迁移学习(使用预训练网络)
预训练网络
预训练网络是一个保存好的之前已在大型数据集(大规模图像分类任务)上训练好的卷积神经网络。
如果这个原始数据集足够大且足够通用,那么预训练网络学到的特征的空间层次结构可以作为有效的提取视觉世界特征的模型。即使新问题和新任务与原始任务完全不同学习到的特征在不同问题之间是可移植的,这也是深度学习与浅层学习方法的一个重要优势。它使得深度学习对于小数据问题非常的有效。
Keras内置预训练网络
Keras库中包含VGG16、VGG19、ResNet50、Inception v3、Xception等经典的模型架构。在 ImageNet 上预训练过的用于图像分类的模型:VGG16、VGG19、ResNet50、InceptionV3、InceptionResNetV2、Xception、MobileNet、MobileNetV2、DenseNet、NASNet。
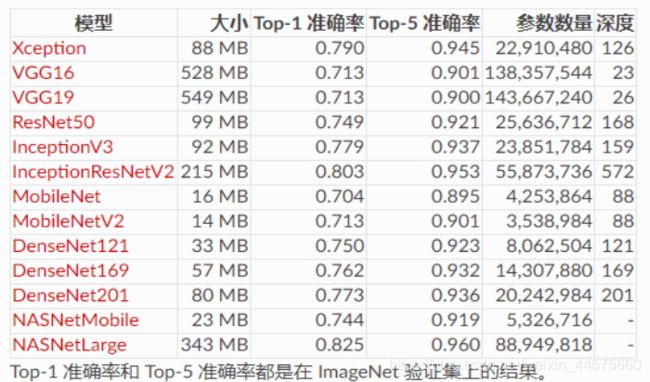
预训练网络API
微调
所谓微调:冻结模型库的底部的卷积层,共同训练新添加的分类器层和顶部部分卷积层。这允许我们“微调”基础模型中的高阶特征表示,以使它们与特定任务更相关。只有分类器已经训练好了,才能微调卷积基的顶部卷积层。如果有没有这样的话,刚开始的训练误差很大,微调之前这些卷积层学到的表示会被破坏掉。
微调步骤
一、在预训练卷积基上添加自定义层。
二、冻结卷积基所有层。
三、训练添加的分类层。
四、解冻卷积基的一部分层。
五、联合训练解冻的卷积层和添加的自定义层。
VGG16与VGG19预训练网络
在2014年,VGG模型架构由Simonyan和Zisserman提出,在“极深的大规模图像识别卷积网络”(Very Deep Convolutional Networks for Large Scale Image Recognition)这篇论文中有介绍。
VGG模型结构简单有效,前几层仅使用3×3卷积核来增加网络深度,通过max pooling(最大池化)依次减少每层的神经元数量,最后三层分别是2个有4096个神经元的全连接层和一个softmax层。
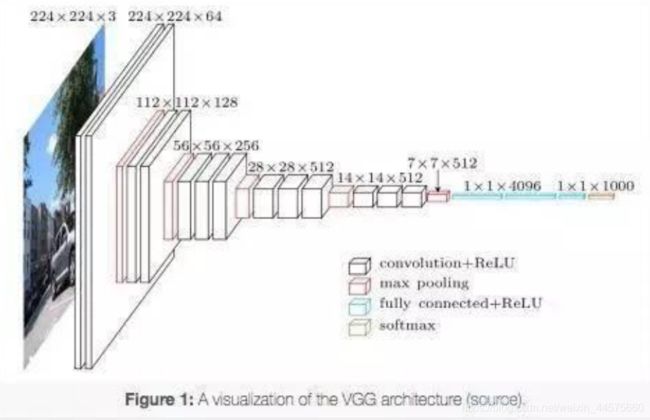
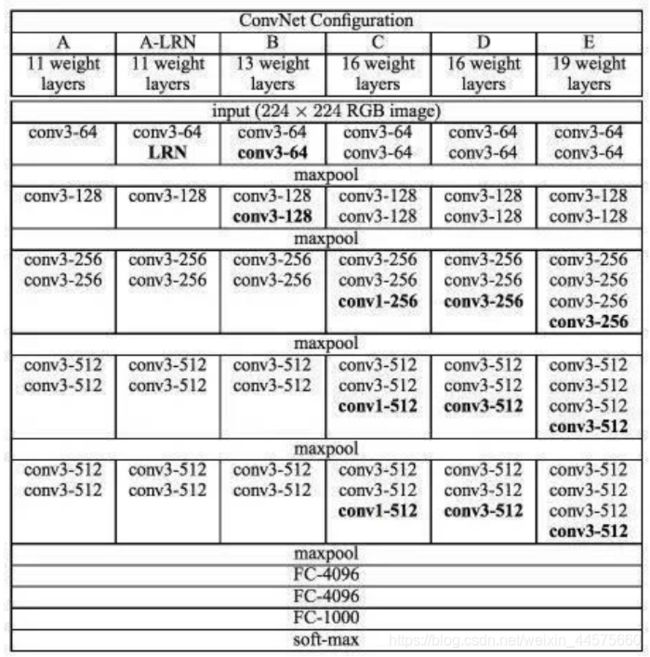
VGG缺点:
- 网络架构weight数量相当大,很消耗磁盘空间。
- 训练非常慢由于其全连接节点的数量较多,再加上网络比较深,VGG16有533MB+,VGG19有574MB。这使得部署VGG比较耗时。
使用VGG16预训练网络实例
数据集
import glob
import tensorflow as tf
keras = tf.keras
layers = tf.keras.layers
train_image_path = glob.glob('/kaggle/input/-2000/dc_2000/train/*/*.jpg')
# print(len(train_image_path))
# print(train_image_path[-5:])
train_image_label = [int(p.split('/')[6] == 'cat') for p in train_image_path]
# print(train_image_label)
# 处理图片
def load_preprosess_image(path, label):
image = tf.io.read_file(path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [256, 256])
