,真正实现了数据的一键化和批量化同步,一键完成DDL和DML的生成、数据的冒烟测试以及在生产环境中测试等。
- 对不同数据源的数据同步配置透明化,可以通过库名和表名唯一定位,通过IDB接口获取元数据信息自动生成配置信息。
- 简化了数据同步的操作步骤,实现了与数据同步相关的建表、配置任务、发布、测试操作一键化处理,并且封装成Web接口进一步达到批量化的效果。
- 降低了数据同步的技能门槛,让数据需求方更加方便地获取和使用数据。
IDB是阿里巴巴集团用于统一管理MySQL、OceanBase、PostgreSQL、Oracle、SQL Server等关系型数据库的平台,它是一种集数据管理、结构管理、诊断优化、实时监控和系统管理于一体的数据管理服务;在对集团数据库表的统一管理服务过程中,IDB产出了数据库、表、字段各个级别元数据信息,并且提供了元数据接口服务。
3.3.3 增量与全量同步的合并
每次只同步新变更的增量数据,然后与上一个同步周期获得的全量数据进行合井,从而获得最新版本的全量数据。我们比较推荐的方式是全外连接( full outer join) + 数据全量覆盖重新加载(insert overwrite)。如果担心数据更新错误问题,可以采用分区方式,每天保持一个最新的全量版本,保留较短的时间周期。
3.3.4 同步性能的处理
阿里巴巴数据团队实践出了一套基于负载均衡思想的新型数据同步方案。该方案的核心思想是通过目标数据库的元数据估算同步任务的总线程数,以及通过系统预先定义的期望同步速度估算首轮同步的线程数,同时通过数据同步任务的业务优先级决定同步线程的优先级,最终提升同步任务的执行效率和稳定性。具体实现步骤如下:
- 用户创建数据同步任务,并提交该同步任务。
- 根据系统提前获知及设定的数据,估算该同步任务需要同步的数据量、平均同步速度、首轮运行期望的线程数、需要同步的总线程数。
- 根据需要同步的总线程数将待同步的数据拆分成相等数量的数据块,一个线程处理一个数据块,并将该任务对应的所有线程提交至同步控制器。
- 同步控制器判断需要同步的总线程数是否大于首轮运行期望的线程数,若大于,则跳转至2 若不大于,则跳转至下一步。
- 同步控制器采用多机多线程的数据同步模式,准备该任务第一轮线程的调度,优先发送等待时间最长、优先级最高且同一任务的线程。
- 同步控制器准备一定数据量(期望首轮线程数-总线程数)的虚拟线程,采用单机多线程的数据同步模式,准备该任务相应实体线程和虚拟线程的调度,优先发送等待时间最长、优先级最高且单机CPU剩余资源可以支持首轮所有线程数且同一任务的线程,如果没有满足条件的机器,则选择CPU剩余资源最多的机器进行首轮发送。
- 数据任务开始同步,并等待完成。
- 数据任务同步结束。
3.3.5 数据漂移的处理
数据漂移通常是指ODS表的同一个业务日期数据中包含前一天或后一天凌晨附近的数据或者丢失当天的变更数据。处理方法主要有以下两种:
- 多获取后一天的数据:在ODS每个时间分区中向前、向后多冗余一些数据,保障数据只会多不会少,而具体的数据切分让下游根据自身不同的业务场景用不同的业务时间proc_time来限制。
- 通过多个时间戳字段限制时间来获取相对准确的数据。
第4章:离线数据开发
阿里巴巴的数据计算层包括两大体系:数据存储及计算平台(离线计算平台MaxCompute和实时计算平台StreamCompute)、数据整合及管理体系(OneData)。
4.1 数据开发平台
通过统一的计算平台(MaxCompute)、统一的开发平台(D2等相关平台和工具)、统一的数据模型规范和统一的数据研发规范,可以在一定程度上解决数据研发的痛点。
4.1.1 统一计算平台
阿里离线数据仓库的存储和计算都是在阿里云大数据计算服务MaxCompute上完成的。MaxCompute采用抽象的作业处理框架,将不同场景的各种计算任务统一在同一个平台之上,共享安全、存储、数据管理和资源调度,为来自不同用户需求的各种数据处理任务提供统一的编程接口和界面。它提供数据上传/下载通道、SQL 、MapReduce 、机器学习算法、图编程模型和流式计算模型多种计算分析服务,并且提供完善的安全解决方案。
4.1.2 统一开发平台
围绕MaxCompute计算平台,从任务开发、调试、测试、发布、监控、报警到运维管理,形成了整套工具和产品,既提高了开发效率,又保证了数据质量,并且在确保数据产出时效的同时,能对数据进行有效管理。
- 在云端(D2):D2 是集成任务开发、调试及发布,生产任务调度及大数据运维,数据权限申请及管理等功能的一站式数据开发平台,并能承担数据分析工作台的功能。
- SQLSCAN:SQLSCAN将在任务开发中遇到的各种问题,如用户编写的SQL质量差、性能低、不遵守规范等,总结后形成规则,并通过系统及研发流程保障,事前解决故障隐患,避免事后处理。
- DQC(Data Quality Center,数据质量中心)主要关注数据质量,通过配置数据质量校验规则,自动在数据处理任务过程中进行数据质量方面的监控。DQC主要有数据监控和数据清洗两大功能。
- 在彼岸:数据测试的典型测试方法是功能测试,主要验证目标数据是否符合预期。a. 新增业务需求:其主要对目标数据和源数据进行对比,包括数据量、主键、字段空值、字段枚举值、复杂逻辑(如UDF、多路分支)等的测试。b. 数据迁移、重构和修改:对修改前后的数据进行对比,包括数据量差异、字段值差异对比等,保证逻辑变更正确。在彼岸主要包含如下组件:a. 数据对比: 支持不同集群、异构数据库的表做数据对比;b. 数据分布:提取表和字段的一些特征值,并将这些特征值与预期值进行比对;c. 数据脱敏:将敏感数据模糊化。
4.2 任务调度系统
4.2.1 背景
在大数据环境下,每天需要处理海量的任务,任务的类型也很繁杂,任务之间互相依赖且需要不同的运行环境。为了解决以上问题,阿里巴巴的大数据调度系统应运而生。
4.2.2 介绍
- 数据开发流程与调度系统的关系:用户通过D2平台提交、发布的任务节点,需要通过调度系统,按照任务的运行顺序调度运行。
- 调度系统的核心设计模型:调度引擎(Phoenix Engine)和执行引擎(Alisa)。调度引擎的作用是根据任务节点属性以及依赖关系进行实例化,生成各类参数的实值,并生成调度树;执行引擎的作用是根据调度引擎生成的具体任务实例和配置信息,分配CPU、内存、运行节点等资源, 在任务对应的执行环境中运行节点代码。
- 任务状态机模型:针对数据任务节点在整个运行生命周期的状态定义。
- 工作流状态机模型:针对数据任务节点在调度树中生成的工作流运行的不同状态定义。
- 调度引擎工作原理:基于以上两个状态机模型原理,以事件驱动的方式运行,为数据任务节点生成实例,并在调度树中生成具体执行的工作流。
- 执行引擎工作原理。
- 执行引擎的用法:Alisa的用户系统包括上文的工作流服务、数据同步服务,以及调度引擎生成的各类数据处理任务的调度服务。
4.2.3 特点及应用
- 调度配置:采用的是输入输出配置和自动识别相结合的方式。任务提交时,SQL解析引擎自动识别此任务的输入表和输出表,输入表自动关联产出此表的任务,输出表亦然。
- 定时调度:分钟、小时、日、周、月,具体可精确到秒。
- 周期调度:可按照小时、日等时间周期运行任务,与定时调度的区别是无须指定具体的开始运行时间。
- 手动运行:当生产环境需要做一些数据修复或其他一次性的临时数据操作时,可以选择手动运行的任务类型。
- 补数据:可以设定需要补的时间区间,并圈定需要运行的任务节点,从而生成一个补数据的工作流,同时还能选择并行的运行方式以节约时间。
- 基线管理:基于充分利用计算资源,保证重点业务数据优先产出,合理安排各类优先级任务的运行,调度系统引入了按优先级分类管理的方法。对于同一类优先级的任务,放到同一条基线中,这样可以实现按优先级不同进行分层的统一管理,并可对基线的运行时间进行预测估计,以监控是否能在规定的时间内完成。
- 监控报警:调度系统有一套完整的监控报警体系,包括针对出错的节点、运行超时未完成的节点,以及可能超时的基线等,设置电话、短信、邮件等不同的告警方式,实现了日常数据运维的自动化。
第5章:实时技术
5.1 简介
流式数据处理一般具有以下特征。
- 时效性高;
- 常驻任务;
- 性能要求高;
- 应用局限性;
5.2 流式技术架构
各个子系统按功能划分的话,主要分为以下几部分。
- 数据采集:日志服务器数据被实时采集到数据中间件中,供下游实时订阅使用。
- 数据处理:下游实时订阅数据,并拉取到流式计算系统的任务中进行加工处理。
- 数据存储:数据被实时加工处理(比如聚合、清洗等)后,会写到某个在线服务的存储系统中,供下游调用方使用。
- 数据服务:在存储系统上会架设一层统一的数据服务层,用于获取实时计算结果。
5.2.1 数据采集
不管是数据库变更日志还是引擎访问日志,都会在业务服务器上落地成文件,所以只要监控文件的内容发生变化,采集工具就可以把最新的数据采集下来。一般情况下,出于吞吐量以及系统压力上的考虑,并不是新增一条记录就采集一次,而是按批次对数据进行采集。对于采集到的数据需要一个数据交换平台分发给下游,这个平台就是数据中间件。阿里巴巴集团内部用得比较多的是TimeTunnel(原理和Kafka类似),还有MetaQ、Notify等消息系统。
5.2.2 数据处理
在阿里巴巴集团内使用比较多的是阿里云提供的StreamCompute系统,涵盖了从数据采集到数据生产各个环节,力保流计算开发严谨、可靠。实时任务遇到的几个典型问题。
- 去重指标:精确去重。在这种情况下,明细数据是必须要保存下来的。模糊去重,可以使用相关的去重算法:布隆过滤器、基数估计等。
- 数据倾斜:对数据进行分桶处理。去重指标分桶:通过对去重值进行分桶Hash,相同的值一定会被放在同一个桶中去重,最后再把每个桶里面的值进行加和就得到总值。
- 事务处理:几个流计算系统几乎都提供了数据自动ACK、失败重发以及事务信息等机制。超时时间、事务信息、备份机制,这些机制都是为了保证数据的幂等性。
5.2.3 数据存储
数据存储系统必须能够比较好地支持多并发读写,并且延时需要在毫秒级才能满足实时的性能要求。在实践中,一般使用HBase 、Tair、MongoDB等列式存储系统。表名设计和rowkey设计的一些实践经验。
- 表名设计:设计规则:汇总层标识+数据域+主维度+时间维度。
- rowkey设计:设计规则:MD5+主维度+维度标识+子维度1+时间维度+子维度2。以MD5的前四位作为rowkey的第一部分,可以把数据散列,让服务器整体负载是均衡的,避免热点问题。
5.2.4 数据服务
实时数据落地到存储系统中后,使用方就可以通过统一的数据服务获取到实时数据。比如OneService,其好处是:
- 不需要直连数据库,数据源等信息在数据服务层维护,这样当存储系统迁移时,对下游是透明的。
- 调用方只需要使用服务层暴露的接口,不需要关心底层取数逻辑的实现。
- 屏蔽存储系统间的差异,统一的调用日志输出,便于分析和监控下游使用情况。
