豆瓣IMDB影评数据集的GRU形式
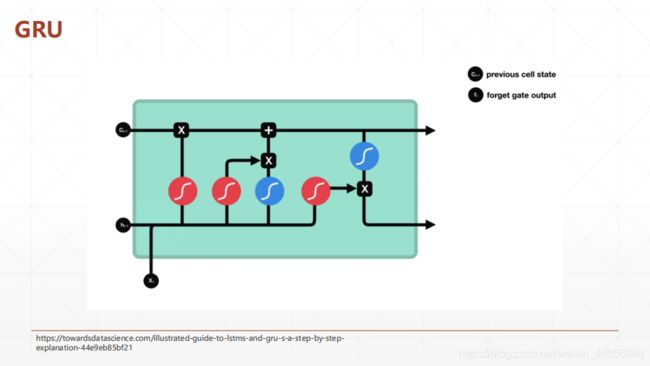

这里边GRU是比LSTM少一个门,LSTM是有Forget gate, Imput gate, 和 Cell gate, GRU只有 Reset gate和 Forget gate 下面这个是layers形式的
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
#每次取多少个句子
batchsz = 128
# 保留词频最高的前10000个单词其余的不会出现在train和test中
total_words = 10000
#每个句子包含的最多的词的个数
max_review_len = 80
#每个词用一个一百维的向量进行表示
embedding_len = 100
#读入数据并切分训练集与测试集
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words = total_words)
#pad_sequence填充序列,这里依照每个句子为80词进行填充,多的裁减掉,缺少的用0来补
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen = max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen = max_review_len)
#将读入的数据转换为tensor张量形式
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('x_test shape', x_test.shape)
#定义RNN类,分别需要两个步骤,一个是初始化
class MyRNN(keras.Model):
#这里的keras.Model是指MyRNN继承的父类
def __init__(self, units):
#这里的units是指输出的ht的维度
super(MyRNN, self).__init__()
#指继承父类的初始化变量
#将文本转换为词向量的表示形式即 [b, 80] -> [b, 80, 100]
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# [b, 80, 100], h_dim: 64
#构建两个GRU层,分别代表着state0和state1
self.rnn = keras.Sequential([
layers.GRU(units, dropout = 0.5, return_sequences = True, unroll = True),
layers.GRU(units, dropout = 0.5, unroll = True)
])
#fc, [b, 80, 100] => [b ,64] => [b, 1]
self.outlayer = layers.Dense(1)
#最后的一个flatten 输出到全连接层
def call(self, inputs, training = None):
# call是将类实例的重载 是的类实例对象可以像调用普通函数那样, 以“对象名”的形式调用
# [b, 80] 这里将input的输入值传入到x
x = inputs
#将输入的文本数据进行embedding操作 也就是[b, 80] => [b, 80, 100]
x = self.embedding(x)
# 将embedding的数据传入构建好的sequential 这里就是调用self.rnn [b, 60, 100] => [b, 64]这里的64是units
# 也就是循环神经网络的ht的输出维度
x = self.rnn(x)
# 传入下一层输出层 也就是flatten [b, 64] => [b, 1]
x = self.outlayer(x)
# 最后经过激活函数sigmoid 将输出值映射到[0, 1]区间上
prob = tf.sigmoid(x)
return prob
def main():
#定义RNN每个Cell 输出的ht的维数
units = 64
#定义迭代次数为4次
epochs = 4
import time
t0 = time.time()
#实例化类 MyRNN
model = MyRNN(units)
#这里因为model 是继承了keras.model的父类的子类,所以可以调用其中方法compile进行优化器,
# LOSS函数和相关指标参数设置
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics=['accuracy'])
#调用类方法.fit进行训练,这里设置训练过程中参考评估数据集为db_test
model.fit(db_train, epochs = epochs, validation_data = db_test)
#评估每次迭代训练过的模型
model.evaluate(db_test)
t1 = time.time()
print('total time cost:', t1 - t0)
if __name__ == '__main__':
main()
这个是cell形式的,更有助于理解GRU的内部过程
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batchsz = 128
total_words = 10000
max_review_len = 80
embedding_len = 100
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen = max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('x_test shape:', x_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
#这里与layers类型不同,需要对state0和state1两个cell状态分别定义,因为GRU的循环过程
#就是从state0进行门运算后产生输出至state1然后更新state0,然后有经过state1返回来,注意这里因为比LSTM少一个门
#所以只有一个tf.zeros
self.state0 = [tf.zeros([batchsz, units])]
self.state1 = [tf.zeros([batchsz, units])]
self.embedding = layers.Embedding(total_words, embedding_len,
input_length = max_review_len)
#这里因为是以cell形式构建的,所以需要不能用sequential形式构建网络,这里逐个定义cell0和cell1
self.rnn_cell0 = layers.GRUCell(units, dropout = 0.5)
self.rnn_cell1 = layers.GRUCell(units, dropout = 0.5)
self.outlayer = layers.Dense(1)
def call(self, inputs, training = None):
x = inputs
x = self.embedding(x)
state0 = self.state0
state1 = self.state1
# 这里将文本按照第二个维度展开 并将每个词映射成一个100维的向量,循环按照第二个维度一个一个词迭代
for word in tf.unstack(x, axis = 1):
out0, state0 =self.rnn_cell0(word, state0, training)
out1, state1 = self.rnn_cell1(out0, state1, training)
x = self.outlayer(out1)
prob = tf.sigmoid(x)
return prob
def main():
units = 64
epochs = 4
import time
t0 = time.time()
model = MyRNN(units)
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics = ['accuracy'])
model.fit(db_train, epochs = epochs, validation_data = db_test)
model.evaluate(db_test)
t1 = time.time()
print('total time cost:', t1 - t0)
if __name__ =="__main__":
main()