数据结构之图:单源最短路径算法详解与Java实现(Dijkstra算法与Bellman-Ford算法)
一、几个需要清楚的问题
1.问题定义
给定一个有向带权图 G = ( V , E , W ) G=(V,E,W) G=(V,E,W),图中一条路径 p = < v 0 , v 1 , ⋯ , v k > p=
从结点 u u u到结点 v v v的最短路径权重 δ ( u , v ) \delta(u,v) δ(u,v)定义为: δ ( u , v ) = { m i n { w ( p ) : u → v } i f e x i s t p a t h f r o m u t o v ∞ e l s e \delta(u,v)=\begin{cases}min\{w(p):u\to v\}&if\ exist\ path\ from\ u\ to\ v\\ \infty&else\end{cases} δ(u,v)={ min{ w(p):u→v}∞if exist path from u to velse
而结点 u u u到结点 v v v的最短路径就是任意一条权重为 w ( p ) = δ ( u , v ) w(p)=\delta(u,v) w(p)=δ(u,v)的从 u u u到 v v v的路径 p p p
2.最优子结构
最优子结构-最短路径的子路径也是最短路径
设 p = < v 0 , v 1 , ⋯ , v k > p=
证明(反证法):
有 w ( p ) = w ( p 0 i ) + w ( p i j ) + w ( p j k ) w(p)=w(p_{0i})+w(p_{ij})+w(p_{jk}) w(p)=w(p0i)+w(pij)+w(pjk),若 p i j p_{ij} pij不是一条 i i i到 j j j的最短路径,则存在一条 i i i到 j j j的路径,使得 w ( p i j ′ ) < w ( p i j ) w(p^{'}_{ij})
证毕。
3.松弛操作
设 d i s [ x ] dis[x] dis[x]是结点 x x x当前离源点的距离最小值, p a r e n t [ x ] parent[x] parent[x]表示路径上的前驱结点。松弛操作可表示为:
i f if if d i s [ v ] > d i s [ u ] + w ( u , v ) dis[v]>dis[u]+w(u,v) dis[v]>dis[u]+w(u,v)
d i s [ v ] = d i s [ u ] + w ( u , v ) dis[v]=dis[u]+w(u,v) dis[v]=dis[u]+w(u,v)
p a r e n t [ v ] = u parent[v]=u parent[v]=u
也即,发现经过 u u u结点可以更快到达 v v v,则“经过 u u u”来使得到达 v v v路径更短。
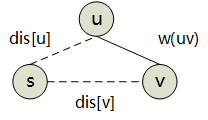
视觉上看,路径增多了一条,路线更松,故称之为"松弛操作"。
4.负权重的边
了解过Dijkstra算法后再看,可知,它通过"最近邻居"来选择直接一条新的可以确定的最短路径。而这需要没有负权重的边。
若有负权边,如下图:根据Dijkstra算法,v将直接被确定其最短路径为3,因为我们认为不可能绕路却比最短直达还近,但事实上,由于负权边的存在,可以通过"绕路"来实现"松弛操作",也即找到一条更短的路径。

5.负权环
无论是Dijkstra算还是Bellman-Ford算法,在有负权环的图中都无法正常工作(但Bellman-Ford算法可以检测出负权环),如图所示:

由于负权环的存在,每走一轮环都可以使得代价变小,因此,通过无休止地转圈 w → u → v ⋯ → w w\rightarrow u \rightarrow v\cdots\rightarrow w w→u→v⋯→w可以使得到 w , u , v w,u,v w,u,v和 X X X中所有结点的最短路径都是 − ∞ -\infty −∞
二、Dijkstra算法
1.适用范围
有向图/无向图+无负权边
2.算法原理
现有集合 S S S,其中包括源结点 s s s和一些已知最短路径的结点,这些结点记录了离 s s s的最短距离及其前驱;集合 V V V,包含所有未知最短路径的结点,其中与 S S S有邻接关系结点记录了经过 S S S中的某些结点的离 s s s的已知的最短距离及其前驱;未与 S S S相邻的结点路径是未可知的,记为无穷。
以下图为例:
S = { s , a , b , c } , V = { d , e , f , g } S=\{s,a,b,c\},V=\{d,e,f,g\} S={ s,a,b,c},V={ d,e,f,g},红色上标为已知的最短路径,黑色上标为待定的最短路径。

