python爬虫豆瓣读书top250+数据清洗+数据库+Java后端开发+Echarts数据可视化(二)
之前的博客已经写了python爬取豆瓣读书top250的相关信息,接下来继续看如何清洗数据。
如果有没看懂的或是不了解上一部分说的是什么内容的,请看https://blog.csdn.net/qq_45804925/article/details/112848887
现在开始具体内容的复习:
1. 豆瓣读书top250信息预处理
#数据清洗
import pandas as pd
import re
import time
# 先读取数据文件
data = pd.read_csv('E:/Class/商业智能实训/我~编写代码/DoubanMovies/book.csv')
result = pd.DataFrame(data)
a = result.dropna(axis=0, how='any')
pd.set_option('display.max_rows', None) #输出全部行,不省略
b = u'数据'
number = 1
b1 = '1981-8'
li1 = a['出版社']
for i in range(0, len(li1)):
try:
if b1 in li1[i]:
# print(number,li1[i])
number += 1
a = a.drop(i, axis=0)
except:
pass
b2 = '中国基督'
a['出版时间'] = a['出版时间'].str[0: 5]
li2 = a['出版时间']
for i in range(0, len(li2)):
try:
if b2 in li2[i]:
# print(number,li2[i])
number += 1
a = a.drop(i, axis=0)
except:
pass
b3 = 'CNY'
li3 = a['价格']
for i in range(0, len(li3)):
try:
if b3 in li3[i]:
a['价格'] = li3.str.replace('CNY', '')
except:
pass
b41 = '清'
b42 = '明'
li4 = a['国家']
a['国家'] = li4.str.replace("国", "")
for i in range(0, len(li4)):
try:
if b41 in li4[i]:
a['国家'] = li4.str.replace('清', '中')
if b42 in li4[i]:
a['国家'] = li4.str.replace('明', '中')
except:
pass
time.sleep(3)
a.to_csv('newbook.csv', index=False)
在《福尔摩斯探案全集》这部分我们选择的是删掉数据,因为其xpath定位的内容与其他书籍有很大不同,导致数据位置不对,删掉后对于总体的数据来说影响不大。其次,为了简化后续对数据的统计,我们将作者国家部分的‘清’‘明’等朝代问题统一改为中(国),并且出版时间格式各有不同,为方便管理统一截取出版年份,在统计时变更为简便。
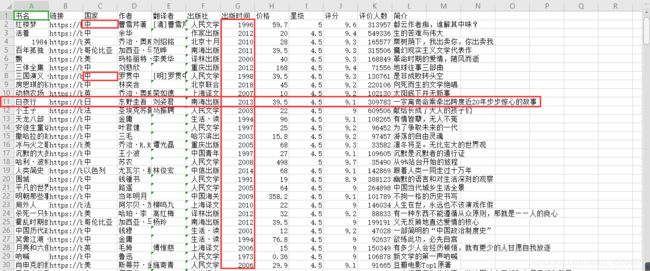
2. 数据预处理结果展示
3. 将清洗好后的数据文件导入数据库
3.1 将csv文件导入数据库
这里使用的是navicat,具体导入操作可以自行百读哈。需要提前将数据库建好哦!
创建原始数据表
CREATE TABLE `books` (
`title` varchar(255) DEFAULT NULL,
`link` varchar(255) DEFAULT NULL,
`country` varchar(255) DEFAULT NULL,
`author` varchar(255) DEFAULT NULL,
`translator` varchar(255) DEFAULT NULL,
`publisher` varchar(255) DEFAULT NULL,
`press_time` int(11) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
`star` float DEFAULT NULL,
`score` float DEFAULT NULL,
`people` int(11) DEFAULT NULL,
`comment` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
百度如何将csv文件导入数据库
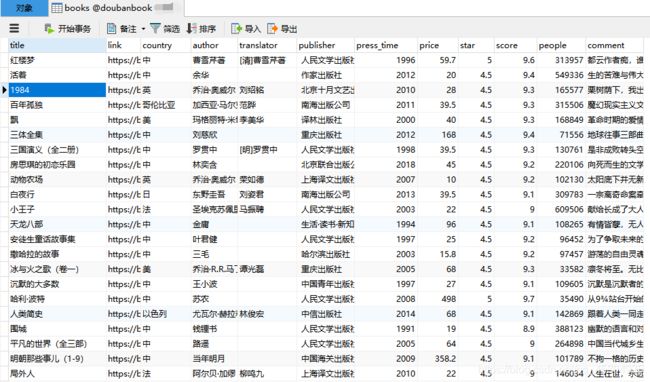
导入成功后的截图显示如下:
需求分析:
首先根据网页信息确认爬取的图书内容后,主要针对国家、作者、出版社、出版时间、评论人数、价格和评分这几点进行了分析。其中包括各国家和各作者出版的图书数量、各出版社出版图书占比、每年出版图书数量、评论人数前10的热议图书名称及评论人数、书友能够接受的图书价格和书籍评分。最终以折线图、柱状图和饼状图等形式分别呈现出其数据可视化效果。
3.2创建要实现数据可视化库表
如图所示:

| 表名 | 说明 |
|---|---|
| books | 原始数据表 |
| book_country_num | 各国家出版的图书数量表 |
| book_author_num | 各作者出版图书数量数据表 |
| book_publisher_num | 各出版社出版图书占比数据表 |
| book_presstime_num | 每年图书出版数量数据表 |
| book_people_title | 评论人数top10数据表 |
