简介: 在存储计算分离的场景下,通过网络从远端存储读取数据是一个代价较大的操作,往往会带来性能的损耗。以OSS为例,OSS数据读取延时通常较本地磁盘大很多,同时OSS对单个用户使用的带宽上限做了限制,这都会对数据分析的延时造成影响。在云原生数据湖分析(DLA)SQL引擎中,我们通过引入本地缓存机制,将热数据缓存在本地磁盘,拉近数据和计算的距离,减少从远端读取数据带来的延时和IO限制,实现更小的查询延时和更高的吞吐。
背景
在数据上云的大背景下,随着网络和存储硬件能力的提升,存储计算分离逐渐成为了大数据处理的一大趋势。相比于存储和计算耦合的架构,存储计算分离可以带来许多好处,例如允许独立扩展计算和存储、提高资源的利用率、提高业务的灵活性等等。特别是,借助云上的基础设施,存储可以选择便宜的对象存储OSS,计算资源可以按需付费和弹性扩缩容,这些都使得存储计算分离架构可以很好的发挥云计算的成本优势和灵活性。
但是在存储计算分离的场景下,通过网络从远端存储读取数据仍然是一个代价较大的操作,往往会带来性能的损耗。以OSS为例,OSS数据读取延时通常较本地磁盘大很多,同时OSS对单个用户使用的带宽上限做了限制,这都会对数据分析的延时造成影响。在云原生数据湖分析(DLA)SQL引擎中,我们通过引入本地缓存机制,将热数据缓存在本地磁盘,拉近数据和计算的距离,减少从远端读取数据带来的延时和IO限制,实现更小的查询延时和更高的吞吐。
DLA SQL引擎基于弹性的Presto,采取计算与存储完全分离的架构,支持对用户存储在OSS、HDFS等介质上的各种文件格式进行Adhoc查询、BI分析、轻量级ETL等数据分析工作。此次推出数据湖分析加速,DLA与开源大规模数据编排系统厂商Alluxio合作,借助Alluxio提供的缓存加速能力,解决存储计算分离场景下从远端读取数据带来的性能损耗。未来双方将继续在数据湖技术领域开展全方位合作,为客户提供一站式、高效的数据湖分析与计算服务。
DLA SQL数据湖分析加速方案
基于Alluxio的缓存加速原理
- 架构
在DLA SQL引擎中,负责从远端数据源读取数据的角色是Worker节点。因此,一个自然的想法就是在Worker节点缓存热数据,来实现查询加速的效果。如下图所示:

这里主要的挑战是在大数据量场景下面如何提高缓存的效率,包括:如何快速定位和读取缓存数据,如何提高缓存命中率,如何快速从远端加载缓存数据等。为了解决这些问题,在单机层面,我们使用Alluxio来实现对缓存的管理,借助Alluxio提供的能力,提高缓存的效率;而在系统层面,使用SOFT_AFFINITY提交策略在worker和数据之间建立对应关系,使得同一段数据(大概率)总是在同一个worker上面读取,从而提高缓存的命中率。
SOFT_AFFINITY提交策略
Presto默认的split提交策略是NO_PREFERENCE,在这种策略下面,主要考虑的因素是worker的负载,因此某个split会被分到哪个worker上面很大程度上是随机的。而在缓存的场景里面则需要考虑“数据本地化”的因素,如果一个split总是被提交到同一个worker上面,对提高缓存效率会很有帮助。
因此,在DLA SQL中,我们使用SOFT_AFFINITY提交策略。在提交Hive的split时,会通过计算split的hash值,尽可能将同一个split提交到同一个worker上面。如下图所示。

使用_SOFT_AFFINITY_策略时,split的提交策略是这样的:
- 通过split的hash值确定split的首选worker和备选worker。
- 如果首选worker空闲,则提交到首选worker。
- 如果首选worker繁忙,则提交到备选worker。
- 如果备选worker也繁忙,则提交到最不繁忙的worker。
如下图:

这里面,“繁忙”的判断根据如下两个参数来确定:
- node-scheduler.max-splits-per-node参数用来控制每个worker上面最大可以提交多少个split,默认是100。超出这个值则判定这个worker繁忙。
- node-scheduler.max-pending-splits-per-task用来控制每个worker上面最多可以有多少个split处于Pending状态。超出这个值则判定这个worker繁忙。
通过这样的判断,可以兼顾数据本地化和worker的负载,避免因为split的hash不均匀造成worker之间的负载不平衡,也不会因为某个worker特别慢而导致查询整体变慢。
Alluxio缓存管理
在Worker上面,我们基于Alluxio Local Cache来对缓存进行管理。 Local Cache是一个嵌入在Presto进程中的库,通过接口调用的方式和Presto通信。和使用Alluxio集群相比,Local Cache模式下Presto调用Alluxio带来的成本更小,同时Local Cache具备完整的缓存管理的功能,包括缓存的加载、淘汰、元数据管理和监控。此外,Alluxio支持缓存的并发异步写入,支持缓存的并发读取,这些都对提高缓存效率有很好的帮助。
Alluxio对外暴露的是一个标准的HDFS接口,因此Cache的管理对Presto是透明的。在这个接口内部,当用户查询需要访问OSS数据源时,如果数据存在于本地缓存中,就会直接从缓存读取数据,加速查询;如果没有命中缓存,就会直接从OSS读取数据(并异步写入到本地磁盘)。