1)若可以从集合 V V V中取得结点,确定其最短路径,之后将其放置于集合 S S S中,如此一来便扩大了确定了短路径的结点数,如此反复,即可完成所有的结点最短路径确定。
办法为:
从 V V V中获取待定最短距离最小的点,确定其最短距离并将其归入 S S S,图中即为 e e e,然后通过该点更新 V V V中其它结点的待定距离值, d d d的值更新为6, g g g的值更新为7。
证明其可行性(反证法):
若刚刚确定的结点 e e e不是 V V V中离 s s s最近的结点,而是另一个结点 e ′ e^{'} e′:(1)若 e ′ e^{'} e′与集合 S S S相邻,则 e ′ e^{'} e′必然是e,与假设矛盾。(2)若 e ′ e^{'} e′不与集合 S S S相邻,则该路径必然经过两个集合的边界,而此时可取路径上 V V V那个边界点作为终点,其最短路径小于到 e ′ e^{'} e′最短路径,而此时该点必然是e,与假设矛盾。
该算法与Prim算法较为相似,都是将已经确定的结点置入一个集合,然后选择代价最小(本算法是离源点最近-Prim算法是离已生成的树最近)的非集合中的结点使之加入集合,并更新与该节点相邻结点的信息。因此,该算法首先将所有结点离源点距离置为无穷,将源点距离置为0表示源已经添加至集合中,更新其相邻结点信息。之后重复1)的步骤。
3.算法步骤
结点信息设置,两个信息,一个是结点离s的当前最短距离,一个是前驱结点
S t e p 1 : Step1: Step1:集合S用于保存已知最短路径的结点,初始为空;s的当前最短路径设置为0
S t e p 2 : Step2: Step2:将所有结点按照当前最短路径推入优先级队列
S t e p 3 : Step3: Step3:当队列非空时循环:(1)取出队头结点,即离s最近的结点u,将其归入S集合(2)通过结点u的信息来更新u的邻接结点的信息。直至队列为空。
S t e p 3.2 : Step3.2: Step3.2:更新操作具体为:循环u的所有邻接点v,若v的当前最短路径>u的当前最短路径+w(u,v),则说明v经过u会离s更近,故更新当前最短距离以及前驱结点。
4.伪代码(参考自算法导论)
1. S = ∅ 1.S=\varnothing 1.S=∅
2. Q = G . V 2.Q=G.V 2.Q=G.V
3. w h i l e 3.while 3.while Q ≠ ∅ Q\ne\varnothing Q=∅
u = Q . p o l l ( ) u=Q.poll() u=Q.poll()
S = S ∪ { u } S=S\cup \{u\} S=S∪{ u}
f o r for for v ∈ G . A d j [ u ] v\in G.Adj[u] v∈G.Adj[u]
i f if if v . d i s > u . d i s + w e i g h t ( u , v ) v.dis>u.dis+weight(u,v) v.dis>u.dis+weight(u,v)
v . d i s = u . d i s + w e i g h t ( u , v ) v.dis=u.dis+weight(u,v) v.dis=u.dis+weight(u,v)
v . p a r e n t = u v.parent=u v.parent=u
5.算法图解
初始状态,A为源点

| 结点 | A | B | C | D | E |
|---|---|---|---|---|---|
| 当前最短路径 | 0 | INF | INF | INF | INF |
| 是否确定 | false | false | false | false | false |
| 前驱结点 | A | null | null | null | null |
1.当前最短路径最小的且未确定的结点是A,故A出队,将其并入S集合,依次对所有邻边进行松弛。

| 结点 | A | B | C | D | E |
|---|---|---|---|---|---|
| 当前最短路径 | 0 | 5 | 2 | 6 | INF |
| 是否确定 | true | false | false | false | false |
| 前驱结点 | A | A | A | A | null |
2.当前最短路径最小的且未确定的结点是C,故C出队,将其并入S集合,依次对所有邻边进行松弛。
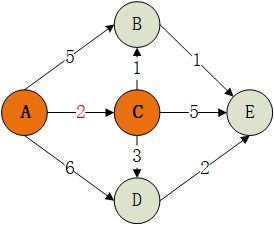
| 结点 | A | B | C | D | E |
|---|---|---|---|---|---|
| 当前最短路径 | 0 | 3 | 2 | 5 | 7 |
| 是否确定 | true | false | true | false | false |
| 前驱结点 | A | C | A | C | C |
2.当前最短路径最小的且未确定的结点是B,故B出队,将其并入S集合,依次对所有邻边进行松弛。