5.3 流式数据模型
实时建模跟离线建模非常类似,数据模型整体上分为五层(ODS、DWD、DWS、ADS、DIM)。由于实时计算的局限性,每一层中并没有像离线做得那么宽,维度和指标也没有那么多,特别是涉及回溯状态的指标,在实时数据模型中几乎没有。
5.3.1 数据分层
- ODS层:操作数据层,实时和离线在源头上是统一的,这样的好处是用同一份数据加工出来的指标,口径基本是统一的,可以更方便进行实时和离线间数据比对。
- DWD层:根据业务过程建模出来的实时事实明细层,最大程度地保证实时和离线数据在ODS层和DWD层是一致的。
- DWS层:如果维度是各个垂直业务线通用的,则会放在实时通用汇总层,作为通用的数据模型使用。
- ADS层:个性化维度汇总层,对于不是特别通用的统计维度数据会放在这一层中,这里计算只有自身业务才会关注的维度和指标,跟其他业务线一般没有交集,常用于一些垂直创新业务中。
- DIM层:实时维表层的数据基本上都是从离线维表层导出来的,抽取到在线系统中供实时应用调用。
5.3.2 多流关联
在流式计算中常常需要把两个实时流进行主键关联,以得到对应的实时明细表。多流关联的一个关键点就是需要相互等待,只有双方都到达了,才能关联成功。实时采集两张表的数据,每到来一条新数据时都在内存中的对方表截至当前的全量数据中查找,如果能查找到,则说明关联成功,直接输出;如果没查找到,则把数据放在内存中的自己表数据集合中等待。另外,不管是否关联成功,内存中的数据都需要备份到外部存储系统中,在任务重启时,可以从外部存储系统中恢复内存数据,这样才能保证数据不丢失。因为在重启时,任务是续跑的,不会重新跑之前的数据。
在实际处理时,考虑到查找数据的性能,实时关联这个步骤一般会把数据按照关联主键进行分桶处理,并且在故障恢复时也根据分桶来进行,以降低查找数据量和提高吞吐量。
5.3.3 维表使用
在实时计算中,关联维表一般会使用当前的实时数据(T)去关联T-2 的维表数据,相当于在T的数据到达之前需要把维表数据准备好,并且一般是一份静态的数据。主要基于以下几点的考虑。
- 数据无法及时准备好:T-1的维表数据一般不能在零点马上准备就绪(因为T-1的数据需要在T这一天加工生成),因此去关联T-2维表。
- 无法准确获取全量的最新数据:需要T-1的数据+当天变更才能获取到完整的维表数据。
- 数据的无序性:维表的使用分为两种形式。a. 全量加载,在维表数据较少的情况下;b. 增量加载,增量查找和LRU过期的形式,优点是可以控制内存的使用量,缺点是需要查找外部存储系统,运行效率会降低。
5.4 大促挑战&保障
5.4.1 大促特征
在大促的时候一天中的峰值特别明显,数据量是其他时间点的几倍甚至数十倍,这对系统的抗压能力要求非常高,不能因为洪流的到来而把系统压垮。
- 毫秒级延时;
- 洪峰明显;
- 高保障性:多链路冗余(从采集、处理到数据服务整个数据链路都需要做物理隔离,由于各个链路计算的速度有一定的差异,会导致数据在切换时出现短时间下跌的情况,使用方需要做指标大小的判断,避免指标下跌对用户造成困扰);
- 公关特性:要求实时计算的数据质量非常高。这里面涉及主键的过滤、去重的精准和口径的统一等一系列问题;
5.4.2 大促保障
- 如何进行实时任务优化:a. 独占资源和共享资源的策略;b. 合理选择缓存机制,尽量降低读写库次数;c. 计算单元合并,降低拓扑层级;d. 内存对象共享,避免字符拷贝;e. 在高吞吐量和低延时间取平衡;
- 如何进行数据链路保障:为了保障实时数据的可用性,需要对整条计算链路都进行多链路搭建,做到多机房容灾,甚至异地容灾。
- 如何进行压测:数据压测主要是蓄洪压测,就是把几个小时甚至几天的数据积累下来,并在某个时刻全部放开;产品压测还细分为产品本身压测和前端页面稳定性测试。产品本身压测:收集大屏服务端的所有读操作的URL,通过压测平台进行压测流量回放。前端页面稳定性测试:将大屏页面在浏览器中打开,并进行8~24小时的前端页面稳定性测试。
第6章:数据服务
6.1 服务架构演进
阿里数据服务依次经历了内部代号为DWSOA、OpenAPI、SmartDQ和OneService的四个阶段。
6.1.1 DWSOA
将业务方对数据的需求通过SOA服务的方式暴露出去。由需求驱动,一个需求开发一个或者几个接口,编写接口文档,开放给业务方调用。一方面,接口粒度比较粗,灵活性不高,扩展性差,复用率低。随着业务方对数据服务的需求增加,接口的数量显著增加。
6.1.2 OpenAPI
将数据按照其统计粒度进行聚合,同样维度的数据,形成一张逻辑表,采用同样的接口描述。这种方式有效地收敛了接口数量。
6.1.3 SmartDQ
数据的维度并没有我们想象的那么可控,随着时间的推移,大家对数据的深度使用,分析数据的维度也越来越多。可以开放给业务方通过写SQL的方式对外提供服务,由服务提供者自己来维护SQL。SQL提供者只需关心逻辑表的结构,不需要关心底层由多少物理表组成,甚至不需要关心这些物理表是HBase还是MySQL的,是单表还是分库分表,因为SmartDQ已经封装了跨异构数据源和分布式查询功能。
小结:接口易上难下,即使一个接口也会绑定一批人(业务方、接口开发维护人员、调用方)。所以对外提供的数据服务接口一定要尽可能抽象,接口的数量要尽可能收敛,最后在保障服务质量的情况下,尽可能减少维护工作量。现在SmartDQ提供300多个SQL模板,每条SQL承担多个接口的需求,而我们只用l位同学来维护SmartDQ。
6.1.4 统一的数据服务层
SmartDQ其实只满足了简单的查询服务需求。我们遇到的场景还有这么几类:个性化的垂直业务场景、实时数据推送服务、定时任务服务。所以OneService主要是提供多种服务类型来满足用户需求,分别是OneService-SmartDQ、OneService-Lego、OneService-iPush、OneService-uTiming。数据生产者将数据入库之后,服务提供者可以根据标准规范快速创建服务、发布服务、监控服务、下线服务,服务调用者可以在门户网站中快速检索服务,申请权限和调用服务。
6.2 技术架构
6.2.1 SmartDQ
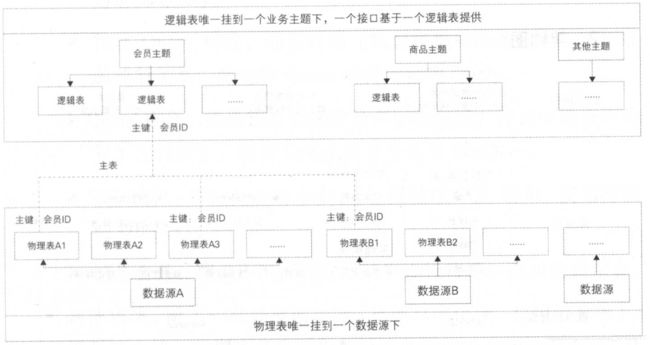
- 元数据模型:就是逻辑表到物理表的映射。
- 架构图:a. 查询数据库;b. 服务层:元数据配置,主处理模块,其他模块。
6.2.2 iPush
iPush应用产品是一个面向TT、MetaQ等不同消息源,通过定制过滤规则,向Web、无线等终端推送消息的中间件平台。iPush核心服务器端基于高性能异步事件驱动模型的网络通信框架Netty4实现,结合使用Guava缓存实现本地注册信息的存储,Filter与Server之间的通信采用Thrift异步调用高效服务实现,消息基于Disruptor高性能的异步处理框架的消息队列,在服务器运行时Zookeeper实时监控服务器状态,以及通过Diamond作为统一的控制触发中心。
6.2.3 Lego
Lego被设计成一个面向中度和高度定制化数据查询需求、支持插件机制的服务容器。它本身只提供日志、服务注册、Diamond配置监听、鉴权、数据源管理等一系列基础设施,具体的数据服务则由服务插件提供。基于Lego的插件框架可以快速实现个性化需求并发布上线。
6.2.4 uTiming
uTiming是基于在云端的任务调度应用,提供批量数据处理服务,支撑用户识别、用户画像、人群圈选三类服务的离线计算,以及用户识别、用户画像、人群透视的服务数据预处理、入库。
6.3 最佳实践
6.3.1 性能
- 资源分配:剥离计算资源;查询资源分配;执行计划优化:①查询拆分②查询优化;
- 缓存优化:元数据缓存:全量缓存+监听增量更新;模型缓存:将解析后的模型(包括逻辑模型、物理模型)缓存在本地;结果缓存;
- 查询能力:合并查询;推送服务:监听数据提供者;
6.3.2 稳定性
- 发布系统:元数据隔离:日常环境、预发环境和线上环境;隔离发布:资源划分、资源独占、增量更新;
- 隔离:机房隔离;分组隔离;
- 安全限制:最大返回记录数、必传字段、超时时间;、
- 监控:调用日志采集;调用监控;
- 限流、降级:限流,应用内的QPS保护;降级:通过限流措施,将QPS置为0,则对应的所有访问全部立即失败,防止了故障的扩散。通过修改元数据,将存在问题的资源置为失效状态,则重新加载元数据后,对应的访问就全部失败了,不会再消耗系统资源;
第7章:数据挖掘
7.1 数据挖掘概述
如何从海量数据中挖掘出有效信息形成真正的生产力,是所有大数据公司需要面对的共同课题。基于大数据的企业级数据挖掘需要包含两个要素:①面向机器学习算法的并行计算框架与算法平台;②面向企业级数据挖掘的算法资产管理体系。
7.2 数据挖掘算法平台
MPI是一种基于消息传递的并行计算框架,由于没有IO操作,性能优于MapReduce。因此,阿里巴巴的算法平台选用MPI作为基础计算框架,其核心机器学习算法的开发都是基于阿里云MaxCompute的MPI实现的。
7.3 数据挖掘中台体系
对于数据挖掘中台体系的设计也包含两大块:数据中台与算法中台。
7.3.1 挖掘数据中台
在数据挖掘的过程中包含两类数据:特征数据与结果数据。我们把数据中台分为三层:特征层(Featural Data Mining Layer, FDM)、中间层和应用层(Application-oriented Data Mining Layer, ADM),其中中间层包括个体中间层(Individual Data Mining Layer, IDM)和关系中间层(Relational Data Mining Layer, RDM)。不同数据层的作用有所区别:
- FDM层:用于存储在模型训练前常用的特征指标,并进行统一的清洗和去噪处理,提升机器学习特征工程环节的效率。
- IDM层:个体挖掘指标中间层,面向个体挖掘场景,用于存储通用性强的结果数据。
- RDM层: 关系挖掘指标中间层,面向关系挖掘场景,用于存储通用性强的结果数据。
- ADM层:用来沉淀比较个性偏应用的数据挖掘指标。
7.3.2 挖掘算法中台
理解算法的原理不难,难的是在理解原理的基础上如何能结合业务合理地运用算法。阿里巴巴数据挖掘算法中台建设的目的同样在于从各种各样的挖掘场景中抽象出有代表性的几类场景,并形成相应的方法论和实操模板。按照个体挖掘应用和关系挖掘应用的分类方式,可以抽象出常见的几类数据挖掘应用场景一一在个体挖掘应用中,消费者画像与业务指标预测是两类非常有代表性的场景;而在关系挖掘应用中,相似关系与竞争关系是两类非常通用的关系挖掘应用,在此基础上构建的推荐系统与竞争分析系统,则是电商领域持续关注的两大热门话题。
7.4 数据挖掘案例
7.4.1 用户画像
用户画像即是为用户打上各种各样的标签,如年龄、性别、职业、商品品牌偏好、商品类别偏好等。用户画像可以分为基础属性、购物偏好、社交关系、财富属性等几大类。
7.4.2 互联网反作弊
从业务上看,反作弊工作主要体现在以下几个方面:
- 账户/资金安全与网络欺诈防控;
- 非人行为和账户识别;
- 虚假订单与信用炒作识别;
- 广告推广与APP安装反作弊;
- UGC恶意信息检测;
从所采用的算法技术上说,反作弊方法主要包括如下几类:
- 基于业务规则的方法;
- 基于有监督学习的方法,其基本思路是按照有监督分类算法的流程来建模,通过正负样本标记、特征提取、模型训练及预测等过程来识别作弊行为;
- 基于无监督学习的方法:较常见的是异常检测算法,该方法假设作弊行为极其罕见且在某些特征维度下和正常行为能够明显地区分开来;
在算法实现方面的工作主要分为以下两个方面:
- 离线反作弊系统:主要包含规则判断、分类识别、异常检测等模块,通过历史行为和业务规则的沉淀,来判断未来行为的作弊情况;
- 实时反作弊系统:将离线中的许多规则和算法进行总结,在基本满足准确率和覆盖率的前提下抽取出其中计算速度较快的部分,以此来满足对实时性的要求;
反作弊未来还面临着诸多挑战。比如:
- 作弊手段的多样性和多变性;
- 算法的及时性和准确性;
- 数据及作弊手段的沉淀和逆向反馈;
第8章:大数据领域建模综述
8.1 为什么需要数据建模
数据模型就是数据组织和存储方法,它强调从业务、数据存取和使用角度合理存储数据。数据建模有以下好处。
- 性能:良好的数据模型能帮助我们快速查询所需要的数据,减少数据的I/O吞吐。
- 成本:良好的数据模型能极大地减少不必要的数据冗余,也能实现计算结果复用,极大地降低大数据系统中的存储和计算成本。
- 效率:良好的数据模型能极大地改善用户使用数据的体验,提高使用数据的效率。
- 质量:良好的数据模型能改善数据统计口径的不一致性,减少数据计算错误的可能性。
大数据系统需要数据模型方法来帮助更好地组织和存储数据,以便在性能、成本、效率和质量之间取得最佳平衡。
8.2 关系数据库系统和数据仓库
现代企业信息系统几乎都使用关系数据库来存储、加工和处理数据。数据仓库系统也不例外,大量的数据仓库系统依托强大的关系数据库能力存储和处理数据,其采用的数据模型方法也是基于关系数据库理论的。
8.3 从OLTP和OLAP系统的区别看模型方法论的选择
OLTP系统通常面向的主要数据操作是随机读写,主要采用满足3NF的实体关系模型存储数据,从而在事务处理中解决数据的冗余和一致性问题;而OLAP系统面向的主要数据操作是批量读写,事务处理中的一致性不是OLAP所关注的,其主要关注数据的整合,以及在一次性的复杂大数据查询和处理中的性能,因此它需要采用一些不同的数据建模方法。
8.4 典型的数据仓库建模方法论
8.4.1 ER模型
从全企业的高度设计一个3NF模型,用实体关系(Entity Relationship, ER)模型描述企业业务,在范式理论上符合3NF。在不太成熟、快速变化的业务面前,构建ER模型的风险非常大,不太适合去构建ER模型。其具有以下几个特点:
- 需要全面了解企业业务和数据。
- 实施周期非常长。
- 对建模人员的能力要求非常高。
采用ER模型建设数据仓库模型的出发点是整合数据,将各个系统中的数据以整个企业角度按主题进行相似性组合和合并,并进行一致性处理,为数据分析决策服务,但是并不能直接用于分析决策。其建模步骤分为三个阶段。
- 高层模型:一个高度抽象的模型,描述主要的主题以及主题间的关系,用于描述企业的业务总体概况。
- 中层模型:在高层模型的基础上,细化主题的数据项。
- 物理模型(也叫底层模型):在中层模型的基础上,考虑物理存储,同时基于性能和平台特点进行物理属性的设计,也可能做一些表的合并、分区的设计等。
8.4.2 维度模型
维度建模从分析决策的需求出发构建模型,为分析需求服务,因此它重点关注用户如何更快速地完成需求分析,同时具有较好的大规模复杂查询的响应性能。其典型的代表是星形模型,以及在一些特殊场景下使用的雪花模型。其设计分为以下几个步骤。
- 选择需要进行分析决策的业务过程。
- 选择粒度。粒度是维度的一个组合。
- 识别维表。
- 选择事实。确定分析需要衡量的指标。
8.4.3 Data Vault模型
Data Vault模型设计的出发点也是为了实现数据的整合,但不能直接用于数据分析决策。它强调建立一个可审计的基础数据层,也就是强调数据的历史性、可追溯性和原子性,而不要求对数据进行过度的一致性处理和整合。Data Vault模型由以下几部分组成。
- Hub:是企业的核心业务实体,由实体key、数据仓库序列代理键、装载时间、数据来源组成。
- Link:代表Hub之间的关系。这里与ER模型最大的区别是将关系作为一个独立的单元抽象,可以提升模型的扩展性。它由Hub的代理键、装载时间、数据来源组成。
- Satellite:是Hub的详细描述内容,一个Hub可以有多个Satellite。它由Hub的代理键、装载时间、来源类型、详细的Hub描述信息组成。
Data Vault模型比ER模型更容易设计和产出,它的ETL加工可实现配置化。
8.4.4 Anchor 模型
Anchor对Data Vault模型做了进一步规范化处理,其核心思想是所有的扩展只是添加而不是修改,因此将模型规范到6NF,基本变成了k-v结构化模型。Anchor模型的组成。
- Anchors:类似于Data Vault的Hub,代表业务实体,且只有主键。
- Attributes:功能类似于Data Vault的Satellite,但是它更加规范化,将其全部k-v结构化,一个表只有一个Anchors的属性描述。
- Ties:就是Anchors之间的关系,单独用表来描述,类似于DataVault的Link,可以提升整体模型关系的扩展能力。
- Knots:代表那些可能会在多个Anchors中公用的属性的提炼,比如性别、状态等这种枚举类型且被公用的属性。
Anchor模型的创建者的观点是,数据仓库中的分析查询只是基于一小部分字段进行的,类似于列存储结构,可以大大减少数据扫描,从而对查询性能影响较小。
8.5 阿里巴巴数据模型实践综述
阿里巴巴数据公共层建设的指导方法是一套统一化的集团数据整合及管理的方法体系(称为“OneData”),其包括一致性的指标定义体系、模型设计方法体系以及配套工具。
第9章:阿里巴巴数据整合及管理体系
OneData即是阿里巴巴内部进行数据整合及管理的方法体系和工具。阿里巴巴的大数据工程师在这一体系下,构建统一、规范、可共享的全域数据体系,避免数据的冗余和重复建设,规避数据烟囱和不一致性,充分发挥阿里巴巴在大数据海量、多样性方面的独特优势。
9.1 概述
阿里巴巴集团大数据建设方法论的核心是:从业务架构设计到模型设计,从数据研发到数据服务,做到数据可管理、可追溯、可规避重复建设。
9.1.1 定位及价值
建设统一的、规范化的数据接人层(ODS)和数据中间层(DWD和DWS),通过数据服务和数据产品,完成服务于阿里巴巴的大数据系统建设,即数据公共层建设。提供标准化的(Standard)、共享的(Shared)、数据服务(Service)能力,降低数据互通成本,释放计算、存储、人力等资源,以消除业务和技术之痛。
9.1.2 体系架构
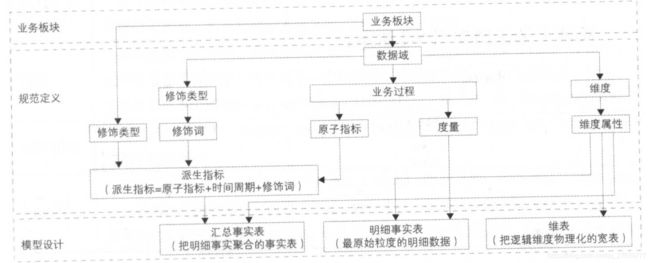
9.2 规范定义
规范定义指以维度建模作为理论基础,构建总线矩阵,划分和定义数据域、业务过程、维度、度量/原子指标、修饰类型、修饰词、时间周期、派生指标。
9.2.1 名词术语
- 数据域:指面向业务分析,将业务过程或者维度进行抽象的集合。
- 业务过程:指企业的业务活动事件,请注意,业务过程是一个不可拆分的行为事件,通俗地讲,业务过程就是企业活动中的事件。
- 时间周期:用来明确数据统计的时间范用或者时间点。
- 修饰类型:是对修饰词的一种抽象划分。
- 修饰词:指除了统计维度以外指标的业务场景限定抽象。
- 度量/原子指标:原子指标和度量含义相同,基于某一业务事件行为下的度量,是业务定义中不可再拆分的指标,具有明确业务含义的名词。
- 维度:维度是度量的环境,用来反映业务的一类属性,这类属性的集合构成一个维度,也可以称为实体对象。
- 维度属性:维度属性隶属于一个维度,如地理维度里面的国家名称、同家ID、省份名称等都属于维度属性。
- 派生指标:派生指标=一个原子指标+多个修饰词(可选)+时间周期。可以理解为对原子指标业务统计范围的圈定。
9.2.2 指标体系
- 基本原则:a. 组成体系之间的关系:派生指标由原子指标、时间周期修饰词、若干其他修饰词组合得到。原子指标、修饰类型及修饰词,直接归属在业务过程下,其中修饰词继承修饰类型的数据域。派生指标可以选择多个修饰词,修饰词之间的关系“或”或者“且”,由具体的派生指标语义决定。派生指标唯一归属一个原子指标,继承原子指标的数据域,与修饰词的数据域无关。原子指标有确定的英文字段名、数据类型和算法说明;派生指标要继承原子指标的英文名、数据类型和算法要求。b. 命名约定:命名所用术语。c. 算法。
- 操作细则:a. 派生指标的种类,事务型指标、存量型指标和复合型指标。
- 其他规则:a. 上下层级派生指标同时存在时。b. 父子关系原子指标存在时。
9.3 模型设计
9.3.1 指导理论
阿里巴巴集团数据公共层设计理念遵循维度建模思想,数据模型的维度设计主要以维度建模理论为基础,基于维度数据模型总线架构,构建一致性的维度和事实。
9.3.2 模型层次
- 操作数据层(ODS):把操作系统数据几乎无处理地存放在数据仓库系统中。
- 公共维度模型层(CDM):存放明细事实数据、维表数据及公共指标汇总数据,其中明细事实数据、维表数据一般根据ODS层数据加工生成;公共指标汇总数据一般根据维表数据和明细事实数据加工生成。
- 应用数据层(ADS):存放数据产品个性化的统计指标数据,根据CDM层与ODS层加工生成。
9.3.3 基本原则
- 高内聚和低耦合:主要从数据业务特性和访问特性两个角度来考虑:将业务相近或者相关、粒度相同的数据设计为一个逻辑或者物理模型;将高概率同时访问的数据放一起,将低概率同时访问的数据分开存储。
- 核心模型与扩展模型分离:核心模型包括的字段支持常用的核心业务,扩展模型包括的字段支持个性化或少量应用的需要,不能让扩展模型的字段过度侵人核心模型,以免破坏核心模型的架构简洁性与可维护性。
- 公共处理逻辑下沉及单一:越是底层公用的处理逻辑越应该在数据调度依赖的底层进行封装与实现,不要让公用的处理逻辑暴露给应用层实现,不要让公共逻辑多处同时存在。
- 成本与性能平衡:适当的数据冗余可换取查询和刷新性能,不宜过度冗余与数据复制。
- 数据可回滚:处理逻辑不变,在不同时间多次运行数据结果确定不变。
- 一致性:具有相同含义的字段在不同表中的命名必须相同,必须使用规范定义中的名称。
- 命名清晰、可理解:表命名需清晰、一致,表名需易于消费者理解和使用。
9.4 模型实施
9.4.1 业界常用的模型实施过程
1. Kimball模型实施过程
构建维度模型一般要经历四个阶段:
- 第一个阶段是高层设计时期,定义业务过程维度模型的范围,提供每种星形模式的技术和功能描述;
