微服务下使用GraphQL构建BFF
https://zhuanlan.zhihu.com/p/35108457
微服务架构,这个在几年前还算比较前卫的技术在如今遍地开花。得益于开源社区的支持,我们可以轻松地利用 Spring Cloud 以及 Docker 容器化快速搭建一个微服务架构的原型。不管是成熟的互联网公司、创业公司还是个人开发者,对于微服务架构的接纳程度都相当高,微服务架构的广泛应用也自然促进了技术本身更好的发展以及更多的实践。本文将结合项目实践,剖析在微服务的背景下,如何通过前后端分离的方式开发移动应用。
对于微服务本身,我们可以参考 Martin Fowler 对 Microservice 的阐述。简单说来,微服务是一种架构风格。通过对特定业务领域的分析与建模,将复杂的应用分解成小而专一、耦合度低并且高度自治的一组服务。微服务中的每个服务都是很小的应用,这些应用服务相互独立并且可部署。微服务通过对复杂应用的拆分,达到简化应用的目的,而这些耦合度较低的服务则通过 API 形式进行通信,所以服务之间对外暴露的都是 API,不管是对资源的获取还是修改。
微服务架构的这种理念,和前后端分离的理念不谋而合,前端应用控制自己所有的 UI 层面的逻辑,而数据层面则通过对微服务系统的 API 调用完成。以 JSP (Java Server Pages) 为代表的前后端交互方式也逐渐退出历史舞台。前后端分离的迅速发展也得益于前端 Web 框架 (Angular, React 等) 的不断涌现,单页面应用(Single Page Application)迅速成为了一种前端开发标准范式。加之移动互联网的发展,不管是 Mobile Native 开发方式,还是 React Native / PhoneGap 之流代表的 Hybrid 应用开发方式,前后端分离让 Web 和移动应用成为了客户端。客户端只需要通过 API 进行资源的查询以及修改即可。
BFF 概况及演进
Backend for Frontends(以下简称BFF) 顾名思义,是为前端而存在的后端(服务)中间层。即传统的前后端分离应用中,前端应用直接调用后端服务,后端服务再根据相关的业务逻辑进行数据的增删查改等。那么引用了 BFF 之后,前端应用将直接和 BFF 通信,BFF 再和后端进行 API 通信,所以本质上来说,BFF 更像是一种“中间层”服务。下图看到没有BFF以及加入BFF的前后端项目上的主要区别。
1. 没有BFF 的前后端架构
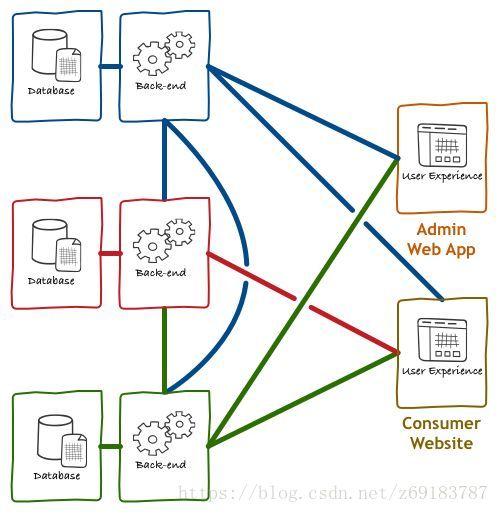
在传统的前后端设计中,通常是 App 或者 Web 端直接访问后端服务,后台微服务之间相互调用,然后返回最终的结果给前端消费。对于客户端(特别是移动端)来说,过多的 HTTP 请求是很昂贵的,所以开发过程中,为了尽量减少请求的次数,前端一般会倾向于把有关联的数据通过一个 API 获取。在微服务模式下,意味着有时为了迎合客户端的需求,服务器常会做一些与UI有关的逻辑处理。
2. 加入了BFF 的前后端架构
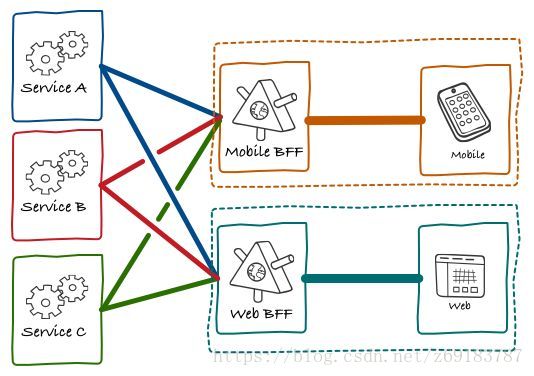
