吴恩达机器学习作业(python版)—— ex1线性回归
文章目录
-
- 【1】单变量线性回归
-
- 1.题目描述:
- 2.涉及知识点:
- 3.详细代码解释
- 4.完整代码
- 【2】梯度下降
-
- 1.涉及知识点
- 2.详细代码解释
- 3.完整代码
- 【3】多变量线性回归
-
- 1.题目描述
- 2.涉及知识点
- 3.详细代码解释
- 【4】正规方程
-
- 1.涉及知识点
- 2.详细代码解释
- 【5】slearn线性回归算法
以下代码本人是使用JupiterLab运行的,所以没有print语句,此外本文章所有的代码是放在一起运行的
【1】单变量线性回归
1.题目描述:
在本部分的练习中,您将使用一个变量实现线性回归,以预测食品卡车的利润。假设你是一家餐馆的首席执行官,正在考虑不同的城市开设一个新的分店。该连锁店已经在各个城市拥有卡车,而且你有来自城市的利润和人口数据。
您希望使用这些数据来帮助您选择将哪个城市扩展到下一个城市。
2.涉及知识点:
(1)打开数据文档
(2)会根据导入的数据画散点图
(3)了解matrix的基本操作:转置,相乘,转化
3.详细代码解释
(1)导入需要使用的包
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
(2)打开所需的数据文档,并打印查看
path = 'ex1data1.txt' #将文档名字存在path中
data = pd.read_csv(path,header=None,names=['Population','Profit'])
data
输出将文档数据转化为图表

可以统计并查看下数据的情况
data.describe()
 (3)将数据转化为散点图
(3)将数据转化为散点图
data.plot(kind = 'scatter',x='Population',y='Profit',figsize=(12,8))
#figsize=(12,8)控制画布长宽
plt.show() #呈现在画布上

(4) 计算代价函数的表达式J(θ)
为了保证h(x)包含常数项,所以增加一个特征变量x0=1,体现在表中为增加一列为1的数据
data.insert(0,'ones',1)
cols = data.shape[1]#查看一下插入后的列数
col #3
data.shape[1]:表示data的列数;
data.shape[0]:表示data的行数
插入后的数据如下:

代价函数表达式如下
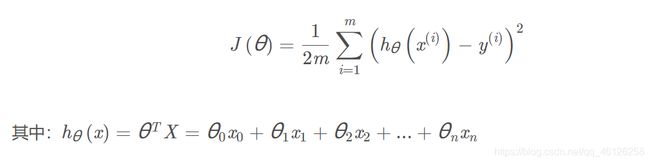
转化为代码则如下:
def computeCost(X,y,theta):
inner = np.power( (np.dot( X , theta.T) - y), 2)
return np.sum(inner) / ( 2 * len(X) )
理论上:
X:特征变量的矩阵,维数为 (n+1)×1
y:真实的利润,(h(x)-y)^2表示建模误差
theta:h(x)中对x进行线性组合的参数矩阵,从(0,0)开始尝试
.T表示转置、np.power( , )求平方、np.dot( , )或 * 为矩阵相乘
矩阵乘法的区分如有不懂,-> 请戳这里
代码中:
X = data.iloc[:,0:cols-1]
#去掉data的最后一列 :取所有行,0列到cols-1列
X = np.matrix(X.values) #根据X的值做成矩阵
y = data.iloc[:,cols-1:cols]
#取data的最后一列:去所有行,倒数第一列
y = np.matrix(y.values)
theta = np.matrix(np.array([0,0]))#theta 是一个(1,2)矩阵
不会使用iloc的小伙伴请戳这里 -> iloc的使用方法链接
5.调用
computeCost(X,y,theta) #求出代价函数的值32.072733877455676
4.完整代码
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
def computeCost(X,y,theta): #代价函数
inner = np.power( (np.dot( X , theta.T) - y), 2)
return np.sum(inner) / ( 2 * len(X) )
path = 'ex1data1.txt'
data = pd.read_csv(path,header=None,names=['Population','Profit'])
data.insert(0,'ones',1)
cols = data.shape[1]
X = data.iloc[:,0:cols-1]
y = data.iloc[:,cols-1:cols]
X = np.matrix(X.values)
y = np.matrix(y.values)
theta = np.matrix(np.array([0,0]))
computeCost(X,y,theta)
【2】梯度下降
相当于多变量的线性回归问题,与单变量相比theta矩阵会变为1×(n+1)维

