爬虫(7) lxml和xpath2020-12-28
文章目录
- 1. Xpath的简介
- 2. 工具安装
- 3. xpath的使用
-
- 3.1 百度网页
- 3.2 智联招聘网页
- 4. xpath常用语法总结
- 5. lxml模块快速入门
-
- 5.1 xpath导航练习
- 5.2 把输出结果保存到字典中并把这些数据写入一个csv文件中
- 6. 电影信息爬取案例
1. Xpath的简介
XPath(XML Path Language)是一种XML的查询语言,他能在XML树状结构中寻找节点。XPath 用于在 XML 文档中通过元素和属性进行导航。
xml是一种标记语法的文本格式,xpath可以方便的定位xml中的元素和其中的属性值。lxml是python中的一个第三方模块,它包含了将html文本转成xml对象,和对对象执行xpath的功能。
xml_content = '''
Harry Potter
JK.Rowing
2005
29
'''
我们看以上代码里面
文档节点
JK.Rowing 元素节点
lang='eng' 属性节点
- 父(Parent) book元素是title、author、year、price元素的父
- 子(Children) title、author、year、price都是book元素的子
- 同胞(Sibling) title、author、year、price都是同胞
- 先辈(Ancestor) title元素的先辈是 book元素和bookstore元素
2. 工具安装
常用节点选择工具:
- Chrome插件Xpath Helper
- Firefox插件Xpat Checker
Xpath Helper工具下载链接
链接:https://pan.baidu.com/s/1VuYGy2Qcg3V3bgTeql_sAg
提取码:word
推荐使用谷歌浏览器。下载好工具后,可以将“xpath-helper.crx”的后缀改成“rar”,然后解压缩。打开谷歌浏览器,在右上角三个点的地方点击

选择“更多工具”-“扩展程序”,然后将开发者模式按钮打开

在左上方点击“加载已解压的扩展程序”。加载后确定即可。另外还有一个简单的安装方法,就是直接将
“xpath-helper.crx”文件拖到浏览器里,这样更方便。不过有的浏览器版本不支持,那就按照刚才介绍的方法安装就可以了。注意,要保持文件所存放的路径,不要将文件删除。
3. xpath的使用
反斜杠和双反斜杠用的是最多的,反斜杠的意思是从根节点提取。它要考虑一个位置,如我要找一个href标签,我们要先确定它在哪个标签下,而这个标签又在哪个标签下,这样一层一层的去标出来。而双斜杠不需要,它是从匹配文档的当前节点选择文档中的节点,而不考虑它们的位置。
3.1 百度网页
打开浏览器,同时按住ctrl+shift+x调出xpath工具。
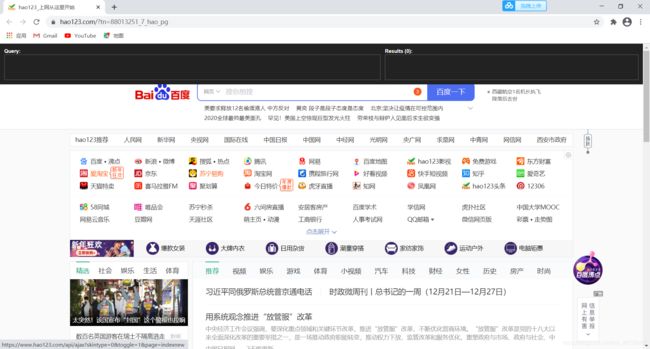
右键,选择检查,调出源代码页面。

我们在左边的输入框里输入反斜杠,然后输入html。这是一个根节点。
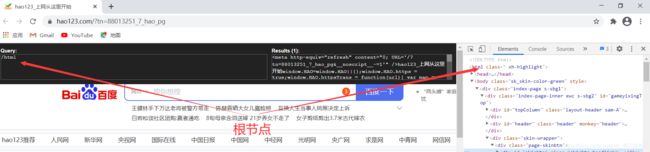
也可以打开百度页面,在这里做同样的输入,这个页面更简单一些。

我们可以看到整个页面的代码在右边的框内出现了。下面我想获取“百度一下你就知道”这个文字。我们看这个文字的节点位置。

在html下面的head,再下面的title,于是我们可以这样写:

我们看到在右边的框内就出现了该文字内容。一般,如果我们在代码中,要加上text()。虽然在xpath工具里没有加也是这样显示的,但是代码里要加上。
3.2 智联招聘网页
打开智联招聘的官网,搜索python开发。我们在随便一个职位右键,然后选择检查,进入代码区,可以看到我们刚才选的文字,如图。
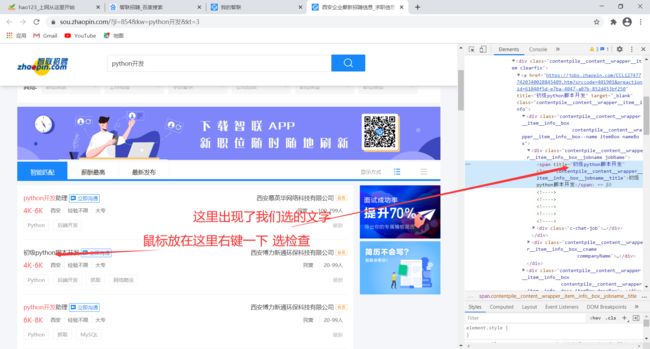
我们看到它在一个div标签下的span标签里。div标签有很多,但是我们可以通过标签的属性来定位这个标签。在左边的框里我们输入以下内容:
//div[@class='contentpile__content__wrapper__item__info__box__jobname jobName']/span/text()
我们看到右边的框内有了很多职位的内容。
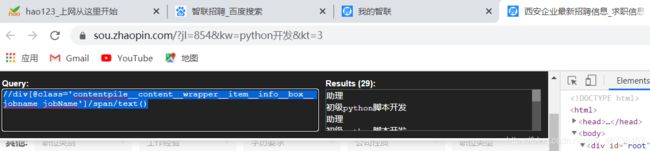
我们发现,只要定位好一个节点的位置,然后逐层查找,确定位置就可以了。那么代码里的中括号是什么意思呢?这里叫着谓语,是用来查找某个特定的节点,或者包含某个特定值的节点。谓语嵌在方括号内,以@开头,后面跟属性或者某个特定的值。@的作用是选取属性,其实上面我们看到了,有些职位只出现一部分,前面的英文部分没有显示,我们可以修改一下代码,在左边框内输入以下内容:
//div[@class='contentpile__content__wrapper__item__info__box__jobname jobName']/span/@title
我们发现加上标签的属性后,右边的框内出现了完整的职位名称,其实它出现的是title的属性值。

也可以右键我们要获取的内容所在的代码,然后选择copy>copy xpath。然后将复制到的内容
//*[@id="listContent"]/div[2]/div/a/div[1]/div[1]/span
粘贴到左边框里。结果如图:

这种方法优点是方便,简洁。缺点是代码的可读性差,我们不太容易读懂,都是一些代号。当你的基础比较好的时候你可以用这种方式。
xpath中的英文输入状态下的点是指在当前节点的标签内,而点点,即两个点,表示当前标签的父级标签,就是往前退了一步。注意下图:


其实右边框内还有很多代码如下:
西安企业最新招聘信息_求职信息_找工作上智联招聘
(function(a,e,f,g,b,c,d){a.ZhaoPinBigdataAnalyticsObject=b;a[b]=a[b]
||function(){(a[b].q=a[b].q||[]).push(arguments)};a[b].l=1*new Date;
a._ATAD_GIB_NIPOAHZ_||(c=e.createElement(f),d=e.getElementsByTagName(f)[0],
c.async=1,c.src=g,d.parentNode.insertBefore(c,d),a._ATAD_GIB_NIPOAHZ_=!0)})
(window,document,"script",document.location.protocol+
"//statistic.zhaopin.cn/sdk/zhaopin_tracker.js","za");
za("creat", "A23");
... ...
代码太多,这里省略了。
我把左边框内的代码改成父级的你看一下,对照右边框内的代码是否与上面的相同。

右边框内的代码:
西安企业最新招聘信息_求职信息_找工作上智联招聘
(function(a,e,f,g,b,c,d){a.ZhaoPinBigdataAnalyticsObject=b;a[b]=a[b]
||function(){(a[b].q=a[b].q||[]).push(arguments)};a[b].l=1*new Date;
a._ATAD_GIB_NIPOAHZ_||(c=e.createElement(f),d=e.getElementsByTagName(f)[0],
c.async=1,c.src=g,d.parentNode.insertBefore(c,d),a._ATAD_GIB_NIPOAHZ_=!0)})
(window,document,"script",document.location.protocol+
"//statistic.zhaopin.cn/sdk/zhaopin_tracker.js","za");
za("creat", "A23");
... ...
结果一模一样。这和dos命令里的cd.与cd..类似。前者是进入当前文件夹,后面是往前一个文件夹。
下面还有很多xpath语法,我们再介绍几个。
假如我想要智联招聘第一页的页码