加入了BFF的前后端架构中,最大的区别就是前端(Mobile, Web) 不再直接访问后端微服务,而是通过 BFF 层进行访问。并且每种客户端都会有一个BFF服务。从微服务的角度来看,有了 BFF 之后,微服务之间的相互调用更少了。这是因为一些UI的逻辑在 BFF 层进行了处理。
BFF 和 API Gateway
从上文对 BFF 的了解来看,BFF 既然是前后端访问的中间层服务,那么 BFF 和 API Gateway 有什么区别呢?我们首先来看下 API Gateway 常见的实现方式。(API Gateway 的设计方式可能很多,这里只列举如下三种)
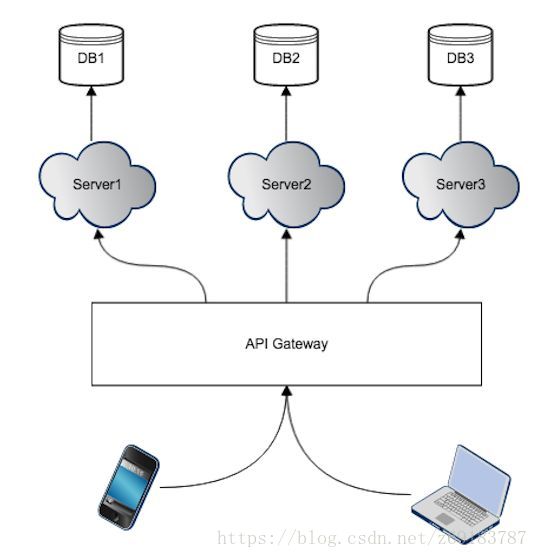
1. API Gateway 的第一种实现:一个 API Gateway 对所有客户端提供同一种 API
单个 API Gateway 实例,为多种客户端提供同一种API服务,这种情况下,API Gateway 不对客户端类型做区分。即所有/api/users的处理都是一致的,API Gateway 不做任何的区分。如下图所示:
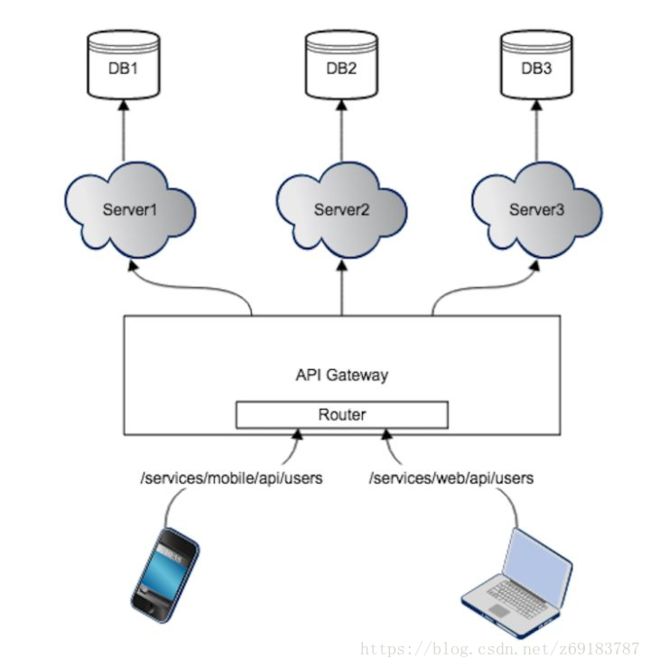
2. API Gateway 的第二种实现:一个 API Gateway 对每种客户端提供分别的 API
单个 API Gateway 实例,为多种客户端提供各自不同的API。比如对于 users 列表资源的访问,web 端和 App 端分别通过/services/mobile/api/users, /services/web/api/users服务。API Gateway 根据不同的 API 判定来自于哪个客户端,然后分别进行处理,返回不同客户端所需的资源。
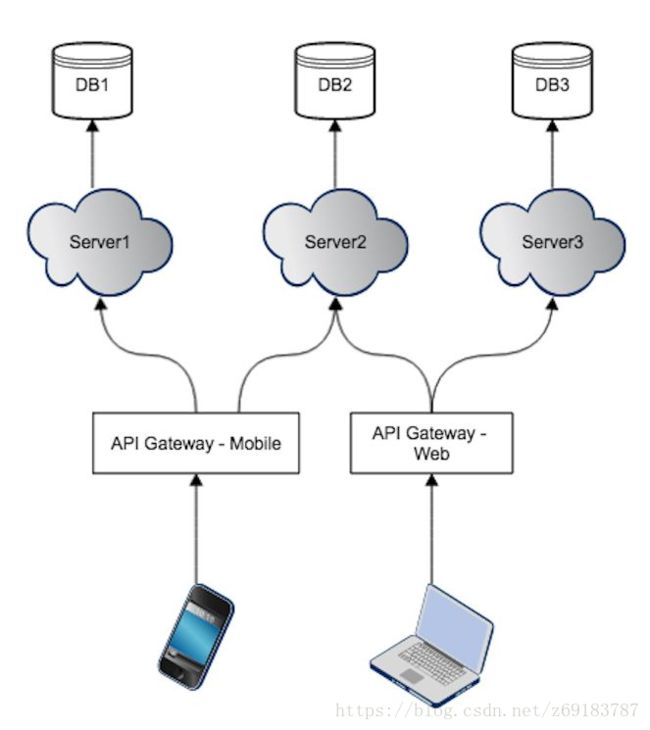
3. API Gateway 的第三种实现:多个 API Gateway 分别对每种客户端提供分别的 API
在这种实现下,针对每种类型的客户端,都会有一个单独的 API Gateway 响应其 API 请求。所以说 BFF 其实是 API Gateway 的其中一种实现模式。
GraphQL 与 REST
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
GraphQL 作为一种 API 查询语句,于2015年被 Facebook 推出,主要是为了替代传统的 REST 模式,那么对于 GraphQL 和 REST 究竟有哪些异同点呢?我们可以通过下面的例子进行理解。
按照 REST 的设计标准来看,所有的访问都是基于对资源的访问(增删查改)。如果对系统中 users 资源的访问,REST 可能通过下面的方式访问:
Request:
GET http://localhost/api/users
Response:
[
{
"id": 1,
"name": "abc",
"avatar": "http://cdn.image.com/image_avatar1"
},
...
]
- 对于同样的请求如果用 GraphQL 来访问,过程如下:
Request:
POST http://localhost/graphql
Body:
query {users { id, name, avatar } }
Response:
{
"data": {
"users": [
{
"id": 1,
"name": "abc",
"avatar": "http://cdn.image.com/image_avatar1"
},
...
]
}
}
关于 GraphQL 更详细的用法,我们可以通过查看文档以及其他文章更加详细的去了解。相比于 REST 风格,GraphQL 具有如下特性:
1. 定义数据模型:按需获取
GraphQL 在服务器实现端,需要定义不同的数据模型。前端的所有访问,最终都是通过 GraphQL 后端定义的数据模型来进行映射和解析。并且这种基于模型的定义,能够做到按需索取。比如对上文/users 资源的获取,如果客户端只关心 user.id, user.name 信息。那么在客户端调用的时候,query 中只需要传入users {id \n name}即可。后台定义模型,客户端只需要获取自己关心的数据即可。
2. 数据分层
查询一组users数据,可能需要获取user.friends, user.friends.addr 等信息,所以针对 users 的本次查询,实际上分别涉及到对 user, frind, addr三类数据。GraphQL 对分层数据的查询,大大减少了客户端请求次数。因为在 REST 模式下,可能意味着每次获取 user 数据之后,需要再次发送 API 去请求 friends 接口。而 GraphQL 通过数据分层,能够让客户端通过一个 API获取所有需要的数据。这也就是 GraphQL(图查询语句 Graph Query Language)名称的由来。
{
user(id:1001) { // 第一层
name,
friends { // 第二层
name,
addr { // 第三层
country,
city
}
}
}
}
3. 强类型
const Meeting = new GraphQLObjectType({
name: 'Meeting',
fields: () => ({
meetingId: {type: new GraphQLNonNull(GraphQLString)},
meetingStatus: {type: new GraphQLNonNull(GraphQLString), defaultValue: ''}
})
})
GraphQL 的类型系统定义了包括 Int, Float, String, Boolean, ID, Object, List, Non-Null 等数据类型。所以在开发过程中,利用强大的强类型检查,能够大大节省开发的时间,同时也很方便前后端进行调试。
4. 协议而非存储
GraphQL 本身并不直接提供后端存储的能力,它不绑定任何的数据库或者存储引擎。它利用已有的代码和技术进行数据源的管理。比如作为在 BFF 层使用 GraphQL, 这一层的 BFF 并不需要任何的数据库或者存储媒介。GraphQL 只是解析客户端请求,知道客户端的“意图”之后,再通过对微服务API的访问获取到数据,对数据进行一系列的组装或者过滤。
5. 无须版本化
const PhotoType = new GraphQLObjectType({
name: 'Photo',
fields: () => ({
