网络舆情热点发现及分析(single-pass聚类)
热点话题的发现模型

在整个的过程中,介绍三个点:
- 预处理:基于网络新词的识别算法
- 热点话题发现:增量聚类算法Single-Pass
- 热点话题分析:文本倾向性分析
基于网络新词的识别算法
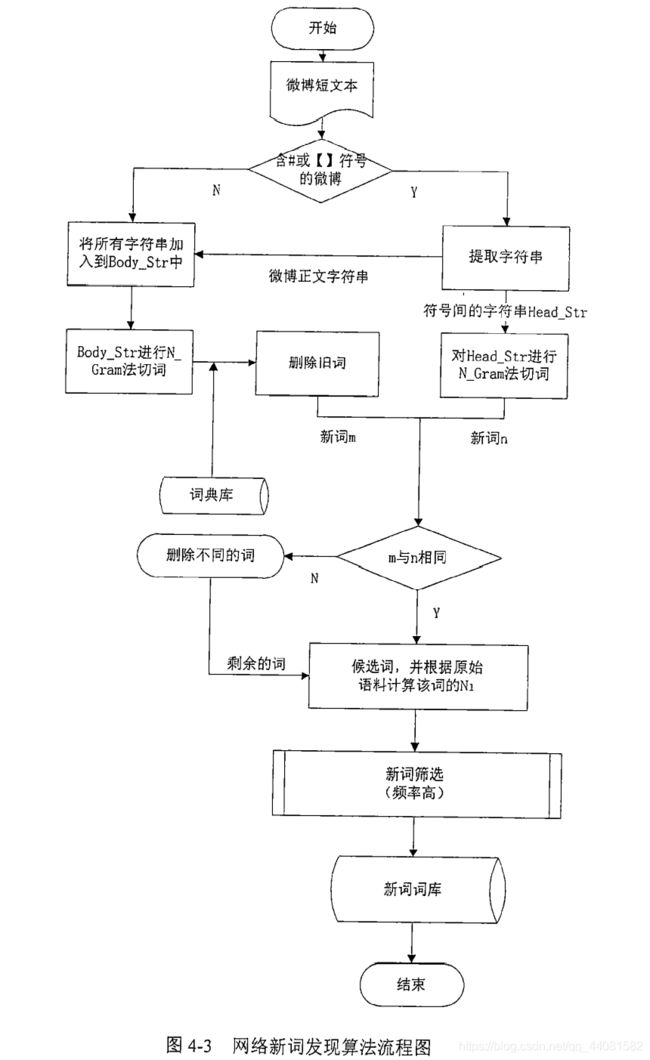
算法思路:
首先根据微博文本的特点,将#和中括号之间的文本进行了提取,因为在微博中,这样的文本本身就表示一个话题,所以可以直接被提取。而对于微博的正文部分,或者本身没有#和中括号这样的文本内容,则会进行初步分词,然后利用中文分词系统对初步分词进行筛选,删掉旧词,得到网络新词。这时候就得到了两组新词,算法会对这两组新词进行比较,删除不同的词,剩下的作为候选词,根据原始语料计算该词的频率,并根据频率进行筛选,留下频率较高的词作为最终得到的新词输出。
single-pass算法

算法思路:
按照文档到来的顺序一次一篇进行处理的,首先分析接收到的新文档,计算该文档与已有话题类簇中心的相似度,并根据预先设定的阈值(Tc是事先设定好的阈值)来决定当前文档与比对的话题类簇的关系。如果相似度在阈值范围之内,那么该文档归属到当前话题类簇中,如果不在范围之内,则将该文档作为一个新的话题加入到类簇队列中,并结束对当前文档判断,等待下一个文档的到来。
这样就实现了话题的动态增量聚类。算法刚开始时,首先将第一篇文档作为第一个类簇,并确定阈值,当有新的文档加入后,计算文档与已有类簇的相似度,以此循环下去,直到结束。
传统的single-pass算法的缺点及改进:
第一,对文档输入顺序很敏感:而由于新闻数据流本身就有时间特性,我们就可以将新闻话题以发表的时间作为输入顺序,对新采集的文档按照更新时间进行排序,较早时间的优先进行聚类,较新时间的随后进行聚类。
第二,随着文档不断增多而带来的逐一比较文档效率低的问题:增加一个“类簇特征中心”,在聚类过程中,形成该类簇的一个中心,该特征中心代表了当前类簇中所有文档的核心内容的一个概括,当采集到新文档进行对比计算时,只需要与该特征中心比较即可找到二者之间的相似度,进而可以知道该文档是否属于当前类簇。这种改进,可以有效降低文档比较次数,从而提高了算法的求解效率。
第三:时间增加带来的类簇剧增的问题,网上很多人在说“互联网是没有记忆的”,这个观点的产生,就是由于网络热点的时效性,再火的话题,他的热度也会随着时间而消退,旧的话题就是会多数人被淡忘,如果这样的类簇都永久保留,不仅影响新热点的发现与分析的效果,也会付出更多的计算存储开销,所以我们就可以根据热度存在的周期分析对话题类簇进行有效的舍取。
文本倾向性分析
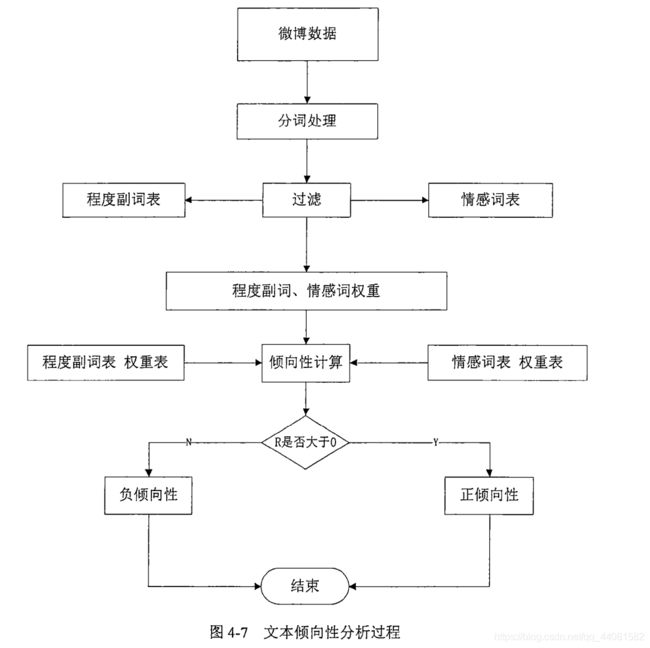
分析思路:
主要依据由情感词构建的词典来进行,对预处理后的词语进行过滤,将其中的程度副词、情感词等进行权重划分,比如表示欢乐的词语及表情符号被给予较低的权重值,而表示消极的词语及符号给予较高的权重值,以此来衡量该评论的情感倾向。
除此之外,还可以统计评论转发次数和点赞次数来确定该文本情感倾向的支持率,以此获得该话题当前整体的流向和影响力。
附代码:
package test;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import java.util.Vector;
public class OpinionAnalyser {
//倾向词表
public Vector words=new Vector ();
//修饰词表
public Vector adjectives=new Vector ();
//描述词表
public Vector descriptions=new Vector ();
//正面句子数
public int posCount;
//负面句子数
public int negCount;
static String SERVER="59.77.233.*";
static String USER="";
static String PASSWORD="";
static String DATABASE="skycent";
//负面词的权重,为2表示负面词是正面词权重的两倍
static int NEG_WEIGHT=2;
static int TITLE_WEIGHT=10;
private static int atoi(String s)
{
return Integer.parseInt(s);
}
//读取数据库初始化三个词表和其他成员变量
public void OpinionAnalyser() throws SQLException
{
ConnDB conndb;
PreparedStatement stmt = null;
// PreparedStatement stmt = null;
ResultSet rs = null;
conndb = new ConnDB(SERVER, USER, PASSWORD, DATABASE);
conndb.executeUpdate("SET NAMES 'utf8mb4'");
//获取倾向性词表