我们先用元素选择器选择第一页的页码:
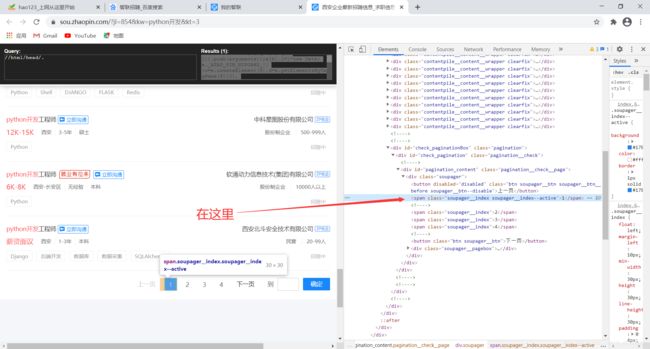
我们发现了它的位置,于是有了以下的代码:
//div[@class='soupager']/span[1]

第一页就找到了。如果代码改成这样的:
//div[@class='soupager']/span[last()]
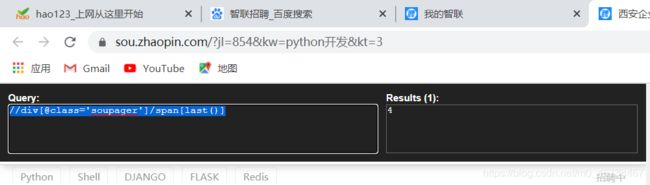
最后一个页码就找到了。如果代码再改成这样:
//div[@class='soupager']/span[position()<4]
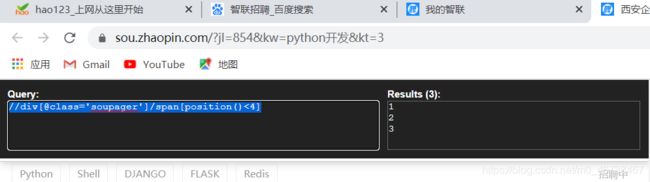
前三页的页码就得到了。
4. xpath常用语法总结
| 符号 | 功能 |
|---|---|
| / | 从根结点选取 |
| // | 从当前节点选,不必考虑位置 |
| . | 选取当前结点 |
| .. | 选取当前结点的父结点 |
| @ | 选取属性 |
查找某个特定的节点或者包含某个指定的值的节点
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于bookstore子元素的第一个book元素 |
| /bookstore/book[last()] | 选取属于bookstore子元素的最后一个book元素 |
| /bookstore/book[last()-1] | 选取属于bookstore子元素的倒数第二个book元素 |
| /bookstore/book[position() < 3] | 选取属于bookstore子元素的前面两个book元素 |
| //title[@lang] | 选取所有拥有名为lang的属性的title元素。 |
| //title[@lang=‘eng’] | 选取所有的title元素,且这些元素拥有值为eng的lang属性 |
| /bookstore/book[price > 35.00] | 选取bookstore元素的所有book元素,且其中price元素的值须大于35.00 |
(未完待续)
5. lxml模块快速入门
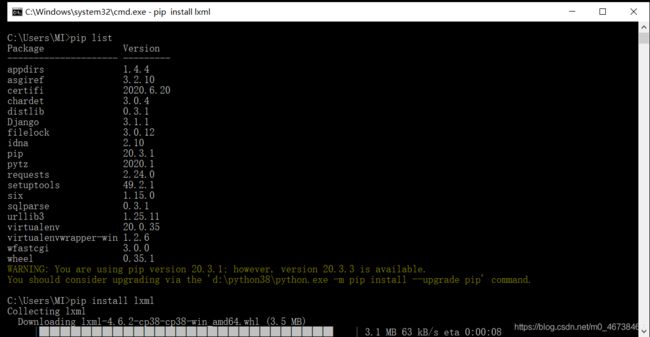
先在交互模式下输入pip list回车,检查一下是不是安装了lxml模块,如果还没有安装则pip install lxml安装一下。
5.1 xpath导航练习
我们通过一个案例来练习:
"""
"""
我们从这段代码里取出"link1.html"类的数据:
from lxml import etree
wb_data = """
"""
html_element = etree.HTML(wb_data)
print(html_element)
得到的是Element html对象,我们可以用xpath进行数据提取了。
from lxml import etree
wb_data = """
"""
html_element = etree.HTML(wb_data)
links = html_element.xpath('//li/a/@href')
print(links)
[‘link1.html’, ‘link2.html’, ‘link3.html’, ‘link4.html’, ‘link5.html’]
很方便得到了。我们还可以得到文本数据。
from lxml import etree
wb_data = """
"""
html_element = etree.HTML(wb_data)
content = html_element.xpath('//li/a/text()')
print(content)
[‘first item’, ‘second item’, ‘third item’, ‘fourth item’, ‘fifth item’]
5.2 把输出结果保存到字典中并把这些数据写入一个csv文件中
现在我们先获取整个字典:
from lxml import etree
wb_data = """
"""
html_element = etree.HTML(wb_data)
links = html_element.xpath('//li/a/@href')
content = html_element.xpath('//li/a/text()')
# print(links)
# print(content)
for link in links:
d = {}
d['href'] = link
d['title'] = content[links.index(link)] # 这里我们通过index()函数获取每个link对应得索引值
print(d)
{‘href’: ‘link1.html’, ‘title’: ‘first item’}
{‘href’: ‘link2.html’, ‘title’: ‘second item’}
{‘href’: ‘link3.html’, ‘title’: ‘third item’}
{‘href’: ‘link4.html’, ‘title’: ‘fourth item’}
{‘href’: ‘link5.html’, ‘title’: ‘fifth item’}
下面我们写入csv文件
from lxml import etree
import csv
wb_data = """
"""
html_element = etree.HTML(wb_data)
links = html_element.xpath('//li/a/@href')
content = html_element.xpath('//li/a/text()')
lst = []
titles = ('href','title')
for link in links:
d = {}
d['href'] = link
d['title'] = content[links.index(link)]
# print(d)
lst.append(d)
with open('d.csv','w',encoding='utf-8',newline='') as f:
writer = csv.DictWriter(f,titles)
writer.writeheader()
writer.writerows(lst)
执行结果