- 第二个阶段是详细模型设计时期,对每个星形模型添加属性和度量信息;
- 第三个阶段是进行模型的审查、再设计和验证等工作;
- 第四个阶段是产生详细设计文档,提交ETL设计和开发,由ETL人员完成物理模型的设计和开发。
2. Inmon 模型实施过程
Inmon 将模型划分为三个层次,分别是ERD (Entity Relationship Diagram,实体关系图)层、DIS (Data Item Set , 数据项集)层和物理层(Physical Model,物理模型)。ERD层是数据模型的最高层,该层描述了公司业务中的实体或主题域以及它们之间的关系;DIS层是中间层,该层描述了数据模型中的关键字、属性以及细节数据之间的关系;物理层是数据建模的最底层,该层描述了数据模型的物理特性。Inmon 对于构建数据仓库模型建议采用螺旋式开发方法,采用迭代方式完成多次需求。
3. 其他模型实施过程
- 业务建模,生成业务模型,主要解决业务层面的分解和程序化。
- 领域建模,生成领域模型,主要是对业务模型进行抽象处理, 生成领域概念模型。
- 逻辑建模,生成逻辑模型,主要是将领域模型的概念实体以及实体之间的关系进行数据库层次的逻辑化。
- 物理建模,生成物理模型,主要解决逻辑模型针对不同关系数据库的物理化以及性能等一些具体的技术问题。
9.4.2 OneData实施过程
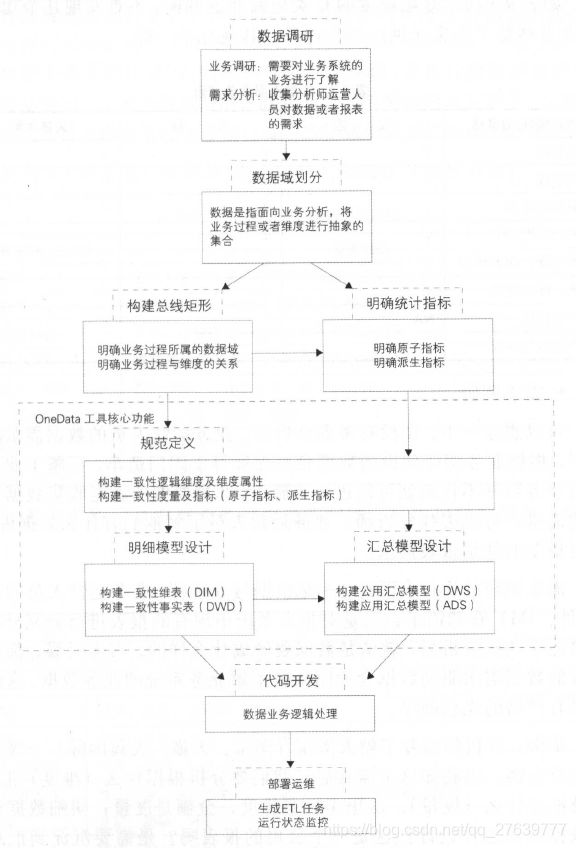
- 指导方针:首先,在建设大数据数据仓库时,要进行充分的业务调研和需求分析。这是数据仓库建设的基石,业务调研和需求分析做得是否充分直接决定了数据仓库建设是否成功。其次,进行数据总体架构设计,主要是根据数据域对数据进行划分;按照维度建模理论,构建总线矩阵、抽象出业务过程和维度。再次,对报表需求进行抽象整理出相关指标体系,使用One Data工具完成指标规范定义和模型设计。最后,就是代码研发和运维。
- 实施工作流:a. 数据调研:业务调研,在阿里巴巴,一般各个业务领域独自建设数据仓库,业务领域内的业务线由于业务相似、业务相关性较大,进行统一集中建设。需求调研,一是根据与分析师、业务运营人员的沟通(邮件、IM)获知需求:二是对报表系统中现有的报表进行研究分析。b. 架构设计:数据域划分,数据域是指面向业务分析,将业务过程或者维度进行抽象的集合。构建总线矩阵,明确每个数据域下有哪些业务过程;业务过程与哪些维度相关,并定义每个数据域下的业务过程和维度。
- 规范定义:主要定义指标体系,包括原子指标、修饰词、时间周期和派生指标。
- 模型设计:主要包括维度及属性的规范定义,维表、明细事实表和汇总事实表的模型设计。
- 总结:OneData的实施过程是一个高度迭代和动态的过程,一般采用螺旋式实施方法。在总体架构设计完成之后,开始根据数据域进行迭代式模型设计和评审。
第10章:维度设计
10.1 维度设计基础
10.1.1 维度的基本概念
在维度建模中,将度量称为“事实” ,将环境描述为“维度”,维度是用于分析事实所需要的多样环境。维度所包含的表示维度的列,称为维度属性。维度属性是查询约束条件、分组和报表标签生成的基本来源,是数据易用性的关键。
如何获取维度或维度属性?一方面,可以在报表中获取;另一方面,可以在和业务人员的交谈中发现维度或维度属性。
维度使用主键标识其唯一性,主键也是确保与之相连的任何事实表之间存在引用完整性的基础。主键有两种:代理键和自然键,它们都是用于标识某维度的具体值。但代理键是不具有业务含义的键,一般用于处理缓慢变化维;自然键是具有业务含义的键。
10.1.2 维度的基本设计方法
维度的设计过程就是确定维度属性的过程,如何生成维度属性,以及所生成的维度属性的优劣,决定了维度使用的方便性,成为数据仓库易用性的关键。正如Kimball所说的,数据仓库的能力直接与维度属性的质量和深度成正比。确定维度属性的几点提示:
- 尽可能生成丰富的维度属性;
- 尽可能多地给出包括一些富有意义的文字性描述;
- 区分数值型属性和事实;
- 尽量沉淀出通用的维度属性;
10.1.3 维度的层次结构
维度中的一些描述属性以层次方式或一对多的方式相互关联,可以被理解为包含连续主从关系的属性层次。
10.1.4 规范化和反规范化
当属性层次被实例化为一系列维度,而不是单一的维度时,被称为雪花模式。将维度的属性层次合并到单个维度中的操作称为反规范化。
10.1.5 一致性维度和交叉探查
Kimball的数据仓库总线架构提供了一种分解企业级数据仓库规划任务的合理方法,通过构建企业范围内一致性维度和事实来构建总线架构。数据仓库总线架构的重要基石之一就是一致性维度。如果不同数据域的计算过程使用的维度不一致,就会导致交叉探查存在问题。下面总结维度一致性的几种表现形式。
- 共享维表。
- 一致性上卷,其中一个维度的维度属性是另一个维度的维度属性的子集,且两个维度的公共维度属性结构和内容相同。
- 交叉属性,两个维度具有部分相同的维度属性。
10.2 维度设计高级主题
10.2.1 维度整合
数据仓库是一个面向主题的、集成的、非易失的且随时间变化的数据集合,用来支持管理人员的决策。其中集成是数据仓库的四个特性中最重要的一个。数据仓库的重要数据来源是大量的、分散的面向应用的操作型环境。应用之间的差异具体表现在如下几个方面:
- 应用在编码、命名习惯、度量单位等方面会存在很大的差异。
- 应用出于性能和扩展性的考虑,或者随技术架构的演变,以及业务的发展,采用不同的物理实现。
所以数据由面向应用的操作型环境进入数据仓库后,需要进行数据集成。将面向应用的数据转换为面向主题的数据仓库数据,本身就是一种集成。具体体现在如下几个方面:
- 命名规范的统一。表名、字段名等统一。
- 字段类型的统一。相同和相似字段的字段类型统一。
- 公共代码及代码值的统一。公共代码及标志性字段的数据类型、命名方式等统一。
- 业务含义相同的表的统一。通常有如下几种集成方式:采用主从表的设计方式,将两个表或多个表都有的字段放在主表中(主要基本信息),从属信息分别放在各自的从表中。通常建议采用复合主键的方式。直接合并,共有信息和个性信息都放在同一个表中。不合并,因为源表的表结构及主键等差异很大,无法合并,使用数据仓库里的多个表存放各自的数据。
10.2.2 水平拆分
主要有两种解决方案:方案l是将维度的不同分类实例化为不同的维度,同时在主维度中保存公共属性;方案2是维护单一维度,包含所有可能的属性。选择哪种方案?在设计过程中需要重点考虑以下三个原则。
- 扩展性:当源系统、业务逻辑变化时,能通过较少的成本快速扩展模型,保持核心模型的相对稳定性。
- 效能: 在性能和成本方面取得平衡。
- 易用性:模型可理解性高、访问复杂度低。
根据数据模型设计思想,在对维度进行水平拆分时,主要考虑如下两个依据。
第一个依据是维度的不同分类的属性差异情况。当维度属性随类型变化较大时,将所有可能的属性建立在一个表中是不切合实际的,也没有必要这样做,此时建议采用方案l。第二个依据是业务的关联程度。两个相关性较低的业务,耦合在一起弊大于利,对模型的稳定性和易用性影响较大。
10.2.3 垂直拆分
出于扩展性、产出时间、易用性等方面的考虑,设计主从维度。主维表存放稳定、产出时间早、热度高的属性;从维表存放变化较快、产出时间晚、热度低的属性。
10.2.4 历史归档
在数据仓库中,可以借用前台数据库的归档策略,定期将历史数据归档至历史维表。关于归档策略,有以下几种方式。
- 归档策略l:同前台归档策略,在数据仓库中实现前台归档算法,定期对历史数据进行归档。此方式适用于前台归档策略逻辑较为简单,且变更不频繁的情况。
- 归档策略2:同前台归档策略,但采用数据库变更日志的方式。可以使用增量日志的删除标志,作为前台数据归档的标志。通过此标志对数据仓库的数据进行归档。但对前台应用的要求是数据库的物理删除只有在归档时才执行,应用中的删除只是逻辑删除。
- 归档策略3:数据仓库自定义归档策略。原则是尽量比前台应用晚归档、少归档。避免出现数据仓库中已经归档的数据再次更新的情况。
10.3 维度变化
10.3.1 缓慢变化维
数据仓库的重要特点之一是反映历史变化,所以如何处理维度的变化是维度设计的重要工作之一。在Kimball的理论中,有三种处理缓慢变化维的方式:
- 第一种处理方式:重写维度值。采用此种方式,不保留历史数据,始终取最新数据。
- 第二种处理方式:插人新的维度行。采用此种方式,保留历史数据,维度值变化前的事实和过去的维度值关联,维度值变化后的事实和当前的维度值关联。
- 第三种处理方式:添加维度列。采用第二种处理方式不能将变化前后记录的事实归一为变化前的维度或者归一为变化后的维度。
10.3.2 快照维表
在Kimball的维度建模中,必须使用代理键作为每个维表的主键,用于处理缓慢变化维。但在阿里巴巴数据仓库建设的实践过程中,虽然使用的是Kimball的维度建模理论,但实际并未使用代理键。为什么不使用代理键?第一个原因是,阿里巴巴数据量庞大,对于分布式计算系统,不存在事务的概念,对于每个表的记录生成稳定的全局唯一的代理键难度很大,此处稳定指某条记录每次生成的代理键都相同。第二个原因是,使用代理键会大大增加ETL的复杂性,对ETL任务的开发和维护成本很高。
在阿里巴巴数据仓库实践中,处理缓慢变化维的方法是采用快照方式。数据仓库的计算周期一般是每天一次,基于此周期,处理维度变化的方式就是每天保留一份全量快照数据。
10.3.3 极限存储
首先来看历史拉链存储。历史拉链存储是指利用维度模型中缓慢变化维的第二种处理方式。这种处理方式是通过新增两个时间戳字段(start_dt和end_dt),将所有以天为粒度的变更数据都记录下来。通常分区字段也是时间戳字段。但是这种存储方式对于下游使用方存在一定的理解障碍,另外,随着时间的推移,分区数量会极度膨胀,而现行的数据库系统都有分区数量限制。为了解决上述两个问题,阿里巴巴提出来用极限存储的方式来处理。
- 透明化:底层的数据还是历史拉链存储,但是上层做一个视图操作或者在Hive里做一个hook,通过分析语句的语法树,把对极限存储前的表的查询转换成对极限存储表的查询。
- 分月做历史拉链表:减少数据分区数。
在实际生产中,做极限存储需要进行一些额外的处理。
- 在做极限存储前有一个全量存储表,全量存储表仅保留最近一段时间的全量分区数据,历史数据通过映射的方式关联到极限存储表。
- 对于部分变化频率频繁的宇段需要过滤。
10.3.4 微型维度
采用极限存储,需要避免维度的过度增长。通过将一些属性从维表中移出,放置到全新的维表中,可以解决维度的过度增长导致极限存储效果大打折扣的问题。其中一种解决方法就是上一节提到的垂直拆分,保持主维度的稳定性;另一种解决方式是采用微型维度。
微型维度的创建是通过将一部分不稳定的属性从主维度中移出,并将它们放置到拥有自己代理键的新表中来实现的。但在阿里巴巴数据仓库实践中,并未使用此技术,主要有以下几点原因:
- 微型维度的局限性。微型维度是事先用所有可能值的组合加载的,需要考虑每个属性的基数,且必须是枚举值。