photoId: {type: new GraphQLNonNull(GraphQLID)},
file: {
type: new GraphQLNonNull(FileType),
deprecationReason: 'FileModel should be removed after offline app code merged.',
resolve: (parent) => {
return parent.file
}
},
fileId: {type: new GraphQLNonNull(GraphQLID)}
})
})
GraphQL 服务端能够通过添加 deprecationReason,自动将某个字段标注为弃用状态。并且基于 GraphQL 高度的可扩展性,如果不需要某个数据,那么只需要使用新的字段或者结构即可,老的弃用字段给老的客户端提供服务,所有新的客户端使用新的字段获取相关信息。并且考虑到所有的 graphql 请求,都是按照 POST/graphql 发送请求,所以在 GraphQL 中是无须进行版本化的。
GraphQL 和 REST
对于 GraphQL 和 REST 之间的对比,主要有如下不同:
1. 数据获取:REST 缺乏可扩展性, GraphQL 能够按需获取。GraphQL API 调用时,payload 是可以扩展的;
2. API 调用:REST 针对每种资源的操作都是一个 endpoint, GraphQL 只需要一个 endpoint( /graphql), 只是 post body 不一样;
3. 复杂数据请求:REST 对于嵌套的复杂数据需要多次调用,GraphQL 一次调用, 减少网络开销;
4. 错误码处理:REST 能够精确返回HTTP错误码,GraphQL 统一返回200,对错误信息进行包装;
5. 版本号:REST通过 v1/v2 实现,GraphQL 通过 Schema 扩展实现;
微服务 + GraphQL + BFF 实践
在微服务下基于 GraphQL 构建 BFF,我们在项目中已经开始了相关的实践。在我们项目对应的业务场景下,微服务后台有近 10 个微服务,客户端包括针对不同角色的4个 App 以及一个 Web 端。对于每种类型的 App,都有一个 BFF 与之对应。每种 BFF 只服务于这个 App。BFF 解析到客户端请求之后,会通过 BFF 端的服务发现,去对应的微服务后台通过 CQRS 的方式进行数据查询或修改。
1. BFF 端技术栈

我们使用 GraphQL-express 框架构建项目的 BFF 端,然后通过 Docker 进行部署。BFF 和微服务后台之间,还是通过 registrator 和 Consul 进行服务注册和发现。
addRoutes () {
this.express.use('/graphql', this.resolveFromRequestScopeAndHandle('GraphqlHandler'))
this.serviceNames.forEach(serviceName => {
this.express.use(`/api/${serviceName}`, this.routers.apiProxy.createRouter(serviceName))