| 结点 | A | B | C | D | E |
|---|---|---|---|---|---|
| 当前最短路径 | 0 | 3 | 2 | 5 | 4 |
| 是否确定 | true | true | true | false | false |
| 前驱结点 | A | C | A | C | C |
2.当前最短路径最小的且未确定的结点是E,故E出队,将其并入S集合,依次对所有邻边进行松弛。

| 结点 | A | B | C | D | E |
|---|---|---|---|---|---|
| 当前最短路径 | 0 | 3 | 2 | 5 | 4 |
| 是否确定 | true | true | true | false | true |
| 前驱结点 | A | C | A | C | B |
2.当前最短路径最小的且未确定的结点是D,故D出队,将其并入S集合,依次对所有邻边进行松弛。

| 结点 | A | B | C | D | E |
|---|---|---|---|---|---|
| 当前最短路径 | 0 | 3 | 2 | 5 | 4 |
| 是否确定 | true | true | true | true | true |
| 前驱结点 | A | C | A | C | B |
单源最短路径完成
6.代码实现
先给出数据结构
邻接矩阵结构为:
public class MGraph<E>{
private static final int maxWeight = 10000;
private static final int maxVertices = 100;
private ArrayList<E> Vertices; //顶点
private int[][] edge; //边
private int numOfEdges; //边数量
}
邻接表结构为:
public class LGraph<E> {
private static final int maxVertices = 100;
private ArrayList<ListNode> Vertices; //存储头节点
private int numOfEdges; //边数
private int numOfVexs; //顶点数
private class EdgeNode{
//边结点结构
int nodeIndex; //指向的顶点索引
int weight; //权值
EdgeNode next; //下一条边
}
private class ListNode{
//头节点结构
E data; //结点信息
int headNodeIndex; //结点索引
EdgeNode headNode; //第一条邻接边
}
}
邻接矩阵实现
public void dijkstra(int source){
int size = Vertices.size();
if (source>size-1){
throw new IndexOutOfBoundsException();
}
int[][] index_distance_parent_visited = new int[size][4];
for (int i = 0; i < size; i++) {
//分别为结点序号,距离,前驱结点,是否已经访问的标记数组
index_distance_parent_visited[i][0] = i;
index_distance_parent_visited[i][1] = Integer.MAX_VALUE;
index_distance_parent_visited[i][2] = 0;
index_distance_parent_visited[i][3] = -1;
}
index_distance_parent_visited[source][1] = 0;
PriorityQueue<int[]> pq = new PriorityQueue<>(size, new Comparator<int[]>() {
@Override //优先级队列按距离排序
public int compare(int[] t1, int[] t2) {
return t1[1]-t2[1];
}
});
for (int i = 0; i < size; i++) {
//入队
pq.offer(index_distance_parent_visited[i]);
}
while (!pq.isEmpty()){
//队非空时循环
int[] u = pq.poll(); //取队头元素
int uIndex = u[0];
u[3] = 1;
for (int i = 0; i < size; i++) {
//松弛操作
int vIndex = index_distance_parent_visited[i][0];
if (edge[uIndex][vIndex]>0&&edge[uIndex][vIndex]<maxWeight&&index_distance_parent_visited[vIndex][1]>index_distance_parent_visited[uIndex][1]+edge[uIndex][vIndex]&&index_distance_parent_visited[i][3]==-1){
pq.remove(index_distance_parent_visited[vIndex]); //以出队入队代替队中位置更新操作
index_distance_parent_visited[vIndex][1]=index_distance_parent_visited[uIndex][1]+edge[uIndex][vIndex];
index_distance_parent_visited[vIndex][2] = uIndex;
pq.offer(index_distance_parent_visited[vIndex]);
}
}
}
//打印语句
for (int i = 0; i < size; i++) {
System.out.println(Vertices.get(index_distance_parent_visited[i][0])+":"+index_distance_parent_visited[i][1]);
}
}
邻接表实现
public void dijkstra(int source){
int size = Vertices.size();
