统计学方法论2---------推断统计分析:通过样本推断总体
推断统计分析:通过样本推断总体
- 1、概述
- 2、点估计和区间估计
-
- 2.1、点估计
- 2.2、区间估计
-
- 2.2.1、中心极限定理
- 2.2.2、正态分布特征(数据分布比例)==图很重要==
- 3、假设检验(反证法思想)(有很多假设检验方式)
-
- 3.1、小概率事件
- 3.2 P-Value与显著性水平
- 3.3、假设检验的步骤
- 4、常用的假设检验
-
- 4.1、Z检验
- 4.2、t检验(更常用,因为一般总体方差都不知道)
-
- 4.2.1、t检验原理及验证
- 4.2.2、scipy提供的stats.ttest_lsamp方法计算t检验
注意学习方式,学习本部分是为数据分析铺垫,不关注数学公式的推导,关注结果及代码验证
理解假设检验的方法,会看结果代表什么,计算可以调库实现
1、概述
总体、个体、样本
2、点估计和区间估计
2.1、点估计
点估计使用样本代替总体,易受到随机抽样的影响,无法保证结论的准确性
2.2、区间估计
置信度:总体参数有多大的概率位于置信区间
置信区间:均值±1/2/3倍标准差
使用置信区间与置信度,表示总体参数有多少可能(置信度)会在某范围(置信区间内)
2.2.1、中心极限定理
如果总体(是不是正态分布无所谓)均值为μ,方差为σ²,那我们进行随机抽样,样本容量为n,当n增大时,则样本均值逐渐趋近服从正态分布:
![]()
中心极限定理结论:
-
多次抽样,每次抽样计算出一个均值,这些均值会围绕在总体均值左右,呈正态分布
-
样本容量n足够大时,样本均值服从正态分布:
- 样本均值构成的正态分布,其均值等于总体的均值μ
- 样本均值构成的正态分布,其标准差等于总体标准差σ/根号n
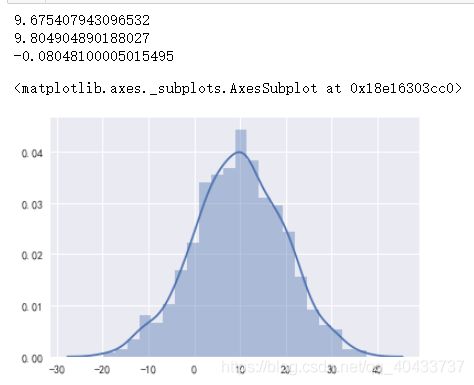
代码验证样本均值构成的正态分布:
#验证从总体中随机抽样n次,得到的样本均值分布是否为正态分布
test=np.random.normal(loc=10,scale=80,size=10000)
mean_array=np.zeros(1000)
for i in range(len(mean_array)):
#注意此处replace为False代表本次抽样的过程64个是不能放回去的。本次抽样完成,进行下次抽样时这64个才放回去
mean_array[i]=np.random.choice(test,size=64,replace=False).mean()
#1000次样本均值的均值
print(mean_array.mean())
#标准误差,简称标准误。为总体的标准差/根号n
print(mean_array.std())
#注意skew需要pandas才能用
print(pd.Series(mean_array).skew())
sns.distplot(mean_array)
2.2.2、正态分布特征(数据分布比例)图很重要
正态分布的均值、中位数、众数相等
其数据分布如下:
- 以均值为中心,在一倍标准差内,包含68%的样本数据
- 以均值为中心,在二倍标准差内,包含95%的样本数据
- 以均值为中心,在三倍标准差内,包含99.7%的样本数据

#验证正态分布的数据分布概率
#标准差50
scale=50
test=np.random.normal(0,scale,size=100000)
#分别计算一倍标准差,二倍及三倍下数据分布的概率
for i in range(1,4):
test_scale=test[(test>(-i*scale))&(test<i*scale)]
p=len(test_scale)*100/len(test)
print('{}倍标准差概率为{}%' .format(i,p))