String strSQL = "select word,polar,weight from twordlist";
try {
stmt = conndb.getConnection().prepareStatement(strSQL);
rs = stmt.executeQuery();
} catch (SQLException e1) {
e1.printStackTrace();
}
// 处理空集情况
if (rs.next() == false) {
System.out.println("twordlist没有词!");
}
else{
rs.previous();
}
while(rs.next())
{
int polar=atoi(rs.getString("polar"));
int weight=atoi(rs.getString("weight"));
// System.out.println(polar+" "+weight+" "+rs.getString("word"));
Word tmp=new Word(rs.getString("word"),polar,weight);
words.addElement(tmp);
// System.out.println(polar+" "+weight);
}
//获取描述词表
strSQL = "select word,type from twordlist_ms";
try {
stmt = conndb.getConnection().prepareStatement(strSQL);
rs = stmt.executeQuery();
} catch (SQLException e1) {
e1.printStackTrace();
}
// 处理空集情况
if (rs.next() == false) {
System.out.println("twordlist_ms没有词!");
}
else{
rs.previous();
}
while(rs.next())
{
int polar=atoi(rs.getString("type"));
// System.out.println(polar+" "+rs.getString("word"));
Word tmp=new Word(rs.getString("word"),polar,0);
descriptions.addElement(tmp);
}
//获取修饰词表
strSQL = "select word,polar,weight from twordlist_xs";
try {
stmt = conndb.getConnection().prepareStatement(strSQL);
rs = stmt.executeQuery();
} catch (SQLException e1) {
e1.printStackTrace();
}
// 处理空集情况
if (rs.next() == false) {
System.out.println("twordlist_xs没有词!");
}
else{
rs.previous();
}
while(rs.next())
{
int polar=atoi(rs.getString("polar"));
int weight=atoi(rs.getString("weight"));
// System.out.println(polar+" "+weight+" "+rs.getString("word"));
Word tmp=new Word(rs.getString("word"),polar,weight);
adjectives.addElement(tmp);
}
posCount=0;
negCount=0;
conndb.close();
}
//句子倾向性得分
public int sentenceScore(String sentence)
{
int opinionScore=0;
//是否出现倾向词
int opinionPosition=0;
for(int i=0;i0)
opinionScore +=tmpScore;
else
opinionScore +=tmpScore*NEG_WEIGHT;
}
}
//没出现修饰词只计算倾向次本身的权重
if(flag==0)
{
// System.out.println(opinionPosition);
// System.out.println("nnnnnnnnnnnnn");
if(words.get(i).getPolar()==1)
{
opinionScore+=words.get(i).getWeight()*words.get(i).getPolar();
// System.out.println(words.get(i).getWord());
// System.out.println("wwwwwwwww");
}
else if(words.get(i).getPolar()==-1)
{
opinionScore+=words.get(i).getWeight()*words.get(i).getPolar()*NEG_WEIGHT;