- ETL逻辑复杂。对于分布式系统,生成代理键和使用代理键进行ETL加工都非常复杂,ETL开发和维护成本过高。
- 破坏了维度的可浏览性。
10.4 特殊维度
10.4.1 递归层次
维度的递归层次,按照层级是否固定分为均衡层次结构和非均衡层次结构。对于这种具有固定数量级别的递归层次,称为“均衡层次结构”。对于这种数量级别不固定的递归层次,称为“非均衡层次结构”。
在物理实现时,可以使用递归SQL实现,如Oracle中的connect by语句。由于很多数据仓库系统和商业智能工具不支持递归SQL ,且用户使用递归SQL的成本较高,所以在维度模型中,需要对此层次结构进行处理。
- 层次结构扁平化:对于均衡层次结构,采用扁平化最有效。
- 层次桥接表:该方法适合解决更宽泛的分析问题,灵活性好;但复杂性高,使用成本高。
10.4.2 行为维度
类似的维度,都和事实相关,如交易、物流等,称之为“行为维度”,或“事实衍生的维度”。按照加工方式,行为维度可以划分为以下几种:
- 另一个维度的过去行为;
- 快照事实行为维度;
- 分组事实行为维度,将数值型事实转换为枚举值。
- 复杂逻辑事实行为维度,通过复杂算法加工或多个事实综合加工得到。
对于行为维度,有两种处理方式,其中一种是将其冗余至现有的维表中,如将卖家信用等级冗余至卖家维表中;另一种是加工成单独的行为维表,如卖家主营类目。具体采用哪种方式主要参考如下两个原则:
- 第一,避免维度过快增长。
- 第二,避免耦合度过高。
10.4.3 多值维度
针对多值维度,常见的处理方式有三种,可以根据业务的表现形式和统计分析需求进行选择。
- 第一种处理方式是降低事实表的粒度。将多值打平成多行。
- 第二种处理方式是采用多字段。
- 第三种处理方式是采用较为通用的桥接表。桥接表方式更加灵活、扩展性更好,但逻辑复杂、开发和维护成本较高,可能带来双重计算的风险,选择此方式需慎重。
10.4.4 多值属性
维表中的某个属性字段同时有多个值,称之为“多值属性”。它是多值维度的另一种表现形式。对于多值属性,常见的处理方式有三种,可以根据具体情况进行选择。
- 第一种处理方式是保持维度主键不变,将多值属性放在维度的一个属性字段中。此种处理方式扩展性好,但数据使用较为麻烦。
- 第二种处理方式也是保持维度主键不变,但将多值属性放在维度的多个属性字段中。扩展性较差。
- 第三种处理方式是维度主键发生变化,一个维度值存放多条记录,将多值属性k:v中的k变成维表的主键之一。此种处理方式扩展性好,使用方便,但需要考虑数据的急剧膨胀情况。
10.4.5 杂项维度
杂项维度是由操作型系统中的指示符或者标志字段组合而成的,一般不在一致性维度之列。一个事实表中可能会存在多个类似的字段,如果作为事实存放在事实表中,则会导致事实表占用空间过大;如果单独建立维表,外键关联到事实表,则会出现维度过多的情况;如果将这些字段删除,则会有人不同意。通常的解决方案就是建立杂项维度,将这些字段建立到一个维表中,在事实表中只需保存一个外键即可。多个字段的不同取值组成一条记录,生成代理键,存入维表中,并将该代理键保存到相应的事实表字段下。
在阿里巴巴的实践中,一般在逻辑建模中,会使用实体的主键作为杂项维度的主键。只考虑杂项维度,忽略其他维度,会将维度属性退化至事实表中。
第11章:事实表设计
11.1 事实表基础
11.1.1 事实表特性
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计,通过获取描述业务过程的度量来表达业务过程,包含了引用的维度和与业务过程有关的度量。事实表中一条记录所表达的业务细节程度被称为粒度。通常粒度可以通过两种方式来表述:一种是维度属性组合所表示的细节程度;一种是所表示的具体业务含义。作为度量业务过程的事实,一般为整型或浮点型的十进制数值,有可加性、半可加性和不可加性三种类型。
维度属性也可以存储到事实表中,这种存储到事实表中的维度列被称为“退化维度”。事实表有三种类型: 事务事实表、周期快照事实表和累积快照事实表。事务事实表用来描述业务过程,跟踪空间或时间上某点的度量事件,保存的是最原子的数据,也称为“原子事实表”。周期快照事实表以具有规律性的、可预见的时间间隔记录事实,时间间隔如每天、每月、每年等。累积快照事实表用来表述过程开始和结束之间的关键步骤事件,覆盖过程的整个生命周期,通常具有多个日期字段来记录关键时间点, 当过程随着生命周期不断变化时,记录也会随着过程的变化而被修改。
11.1.2 事实表设计原则
- 原则1:尽可能包含所有与业务过程相关的事实。
- 原则2:只选择与业务过程相关的事实。
- 原则3:分解不可加性事实为可加的组件。
- 原则4:在选择维度和事实之前必须先声明粒度。
- 原则5:在同一个事实表中不能有多种不同粒度的事实。
- 原则6:事实的单位要保持一致。
- 原则7:对事实的null 值要处理,建议用零值填充。
- 原则8:使用退化维度提高事实表的易用性。
11.1.3 事实表设计方法
对于维度模型设计采用四步设计方法:选择业务过程、声明粒度、确定维度、确定事实。为了更有效、准确地进行维度模型建设,基于Kimball的四步维度建模方法,我们进行了更进一步的改进。
- 第一步:选择业务过程及确定事实表类型。
- 第二步:声明粒度。粒度的声明是事实表建模非常重要的一步,意味着精确定义事实表的每一行所表示的业务含义,粒度传递的是与事实表度量有关的细节层次。应该尽量选择最细级别的原子粒度,以确保事实表的应用具有最大的灵活性。
- 第三步:确定维度。完成粒度声明以后,也就意味着确定了主键,对应的维度组合以及相关的维度字段就可以确定了,应该选择能够描述清楚业务过程所处的环境的维度信息。
- 第四步:确定事实。应该选择与业务过程有关的所有事实,且事实的粒度要与所声明的事实表的粒度一致。事实有可加性、半可加性、非可加性三种类型,需要将不可加性事实分解为可加的组件。
- 第五步:冗余维度。在传统的维度建模的星形模型中,对维度的处理是需要单独存放在专门的维表中的,通过事实表的外键获取维度。所以通常事实表中会冗余方便下游用户使用的常用维度,以实现对事实表的过滤查询、控制聚合层次、排序数据以及定义主从关系等操作。
11.2 事务事实表
11.2.1 设计过程
任何类型的事件都可以被理解为一种事务。事务事实表,即针对这些过程构建的一类事实表,用以跟踪定义业务过程的个体行为,提供丰富的分析能力,作为数据仓库原子的明细数据。事务事实表的一般设计过程。
- 选择业务过程;
- 确定粒度;
- 确定维度;
- 确定事实;
- 冗余维度;Kimball维度建模理论建议在事实表中只保存这些维表的外键,将维度属性都冗余到事实表中,提高对事实表进行过滤查询、统计聚合的效率。
11.2.2 单事务事实表
针对每个业务过程设计一个事实表。可以方便地对每个业务过程进行独立的分析研究。
11.2.3 多事务事实表
多事务事实表,将不同的事实放到同一个事实表中,即同一个事实表包含不同的业务过程。多事务事实表在设计时有两种方法进行事实的处理:①不同业务过程的事实使用不同的事实字段进行存放:②不同业务过程的事实使用同一个事实字段进行存放,但增加一个业务过程标签。上面介绍了两种多事务事实表的设计方式,在实际应用中需要根据业务过程进行选择。
- 当不同业务过程的度量比较相似、差异不大时,可以采用第二种多事务事实表的设计方式,使用同一个字段来表示度量数据。但这种方式存在一个问题一一在同一个周期内会存在多条记录。
- 当不同业务过程的度量差异较大时,可以选择第一种多事务事实表的设计方式,将不同业务过程的度量使用不同字段冗余到表中,非当前业务过程则置零表示。这种方式所存在的问题是度量字段零值较多。
11.2.4 两种事实表对比
- 业务过程。多个业务过程是否放到同一个事实表中,首先需要分析不同业务过程之间的相似性和业务源系统。
- 粒度和维度。当不同业务过程的粒度相同,同时拥有相似的维度时,此时就可以考虑采用多事务事实表。如果粒度不同,则必定是不同的事实表。
- 事实。如果单一业务过程的事实较多,同时不同业务过程的事实又不相同,则可以考虑使用单事务事实表,处理更加清晰;若使用多事务事实表,则会导致事实表零值或空值字段较多。
- 下游业务使用。单事务事实表对于下游用户而言更容易理解,关注哪个业务过程就使用相应的事务事实表;而多事务事实表包含多个业务过程,用户使用时往往较为困惑。
- 计算存储成本。当业务过程数据来源于同一个业务系统,具有相同的粒度和维度,且维度较多而事实相对不多时,此时可以考虑使用多事务事实表,不仅其加工计算成本较低,同时在存储上也相对节省,是一种较优的处理方式。
11.2.5 父子事实的处理方式
将父事实的度量分摊到子事实上,将父子事实同时冗余到事务表中。
11.2.6 事实的设计准则
- 事实完整性。事实表包含与其描述的过程有关的所有事实,即尽可能多地获取所有的度量。
- 事实一致性。在确定事务事实表的事实时,明确存储每一个事实以确保度量的一致性。
- 事实可加性。
11.3 周期快照事实表
快照事实表在确定的间隔内对实体的度量进行抽样,这样可以很容易地研究实体的度量值,而不需要聚集长期的事务历史。
11.3.1 特性
事务事实表的粒度能以多种方式表达,但快照事实表的粒度通常以维度形式声明;事务事实表是稀疏的,但快照事实表是稠密的;事务事实表中的事实是完全可加的,但快照模型将至少包含一个用来展示半可加性质的事实。
- 用快照采样状态:快照事实表以预定的间隔采样状态度量。
- 快照粒度:快照需要采样的周期以及什么将被采样。
- 密度与稀疏性:事务事实表是稀疏的,只有当天发生的业务过程,事实表才会记录该业务过程的事实,如下单、支付等;而快照事实表是稠密的,无论当天是否有业务过程发生,都会记录一行,比如针对卖家的历史至今的下单和支付金额,无论当天卖家是否有下单支付事实,都会给该卖家记录一行。
- 半可加性:在快照事实表中收集到的状态度量都是半可加的。比如对于淘宝交易事务事实表,可以对一个周期内的下单金额或者支付金额进行汇总,得到下单支付总额,但快照事实表在每个采样周期内是不能对状态度量进行汇总的。
11.3.2 实例
子快照事实表的设计步骤可以归纳为:
- 确定快照事实表的快照粒度。
- 确定快照事实表采样的状态度量。
可以从事务事实表进行汇总产出,这是周期快照事实表常见的一种产出模式。还有一种产出模式,即直接使用操作型系统的数据作为周期快照事实表的数据源进行加工,比如淘宝卖家星级、卖家DSR事实表等。
11.3.3 注意事项
- 事务与快照成对设计:数据仓库维度建模时,对于事务事实表和快照事实表往往都是成对设计的,互相补充,以满足更多的下游统计分析需求,特别是在事务事实表的基础上可以加工快照事实表。
- 附加事实:快照事实表在确定状态度量时, 一般都是保存采样周期结束时的状态度量。但是也有分析需求需要关注上一个采样周期结束时的状态度量,因此一般在设计周期快照事实表时会附加一些上一个采样周期的状态度量。
