从构建进程间缓存设计谈Webpack5 优化和工作原理
编者按:本文转载自知乎专栏《颜海镜的博客》。快来一起学习吧!
今天,让我们把目光先聚焦到即将破土而出的 Webpack 5 上,尽管国内外已经有抢鲜试水的尝试,其中也不乏张立理的文章:Webpack 5 升级实验,讲述升级路径和体会,但是尚没发现从技术原理角度的设计解析。
这篇文章,我就以 Spec: A module disk cache between build processes 为方向,介绍一下 Webpack 5 最令人期待的「长效缓存」功能的前世今生,技术背景以及落地方案。同时希望“管中窥豹”,介绍一下整体 Webpack 的构建流程。 整篇文章将会设计大量 Webpack 实现原理和体系设计,阅读需要一定的前置知识和理解成本。总之:“你认为的缓存不仅仅是简单的「空间换时间」,同时,你认为的「Webpack 工程师」恰恰是前端体系中最具功力的拼图板块”。
后续更多技术规划和设计分析,我们团队将会逐步整理产出。
关于现状和深度场景 关于问题和解决方向
这一部分我们将从两个方面,介绍现有 webpack 构建的痛点和已有解决方案,我们逐一分析这些解决方案的不足,并以 Webpack 官方视角,来探讨是否存在更可行、更优雅的官方解决方案。
不间断进程(continuous processes)和缓存
对于大型复杂项目应用,在开发阶段,开发者一般习惯使用 Webpack --watch 选项或者 webpack-dev-server 启动一个不间断的进程(continuous processes)以达到最佳的构建速度和效率。Webpack --watch 选项和 webpack-dev-server 都会监听文件系统,进而在必要时,触发持续编译构建动作。此中细节值得研究,源码涉及到文件系统的监听、内存读写、不同操作系统的兼容、插件化和分层缓存设计等,也有很多著名的性能优化 issues,这里不再一一介绍,但提炼出关键点需要读者优先了解,以帮助对后文的理解消化:
正常启动 Webpack 构建流程会调用 compiler.run 方法
--watch 模式启动的 Webpack 构建流程会调用 compiler.watch 方法,并启动一个构建 watch 服务
webpack-dev-server 是一个小型的 NodeJS 服务器,它使用 webpack-dev-middleware 这个包,webpack-dev-middleware 也是最终调用了 compiler.watch 方法
--watch 模式依靠各层级的缓存提高后续构建速度
--watch 模式下,完成第一次构建后,为了后续不再重复启动构建进程,Webpack 会在构造函数 Watching 的原型方法 _done 上(Watching.prototype._done)监听文件的变动,实时进行构建
因此,watch 服务进程会处在:「构建 -> 监听文件变动 -> 触发重新构建 -> 构建」的循环当中
Webpack 采用 graceful-fs 这个包来实现文件的读写,它对 Node.js 中的 fs 模块进行了扩展和封装,优化了使用方式
除了 graceful-fs,业界(比如 webpack-dev-middleware)使用 memory-fs,借助 memory-fs,可以将 compiler 的 outputFileSystem 设置成 MemoryFileSystem,这样以内存读写的方式,将资源编译文件不落地输出,大大提高构建性能
截止到此,对文件的监听逻辑源码重点在 compiler.watchFileSystem 对象的 watch 方法,具体以 NodeEnvironmentPlugin 插件辅助 Webpack 的 watchpack 模块进行加载
上述监听文件(夹)的底层采用的是 chokidar 包执行
文件(夹)发生变化时,除了进行实例事件触发以外,还有进行文件变更数据的更新,以及 FS_ACCURENCY 的校准逻辑。FS_ACCURENCY 校准是为了平衡「文件系统数据低精确度而导致 mtime 相同但确实发生了变化」的情况