DLA中的进一步优化
提高缓存命中率
为了实现更高的缓存命中率,我们主要做了两方面的工作:
- 在成本允许的范围内尽量调大用于缓存加速的磁盘空间。
- 提高数据“本地化”的比例。
前者很好理解,这里重点介绍后者。
我们分析前面讲的SOFT_AFFINITY提交策略就会发现,如果查询进入“繁忙”的状态,split就会回退到和NO_PREFERENCE一样的随机提交,这种情况下数据“本地化”的比例肯定会降低,因此关键是要尽量避免“繁忙”。但是如果简单调大“繁忙”的阈值,又可能造成worker负载不均匀,cache带来的性能提升被长尾效应吃掉了。
在DLA中,我们是这样做的:
- 调大node-scheduler.max-splits-per-node的值,使更多的split可以命中缓存。
- 修改HiveSplit的hash算法,在计算hash值时不仅使用文件名,也使用split在文件中的位置,这样就可以避免大文件被hash到一个worker上面,split的hash值天然就会有比较均匀的分布。
提高磁盘吞吐
除了缓存命中率,提高缓存效率的另一个关键点是缓存的读写速度。在基于磁盘的缓存方案里面,实现这个目标的一个重要部分就是提高磁盘的吞吐性能。
在DLA中,我们使用高效云盘来作为缓存的数据盘。背后的考虑是我们把缓存加速特性作为CU版的内置产品能力,不额外收取费用,这就要求缓存引入的成本在CU的总成本中占比要足够小,所以我们不能使用价格昂贵的SSD盘。从成本出发,使用高效云盘是必然的选择,但是这样就需要解决高效云盘单盘吞吐低的问题。
我们通过使用多块盘并在缓存写入时打散来实现更高的吞吐,这样就弥补了云盘吞吐不足的问题。目前DLA中的配置,实测单机读写吞吐均可达到接近600MB/s,在降低成本的同时仍然提供了很好的读写性能。
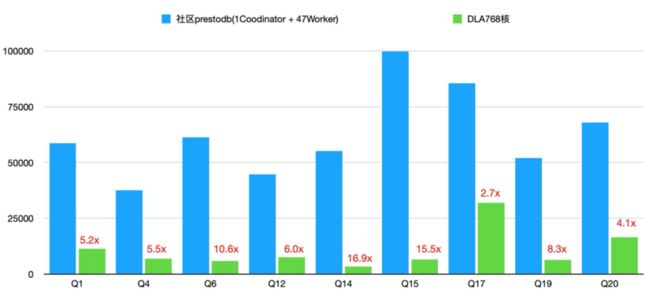
性能测试
我们针对社区版本prestodb和DLA做了性能对比测试。社区版本我们选择了prestodb 0.228版本,并通过复制jar包以及修改配置的方式增加对oss数据源的支持。我们分别对DLA-SQL CU版256核1024GB、512核2048GB、768核3072GB三种规格与同等算力的社区版本集群进行了对比。
测试的查询我们选择TPC-H 1TB数据测试集。由于TPC-H的大部分查询并不是IO密集型的,所以我们只从中挑选出符合如下两个标准的查询来做比较:
- 查询中包含了对最大的表lineitem的扫描,这样扫描的数据量足够大,IO有可能成为瓶颈。
- 查询中不涉及多个表的join操作,这样就不会有大数据量参与计算,因而计算不会先于IO而成为瓶颈。
按照这两个标准,我们选择了对lineitem单个表进行查询的Q1和Q6,以及lineitem和另一个表进行join操作的Q4、Q12、Q14、Q15、Q17、Q19和Q20。
测试结果如下:


如何使用
目前缓存特性只在CU版提供,新购买的集群自动开通对oss、hdfs数据源的缓存能力。已有集群可以联系我们升级到最新版本。关于CU的开通和使用可以参考我们的帮助文档。
我们现在还有一元1000CU时的优惠套餐,欢迎试用。点击购买套餐
总结与展望
缓存加速特性通过将热数据缓存在本地磁盘,提供更小的查询延时和更高的吞吐,对IO密集的查询有很好的加速效果。在云上普遍计算和存储分离的场景中,缓存一定还具有更广阔的应用场景。未来我们会进一步探索缓存在Maxcompute等其他数据源和场景的使用,为更多类型的数据读取和计算做加速,提供更好的查询性能。
作者:云原生数据湖分析DLA
原文链接
本文为阿里云原创内容,未经允许不得转载