应用:基于以上理论,验证一次抽样的结果,是否真的落在置信区间内
理解:对总体进行1次抽样,该样本的均值有95%的概率落在二倍标准差内(此处的标准差为样本均值构成的正态分布的标准差,也称为标准误,不要理解错了)
#验证一次抽样结果,是否在2倍标准差内
#随机获取一个总体的均值
mean=np.random.randint(-10000,10000)
print('总体均值:',mean)
std=50
#构造一个总体,正态分布
test=np.random.normal(mean,std,size=10000)
#从总体中进行一次抽样,n=50,并求均值
one_mean=np.random.choice(test,size=50,replace=False).mean()
print('一次抽样样本的均值:',one_mean)
plt.plot(mean,0,marker='*',color='orange',ms=15)
plt.plot(one_mean,0,marker='o',color='r')
one_std=std/np.sqrt(50)
left_one=mean-2*one_std
right_one=mean+2*one_std
print('95%置信度的置信区间为:',(left_one,right_one))
plt.axvline(left_one,color='r',ls='--',label='左边界')
plt.axvline(right_one,color='g',ls='--',label='右边界')
plt.legend()
plt.show()


3、假设检验(反证法思想)(有很多假设检验方式)
原假设、备则假设
认为取一次事件,不可能发生小概率事件
3.1、小概率事件
置信区间外,就认为他是小概率事件,一次抽样是不可能发生的。所以拒绝原假设
3.2 P-Value与显著性水平
显著性水平使用α
α=0.05=1-置信度
当P-Value(支持原假设的概率)大于α即0.05时,支持原假设,否则拒绝
3.3、假设检验的步骤
- 设置原假设和备择假设
- 设置显著性水平α,一般α=0.05
- 根据问题,选择假设检验的方式,并计算统计量(z检验就是计算z),通过统计量获取P值
- 根据P值和α值,判断结果
4、常用的假设检验
4.1、Z检验
适用场景:
- 总体呈正态分布
- 总体方差已知
- 样本容量较大(≥30)
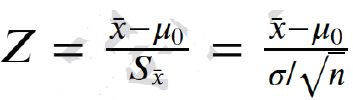

- 理解:样本均值-总体均值即为偏离中心均值的程度,除以标准误差,即可得出是正态分布的1倍(68%)还是2倍(95%)还是3倍(99.7%),Z若小于2代表该值在置信区间内,P值大于5%,原假设成立。若Z大于2,说明原假设落在了95%之外,为小概率事件,原假设不成立。
- 代码验证:鸢尾花平均花瓣长度为3.5cm,是否可靠?
#通过t检验验证鸢尾花花瓣长度为3.5cm是否可靠
iris = load_iris()
iris_data=np.concatenate((iris.data,iris.target.reshape(-1,1)),axis=1)
df=pd.DataFrame(iris_data,columns=['sepal length','sepal width','petal length','petal width','type'])
#假设可靠,那么总体的均值为3.5。
#计算样本均值
df_mean=df['petal length'].mean()
std=1.8
z=(df_mean-3.5)/(std/np.sqrt(len(df)))
print(z)
![]()
z=1.755,小于2,说明在2倍标准差内,P应该大于5%,接受原假设
4.2、t检验(更常用,因为一般总体方差都不知道)
4.2.1、t检验原理及验证
与Z检验类似,t检验是基于t分布的。随着样本容量增大,t分布接近正态分布,此时t检验近似Z检验
使用场景:
- 总体呈正态分布
- 总体方差未知
- 样本容量较少(<30)(大于30也可以,只不过近似Z检验)


- 原理同z检验,区别在于使用样本均值的标准误差
- 代码验证:
#t检验
df_mean=df['petal length'].mean()
df_std=df['petal length'].std()
t=(df_mean-3.5)/(df_std/np.sqrt(len(df)))
print(t)
![]()
t小于2,说明在2倍标准差内,P应该大于5%,接受原假设
4.2.2、scipy提供的stats.ttest_lsamp方法计算t检验
from scipy import stats
tt=stats.ttest_lsamp(df['petal length'],3.5)
print('t值',tt.statistic)
print('p值',tt.pvalue)
t值为偏离均值多少倍的标准差
p值为p_value,大于0.05即不能推翻原假设