底层文件(夹)监听触发的功能依赖于对 EventEmitter 的继承,并最终完成上层 Webpack 重新构建流程
Webpack 的 --watch 选项内置了类似 batching 的能力,我们称之为 aggregateTimeout。意思是说:在触发 Watchpack 实例监听的文件(夹)的 change 事件后,会将修改的内容暂存的 aggregatedChanges 数组中,并在最后一次文件(夹)没有变更的 200ms 后,将聚合事件 emit 给上层
了解这些内容,大家应该能大致明白「Webpack --watch 模式的背后发生了什么」以及「Webpack --watch 模式下第一次构建耗时较多,后续的构建速度却大幅度提升」——这一现象背后的实现原理了。 原理虽然就是大家都知道的“缓存”这么简单,但是我们还要刨根问底:--watch 流程是如何利用事件模型,如何采用多个逻辑层设计,如何对触发流程进行解耦,最终实现清晰而可靠的代码的。各种细节需要结合源码逐一分析,这里不是我们的重点,暂不展开。
业界构建优化方案梳理和分析
尽管如此,并不是所有的 Webpack 使用都需要开启一个不间断的可持续进程(continuous processes,下文用可持续进程表达),比如在 CI(Continuous Integration)持续集成阶段以及构建线上应用包(Production Build)的阶段。这些阶段的构建成本甚至更高,因为开发者需要在 CI/CD pipeline 和构建线上应用时,对 Webpack 配置加入代码优化、代码压缩等插件。
为此社区上诞生了很多伟大的,励志于缩短 Webpack 构建时间以及减小成本的解决方案,他们包括但不限于:
cache-loader
DllReferencePlugin
auto-dll-plugin
thread-loader
happypack
hard-source-webpack-plugin
这里简要进行说明:cache-loader 可以在一些性能开销较大的 loader 之前添加,目的是将结果缓存到磁盘里;DLLPlugin 和 DLLReferencePlugin 实现了拆分 bundles,同时节约了反复构建 bundles 的成本,大大提升了构建的速度;thread-loader 和 happypack 实现了单独的 worker 池,用于多进程/多线程运行 loaders;不过有趣的是,vue-cli 和create-react-app 并没有使用到 dll 技术,而是使用了更好的代替着:hard-source-webpack-plugin。
这些社区方法优化的实现是以牺牲部分文件体积和后续优化空间为代价的。所有这些方法的使用也需要一定的学习成本,更别说普通开发者参与实现和开发成本了。
再谈文件监听和缓存:unsafe cache
上面我们更多提到了模块缓存的概念。除了模块之外,还有个不可忽视的缓存目标,我们称之为 resolver's unsafe cache。
什么是 resolver's unsafe cache 呢?我们先要从 Webpack 中 resolver 这个概念说起。Webpack 带来的一大理念是:一切皆模块。在项目中我们可以使用 ESM 的方式 import './xxx/xxx' 或者 import 'some_pkg_in_nodemodules',甚至使用 alias:import '@/xxx' 来实现模块化。Webpack 在处理这些引用时,是通过 resolve 过程,找到正确的目标文件。其实不光是项目代码中的引入声明,在 Webpack 的整体处理流程,包括 loaders 的寻找等,只要涉及到文件路径的,都离不开 resolve 过程。因此 resolve 可以简单地理解为“文件路径查找”。Webpack 对使用者也暴露了 resolve 的配置,我们可以对文件路径查找过程进行适当的配置,比如设置文件扩展名,查找搜索的目录等。因此,resolve 过程也会涉及到很多耗时的操作。