})
}
在 BFF 的路由设置中,对于客户端的处理,主要有 /graphql 和 /api/${serviceName}两部分。/graphql 处理的是所有 GraphQL 查询请求,同时我们在 BFF 端增加了/api/${serviceName} 进行 API 透传,对于一些没有必要进行 GraphQL 封装的请求,可以直接通过透传访问到相关的微服务中。
2. 整体技术架构
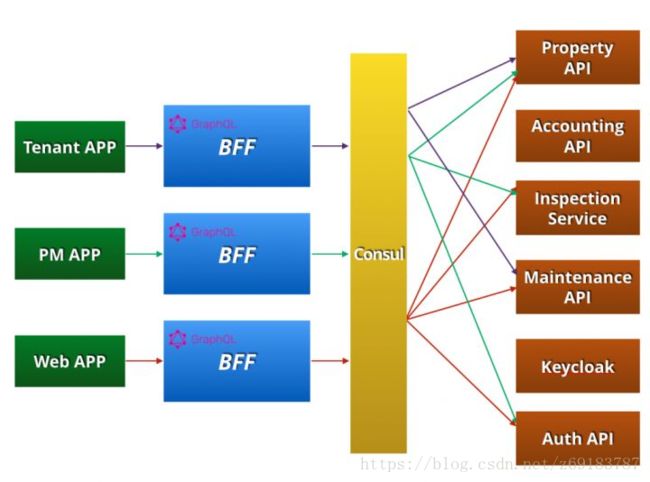
整体来看,我们的前后端架构图如下,三个 App 客户端分别使用 GraphQL 的形式请求对应的 BFF。BFF 层再通过 Consul 服务发现和后端通信。
关于系统中的鉴权问题
用户登录后,App 直接访问 KeyCloak 服务获取到 id_token,然后通过 id_token 透传访问 auth-api 服务获取到 access_token, access_token 以 JWT (Json Web Token) 的形式放置到后续 http 请求的头信息中。
在我们这个系统中 BFF 层并不做鉴权服务,所有的鉴权过程全部由各自的微服务模块负责。BFF 只提供中转的功能。BFF 是否需要集成鉴权认证,主要看各系统自己的设计,并不是一个标准的实践。
3. GraphQL + BFF 实践
通过如下几个方面,可以思考基于 GraphQL 的 BFF 的一些更好的特质:
GraphQL 和 BFF 对业务点的关注
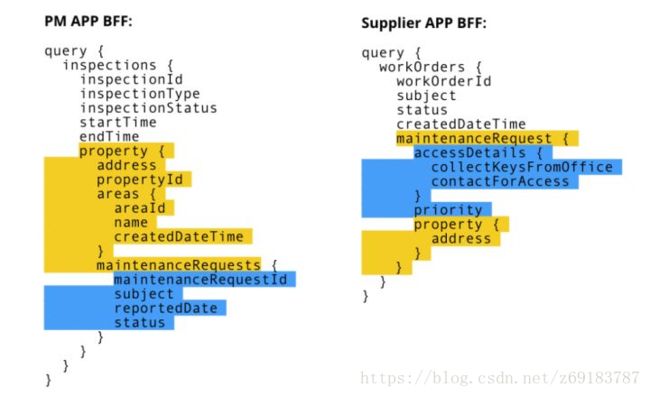
从业务上来看,PM App(使用者:物业经理)关注的是property,物业经理管理着一批房屋,所以需要知道所有房屋概况,对于每个房屋需要知道有没有对应的维修申请。所以 PM App BFF 在定义数据结构是,maintemamceRequests 是property 的子属性。
同样类似的数据,Supplier App(使用者:房屋维修供应商)关注的是 maintenanceRequest(维修工单),所以在 Supplier App 获取的数据里,我们的主体是maintenanceRequest。维修供应商关注的是workOrder.maintenanceRequest。
所以不同的客户端,因为存在着不同的使用场景,所以对于同样的数据却有着不同的关注点。BFF is pary of Application。从这个角度来看,BFF 中定义的数据结构,就是客户端所真正关心的。BFF 就是为客户端而生,是客户端的一部分。需要说明的是,对于“业务的关注”并不是说,BFF会处理所有的业务逻辑,业务逻辑还是应该由微服务关心,BFF 关注的是客户端需要什么。
GraphQL 对版本化的支持
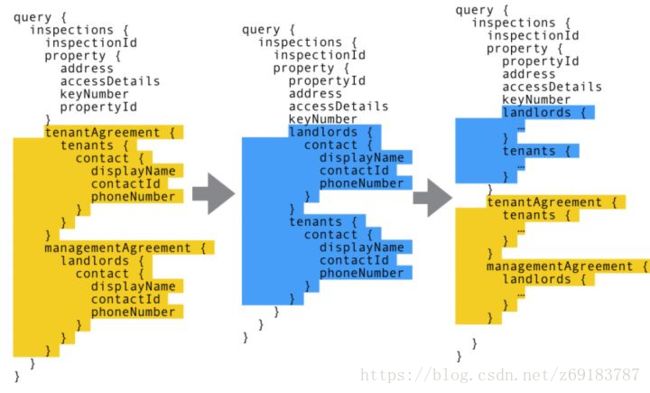
假设 BFF 端已经发布到生产环境,提供了 inspection 相关的 tenants 和 landlords 的查询。现在需要将图一的结构变更为图二的结构,但是为了不影响老用户的 API 访问,这时候我们的 BFF API 必须进行兼容。如果在 REST 中,可能会增加api/v2/inspections进行 API 升级。但是在 BFF 中,为了向前兼容,我们可以使用图三的结构。这时候老的 APP 使用黄色区域的数据结构,而新的 APP 则使用蓝色区域定义的结构。