if (source > size-1){
throw new IndexOutOfBoundsException();
}
int[][] index_distance_parent_visited = new int[size][size];
for (int i = 0; i < size; i++) {
index_distance_parent_visited[i][0] = i;
index_distance_parent_visited[i][1] = Integer.MAX_VALUE;
index_distance_parent_visited[i][2] = 0;
index_distance_parent_visited[i][3] = -1;
}
index_distance_parent_visited[source][1] = 0;
PriorityQueue<int[]> pq = new PriorityQueue<>(size, new Comparator<int[]>() {
@Override
public int compare(int[] t1, int[] t2) {
return t1[1]-t2[1];
}
});
for (int i = 0; i < size; i++) {
pq.offer(index_distance_parent_visited[i]);
}
while (!pq.isEmpty()){
int[] u = pq.poll();
int uIndex = u[0];
u[3] = 1;
EdgeNode p = Vertices.get(uIndex).headNode;
while (p!=null){
int vIndex = p.nodeIndex;
if (p.weight>0&&p.weight<Integer.MAX_VALUE&&index_distance_parent_visited[vIndex][1]>index_distance_parent_visited[uIndex][1]+p.weight){
pq.poll();
index_distance_parent_visited[vIndex][1] = index_distance_parent_visited[uIndex][1]+p.weight;
index_distance_parent_visited[vIndex][2] = uIndex;
pq.offer(index_distance_parent_visited[vIndex]);
}
p = p.next;
}
}
for (int i = 0; i < size; i++) {
System.out.println(Vertices.get(i).data+":"+index_distance_parent_visited[i][1]);
}
}
7.性能(优先级队列+邻接表存储的标准实现)
S t e p 1 : O ( 1 ) Step1:O(1) Step1:O(1)
S t e p 2 : O ( V ) Step2:O(V) Step2:O(V)
S t e p 3 : O ( V ⋅ l g V + E ⋅ l g V ) Step3:O(V\cdot lgV+E\cdot lg V) Step3:O(V⋅lgV+E⋅lgV)
故其时间复杂度为 O ( E ⋅ l g V ) O(E\cdot lg V) O(E⋅lgV)
可以使用斐波那契队优化到 O ( E + V ⋅ l g V ) O(E+V\cdot lg V) O(E+V⋅lgV)
8.性能(数组)
O ( V 2 ) O(V^2) O(V2)
三、Bellman-Ford算法
1.适用范围
有向图+有负权边/无负权边+无负权环
2.算法原理
根据第一章负权边部分所述Dijkstra算法不适用于带负权边的图,是因为即使相邻结点的最短路径也可以通过绕路来实现松弛操作,也就是说,有可能绕图中若干个点的路径相比已知的最短路径更短。那么,意味着有负权边的图需要尝试所有路径是否可以松弛来完成最短路径的确定。
图中共有 V V V个顶点,从某一个点到任意一个点最多经过 V − 1 V-1 V−1条边和 V V V个顶点,因此我们需要进行 V − 1 V-1 V−1轮的松弛操作尝试——>其中第 i i i轮尝试代表着找到了从源点出发经过 i i i条边所到达的所有顶点的“可能最短路径”,每轮都需要对所有边进行尝试。
若 V − 1 V-1 V−1轮松弛操作之后,某路径仍然可以被松弛,说明需要经过至少V+1个顶点,那么必然有一个顶点被经过了两次,也即存在负权环。
3.算法步骤
S t e p 1 : V − 1 Step1:V-1 Step1:V−1轮松弛操作
S t e p 1.1 : Step1.1: Step1.1:对所有路径进行松弛尝试
S t e p 2 : Step2: Step2:新一轮的松弛操作尝试,以判断是否有负权环
4.伪代码(参考自算法导论)
1. f o r 1.for 1.for i = 1 i=1 i=1 t o to to G . V − 1 G.V-1 G.V−1
1.1 f o r 1.1for 1.1for e d g e ( u , v ) ∈ G . E edge(u,v)\in G.E edge(u,v)∈G.E
i f if if v . d i s > u . d i s + w e i g h t ( u , v ) v.dis>u.dis+weight(u,v) v.dis>u.dis+weight(u,v)
v . d i s = u . d i s + w e i g h t ( u , v ) v.dis=u.dis+weight(u,v) v.dis=u.dis+weight(u,v)
v . p a r e n t = u v.parent=u v.parent=u
2. f o r 2.for 2.for e d g e ( u , v ) ∈ G . E edge(u,v)\in G.E edge(u,v)∈G.E
i f if if v . d i s > u . d i s + w e i g h t ( u , v ) v.dis>u.dis+weight(u,v) v.dis>u.dis+weight(u,v)
r e t u r n return return f a l s e false false
r e t u r n return return t r u e true true
5.算法图解

