索引原理-索引数据结构
推荐一个学习树结构的网站 --> 树结构学习网站
本文目录:
- 二叉树
- 红黑树
- Hash表
- B树
- B+树
- 巨簇索引
- 非巨簇索引
- 联合索引
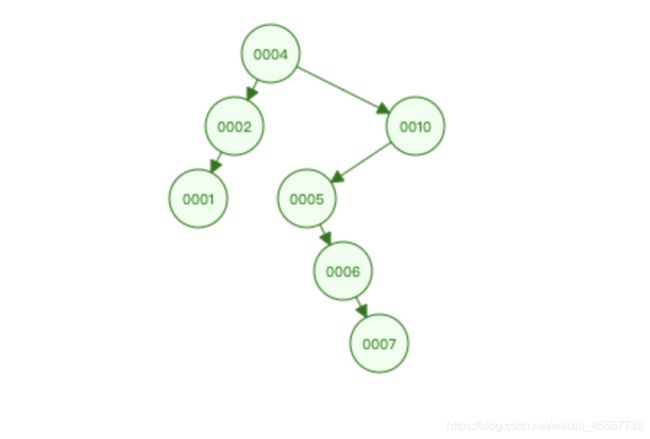
一. 二叉树
插入顺序: 4 2 1 10 6 7
首先, 左侧叶子节点 < 主节点 < 右侧叶子节点
我们乱序插入一些数据, 我们会发现0010这个节点被“孤立”了, 随着数据量的增加树的H(高度)会随之增加, 当我们加到了N的数据量后, 我们再查询这个N. 那么这个树搜索会从根直至到N这个位置, 对于自增的表列而言, 并没有明显提供查询性能. 而且有些节点甚至可能会独立存在, 拉高了树的H.
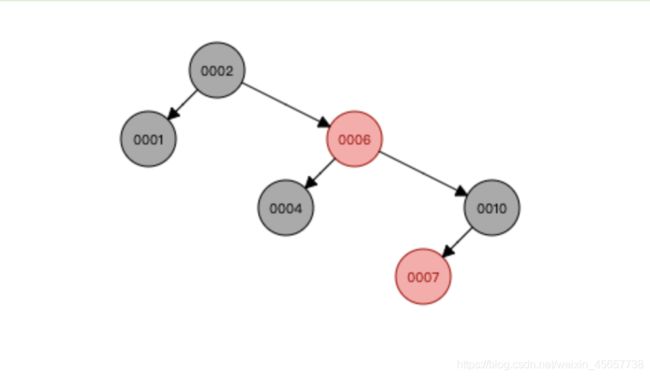
二. 红黑树
插入顺序: 4 2 1 10 6 7
我们会发现这棵树, 在添加的过程中, 会字段平衡节点与叶子节点之间的关系, 当一侧单向高时, 会把大于和小于的节点提上来, 左面是小于这个节点的, 右面是大于这个节点的, 它相比于二叉树, 有了一个自动平衡的功能, 但是与二叉树有一个相同的特点, 虽然数据量的增加树的高度会无限增加. 所以数据库的索引不会使用这个红黑树, 而JDK8的hashMap是数组+红黑树, 每个bucket内的红黑树节点数量也会有控制.
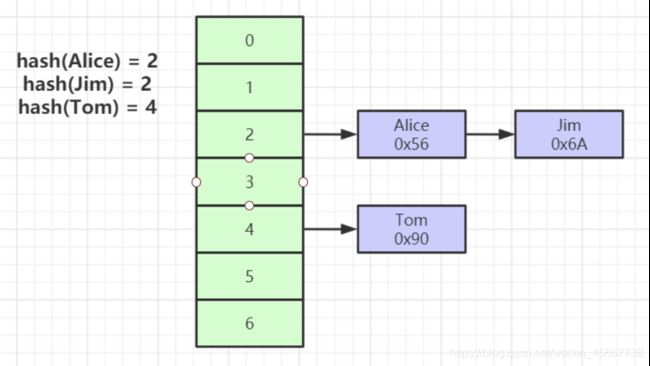
三. Hash表
Hash表的索引优缺点也显而易见, 对于where条件之后的=查询, 它是可以精确到桶的位置, 然后再看桶内数据哪条数据符合条件, 拿着地址去找数据.
