豆瓣Top250电影榜单,Python爬虫scrapy框架+selenium爬取数据并把电影图片下载到本地
最近自己用一个python里面非常常用的爬虫框架scrapy爬取豆瓣Top250电影榜单的一些数据,具体过程如下:
首先提前下载好一些库,最主要的是scrapy和selenium
开启项目
开启一个scrapy项目,创建scrapy项目需要在命令行中进行,输入指令 scrapy startproject douban

创建spider
接着创建一个spider.py文件,发起请求的逻辑和解析返回的结果都在这个类中实现,输入指令:scrapy genspider+类名+域名

创建Item
Item是保存爬取数据的容器。打开项目中的items.py文件,根据自己的需要,定义字段。
from scrapy import Item,Field
class DoubanItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
number = Field()
name = Field()
grade = Field()
move_describe = Field()
evaluate = Field()
introduce = Field()
image_url = Field()编写spider.py文件
上面已经说过,请求网站的逻辑和解析Response都要在spider文件里面实现,所以这是一个非常重要的类,打开我们刚刚创建的padouban.py
里面有一个方法:

刚开始的start_urls返回结果也是默认调用此方法进行Response解析,后续的请求逻辑可在这个方法里实现,每当请求成功获取到Response时,可以在这个方法里解析返回的Response,即可以调用自身进行解析Response
解析过程的代码:
#获取电影条目列表
move_lists = response.xpath("//ol[@class='grid_view']/li")
for move in move_lists:
item = DoubanItem()
#img标签,获取属性用::attr(xxx),获取内容用::text
item['name'] = ''.join(move.css('.pic a img::attr(alt)').extract()).strip()
item['grade'] = ''.join(move.css('.star span.rating_num::text').extract()).strip()
item['number'] = ''.join(move.css('.pic em::text').extract()).strip()
item['move_describe'] = ''.join(move.css('.quote span.inq::text').extract()).strip()
item['evaluate'] = ''.join(move.css('.star span:nth-child(4)::text').extract()).strip()
introduce_content = move.xpath(".//div[@class='bd']/p[1]/text()").getall()
introduce = ''
for content in introduce_content:
content_s = ''.join(content.split())
introduce = introduce + content_s + ' '
item['introduce'] = introduce
image_url = ''.join(move.css('.pic a img::attr(src)').extract()).strip()
item['image_url'] = image_url
self.urllist.append(image_url)
yield item请求逻辑代码:
#获取下一页内容
next_text = response.xpath("//div[@class='paginator']/span[@class='next']")
next_page = ''.join(next_text.css('a::attr(href)').extract()).strip()
if next_page:
url = 'https://movie.douban.com/top250' + next_page
yield Request(url=url, callback=self.parse)
下载图片:
我这里的下载过程是先把图片的url获取到,在获取到所有的图片url后才下载图片并保存到本地。
代码如下:
#获取下一页内容
next_text = response.xpath("//div[@class='paginator']/span[@class='next']")
next_page = ''.join(next_text.css('a::attr(href)').extract()).strip()
if next_page:
url = 'https://movie.douban.com/top250' + next_page
yield Request(url=url, callback=self.parse)
else:#爬取完所有电影条目开始下载图片
for url in self.urllist:
self.save_image(url)
def save_image(self,url):
#用requests申请图片资源
reponse = requests.get(url)
#获取图片名字
img_name = url.split('/')[-1]
#图片保存的路径
img_path = self.dir_path + r'\{0}'.format(img_name)
#用os进行图片保存,保存在本地
try:
if not os.path.exists(self.dir_path):
os.makedirs(self.dir_path)
if not os.path.exists(img_path):
with open(img_path, 'wb') as f:
f.write(reponse.content)
f.close()
else:
print("文件已存在")
except:
print("执行出错")完整的spider文件代码:
# -*- coding: utf-8 -*-
from scrapy import Request,Spider
from douban.items import DoubanItem
import requests,os
class PadoubanSpider(Spider):
urllist = []
#获取当前文件padouban.py所在的目录
dir = os.path.dirname(__file__)
#图片的保存目录
dir_path = dir + '/' + 'tupian'
name = 'padouban'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
pass
if response.status == 404:
print('failed url')
#获取电影条目列表
move_lists = response.xpath("//ol[@class='grid_view']/li")
for move in move_lists:
item = DoubanItem()
#img标签,获取属性用::attr(xxx),获取内容用::text
item['name'] = ''.join(move.css('.pic a img::attr(alt)').extract()).strip()
item['grade'] = ''.join(move.css('.star span.rating_num::text').extract()).strip()
item['number'] = ''.join(move.css('.pic em::text').extract()).strip()
item['move_describe'] = ''.join(move.css('.quote span.inq::text').extract()).strip()
item['evaluate'] = ''.join(move.css('.star span:nth-child(4)::text').extract()).strip()
introduce_content = move.xpath(".//div[@class='bd']/p[1]/text()").getall()
introduce = ''
for content in introduce_content:
content_s = ''.join(content.split())
introduce = introduce + content_s + ' '
item['introduce'] = introduce
image_url = ''.join(move.css('.pic a img::attr(src)').extract()).strip()
item['image_url'] = image_url
self.urllist.append(image_url)
yield item
#获取下一页内容
next_text = response.xpath("//div[@class='paginator']/span[@class='next']")
next_page = ''.join(next_text.css('a::attr(href)').extract()).strip()
if next_page:
url = 'https://movie.douban.com/top250' + next_page
yield Request(url=url, callback=self.parse)
else:#爬取完所有电影条目开始下载图片
for url in self.urllist:
self.save_image(url)
def save_image(self,url):
# 用requests申请图片资源
reponse = requests.get(url)
# 获取图片名字
img_name = url.split('/')[-1]
#图片保存的路径
img_path = self.dir_path + r'\{0}'.format(img_name)
# 用os进行图片保存,保存在本地
try:
if not os.path.exists(self.dir_path):
os.makedirs(self.dir_path)
if not os.path.exists(img_path):
with open(img_path, 'wb') as f:
f.write(reponse.content)
f.close()
else:
print("文件已存在")
except:
print("执行出错")
编写middleware.py文件
由于我用的是selenium进行数据的爬取,所以要在middleware.py实现一个Downloader Middleware。下面介绍一下Downloader Middleware:
Downloader Middleware即下载中间件,它是处于scrapy的Request和Response之间的处理模块。Downloader Middleware在整个scrapy框架中所起的作用主要有以下两个:
1.在Request调度出来执行请求之前,也就是我们可以在Request执行下载之前对其进行修改,通俗点讲就是在请求之前,我们可以在这里对请求进行一些处理。
2.在请求成功后获取到Response发送给Spider进行解析之前,也就是我们可以在生成Response被Spider解析之前对其进行修改
所以,我们可以在middleware.py中实现一个Downloader Middleware,用它来使用selenium启动浏览器爬取数据,代码如下:
class seleniumMiddleware(object):
def __init__(self):
self.timeout = 20
self.browser = webdriver.Firefox()
self.browser.set_page_load_timeout(self.timeout)
self.wait = WebDriverWait(self.browser,self.timeout)
def process_request(self, request, spider,):
self.browser.get(request.url)
time.sleep(1.0)
return HtmlResponse(url=request.url, body=self.browser.page_source, encoding='utf-8', request=request)
之后我们还要在settings.py进行注释,自定义的Downloader Middleware一定要在settings.py中进行注释,否则该自定义的类就不会被执行。
DOWNLOADER_MIDDLEWARES = {
'douban.middlewares.seleniumMiddleware': 100,
}编写pipelines.py文件
爬取到的电影信息会保存到MongoDB里面去,所以要在pipelines.py里面自定义一个MongoPipeline类。当spider解析完Response产生Item之后,Item就会传到pipeline这里,被定义的Item pipeline组件会顺次调用,完成一连串的处理过程,如:数据清洗,数据存储…
代码如下:
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_uri = crawler.settings.get('MONGO_URI'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self,item,spider):
self.db[self.collection_name].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()之后我们还要在settings.py进行注释,自定义的MongoPipeline类一定要在settings注释后才会被执行。
ITEM_PIPELINES = {
'douban.pipelines.MongoPipeline':300
}settings.py里MongoDB相关注释:
MONGO_URI = 'localhost'
MONGO_DB = 'DouBan'执行项目
执行项目可在命令行中进行,输入指令 scrapy crawl padouban
运行结果如下:

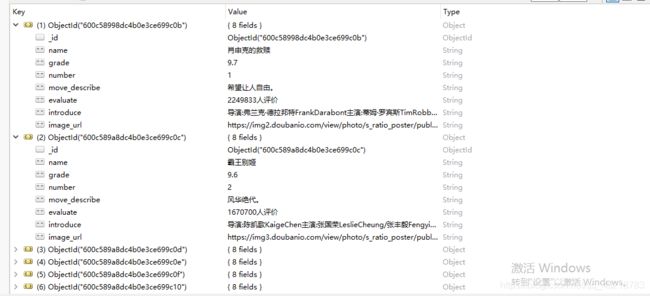
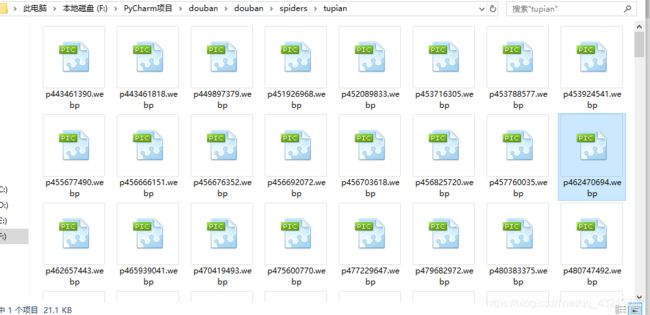
补充:另外两种项目执行方式
第一种:
如果不想把数据保存到MongoDB,而是直接输出,可在命令行输入指令:scrapy crawl padouban -o test.csv(这里我指定输出csv文件)

第二种:
如果不想在命令行中执行项目,可在项目中建立一个main.py启动文件:
代码如下:
from scrapy import cmdline
cmdline.execute('scrapy crawl padouban'.split())