// System.out.println(words.get(i).getWord());
}
}
}
}
//System.out.println("最后得分:"+opinionScore);
return opinionScore;
}
//计算一般新闻的倾向性
public void opinion(Set keyword,String text,String title)
{
posCount=0;
negCount=0;
System.out.println("opinion");
//计算title的倾向性
shortTextOpinion(keyword,title);
Set sentences = new HashSet();
String[] array=text.split(" ");
//System.err.println(array.length);
for(int i=0;i0)
posCount++;
else if(value<0)
negCount +=NEG_WEIGHT;
}
}
}
}
//计算短文本如微博的倾向性
public void shortTextOpinion(Set keyword,String text)
{
System.out.println("shortTextOpinion");
posCount=0;
negCount=0;
int kwordP=0;
int owordP=0;
Iterator kwordIter=keyword.iterator();
while(kwordIter.hasNext())
{
String kwordIt=kwordIter.next().toString();
kwordP=text.indexOf(kwordIt);
//文本中存在关键词
if(kwordP!=-1)
{
int opinionScore=0;
int pairPosition=0;
StringBuffer wordPair=new StringBuffer();
for(int i=0;i0)
opinionScore +=tmpScore;
else
opinionScore +=NEG_WEIGHT*tmpScore;
}
}
if(flag==0)
{
if(words.get(i).getPolar()==1)
opinionScore +=words.get(i).getWeight()*words.get(i).getPolar();
else if(words.get(i).getPolar()==-1)
opinionScore +=NEG_WEIGHT*words.get(i).getWeight()*words.get(i).getPolar();
}
}
}
if(opinionScore>0)
posCount +=TITLE_WEIGHT;
else if(opinionScore<0)
negCount +=TITLE_WEIGHT*NEG_WEIGHT;
}
}
}
//media=3为微博采用短文本倾向性,第二个参数为空
public void analyse(int media,Set keyword,String text,String title)
{
if(media ==3)
{
System.out.println("media=3");
shortTextOpinion(keyword,title);
}
else
{
System.out.println("media=1");
opinion(keyword,text,title);
}
}
//最终倾向性
public int getPolar()
{
if(posCount>negCount)
return 1;
else if(negCount>posCount)
return -1;
else
return 0;
}
public static void main(String[] args) throws SQLException
{
OpinionAnalyser a=new OpinionAnalyser();
a.OpinionAnalyser();
a.sentenceScore("好不好!");
String str="心情很好";
System.out.println("文本倾向性:"+a.sentenceScore(str));
//String text="兴业证券正面临着暴跌!需要采取一定的措施来进行抵御!";
//Set keyword = new HashSet();
//keyword.add("兴业证券");
//keyword.add("金融危机");
//String title="兴业证券面临金融危机";
//a.analyse(1, keyword, text, title);
//System.out.println("该文本最后倾向性:"+a.getPolar());
}
}
详见:
《互联网舆情监测系统中的热点发现及分析》
https://www.cnblogs.com/zeze/p/5331650.html