- 周期到日期度量:也有需要关注自然年至今、季度至今、财年至今的一些状态度量,因此在确定周期快照事实表的度量时,也要考虑类似的度量值,以满足更多的统计分析需求。
11.4 累积快照事实表
对于类似于研究事件之间时间间隔的需求,采用累积快照事实表可以很好地解决。
11.4.1 设计过程
对于累积快照事实表,其建模过程和事务事实表相同,适用于维度建模的步骤。
- 选择业务过程。在“事实表基础”一节中讲解了淘宝交易订单的流转过程,主要有四个事件,即买家下单、买家支付、卖家发货、买家确认收货业务过程。
- 确定粒度。在“事务事实表”中提到,对于淘宝交易,业务需求一般是从子订单粒度进行统计分析,所以选择子订单粒度。而对于累积快照事实表,用于考察实体的唯一实例,所以子订单在此表中只有一行记录,事件发生时,对此实例进行更新。
- 确定维度。与事务事实表相同,维度主要有买家、卖家、店铺、商品、类目、发货地区、收货地区等。
- 确定事实。累积快照事实表解决的最重要的问题是统计不同业务过程之间的时间间隔,建议将每个过程的时间间隔作为事实放在事实表中。
- 退化维度。在传统的维度模型设计完成之后,在物理实现中将各维度的常用属性退化到事实表中,以大大提高对事实表的过滤查询、统计聚合等操作的效率。
11.4.2 特点
- 数据不断更新:事务事实表记录事务发生时的状态,对于实体的某一实例不再更新;而累积快照事实表则对实体的某一实例定期更新。
- 多业务过程日期:累积快照事实表适用于具有较明确起止时间的短生命周期的实体,比如交易订单、物流订单等,对于实体的每一个实例,都会经历从诞生到消亡等一系列步骤。对于商品、用户等具有长生命周期的实体,一般采用周期快照事实表更合适。但结合阿里巴巴数据仓库模型建设的经验,对于累积快照事实表,还有一个重要作用是保存全量数据。
11.4.3 特殊处理
- 非线性过程:并不是所有的业务都会走相同的流程,处理情况主要有以下几种。a. 业务过程的统一,比如流程结束标志的统一。b. 针对业务关键里程碑构建全面的流程,流程未覆盖相关业务过程的时间字段和事实置空。c. 循环流程的处理,使用业务过程第一次发生的日期还是最后一次发生的日期,决定权在商业用户,而不是设计或开发人员。
- 多源过程:针对多业务过程建模时,业务过程可能来自于不同的系统或者来源于不同的表,其对于累积快照事实表的模型设计没有影响,但会影响ETL开发的复杂程度。
- 业务过程取舍:当拥有大量的业务过程时,模型的实现复杂度会增加,特别是对于多源业务过程,模型的耦合度过高,此时需要根据商业用户需求,选取关键的里程碑。
11.4.4 物理实现
第一种方式是全量表的形式。此全量表一般为日期分区表,每天的分区存储昨天的全量数据和当天的增量数据合并的结果,保证每条记录的状态最新。此种方式适用于全量数据较少的情况。如果数据量很大,此全量表数据量不断膨胀,存储了大量永远不再更新的历史数据,对ETL和分析统计性能影响较大。
第二种方式是全量表的变化形式。此种方式主要针对事实表数据量很大的情况。较短生命周期的业务实体一般从产生到消亡都有一定的时间间隔,可以测算此时间间隔,或者根据商业用户的需求确定一个相对较大的时间间隔。比如针对交易订单,设计最近200 天的交易订单累积快照事实表,每天的分区存储最近200天的交易订单。
第三种方式是以业务实体的结束时间分区。每天的分区存放当天结束的数据,设计一个时间非常大的分区,比如3000-12-31,存放截至当前未结束的数据。
11.5 三种事实表的比较
事务事实表记录的事务层面的事实,用于跟踪业务过程的行为,并支持几种描述行为的事实,保存的是最原子的数据,也称为“原子事实表”。事务事实表中的数据在事务事件发生后产生,数据的粒度通常是每个事务一条记录。一旦事务被提交,事实表数据被插入,数据就不能更改,其更新方式为增量更新。
周期快照事实表以具有规律性的、可预见的时间间隔来记录事实,如余额、库存、层级、温度等,时间间隔为每天、每月、每年等,典型的例子如库存日快照表等。周期快照事实表的日期维度通常记录时间段的终止日,记录的事实是这个时间段内一些聚集事实值或状态度量。事实表的数据一旦插入就不能更改,其更新方式为增量更新。
累积快照事实表被用来跟踪实体的一系列业务过程的进展情况,它通常具有多个日期字段,用于研究业务过程中的里程碑过程的时间间隔。另外,它还会有一个用于指示最后更新日期的附加日期字段。由于事实表中许多日期在首次加载时是不知道的,而且这类事实表在数据加载完成后,可以对其数据进行更新,来补充业务状态变更时的日期信息和事实。
11.6 无事实的事实表
在维度模型中,事实表用事实来度量业务过程,不包含事实或度量的事实表称为“无事实的事实表”。常见的无事实的事实表主要有如下两种:
- 事件类的,记录事件的发生。
- 条件、范围或资格类的,记录维度与维度多对多之间的关系。
11.7 聚集型事实表
数据仓库的性能是数据仓库建设是否成功的重要标准之一。聚集主要是通过汇总明细粒度数据来获得改进查询性能的效果。
11.7.1 聚集的基本原则
- 一致性。聚集表必须提供与查询明细粒度数据一致的查询结果。
- 避免单一表设计。不要在同一个表中存储不同层次的聚集数据;否则将会导致双重计算或出现更糟糕的事情。
- 聚集粒度可不同。聚集并不需要保持与原始明细粒度数据一样的粒度,聚集只关心所需要查询的维度。
11.7.2 聚集的基本步骤
- 确定聚集维度。
- 确定一致性上钻。
- 确定聚集事实。
11.7.3 阿里公共汇总层
- 基本原则:数据公用性。不跨数据域。区分统计周期。
- 交易汇总表设计:确定聚集维度一一商品。确定一致性上钻一一按商品(商品ID)最近l天汇总。确定聚集事实一一下单量、交易额。
11.7.4 聚集补充说明
- 聚集是不跨越事实的。聚集的维度和度量必须与原始模型保持一致,因此聚集是不跨越事实的。
- 聚集带来的问题。聚集会带来查询性能的提升,但聚集也会增加ETL维护的难度。
第12章:元数据
12.1 元数据概述
12.1.1 元数据定义
按照传统的定义,元数据(Metadata)是关于数据的数据。元数据主要记录数据仓库中模型的定义、各层级间的映射关系、监控数据仓库的数据状态及ETL的任务运行状态。在数据仓库系统中,元数据可以帮助数据仓库管理员和开发人员非常方便地找到他们所关心的数据,用于指导其进行数据管理和开发工作,提高工作效率。
将元数据按用途的不同分为两类:技术元数据(Technical Metadata)和业务元数据(Business Metadata)。技术元数据是存储关于数据仓库系统技术细节的数据,是用于开发和管理数据仓库使用的数据。阿里巴巴常见的技术元数据有:
- 分布式计算系统存储元数据,如MaxCompute表、列、分区等信息。
- 分布式计算系统运行元数据,如MaxCompute上所有作业运行等信息。
- 数据开发平台中数据同步、计算任务、任务调度等信息。
- 数据质量和运维相关元数据。
业务元数据从业务角度描述了数据仓库中的数据,它提供了介于使用者和实际系统之间的语义层,使得不懂计算机技术的业务人员也能够“读懂”数据仓库中的数据。阿里巴巴常见的业务元数据有:
- OneData元数据,如维度及属性、业务过程、指标等的规范化定义,用于更好地管理和使用数据。
- 数据应用元数据,如数据报表、数据产品等的配置和运行元数据。
12.1.2 元数据价值
元数据有重要的应用价值,是数据管理、数据内容、数据应用的基础,在数据管理方面为集团数据提供在计算、存储、成本、质量、安全、模型等治理领域上的数据支持。
12.1.3 统一元数据体系建设
元数据建设的目标是打通数据接入到加工,再到数据消费整个链路,规范元数据体系与模型,提供统一的元数据服务出口,保障元数据产出的稳定性和质量。
12.2 元数据应用
数据的真正价值在于数据驱动决策,通过数据指导运营。
12.2.1 Data Profile
核心思路是为纷繁复杂的数据建立一个脉络清晰的血缘图谱。通过图计算、标签传播算法等技术,系统化、自动化地对计算与存储平台上的数据进行打标、整理、归档。形象地说,Data Profile实际承担的是为元数据“画像”的任务。Data Profile开发出了四类标签:
- 基础标签:针对数据的存储情况、访问情况、安全等级等进行打标。
- 数仓标签:针对数据是增量还是全量、是否可再生、数据的生命周期来进行标签化处理。
- 业务标签:根据数据归属的主题域、产品线、业务类型为数据打上不同的标签。
- 潜在标签:这类标签主要是为了说明数据潜在的应用场景,比如社交、媒体、广告、电商、金融等。
12.2.2 元数据门户
元数据门户致力打造一站式的数据管理平台、高效的一体化数据市场。包括“前台”和“后台”,“前台”产品为数据地图,定位消费市场,实现检索数据、理解数据等“找数据”需求;“后台”产品为数据管理,定位于一站式数据管理,实现成本管理、安全管理、质量管理等。
12.2.3 应用链路分析
通过应用链路分析,产出表级血缘、字段血缘和表的应用血缘。其中表级血缘主要有两种计算方式:一种是通过MaxCompute任务日志进行解析;一种是根据任务依赖进行解析。
其中难度最大的是表的应用血缘解析,其依赖不同的应用。按照应用和物理表的配置关系,可以分为配置型和无配置型。无配置型主要通过统一的应用日志打点SDK来解决此问题,可以做到配置化、应用无痕化。常见的应用链路分析应用主要有影响分析、重要性分析、下线分析、链路分析、寻根溯源、故障排查等。
12.2.4 数据建模
通过元数据驱动的数据仓库模型建设,提高数据仓库建模的数据化指导,提升建模效率。所使用的元数据主要有:
- 表的基础元数据,包括下游情况、查询次数、关联次数、聚合次数、产出时间等。
- 表的关联关系元数据,包括关联表、关联类型、关联字段、关联次数等。
- 表的字段的基础元数据,包括字段名称、字段注释、查询次数、关联次数、聚合次数、过滤次数等。
在星形模型设计过程中,可能类似于如下使用元数据。
- 基于下游使用中关联次数大于某个阈值的表或查询次数大于某个阈值的表等元数据信息,筛选用于数据模型建设的表。
- 基于表的字段元数据,如字段中的时间字段、字段在下游使用中的过滤次数等,选择业务过程标识字段。
- 基于主从表的关联关系、关联次数,确定和主表关联的从表。
- 基于主从表的字段使用情况,如字段的查询次数、过滤次数、关联次数、聚合次数等,确定哪些字段进入目标模型。
12.2.5 驱动ETL开发
通过元数据,指导ETL工作,提高ETL的效率。我们可以通过Data Profile得到数据的下游任务依赖情况、最近被读写的次数、数据是否可再生、每天消耗的存储计算等,这些信息足以让我们判断数据是否可以下线;如果根据一些规则判断可以下线,则会通过OneClick触发一个数据下线的工作任务流,数据Owner可能只需要点击提交按钮,删除数据、删除元数据、下线调度任务、下线DQC监控等一系列操作就会自动在后台执行完成。
第13章:计算管理
13.1 系统优化