| 结点 | S | A | B | C | D | E |
|---|---|---|---|---|---|---|
| 当前最短路径 | 0 | INF | INF | INF | INF | INF |
| 前驱结点 | S | INF | INF | INF | INF | INF |
松弛操作顺序为(S,A)(S,E)(A,C)(B,A)(C,B)(D,A)(D,C)(E,D)
1.对所有边进行松弛操作:(S,A)(S,E)(A,C)(C,B)(E,D)可松弛
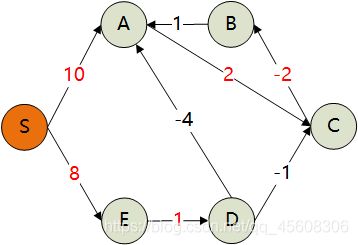
| 结点 | S | A | B | C | D | E |
|---|---|---|---|---|---|---|
| 当前最短路径 | 0 | 10 | 10 | 12 | 9 | 8 |
| 前驱结点 | S | S | C | A | E | S |
2.对所有边进行松弛操作:(D,A)(D,C)可松弛

| 结点 | S | A | B | C | D | E |
|---|---|---|---|---|---|---|
| 当前最短路径 | 0 | 5 | 10 | 8 | 9 | 8 |
| 前驱结点 | S | D | C | D | E | S |
3.对所有边进行松弛操作:(A,C)(C,B)可松弛