1.涉及知识点
1.theta.shape[0]:theta的行数;theta.shape[1]:theta的列数
2.numpy.linspace的使用方法:-> 请戳这位博主的博文
3. plt.subplots的使用方法:-> 请戳这位博主的博文
如果依然难以理解 -> 请戳这里
2.详细代码解释
(1)设置学习率、迭代次数
alpha = 0.01
iters = 1000
(2)梯度下降函数
首先随意设置θ0,θ1(即theta矩阵),这里使用的是[ [0,0] ],根据此点在J(θ)关于θ0,θ1的函数中移动(1000次)从而找到能使J(θ)最小的theta矩阵。
因为后面需要画cost与iters的函数图像(检查我们的iters初值是否合理),所以需要求出不同的迭代产生的cost。初始化cost矩阵后,将每次迭代产生的新的θ带入更新cost矩阵,最后作为返回值返回。
注意:迭代的时候需要把中间计算的theta放入临时的tmp中。
def gradientDescent(X,y,theta,alpha,iters):
tmp = np.matrix(np.zeros(theta.shape)) #初始化的1x2临时矩阵
cost = np.zeros(iters) #初始不同的θ组合对应的J(θ)
m = X.shape[0] #数据的组数即X矩阵的行数
for i in range(iters): #迭代iters次
tmp = theta - ( alpha / m )*( X * theta.T - y ).T * X
#X(97,2),theta.T(2,1),y(97,1)
theta = tmp
cost[i] = computeCost(X,y,theta)
return theta,cost
(3)调用函数得出最优theta
final_theta,cost = gradientDescent(X,y,theta,alpha,iters)
computeCost(X, y,final_theta)
#4.5159555030789118
(4)画出图像查看拟合
画出此时theta对应的函数图像,并与散点图做对比,查看拟合度
x = np.linspace(data.Population.min(),data.Population.max(),100)
f = final_theta[0, 0] + (final_theta[0, 1] * x)
fig, ax = plt.subplots(figsize=(12,8)) #调整画布的大小
ax.plot(x, f, 'r', label='Prediction') #画预测的直线 并标记左上角的标签
ax.scatter(data.Population, data.Profit, label='Traning Data') #画真实数据的散点图 并标记左上角的标签
ax.legend(loc=2) #显示标签
ax.set_xlabel('Population') #设置横轴标签
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size') #设置正上方标题
plt.show() #显示图像
效果见下图

画出此时cost与迭代次数iters的函数,发现设置的1000次可以取到最小的J(θ)
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(np.arange(iters), cost, color = 'r')
# 横坐标为0-1000的等差数组,纵坐标为cost
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
plt.show()
效果见下图