在任务稳定的情况下,可以考虑基于任务的历史执行情况进行资源评估,即采用HBO (History-Based Optimizer,基于历史的优化器)。提到CBO (Cost-Based Optimizer ,基于代价的优化器),首先会想到Oracle的CBO。Oracle会根据收集到的表、分区、索引等统计信息来计算每种执行方式的代价(Cost),进而选择其中最优的执行方式。但对表和列上统计信息的收集也是有代价的,尤其是在大数据环境下,表的体量巨大,消耗大量资源收集的统计信息利用率很低。MaxCompute采用各种抽样统计算法,通过较少的资源获得大量的统计信息,基于先进的优化模型,具备了完善的CBO能力,与传统的大数据计算系统相比,性能提升明显。
13.1.1 HBO
HBO是根据任务历史执行情况为任务分配更合理的资源,包括内存、CPU以及Instance个数。HBO是对集群资源分配的一种优化,概括起来就是:任务执行历史+集群状态信息+优化规则→更优的执行配置。
- 背景:通过数据分析,发现在系统中存在大量的周期性调度的脚本(物理计划稳定),且这些脚本的输入一般比较稳定,如果能对这部分脚本进行优化,那么对整个集群的计算资源的使用率将会得到显著提升。HBO一般通过自造应调整系统参数来达到控制计算资源的目的。
- HBO原理。HBO分配资源的步骤如下:a. 前提:最近7天内任务代码没有发生变更且任务运行4次。b. Instance分配逻辑:基础资源估算值+加权资源估算值。
- HBO效果。提高CPU利用率;提高内存利用率;提高Instance并发数;降低执行时长。
- HBO改进与优化。HBO也增加了根据数据量动态调整Instance数的功能,主要依据Map的数据量增长情况进行调整。
基础资源数量的逻辑:对于Map Task,根据期望的每个Map能处理的数据量,再结合用户提交任务的输入数据量,就可以估算出用户提交的任务所需要的Map数量。对于Reduce Task,比较Hive使用Map输入数据量,MaxCompute使用最近7天Reduce对应Map 的平均输出数据量作为Reduce的输入数据量,用于计算Instance的数量。
加权资源数量的逻辑:对于Map Task,通过该Map在最近一段时间内的平均处理速度与系统设定的期望值做比较,如果平均处理速度小于期望值,则按照同等比例对基础资源数量进行加权,估算出该Map的加权资源数量。对于Reduce Task,方法同上。
13.1.2 CBO
根据收集的统计信息来计算每种执行方式的代价,进而选择最优的执行方式。
- 优化器原理:优化器有多个模块相互组合协调工作,包括Meta Manager(元数据)、Statistics(统计信息)、Rule Set(优化规则集)、Volcano Planner Core(核心计划器)等。
- 优化器新特性:主要是重新排序Join (Join Reorder)和自动MapJoin (Auto MapJoin)。
- 优化器使用:将内部已经实现的优化规则进行分类,并且提供set等命令方便用户使用。
- 注意事项:如果用户需要下推UDF,则要自己改动SQL,这样做主要的好处是用户自己控制UDF执行的逻辑,最了解自己的UDF使用在SQL的哪个部分,而不是优化器任意下推等。对于不确定函数,优化器也不会任意下推,比如sample函数。书写SQL语句时, 应尽量避免Join Key存在隐式类型转换。
13.2 任务优化
13.2.1 Map 倾斜
- 背景:Map端的主要功能是从磁盘中将数据读人内存。以下两种情况可能会导致Map端长尾:上游表文件的大小特别不均匀,并且小文件特别多,导致当前表Map端读取的数据分布不均匀,引起长尾。
- Map端做聚合时,由于某些Map Instance读取文件的某个值特别多而引起长尾,主要是指Count Distinct操作。
- 方案:第一种情况导致的Map端长尾,可通过对上游合并小文件,同时调节本节点的小文件的参数来进行优化。第二种情况:可以使用“distribute by rand()”来打乱数据分布,使数据尽可能分布均匀。
- 思考:首先考虑如何让Map Instance读取的数据量足够均匀,然后判断是哪些操作导致Map Instance比较慢,最后考虑这些操作是否必须在Map端完成,在其他阶段是否会做得更好。
13.2.2 Join 倾斜
- 背景:数据倾斜导致长尾的现象比较普遍,严重影响任务的执行时间。
- 方案:a. Join倾斜时,如果某路输入比较小,则可以采用MapJoin避免倾斜。MapJoin必须是Join中的从表比较小才可用。b. Join因为空值导致长尾,针对这种情况可以将空值处理成随机值。因为空值无法关联上,只是分发到一处,因此处理成随机值既不会影响关联结果,也能很好地避免聚焦导致长尾。c. Join因为热点值导致长尾,并且Join的输入比较大无法使用MapJoin,则可以先将热点key取出,对于主表数据用热点key切分成热点数据和非热点数据两部分分别处理,最后合并。
- 思考:当大表和大表Join因为热点值发生倾斜时,虽然可以通过修改代码来解决,但是修改起来很麻烦,代码改动也很大,且影响阅读。我们还一直在探索和思考,期望有更好的、更智能的解决方案,如生成统计信息,MaxCompute内部根据统计信息来自动生成解决倾斜的代码,避免投入过多的人力。
13.2.3 Reduce 倾斜
- 背景:Reduce端负责的是对Map端梳理后的有序key-value键值对进行聚合。Reduce端产生长尾的主要原因就是key的数据分布不均匀。如下几种情况会造成Reduce端长尾:a. 对同一个表按照维度对不同的列进行Count Distinct操作,造成Map端数据膨胀,从而使得下游的Join和Reduce出现链路上的长尾。b. Map端直接做聚合时出现key值分布不均匀,造成Reduce端长尾。c. 动态分区数过多时可能造成小文件过多,从而引起Reduce端长尾。d. 多个Distinct同时出现在一段SQL代码中时,数据会被分发多次,不仅会造成数据膨胀N倍,还会把长尾现象放大N倍。
- 方案:对于上面提到的第二种情况,可以对热点key进行单独处理,然后通过“Union All”合并。对于上面提到的第三种情况,可以把符合不同条件的数据放到不同的分区,避免通过多次“Insert Overwrite”写入表中,特别是分区数比较多时,能够很好地简化代码。MaxCompute对动态分区的处理是引人额外一级的Reduce Task,把相同的目标分区交由同一个(或少量几个) Reduce Instance 来写入,避免小文件过多,并且这个Reduce肯定是最后一个Reduce Task操作。第四种情况,执行Group By原表粒度+ buyer_id(待去重统计的id),可以先分别进行查询,然后在子查询外Group By原表粒度。
- 思考:对Multi Distinct,在把不同指标Join在一起之前,一定要确保指标的粒度是原始表的数据粒度。修改后的代码较为复杂,在性能和代码简洁、可维护之间需要根据具体情况进行权衡。当代码比较雍肿时,也可以将上述子查询落到中间表里,这样数据模型更合理、复用性更强、层次更清晰。
第14章:存储和成本管理
对于数据爆炸式的增长,存储管理也将面临着一系列挑战。如何有效地降低存储资源的消耗,节省存储成本,将是存储管理孜孜追求的目标。
14.1 数据压缩
目前MaxCompute中提供了archive压缩方法,它采用了具有更高压缩比的压缩算法,可以将数据保存为RAID file的形式,数据不再简单地保存为3份,而是使用盘古RAID file的默认值(6, 3)格式的文件,即6份数据+3份校验块的方式,这样能够有效地将存储比约为1:3 提高到1:1.5,大约能够省下一半的物理空间。当然,这样恢复数据块的时间将要比原来的方式更长,读的性能会有一定的损失。
14.2 数据重分布
在MaxCompute中主要采用基于列存储的方式,由于每个表的数据分布不同,插人数据的顺序不一样,会导致压缩效果有很大的差异,因此通过修改表的数据重分布,避免列热点,将会节省一定的存储空间。目前我们主要通过修改distribute by和sort by字段的方法进行数据重分布。一般我们会筛选出重分布效果高于15%的表进行优化处理。
14.3 存储治理项优化
在元数据的基础上,诊断、加工成多个存储治理优化项。目前已有的存储治理优化项有未管理表、空表、最近62天未访问表、数据无更新无任务表、数据无更新有任务表、开发库数据大于lOOGB且无访问表、长周期表等。通过对该优化项的数据诊断,形成治理项,治理项通过流程的方式进行运转、管理,最终推动各个ETL开发人员进行操作,优化存储管理,并及时回收优化的存储效果。在这个体系下,形成现状分析、问题诊断、管理优化、效果反馈的存储治理项优化的闭环。

14.4 生命周期管理
从数据价值及数据使用性方面综合考虑,数据的生命周期管理是存储管理的一项重要手段。生命周期管理的根本目的就是用最少的存储成本来满足最大的业务需求,使数据价值最大化。
14.4.1 生命周期管理策略
- 周期性删除策略:所存储的数据都有一定的有效期,从数据创建开始到过时,可以周期性删除X天前的数据。
- 彻底删除策略:临时数据,以及不需要保留的数据,包括删除元数据。
- 永久保留策略:重要且不可恢复的底层数据和应用数据需要永久保留。
- 极限存储策略:通过平台化配置手段实现透明访问;缺点是对数据质量要求非常高,配置与维护成本比较高。
- 冷数据管理策略:冷数据管理是永久保留策略的扩展,永久保留的数据需要迁移到冷数据中心进行永久保存。
- 增量表merge全量表策略:需要改成增量同步与全量merge的方式,对于对应的delta增量表的保留策略,目前默认保留93天。
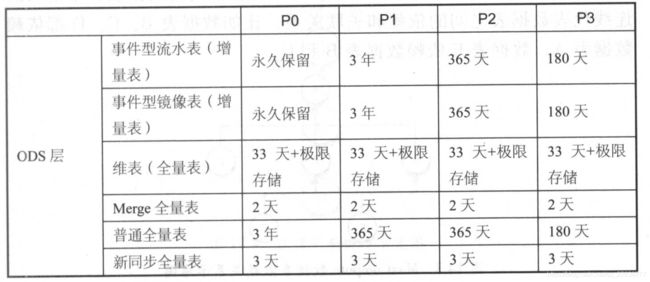
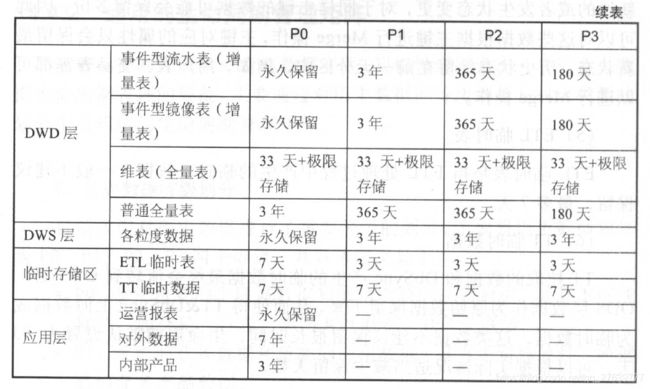
14.4.2 通用的生命周期管理矩阵
- 历史数据等级划分:主要将历史数据划分为PO 、Pl 、P2 、P3四个等级。
- 表类型划分:事件型流水表(增量表);事件型镜像表(增量表);维表;Merge全量表;ETL临时表;TT临时数据;普通全量表。
14.5 数据成本计量
可以采用最简单的方式,将一个数据表的成本分为存储成本和计算成本。存储成本是为了计量数据表消耗的存储资源,计算成本是为了计量数据计算过程中的CPU消耗。但这会存在较大的质疑和挑战,在计量数据表的成本时,除考虑数据表本身的计算成本、存储成本外,还要考虑对上游数据表的扫描带来的扫描成本。我们将数据成本定义为存储成本、计算成本和扫描成本三个部分,能够很好地体现出数据在加工链路中的上下游依赖关系,使得成本的评估尽量准确、公平、合理。
14.6 数据使用计费
在阿里巴巴集团内部,分别依据这三部分成本进行收费,称为:计算付费、存储付费和扫描付费。我们把数据资产的成本管理分为数据成本计量和数据使用计费两个步骤。通过成本计量,可以比较合理地评估出数据加工链路中的成本,从成本的角度反映出在数据加工链路中是否存在加工复杂、链路过长、依赖不合理等问题,间接辅助数据模型优化,提升数据整合效率;通过数据使用计费,可以规范下游用户的数据使用方法,提升数据使用效率,从而为业务提供优质的数据服务。