| 结点 | S | A | B | C | D | E |
|---|---|---|---|---|---|---|
| 当前最短路径 | 0 | 5 | 5 | 7 | 9 | 8 |
| 前驱结点 | S | D | C | A | E | S |
4.对所有边进行松弛操作:无可松弛边
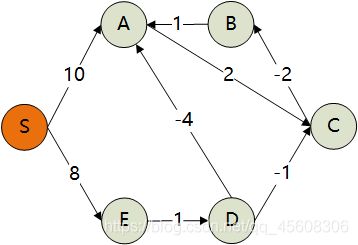
| 结点 | S | A | B | C | D | E |
|---|---|---|---|---|---|---|
| 当前最短路径 | 0 | 5 | 5 | 7 | 9 | 8 |
| 前驱结点 | S | D | C | A | E | S |
5.对所有边进行松弛操作:无可松弛边
最短路径完成
6.代码实现
邻接表实现
public boolean bellmanford(int source){
int size = Vertices.size();
if (source > size - 1){
throw new IndexOutOfBoundsException();
}
int[] dis = new int[size]; //最短距离数组
int[] parent = new int[size]; //前驱结点标记数组
for (int i = 0; i < size; i++) {
dis[i] = Integer.MAX_VALUE;
}
dis[source] = 0;
parent[source] = source;
for (int i = 0; i < size - 1; i++) {
//循环size-1次
for (int j = 0; j < size; j++) {
//处理所有边
int uIndex = j;
EdgeNode pNode = Vertices.get(j).headNode;
while (pNode!=null){
int vIndex = pNode.nodeIndex;
if (dis[uIndex] < Integer.MAX_VALUE&&dis[uIndex] + pNode.weight < dis[vIndex]) {
dis[vIndex] = dis[uIndex] + pNode.weight; //松弛操作
parent[vIndex] = uIndex;
}
pNode = pNode.next;
}
}
}
for (int j = 0; j < size; j++) {
//再次处理所有边,尝试松弛操作,判断是否有负权环
int uIndex = j;
EdgeNode pNode = Vertices.get(j).headNode;
while (pNode!=null){
int vIndex = pNode.nodeIndex;
if (pNode.weight<Integer.MAX_VALUE&&dis[uIndex]+pNode.weight<dis[vIndex])
return false;
pNode = pNode.next;
}
}
//打印结果
for (int i = 0; i < size; i++) {
System.out.println(""+Vertices.get(parent[i]).data+"->"+Vertices.get(i).data+":"+dis[i]);
}
return true;
}
7.性能分析
S t e p 1 : O ( V ) Step1:O(V) Step1:O(V)
S t e p 1.1 : O ( E ) Step1.1:O(E) Step1.1:O(E)
S t e p 1 : O ( E ) Step1:O(E) Step1:O(E)
故其时间复杂度为 O ( V ⋅ E ) O(V\cdot E) O(V⋅E)
四、队列优化的Bellman-Ford算法
1.原理
Shortest Path Faster Algorithm (SPFA)是一个使用队列优化的Bellman-Ford算法,容易看出Bellman-Ford算法的松弛操作是暴力进行的,即每一轮都对所有边进行松弛尝试,进行V-1轮,事实上,有一些边没有处理的必要。
源点s到达其他的点的最短路径中的第一条边,必定是源点s与s的邻接点相连的边,因此第一次松弛只需要将这些边松弛一下即可;第二条边必定是第一次松弛的时候的邻接点与这些邻接点的邻接点相连的边;依此类推。因此可以建立一个队列,开始时只有源点,源点出队,松弛与其邻接点相连的边,将松弛成功的点放入队列中,然后再次取出队列中的点,松弛该点与该点的邻接点相连的边,若松弛成功,判断这个邻接点是否在队列中,没有则将其入队,有则不做处理,直至队列为空。
换一个角度来说,相对于广度优先搜索,出队之后的结点有再入队的可能,也即该点被“优化”过了的情况。
2.伪代码
Q = s Q=s Q=s
w h i l e while while Q ≠ ∅ Q\ne\varnothing Q=∅
u = Q . p o l l ( ) u=Q.poll() u=Q.poll()
f o r for for v ∈ G . A d j [ u ] v\in G.Adj[u] v∈G.Adj[u]
i f if if v . d i s > u . d i s + w e i g h t ( u , v ) v.dis>u.dis+weight(u,v) v.dis>u.dis+weight(u,v)
v . d i s = u . d i s + w e i g h t ( u , v ) v.dis=u.dis+weight(u,v) v.dis=u.dis+weight(u,v)
i f if if v ∉ Q v\notin Q v∈/Q
Q . p u s h ( v ) Q.push(v) Q.push(v)
3.代码实现
邻接表实现
public void spfa(int source){
int size = Vertices.size();
if (source > size - 1){
throw new IndexOutOfBoundsException();
}
int[] dis = new int[size];
boolean[] flag = new boolean[size];
for (int i = 0; i < size; i++) {
dis[i] = Integer.MAX_VALUE;
flag[i] = false;
}
dis[source] = 0;
flag[source] = true;
Queue<Integer> queue = new LinkedList<>();
queue.offer(source);
while (!queue.isEmpty()){
int uIndex = queue.poll();
flag[uIndex] = false;
EdgeNode pNode = Vertices.get(uIndex).headNode;
while (pNode!=null){
int vIndex = pNode.nodeIndex;
if (pNode.weight<Integer.MAX_VALUE&&dis[uIndex]+pNode.weight<dis[vIndex]) {
dis[vIndex] = dis[uIndex] + pNode.weight;
if(!flag[vIndex]){
queue.offer(vIndex);
flag[vIndex] = true;
}
}
pNode = pNode.next;
}
}
for (int i = 0; i < size; i++) {
System.out.println(Vertices.get(i).data+":"+dis[i]);
}
}
4.性能
最坏情况下时间复杂度与Bellman-Ford算法相同为 O ( V ⋅ E ) O(V\cdot E) O(V⋅E),平均情况下要优于Bellman-Ford算法,但无具体定论。
五、小结
1.Dijkstra算法只适用于不带负权边的图,有向无向没有限制; Bellman-Ford算法和SPFA算法只适用于有向图,可处理带负权边但不带负权环的图。
2.标准Dijkstra算法(邻接表存储+优先级队列实现)的时间复杂度是 O ( E ⋅ l g V ) O(E\cdot lgV) O(E⋅lgV),可使用斐波那契堆优化到 O ( E + V ⋅ l g V ) O(E+V\cdot lgV) O(E+V⋅lgV);Bellman-Ford算法时间复杂度为 O ( V ⋅ E ) O(V\cdot E) O(V⋅E);SPFA算法平均情况下要优于BellmanFord算法,但最坏情况下仍然是 O ( V ⋅ E ) O(V\cdot E) O(V⋅E)。
3.三种算法都需要"松弛操作"来完成最小路径的选择–>通过视觉上更长的路径来寻求实际的更短路径。
4.有负权环的图将导致某些结点无法求得最短路径,或说最短路径为负无穷。