3.完整代码
def gradientDescent(X,y,theta,alpha,iters): #梯度下降函数
tmp = np.matrix(np.zeros(theta.shape))
cost = np.zeros(iters)
m = X.shape[0]
for i in range(iters):
tmp = theta - ( alpha / m )*( X * theta.T - y ).T * X
#X(97,2),theta.T(2,1),y(97,1)
theta = tmp
cost[i] = computeCost(X,y,theta)
return theta,cost
alpha = 0.01 #设置 α 和 迭代次数
iters = 1000
final_theta,cost = gradientDescent(X,y,theta,alpha,iters)
computeCost(X, y,final_theta)
#4.5159555030789118
#以下为画图部分
x = np.linspace(data.Population.min(),data.Population.max(),100)
f = g[0, 0] + (g[0, 1] * x)
fig, ax = plt.subplots(figsize=(12,8)) #调整画布的大小
ax.plot(x, f, 'r', label='Prediction') #画预测的直线 并标记左上角的标签
ax.scatter(data.Population, data.Profit, label='Traning Data')
#画真实数据的散点图 并标记左上角的标签
ax.legend(loc=2) #显示标签
ax.set_xlabel('Population') #设置横轴标签
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size') #设置正上方标题
plt.show() #显示图像
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(np.arange(iters), cost, color = 'r')
# 横坐标为0-1000的等差数组,纵坐标为cost
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
plt.show()
【3】多变量线性回归
1.题目描述
练习1还包括一个房屋价格数据集,其中有2个变量(房子的大小,卧室的数量)和目标(房子的价格)。 我们使用我们已经应用的技术来分析数据集。
2.涉及知识点
1.特征归一化:
使用特征归一化可以让迭代次数变少,具体的细节原因和解释可以参考这位博主的博文 -> 请戳这里
3.详细代码解释
(1)导入文档数据+画图
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
path = 'ex1data2.txt'
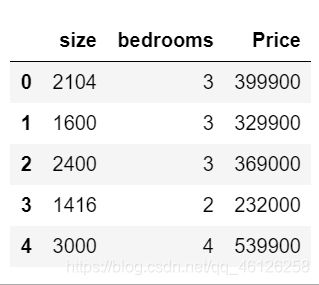
data2 = pd.read_csv(path,header=None,names=['size','bedrooms','Price'])
data2.head()
效果如下(使用data2.head()只显示前5行)
(2)对数据进行预处理
data2 = (data2 - data2.mean()) / data2.std()
data2.head()
data2 = (data2 - data2.mean()) / data2.std()简洁的语句实现了标准化变换(可以当作固定化的处理),类似地可以实现任何想要的变换。
data.mean(axis=0) :输出矩阵为一行,求每列的平均值,同理data.mean(axis=1): 输出矩阵为一列,求每行的平均值
data.std(axis=0) :输出矩阵为一列,求每列的标准差,同理data.std(axis=1) :输出矩阵为一列,求每行的标准差
标准差也成为标准偏差,表示数据的离散程度,和标准差大小成反比
效果见下图

(3)求取最优的theta,并计算J(θ)
重复第1部分的预处理步骤,并对新数据集运行线性回归程序
data2.insert(0, 'ones', 1)
cols = data2.shape[1]
X2 = data2.iloc[:,0:cols-1]
y2 = data2.iloc[:,cols-1:cols]
X2 = np.matrix(X2.values)
y2 = np.matrix(y2.values)
theta2 = np.matrix(np.array([0,0,0]))
iters2 = 1000
alpha2 = 0.1
final_thata2,cost2 = gradientDescent(X2,y2,theta2,alpha2,iters2)
computeCost(X2,y2,final_thata2) #0.13068648053904197
final_thata2
#matrix([[-9.62057904e-17, 8.84765988e-01, -5.31788197e-02]])
(4)画图查看iters和J(θ)的关系
可以明显地发现进行预处理后达到最优的theta所需的迭代次数变少
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(np.arange(iters2), cost2, 'r')
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
plt.show()

【4】正规方程
求使J(θ)最优的θ,除了用梯度下降,还可以使用正规方程
1.涉及知识点
1.np.linalg.inv():矩阵求逆
2.@表示矩阵乘法,其他形式的矩阵乘法 -> 请戳这里
2.详细代码解释
(1)定义正规方程函数
def normalEqn(X, y):
theta = np.linalg.inv(X.T@X)@X.T@y #X.T@X等价于np.dot(X.T,X)
return theta
(2)求出最优θ
和批量梯度下降的theta的值有点差距
final_theta2=normalEqn(X2, y2)
final_theta2
'''
matrix([[-1.17961196e-16],
[ 8.84765988e-01],
[-5.31788197e-02]])
'''
'''
使用梯度下降的结果如下
matrix([[-9.62057904e-17, 8.84765988e-01, -5.31788197e-02]])
'''
【5】slearn线性回归算法
from sklearn import linear_model
model = linear_model.LinearRegression()
model.fit(X, y)
x = np.array(X[:, 1].A1)
f = model.predict(X).flatten()
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data.Population, data.Profit, label='Traning Data')
ax.legend(loc=2)
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
plt.show()
效果如下:

和手动写出回归函数的效果是一样的