但是缺点也很明显, hash冲突, 如果链表数据过多, 反而失去了索引的该有的优势, 而且它并不支持范围查询.
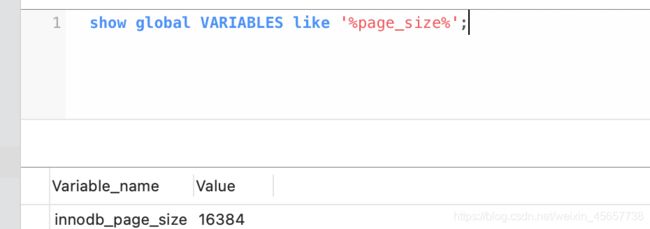
查看引擎的页大小, 大约为16K
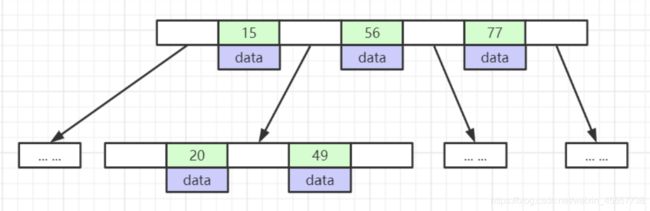
四. B树
B树, 以自增主键举例, 15,56,77,20,49就是id值, 每一个id值下面会挂着一条数据, 主节点和叶子节点是不能重复的.
五. B+树
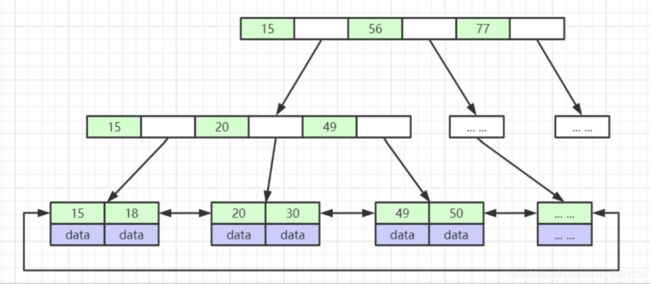
B+树, B树的升级版, 我们会发现相比于B树, 主节点的值是可以和叶子节点重复的, 最终会定位到最终一行上, 获取data数据. 而且data数据是一个双向链表关系. 相比于B树有什么有数呢?
- 主节点来看 如果主键ID是bigint类型, 那么它是8个字节, 白色的地方是指向叶子节点的地址, 在C语言中是6个字节, 那么一对就是14byte, 以页为单位, 一个页可以放16000/14=1143, 以H为3为例, 第二层的量为1143 * 1143 = 1306449, 那么第三层再翻倍, 除去重复的肯定比B数结构的量多的多(data以1KB算, 16000/1014=15 第二层猜15*15).
- data双向链表就决定了B+的数据可以范围查询, 而B树有点类似与Hash表的查询了(最后一行的数据是左小右大, 但是对于范围来说查询影响不大)
六. 巨簇索引
我们先在服务器上安装一个mysql, 创建一个test数据库,
再创建一个 test_innodb的innoDB引擎的表
再创建一个test_myisam的MyISAM引擎的表
我们进入到 /var/lib/mysql路径下, 会发现以数据库命名的文件夹, 我们进到test目录下

我们发现不同引擎的数据文件是不一样的.
innoDB引擎的文件有frm和ibd, frm是表的结构数据, ibd是索引和数据的文件
MyISAM引擎的文件有frm和MYD以及MYI, frm仍然是表的结构数据, MYD是数据文件, MYI是索引数据文件.