Webpack 源码中对于 resolver 的实现主要依赖 enhanced-resolve 的 ResolverFactory,它一共创建了三种类型的 resolver:
normalResolver:提供文件路径解析功能,用于普通文件导入
contextResolver:提供目录路径解析功能,用于动态文件导入
loaderResolver:提供文件路径解析功能,用于 loader 文件导入
在 Webpack 构建运行时,对于每一种类型模块,都会使用 Resolver 预先判断路径是否存在,并获取路径的完整地址供后续加载文件使用。当然对于这三种类型 resolver,也设置了缓存:Webpack 本身通过 UnsafeCachePlugin 对 resolve 结果进行缓存,对于相同引用,返回缓存路径结果。UnsafeCachePlugin 插件原理很简单:它通过 UnsafeCachePlugin.prototype.apply 方法,覆盖原有 Resolver 实例的 resolve 方法,新的方法上会包装一层路径结果 cache,以及包装了在完成原有方法后进行 cache 更新的逻辑。
听上去也很简单,但是这个设计和实现过程关联到「是否需要重新构建」的决断,这就值得深究一下了。我们来具体分析:
在通过 UnsafeCachePlugin 插件完成了必备文件路径查找之后,如果编辑过程没有出错,且当前 loader 调用了 this.cacheable(),且存在上一次构建的结果集合,那么即将进入「是否需要重新构建」的决断(needRebuild),决断策略根据当前模块的 this.fileDependencies 和 this.contextDependencies 这两个关键因素来确定。this.fileDependencies 表示当前模块所关联的文件依赖;this.contextDependencies 表示模块关联的文件夹依赖。我们先获取这两类依赖的最后变更时间(contextTimestamps、fileTimestamps)的最大值 timestamp,再和上一次构建时间 buildTimestamp 进行比对,如果 timestamp >= buildTimestamp,则表示需要重新编译。如果不需要重新编译,直接读取 compilation 对象中的 cache 属性相关值。
请思考,为什么 UnsafeCachePlugin 这个插件的名字需要加上一个 unsafe 前缀呢? 事实上,这类缓存(unsafe cache)默认在 Webpack core 中打开,但是它牺牲了一定的 resolving 准确度,同时它意味着持续性构建过程需要反复重新启动决断策略,这就要收集文件的寻找策略(resolutions)的变化,要识别判断文件 resolutions 是否变化,这一系列过程也是有成本的,只不过对于大多数应用,应用缓存 resolutions 性价比更高,是能够显著提升应用构建性能的。
Webpack 5 新的设计提案
了解了上述知识,我们继续探讨已有方案的缺陷以及 Webpack 5 持久化缓存设计的“台前幕后”。Webpack 5 令人期待的持久缓存优化了整个构建流程,原理依然还是那一套:当检测到某个文件变化时,根据依赖关系,只对依赖树上相关的文件进行编译,从而大幅提高了构建速度。官方经过测试,16000 个模块组成的单页应用,速度竟然可以提高 98%!其中值得注意的是持久缓存会将缓存存储到磁盘。
对于一个持续化构建过程来说,第一次构建是一次全量构建,它会利用磁盘模块缓存,使得后续的构建从中获利。后续构建具体流程是:读取磁盘缓存 -> 校验模块 -> 解封模块内容。因为模块之间的关系并不会被显式缓存,因此模块之间的关系仍然需要在每次构建过程中被校验,这个校验过程和正常的 webpack 进行分析依赖关系时的逻辑是完全一致的。对于 resolver 的缓存同样可以持久化缓存起来,一旦 resolver 缓存经过校验后发现准确匹配,就可以用于快速寻找依赖关系。对于 resolver 缓存校验失败的情况,将会直接执行 resolver 的常规构建逻辑。正常来讲,resolver 的变化也将会引起持续构建过程中文件路径变化的钩子触发。