GraphQL Mutation 与 CQRS
mutation {
area {
create (input: {
areaId:"111",
name:"test",
})
}
}
如果你详细阅读了 GraphQL 的文档,可以发现 GraphQL 对 query 和 mutation 进行了分离。所有的查询应该使用 query { ...},相应的 mutaition 需要使用 mutation { ... }。虽然看起来像是一个convention,但是 GraphQL 的这种设计和后端 API 的 读写职责分离(Command Query Responsibility Segregation)不谋而合。而实际上我们使用的时候也遵从这个规范。所以的 mutation 都会调用后台的 API,而后端的 API 对于资源的修改也是通过 SpringBoot EventListener 实现的 CQRS 模式。
如何做好测试
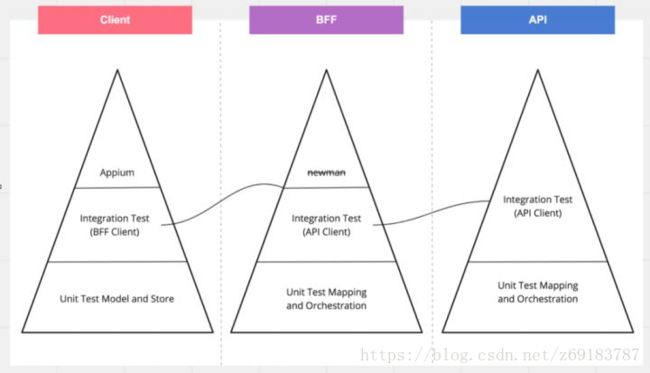
在引入了 BFF 的项目,我们的测试仍然使用金字塔原理,只是在客户端和后台之间,需要添加对 BFF 的测试。
- Client 的 integration-test 关心的是 App 访问 BFF 的连通性,App 中所有访问 BFF 的请求都需要进行测试;
- BFF 的 integration-test 测试的是 BFF 到微服务 API 的连通性,BFF 中依赖的所有 API 都应该有集成测试的保障;
- API 的 integration-test 关注的是这个服务对外暴露的所有 API,通常测试所有的 Controller 中的 API;
结语
微服务下基于 GraphQL 构建 BFF 并不是银弹,也并不一定适合所有的项目,比如当你使用 GraphQL 之后,你可能得面临多次查询性能问题等,但这不妨碍它成为一个不错的尝试。你也的确看到 Facebook 早已经使用 GraphQL,而且 Github 也开放了 GraphQL 的API。而 BFF, 其实很多团队也都已经在实践了,在微服务下等特殊场景下,GraphQL + BFF 也许可以给你的项目带来惊喜。
参考资料
【注】部分图片来自网络
- https://martinfowler.com/articles/microservices.html
- https://www.thoughtworks.com/insights/blog/bff-soundcloud
- http://philcalcado.com/2015/09/18/thebackendforfrontendpattern_bff.html
- http://samnewman.io/patterns/architectural/bff
- https://medium.com/netflix-techblog/embracing-the-differences-inside-the-netflix-api-redesign-15fd8b3dc49d
文/ThoughtWorks 龚铭