第15章:数据质量
数据质量是数据分析结论有效性和准确性的基础,也是这一切的前提。如何保障数据质量,确保数据可用性是阿里巴巴数据仓库建设不容忽视的环节。
15.1 数据质量保障原则
阿里巴巴对数据仓库主要从四个方面进行评估,即完整性、准确性、一致性和及时性。
- 完整性。完整性是指数据的记录和信息是否完整,是否存在缺失的情况。数据的缺失主要包括记录的缺失和记录中某个字段信息的缺失,两者都会造成统计结果不准确,所以说完整性是数据质量最基础的保障。
- 准确性。准确性是指数据中记录的信息和数据是否准确,是否存在异常或者错误的信息。
- 一致性。一致性一般体现在跨度很大的数据仓库体系中,对于同一份数据,必须保证一致性。
- 及时性。保障数据能够及时产出,这样才能体现数据的价值。
15.2 数据质量方法概述
- 消费场景知晓。主要通过数据资产等级和基于元数据的应用链路分析解决消费场景知晓的问题。根据应用的影响程度,确定资产等级;根据数据链路血缘,将资产等级上推至各数据生产加工的各个环节,确定链路上所涉及数据的资产等级和在各加工环节上根据资产等级的不同所采取的不同处理方式。
- 数据生产加工各个环节卡点校验。主要包括在线系统和离线系统数据生产加工各个环节的卡点校验。在线系统校验主要包括两个方面:根据资产等级的不同,当对应的业务系统变更时,决定是否将变更通知下游;对于高资产等级的业务,当出现新业务数据时,是否纳入统计中,需要卡点审批。离线系统生产加工各环节卡点校验主要包括代码开发、测试、发布和历史或错误数据回刷等环节的卡点校验,针对数据资产等级的不同,对校验的要求有所不同。
- 风险点监控。主要是针对在数据日常运行过程中可能出现的数据质量和时效等问题进行监控,包括在线数据和离线数据的风险点监控两个方面。在线数据的风险点监控主要是针对在线系统日常运行产出的数据进行业务规则的校验,以保证数据质量,其主要使用实时业务检测平台BCP(Biz Check Platform);离线数据的风险点监控主要是针对离线系统日常运行产出的数据进行数据质量监控和时效性监控,其中数据质量监控主要使用DQC,时效性监控主要使用摩萨德。
- 质量衡量。对质量的衡量既有事前的衡量,如DQC覆盖率;又有事后的衡量,主要用于跟进质量问题,确定质量问题原因、责任人、解决情况等,并用于数据质量的复盘,避免类似事件再次发生。
- 质量配套工具。针对数据质量的各个方面,都有相关的工具进行保证,以提高效能。
15.2.1 消费场景知晓
基于不断膨胀的数据和对数据类的应用,阿里巴巴内部提出了数据资产等级的方案,旨在解决消费场景知晓的问题。
- 数据资产等级定义。最终将数据分为五个等级,即毁灭性质、全局性质、局部性质、一般性质和未知性质,不同性质的重要性依次降低,如果一份数据出现在多个应用场景中,则遵循就高原则。
- 数据资产等级落地方法。有了数据产品或者数据应用的概念,同时也知道了哪些表是为哪个数据产品或者应用服务的,就可以借助强大的元数据知道整个数据仓库中的哪些表服务于这个数据产品,因此通过给不同的数据产品或者应用划分数据资产等级,再依托元数据的上下游血缘,就可以将整个消费链路打上某一类数据资产的标签,这样就可以将数以亿计的数据进行分类了。
15.2.2 数据加工过程卡点校验
- 在线系统卡点校验。主要是指在在线业务系统(OLTP)的数据生成过程中进行的卡点校验。在线业务复杂多变,总是在不断地变更,每一次变更都会带来数据的变化,数据仓库需要适应这多变的业务发展,及时做到数据的准确性。为了保障在线数据和离线数据的一致性,阿里巴巴在使用数据仓库的不断摸索中总结出两个行之有效的方法:工具和人员双管齐下。既要在工具上自动捕捉每一次业务的变化,同时也要求开发人员在意识上自动进行业务变更通知。工具,首先是发布平台。其次是数据库表的变化感知。
- 离线系统卡点校验。如何保障数据加工过程中的质量,是离线数据仓库保障数据质量的一个重要环节。首先是代码提交时的卡点校验。其次是任务发布上线时的卡点校验。发布上线前的测试主要包括Code Review和回归测试。回归测试一方面要保证新逻辑的正确:另一方面要保证不影响非此次变更的逻辑。最后是节点变更或数据重刷前的变更通知。一般建议使用通知中心的将变更原因、变更逻辑、变更测试报告和变更时间等自动通知下游,下游对此次变更没有异议后,再按照约定时间执行发布变更,将变更对下游的影响降至最低。
15.2.3 风险点监控
主要是针对数据在日常运行过程中容易出现的风险进行监控并设置报警机制,主要包括在线数据和离线数据运行风险点监控。
- 在线数据风险点监控。主要根据业务规则对数据进行监控。针对数据库表的记录进行规则校验,当校验不通过时,以报警的形式披露出来给到规则订阅人,以完成数据的校对。配置和运行成本较高,主要根据数据资产等级进行监控。
- 离线数据风险点监控。主要包括对数据准确性和数据产出及时性的监控。数据准确性,阿里巴巴主要使用DQC来保障数据的准确性,DQC检查其实也是运行SQL任务,只是这个任务是嵌套在主任务中的,一旦检查点太多自然就会影响整体的性能,因此还是依赖数据资产等级来确定规则的配置情况。类似的规则都是由离线开发人员进行配置来确保数据准确性的。数据及时性,则需要进行一系列的报警和优先级设置,使得重要的任务优先且正确产出。可以根据当前业务上所有任务最近7天运行的平均时间来推算的,虽然有误判的可能性,但是总体还是非常准的,可以接受。
调度是一个树形结构,当配置了叶子节点的优先级后,这个优先级会传递到所有上游节点,所以优先级的设置都是给到叶子节点,而叶子节点往往就是服务业务的消费节点。
15.2.4 质量衡量
- 数据质量起夜率。如果频繁起夜, 则说明数据质量的建设不够完善。
- 数据质量事件。首先,用来跟进数据质量问题的处理过程;其次,用来归纳分析数据质量原因;第三,根据数据质量原因来查缺补漏,既要找到数据出现问题的原因,也要针对类似问题给出后续预防方案。
- 数据质量故障体系。对于严重的数据质量事件,将升级为故障。故障,是指问题造成的影响比较严重,已经给公司带来资产损失或者公关风险。一旦出现故障,就会通过故障体系,要求相关团队第一时间跟进解决问题,消除影响。a. 故障定义:首先识别出重要的业务数据,并注册到系统中,一旦延迟或错误即自动生成故障单,形成故障。b. 故障等级:根据一定的标准判断故障等级,各团队会有故障分的概念,到年底会根据故障分情况来判断本年度的运维效果。c. 故障处理:需要快速地识别故障原因,并迅速解决,消除影响。d. 故障Review:分析故障的原因、处理过程的复盘、形成后续解决的Action,并且都会以文字的形式详细记录,对故障的责任进行归属,一般会到具体的责任人。注意,对故障责任的判定,不是为了惩罚个人,而是通过对故障的复盘形成解决方案,避免问题再次发生。
第16章:数据应用
本章主要介绍两个应用:提供给外部商家使用的数据产品平台一一生意参谋和服务于阿里巴巴内部的数据产品平台。
16.1 生意参谋
在对外产品方面,阿里巴巴主要以“生意参谋”作为官方统一的数据产品平台,为商家提供多样化、普惠性的数据赋能。
16.1.1 背景概述
商家只要通过生意参谋一个平台,就能体验统一、稳定、准确的官方数据服务。目前平台的数据巳覆盖淘宝、天猫等阿里系所有平台和PC、无线等终端,涉及指标上千个。在产品功能方面,已拥有店铺自有分析、店铺行业分析、店铺竞争分析三大基础业务模块。另外,它还支持多个专题工具的使用和自助取数等个性化需求。
16.1.2 功能架构与技术能力
目前平台共有七个板块,除首页外,还有实时直播、经营分析、市场行情、自助取数、专题工具、数据学院。从商家实际应用场景来看,这些数据服务可以划分为三个维度,即看我情、看行情和看敌情。
- 看我情。分析“我情”是店铺数据化运营的根本,主要基于店铺经营全链路的各个环节进行设计。
- 看行情。生意参谋通过市场行情,为商家提供了行业维度的大盘分析,包括行业洞察、搜索词分析、人群画像等。
- 看敌情。竞争对手的数据十分敏感,生意参谋的产品设计原则之一又是确保商家数据安全。我们的解决方案是推出“竞争情报”这一专题工具, 在保障商家隐私和数据安全的前提下提供竞争分析。
其实数据服务并不是提供得越多越好,还要注重数据的统一性、及时性和准确性;否则,数据提供越多,给商家带来的困扰可能就越大。平台背后看不见的“数据中台”给生意参谋提供了大量技术保障。OneData体系、One ID技术等在其中为生意参谋等数据产品提供了稳定的技术支持。
16.1.3 商家应用实践
一方面,生意参谋不断开放阿里巴巴的大数据能力;另一方面,其服务对象正受益于大数据,基于数据不断提升自身运营效率和获客能力。
16.2 对内数据产昂平台
16.2.1 定位
数据产品的本质是产品,既然是产品,那么首先要回答用户是谁,用户的痛点是什么,产品要解决用户的哪些痛点,即产品给用户带来的价值是什么。对于企业内部数据产品,它的用户是公司的员工,包括销售、BD、运营、产品、技术、客服、管理者等多种角色:解决的痛点是用户对业务发展中的数据监控、问题分析、机会洞察、决策支持等诉求,提供给用户高效率获取数据、合理分析框架、数据辅助业务决策的价值。
16.2.2 产品建设历程
- 临时需求阶段。当时还没有数据产品的概念,用户诉求主要以临时取数方式满足,用户需要了解业务基本数据时,提交需求给数据仓库团队,数据工程师通过编写代码,将数据跑好,再给到用户,基本靠人力在做支持。
- V2.0自动化报表阶段。基于之前在数据仓库技术、业务支撑方面的经验积累,数据仓库团队将相似的需求合并同类项的同时总结提炼,并且引入BI工具,通过报表和Dashboard的方式将数据需求固化下来,进而实现了自动化。数据门户,将报表和集市以业务主题的方式进行组织。
- 自主研发Bl工具阶段。是真正意义上自主研发数据产品或工具的阶段,是不断积累业务需求及产品规划和技术的过程,为后续做数据平台打下了坚实的基础。
- V4.0数据产品平台。业务对数据的诉求越来越精细化和多元化。为阿里巴巴内部用户打造一站式数据获取、数据分析、数据应用的数据产品平台。我们根据不同的业务场景,规划落地了较多场景化或专题类的分析型数据产品。
16.2.3 整体架构介绍
数据质量和数据安全是数据产品最基础的要求。阿里数据平台共有四个层次,即数据监控、专题分析、应用分析和数据决策。
- 数据监控。提供最基础的报表工具,供用户自助取数、多维分析、DIY个性化数据门户。
- 专题分析。按照分析师沉淀的成熟分析思路组织数据,实现行业运营小二自助分析行业异动原因,发现行业潜在机会,实现“人人都是分析师”,提高数据化运营的效率和质量。
- 应用分析。通过对接前台系统,实现数据的自动化。不仅能够通过勾选条件筛选出目标数据,同时还能够做自助分析,调整条件满足需求后直接对接前台应用系统,实现个性化、精准营销、选品选商、搭建专场的需求。
- 数据决策。提供定制化的数据产品供决策参考,为高管提供宏观决策分析支撑平台,分析历史数据规律,预测未来发展趋势,洞察全行业动态。