缓存设计和安全性校验
那么如何设计这样一个持久化缓存呢?从数据类型和结构上来说,JSON 无疑是一个最好的选择。配合 JSON 数据,我们实现读写磁盘上的模块缓存数据以及每个模块的状态字段,这个模块状态字段将会在校验缓存可用性的阶段派上用场。
对于这样的缓存设计,非常重要的一点是缓存的安全性和可用性,也就是说我们需要保证持久化缓存是一个 safe cache。 任何被缓存的数据都要有一个对应校验可用性的逻辑。如何来保障校验的准确,是非常核心重要的课题。具体来说:对于每个模块,我们根据时间戳 timestamps 和内容 hashes 来做可用性校验。但是这里的 timestamps 并不能完全保证准确性, 因为实际情况中,会存在文件内容改变,但是 timestamps 并没有变化或者甚至 timestamps 变小的情况(比如该文件在依赖关系上下文中被删除,或有被重命名的情况)。因此使用文件内容的 hashes(或其他内容比较算法)就靠谱很多。这里需要注意的是根据文件系统的 metadata 的比较算法(Filesystem metadata comparisons)也是不安全的,因为这个 metadata 往往都是通过文件大小和最近修改时间混淆得到的。
缓存校验的安全性将是 Webpack 5 不同于以往版本的一大关键,我们总结一下:
模块内容基于 timestamps 或 filesystem metadata 的校验需要被基于 hash 算法或其他基于内容的比对算法取代
文件依赖关系(File dependency)的 timestamps 的校验需要被文件内容 hashes 算法取代
上下文依赖(Context dependency)的 timestamps 的校验需要被文件路径的 hashes 算法取代
这里提到的 File dependency 和 Context dependency 是 Webpack 内的重要概念,这里不再展开,只需要读者了解缓存校验设计的思路即可。
除了模块缓存,前面提到过的 resolver 缓存同样需要有类似的缓存校验过程。那么这两种校验过程也同样需要被优化,以达到更好的性能和构建速度。
兄弟缓存(cache sibling)和缓存集合概念
文件依赖关系的变动,文件内容的变动都会触发构建,进而对每个模块的缓存进行校验和应用。同样值得思考的是:不同的 Webpack 配置(比如对 Webpack 配置的修改),不应该直接导致模块缓存失效,而是应该对应不同的缓存集合。
Webpack 配置可能会在开发期间频繁地被改动,对于不同配置的缓存集合,我们可以使用配置内容的 hash 来做标记,标记出该配置下的缓存集合。对于持续性构建来说,每个新增构建会根据当前的配置 hash 找到匹配的缓存集合,再继续进行构建过程。
如下图:
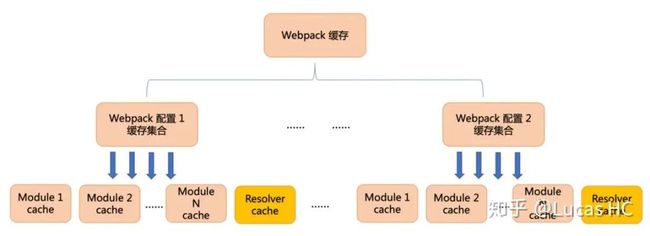 我把它称为缓存集合
我把它称为缓存集合
另外一个注意点是对于第三方依赖即 node_modules 文件内内容的缓存和更新。对于此,Yarn 和 Npm 5 以上版本,这些包管理机制自身可以通过锁文件的 hash 校验来保证依赖内容的一致性和更新监听。对于 Npm 5 以下版本或其他情况,我们仍然需要一种缓存和更新机制,来保证依赖内容的一致性和变化监听。一种常用做法是:将 node_modules 文件夹内第一层所有的 package.json 文件集合进行 hash 化。
缓存淘汰策略设计
我们在设计任何一种缓存体系时,除了要考虑缓存校验,还要考虑到缓存容量限制。 Webpack 5 持久化缓存当然不能无限制的扩展,对于磁盘的合理利用和缓存清理设置是必不可少的关键环节。