不难发现, MyISAM将索引和数据解藕存储, 但是每次查询需要两个文件联查. 在数据量以及索引足够大时MyISAM是占优的, 但是在现如今硬件足够优秀, 以及可以控制好树的高度情况下, innoDB的效率也不会比MyISAM差. 甚至更优.
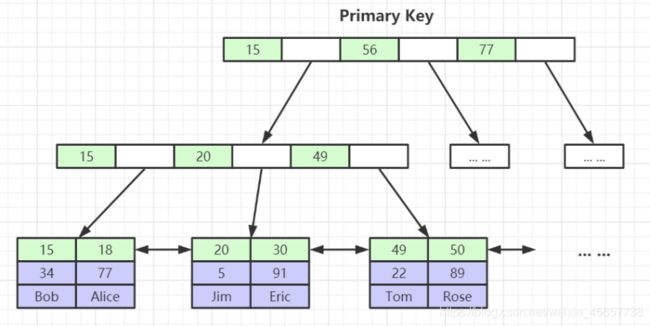
巨簇索引
通过mysql的数据文件, 我看可以看出来InnoDB的索引和数据都在.ibd文件里, 那么数据结构也就是如下, data数据就是行数据.
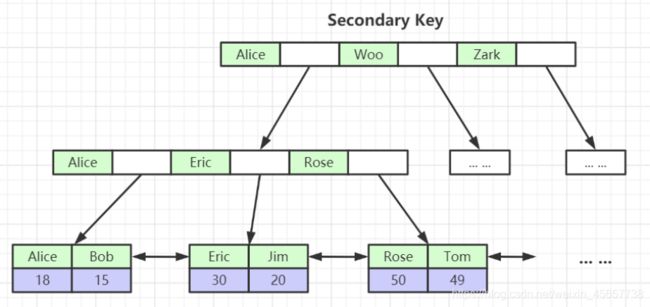
name字段创建B Tree索引
在巨簇索引存在下, 那么再创建索引字段, 他的结构就如下所示, 最终指向了ID的值.
从这里我们可以看出来, 创建一个表带上主键是多么的重要!!!
为什么使用自增作为主键? 如果是UUID这种, 那么树节点排序还需要计算ASCII值去比对. 相对于树结构的特性自增是很好的选择!!!
七. 非巨簇索引(MyISAM的主键索引)
我们查看数据库的MyISAM的数据文件可以知道, 索引是MYI文件, 数据文件是MYD, 那么他的结构也就是如下所示, data指向的是数据地址.
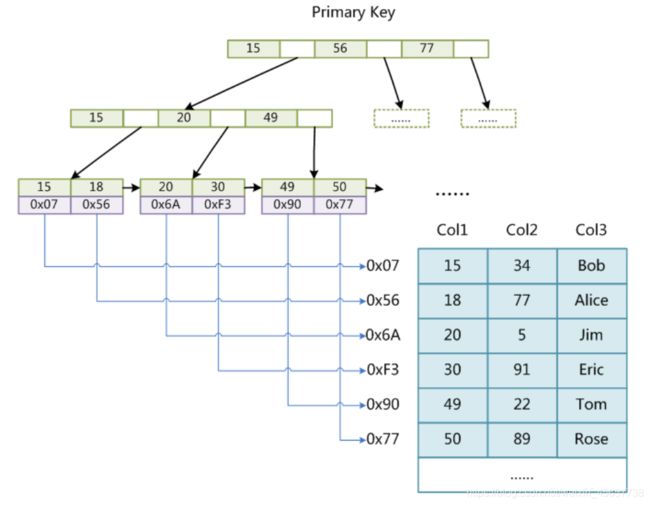
八. 联合索引(左前缀原则)
节点排列我们知道一定是顺序排列, 那么如果是多个字段做联合索引, 那么它的排列一定是一个字段排序, 相同时第二个对比, 第二个也相同再比对第三个字段数据的ASCII值.
那么我们就可以知道, 如果查询where name = 'Bill’和where name = ‘Lilei’ and age = 30是可以走索引的
如果直接where position = 'dev’是无法走索引的
