运用Python+ElementTree解析XML
近日遇到一些XML数据,想把其解析出来,便于后期归纳汇总数据。搜集资料,发现运用Python的ElementTree可以解析XML数据。 XML是一种固有的分层数据格式,表示它的最自然的方式是使用树,XML中结点结构一般形式为:
text
下面以解析https://data.un.org/ws/rest/conceptscheme/为例展开介绍。

1.导入包
# -*- coding: utf-8 -*-
from urllib.request import urlopen ##urllib.request.urlopen()函数用于实现对目标url的访问。
import xml.etree.ElementTree as ET ##xml.etree.ElementTree用于解析遍历XML文件。
import pandas as pd ##pandas用于数据记录和保存
2.解析XML
ElementTree提供了parse()、from_string()、ElementTree类ElementTree()等方式解析xml,具体可以参考博客 ,此处采用from_string()。
# urlopen访问网页
u = urlopen('https://data.un.org/ws/rest/conceptscheme/')
#获取文本
s = u.read().decode('utf-8')
#调用from_string(),返回解析树的根元素
root = ET.fromstring(s)
print(root.tag, ":", root.attrib) # 打印根元素的tag和属性
3.遍历
可以直接循环遍历,也可以采用find(match)、findall(match) 、 iter(tag=None)等方法来匹配遍历。
# 遍历xml文档的第二层
for elem in root:
print("第二层节点")
print ("elem.tag:",elem.tag)
print ("elem.attrib:",elem.attrib)
print ("elem.text:",elem.text)
for i in elem:
print ("第三层节点")
print ("elem.tag:",i.tag)
print ("elem.attrib:",i.attrib)
print ("elem.text:",i.text)
从打印结果可以看到文件中使用了命名空间,所以在使用tag匹配时要注意加上命名空间。


利用上面的遍历方法从xml文件中提取需要的字段。
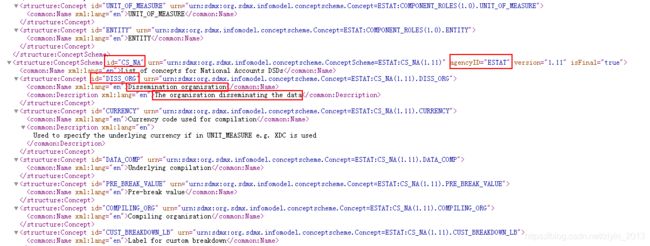
##用列表记录字段
ConceptScheme_id=[]
ConceptScheme_agencyID=[]
ConceptId=[]
ConceptName=[]
ConceptDescription=[]
for item in root.iter('{http://www.sdmx.org/resources/sdmxml/schemas/v2_1/structure}ConceptScheme'):
#获取ConceptScheme
print("#######")
#print(item.tag)
print(item.get("id"),'\t',item.get("agencyID"))
##获取每个ConceptScheme中包含的字段Concept
num=0
for concept in item.iter("{http://www.sdmx.org/resources/sdmxml/schemas/v2_1/structure}Concept"):
#print (concept.get("id"))
#print (concept.tag,concept.attrib,concept.text)
ConceptScheme_id.append(item.get("id"))
ConceptScheme_agencyID.append(item.get("agencyID"))
ConceptId.append(concept.get("id"))
temp=[]
for info in concept:
#print ("concept的name 和 description")
temp.append(info.text)
#print (info.text)
#print(len(temp))
if len(temp)==1:
ConceptName.append(temp[0])
ConceptDescription.append("")
else:
ConceptName.append(temp[0])
ConceptDescription.append(temp[1])
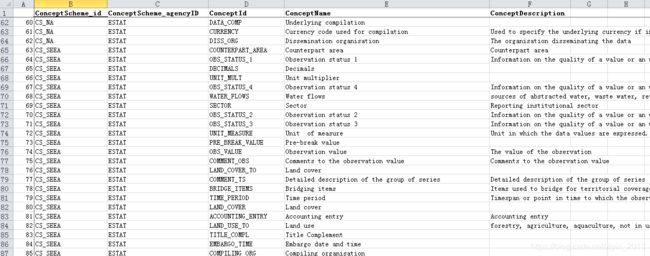
4.数据保存
result=pd.DataFrame()
result['ConceptScheme_id']=ConceptScheme_id
result['ConceptScheme_agencyID']=ConceptScheme_agencyID
result['ConceptId']=ConceptId
result['ConceptName']=ConceptName
result['ConceptDescription']=ConceptDescription
result.to_csv('data/UNSD_Concept.csv')
完整代码
# -*- coding: utf-8 -*-
from urllib.request import urlopen
import xml.etree.ElementTree as ET
import pandas as pd
# urlopen访问网页
u = urlopen('https://data.un.org/ws/rest/conceptscheme/')
#获取文本
s = u.read().decode('utf-8')
#调用from_string(),返回解析树的根元素
root = ET.fromstring(s)
print(root.tag, ":", root.attrib) # 打印根元素的tag和属性
#从根节点迭代子节点
for elem in root:
print("第二层节点")
print ("elem.tag:",elem.tag)
print ("elem.attrib:",elem.attrib)
print ("elem.text:",elem.text)
for i in elem:
print ("第三层节点")
print ("elem.tag:",i.tag)
print ("elem.attrib:",i.attrib)
print ("elem.text:",i.text)
##用列表记录字段
ConceptScheme_id=[]
ConceptScheme_agencyID=[]
ConceptId=[]
ConceptName=[]
ConceptDescription=[]
for item in root.iter('{http://www.sdmx.org/resources/sdmxml/schemas/v2_1/structure}ConceptScheme'):
#获取ConceptScheme
print("#######")
#print(item.tag)
print(item.get("id"),'\t',item.get("agencyID"))
##获取每个ConceptScheme中包含的字段Concept
num=0
for concept in item.iter("{http://www.sdmx.org/resources/sdmxml/schemas/v2_1/structure}Concept"):
#print (concept.get("id"))
#print (concept.tag,concept.attrib,concept.text)
ConceptScheme_id.append(item.get("id"))
ConceptScheme_agencyID.append(item.get("agencyID"))
ConceptId.append(concept.get("id"))
temp=[]
for info in concept:
#print ("concept的name 和 description")
temp.append(info.text)
#print (info.text)
#print(len(temp))
if len(temp)==1:
ConceptName.append(temp[0])
ConceptDescription.append("")
else:
ConceptName.append(temp[0])
ConceptDescription.append(temp[1])
##数据保存
result=pd.DataFrame()
result['ConceptScheme_id']=ConceptScheme_id
result['ConceptScheme_agencyID']=ConceptScheme_agencyID
result['ConceptId']=ConceptId
result['ConceptName']=ConceptName
result['ConceptDescription']=ConceptDescription
result.to_csv('data/UNSD_Concept.csv')
ps:初衷是通过撰写博文记录自己所学所用,实现知识的梳理与积累;将其分享,希望能够帮到面临同样困惑的小伙伴儿。如发现博文中存在问题,欢迎随时交流~~