初期 Webpack 5 核心开发者 mzgoddard 在讨论设计时认为:对于一个缓存集合,最大限度应该不超过 5 个缓存内容,最大累积资源占用不超过 500 MB,当逼近或超过 500MB 的阈值时,优先删除最老的缓存内容。同时,也设计了缓存的有效时长为 2 个星期。
这实际上类似一个经典的 LRU cache(Least Recently Used 最近最少使用)设计。 该算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。一般我们通过基于 HashMap 和 双向链表实现 LRU cache。具体内容只做提示,不再展开。
其他考虑点
一个强健有效的缓存系统,尤其是对于 Webpack 这种复杂的构建工具来说,需要考虑的关键点仍然有很多。这里我们简单进行罗列,不求面面俱到,更重要的是让读者能够有一个更加立体的认知:
面向 Webpack plugin 和 loader 开发者的缓存需求
对于 Webpack plugin 和 loader 开发者来说,缓存体系需要实现开箱即用的工具或策略以便完成对缓存的调试和检验。同时也需要暴露给 Webpack plugin 和 loader 开发者开关缓存的能力以及时全量缓存失效的能力。
面向普通开发者的缓存需求
对于普通开发者,最核心的需求当然是可以依靠缓存系统完成构建的绝对量级优化。同时需要对未开启缓存的性能不优化型构建进行提示,且该提示应该是可关闭的。对于缓存的操作,不需要普通开发者手动进行,所有缓存体系的运转都应该是一个自动流程。
同样对于开发者,也能够使用不支持持久化缓存的 Webpack plugin 和 loader。缓存体系的设计和建设,当然不能破环整个 Webpack 生态体系。
面向 Webpack 开发者
对于 Webpack 官方核心开发者,缓存体系同样需要提供测试和调试能力。
面向 CI 过程和跨系统
CI/CD(持续集成 Continuous Integration / 持续部署 Continuous Deployment)中涉及到的前端构建始终是一个有趣的话题。对于 Webpack 5 持久化缓存来说,对于 CI/CD 过程以及跨系统场景,也应该有合理的控制和设计。
总体来讲,在这个阶段的持久化缓存应该“易于携带”,我们用 portable 这次词语来形容这种特性。对不同的 CI 实例,或不同项目在不同系统设备上的 clones 来说,缓存都应该可以被重复利用,跨环境利用,这也是缓存在面向 CI 过程和跨系统当中所表现出来的可移植性。 举个例子,缓存内容应该在不同的 pipeline 阶段中,在不同的 CI 实例上都可用;或者从一个公共的中心化的存储中拉取最新的缓存内容,而不需要在通过第一次全量构建获取缓存内容。
持久化缓存信息写入 Webpack stats
熟悉 Webpack 核心体系的读者应该对于 Webpack stats 并不陌生。Webpack stats 是 Webpack 对于一次构建的统计分析信息,它对于分析 Webpack 构建过程,优化构建方案非常重要。在此信息中,我们也应该加入持久化缓存所关联的磁盘信息(disk cache information )。比如:编译缓存 ID,缓存所占用磁盘空间等。
总结
本篇文章没有贴源码来具体分析 Webpack 5 持久化缓存实现,而是从设计体系出发,讲解 Webpack 现有构建流程和缓存环节。其中涉及到较多 Webpack 核心原理和基本概念,在阅读过程中读者可以随时查漏补缺。缓存体系说起来简单,但是如何实现的优雅,完成体系化、安全化、工程化等多方面考虑,仍然需要每一个开发者深思。
在这个时间节点,我相信未来一切就像阿尔贝•加缪在《鼠疫》中所说:“春天的脚步正从所有偏远的区域向疫区走来。成千上万朵玫瑰依旧枯萎在市场和街道两旁花商的篮子里,但空气中充溢着它们的香气”。 同时,书中另外一句话也让我印象深刻:“对未来真正的慷慨,是把一切献给现在”, 抗击疫情如此,学习进阶道路同样如此。
Happy coding!
关于奇舞周刊
《奇舞周刊》是360公司专业前端团队「奇舞团」运营的前端技术社区。关注公众号后,直接发送链接到后台即可给我们投稿。