| book_price_num | 出版图书价格数据表 |
| book_score_num | 出版图书评分数据表 |
3.2.1 各国家出版的图书数量数据表
创建各国家出版的图书数量数据表
CREATE TABLE `book_country_num` (
`country` varchar(255) DEFAULT NULL COMMENT '国家',
`num` int(11) DEFAULT NULL COMMENT '数量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
写入book_country_num表
insert into book_country_num
select
country, count(*) as num
from books
group by country;
3.2.2 各作者出版图书数量数据表
创建各作者出版图书数量数据表
CREATE TABLE `book_author_num` (
`author` varchar(255) DEFAULT NULL COMMENT '作者',
`num` int(11) DEFAULT NULL COMMENT '数量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
写入book_author_num表
insert into book_author_num
select
author, count(*) as num
from books
group by author;
3.2.3 各出版社出版图书占比数据表
创建各出版社出版图书占比数据表
CREATE TABLE `book_publisher_num` (
`publisher` varchar(255) DEFAULT NULL COMMENT '出版社',
`num` int(11) DEFAULT NULL COMMENT '数量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
写入book_publisher_num表
insert into book_publisher_num
select
publisher, count(*) as num
from books
group by publisher;
3.2.4 每年图书出版数量数据表
创建每年图书出版数量数据表
CREATE TABLE `book_presstime_num` (
`press_time` int(11) DEFAULT NULL COMMENT '出版时间',
`num` int(11) DEFAULT NULL COMMENT '数量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
写入book_presstime_num表
insert into book_presstime_num
select
press_time, count(*) as num
from books
group by press_time;
3.2.5 评论人数top10数据表
创建评论人数top10数据表
CREATE TABLE `book_people_title` (
`people` int(11) DEFAULT NULL COMMENT '评论人数',
`title` varchar(255) DEFAULT NULL COMMENT '书名'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
写入book_people_title表
insert into book_people_title
select
people, title
from books
group by people
order by people desc
limit 10;
3.2.6 出版图书价格数据表
创建出版图书价格数据表
CREATE TABLE `book_price_num` (
`price` float DEFAULT NULL COMMENT '价格',
`num` int(11) DEFAULT NULL COMMENT '数量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
写入book_price_num表
insert into book_price_num
select
price, count(*) as num
from books
group by price;
3.2.7 出版图书评分数据表
创建出版图书评分数据表
CREATE TABLE `book_score_num` (
`score` float DEFAULT NULL COMMENT '评分',
`num` int(11) DEFAULT NULL COMMENT '数量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
写入book_score_num表
insert into book_score_num
select
score, count(*) as num
from books
group by score;
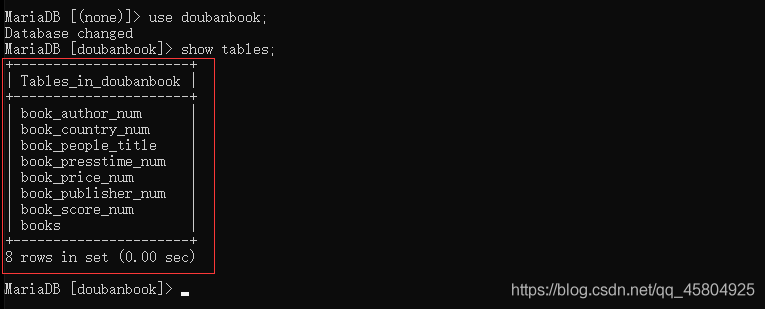
最后在数据库中查看一下,okk
今天就是将豆瓣读书top250的数据信息进行爬取,并进行清洗与预处理,最后将清洗好后的数据文件导入数据库,创建相应的要实现的数据可视化数据库表并插入相关数据。