打开目录中的文件我们就可以看到刚才写入的内容:

6. 电影信息爬取案例
我们今天讲一个案例,从某网爬取数据可以保存下来。目的是复习xpath语法和csv的知识。
项目需求:电影的名字,评分,引言,以及详情页的url。爬取10页,并把信息保存在csv文件当中。
我们大致分为这样几步走:
第一步:先分析网页源码,看看我们要的内容在哪里。
比如我打开一个电影网站:https://www.1hone.com/list_0_0_0_0_0_1.html
发现我们想要的信息全在一个

现在我们尝试写代码,面向对象编程,大概分为三个模块,留意看注释。
import requests
import csv
from lxml import etree
mod_url = 'https://www.1hone.com/list_0_0_0_0_0_{}.html' # 这里用花括号先占位,后面第四个模块中实现一个根据需求变化的url
# 定义一个模块来获取资源
def getSource(url):
response = requests.get(url)
response.encoding = 'utf-8'
return response.text
# 定义一个模块来获取目标项
def getData(source):
element = etree.HTML(source)
elementList = element.xpath('//li[@class="col-list"]') # 这里获取的是包含所有我们所要的信息的模块
info_list = [] # 定义一个空列表,一会儿用来田间我们得到的内容。
for each in elementList:
movDict = {} # 定义一个空列表,一会儿用来装我们要的内容。
title = each.xpath('div[@class="cover-info"]/a/h4/text()')[0] # 这里因为输出的内容是列表,取其中的元素,可以将中括号去掉。
brief_intr = each.xpath('div[@class="cover-info"]/small/text()') # 这里得到的是简介
classify = each.xpath('div[@class="cover-stat"]/span[@class="c-l"]/text()')[0] # 这里得到的是类别
year = each.xpath('div[@class="cover-stat"]/span[@class="c-c"]/text()') # 这里得到的是年代
country = each.xpath('div[@class="cover-stat"]/span[@class="c-r"]/text()')[0] # 这里得到的是国家
link = each.xpath('div[@class="cover-info"]/a/@href')[0] # 这里得到的是播放链接
if year: # 这里做一个判断,因为有的电影没有年代,如果我们直接在后面加中括号取列表元素,遇到没有年代的,列表的内容是空的,这样就会报错。
year = year[0]
else:
year = ''
if brief_intr: # 简介这里也加个判断,以防万一某部片子没有简介。
brief_intr = brief_intr[0]
else:
brief_intr = ''
# 将所获取的信息以键值对添加到字典里,以备添加到列表
movDict['title'] = title
movDict['brief_intr'] = brief_intr
movDict['classify'] = classify
movDict['year'] = year
movDict['country'] = country
movDict['link'] = link
info_list.append(movDict) # 将字典加入列表,以备写入csv文件
return info_list
# 定义一个模块写入数据
def writeData(list):
with open('movieName.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=['title', 'country', 'year', 'classify', 'brief_intr',
'link']) # 注意,这里的内容必须与上一个模块里的字典的键一模一样,顺序不必相同。
writer.writeheader() # 这里不必传参
writer.writerows(list)
# 写一个主程序入口
if __name__ == '__main__':
movielist = []
for i in range(10): # 这里需要几页的内容就写几。
url = mod_url.format(i + 1) # 这里将之前占位的地方换成i+1,这是我们通过观察得到的网页的变化规律
source = getSource(url)
movielist += getData(source) # 注意这里一定要用“+=”,不然的话只能得到最后一页的内容。
print('正打印第' + str(i + 1) + '页') # 这里可以提醒你爬取的进度
writeData(movielist)
走一个。

结果。

本次博客结束。