Python数据分析实例
分析案例的数据集为谷歌应用商店的app数据。
首先导入需要的工具numpy,pandas,matplotlib.pyplot
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltpandas读取数据文件
df = pd.read_csv('./Python案例/googleplaystore.csv', usecols=(0, 1, 2, 3, 4, 5,6))usecols函数表示读取前多少列数据,0到6表示读取7列。不用usecols函数默认读取所有列,本次分析只需用到前7列。
df.head()
预览数据,默认为前五行。运行结果:

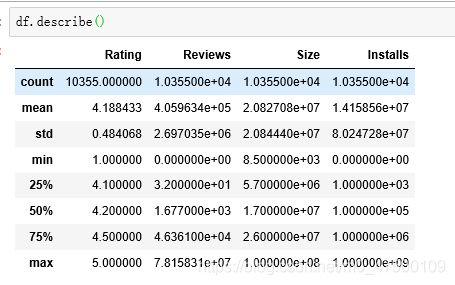
df.describe()
describe函数展示数据的一些描述性统计信息。
默认只输出数值型数据的统计信息。
设置参数为'all'则输入的所有列都在输出中,设置为O则只输出离散型变量的统计信息
df.describe(include='all')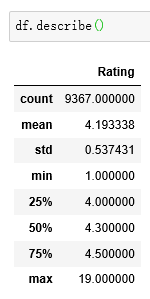
count显示有9367条数据,现在进行一步步数据清洗。
筛选重复数据:
df.drop(df[df.duplicated()].indedx, inplace=True)
duplicated函数筛选重复数据,indedx找出索引。drop函数删除索引数据行,
inplace函数为True时,不创建新的对象,在原数据基础上修改。
为False时对数据进行修改,创建并返回新的对象和结果。 默认为False。单列数据统计预览:
df.Rating.value_counts(dropna=False)
dropna函数为False时,运行结果显示nan值数据。
为True时,运行结果只显示有数据的结果。
这个方式可以预览各个列的数据进行查看,对数据进行筛选清洗。
运行结果有NaN值,数据较少时可以删除,数据比较多时删除会对分析结果产生较大影响。
对这种情况可以选择填充数值,根据具体情况判断可选:中位数,均值等。这里选择均值
df['Rating'].fillna(value=df['Rating'].mean(),inplace=True)
fillna函数给NaN值填充,inplace函数为True时原对象基础上修改。
运行后之前存在的NaN值会被填充为Rating的平均值因为数据分析是对数值类型数据计算,所以数据也要检查和转换为数值类型。
df['Reviews'].value_counts(dropna=False)
统计Reviews列
df['Reviews'].str.isnumeric()
.str.isnumeric()函数,如果字符串只包含数字字符,返回True。否则返回False。
运行结果:
0 True
1 True
2 True
3 True
4 True
...
df['Reviews'] = df['Reviews'].astype('i8')
#将字符串改为数值类型,i8是int64数据类型。
修改为数值类型后,可以用describe函数预览一下
Reviews也变为了数值类型:

预览Size列:

字符串形式,需要转换为可计算的数值类型。
df['Size'] = df['Size'].str.replace('M', 'e+6')
df['Size'] = df['Size'].str.replace('k', 'e+3')
df['Size'] = df['Size'].str.replace('Varies with device', '0')
M替换为e+6,k替换为e+3,'Varies with device'替换为0
df['Size'] = df['Size'].astype('f8')
转换数据类型为f8
df['Size'].replace(0, df['Size'].mean(), inplace=True)
数值0填充为当前列的平均值。再次预览一下,就有了3个可计算的数据列。

这次处理Installs列和处理Size列方法相同。
当然数据处理方法很多,处理方法并不固定。
df['Installs'] = df['Installs'].str.replace('+', '')
df['Installs'] = df['Installs'].str.replace(',', '')
df['Installs'] = df['Installs'].astype('f8')
分别替换字段,修改数据类型。
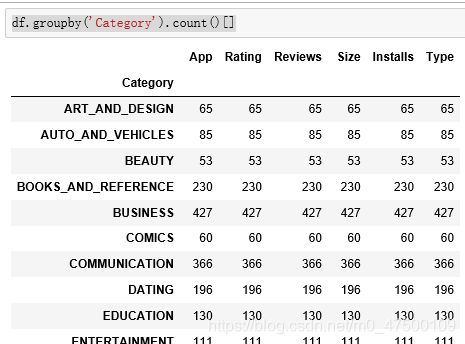
df['Type'].value_counts()
预览Type列
现在数据已经清洗出4列数值型的数据,就可以用来计算分析了!
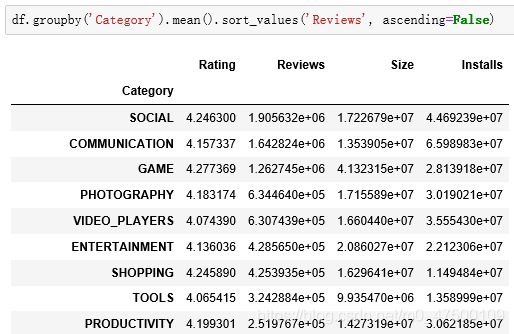
对Category列进行分组统计:
分组Category列,以Reviews数据进行降序排列:
可以得到哪种APP种类SOCIAL评价最多