image = tf.cast(image, tf.float32)
image = image / 255
return image, label
# 数据集处理
train_image_ds = tf.data.Dataset.from_tensor_slices((train_image_path, train_image_label))
AUTOTUNE = tf.data.experimental.AUTOTUNE
train_image_ds = train_image_ds.map(load_preprosess_image, num_parallel_calls=AUTOTUNE)
# print(train_image_ds)
# for img, label in train_image_ds.take(2):
# plt.imshow(img)
# plt.show()
BATCH_SIZE = 32
train_count = len(train_image_path)
train_image_ds = train_image_ds.shuffle(train_count).repeat().batch(BATCH_SIZE)
test_image_path = glob.glob('/kaggle/input/-2000/dc_2000/test/*/*.jpg')
test_image_label = [int(p.split('/')[6] == 'cat') for p in test_image_path]
test_image_ds = tf.data.Dataset.from_tensor_slices((test_image_path, test_image_label))
print(len(test_image_ds))
test_image_ds = test_image_ds.map(load_preprosess_image, num_parallel_calls=AUTOTUNE)
test_image_ds = test_image_ds.repeat().batch(BATCH_SIZE)
test_count = len(test_image_path)
covn_base = tf.keras.applications.VGG16(weights='imagenet',
include_top=False)
model = keras.Sequential()
model.add(covn_base)
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
print(model.summary())
# 设置为不可训练
covn_base.trainable = False
model.compile(optimizer=keras.optimizers.Adam(lr=0.0005),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(
train_image_ds,
steps_per_epoch=train_count//BATCH_SIZE,
epochs=15,
validation_data=test_image_ds,
validation_steps=test_count//BATCH_SIZE)
训练结果
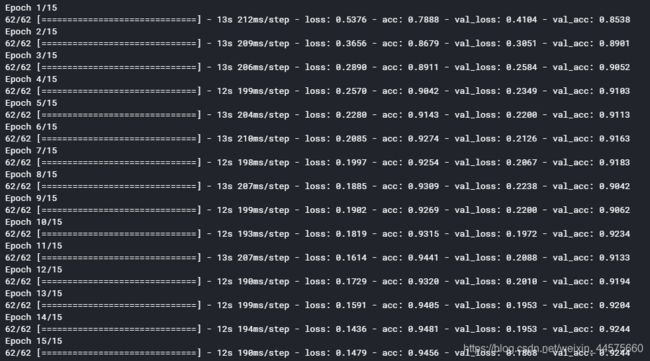
对VGG16预训练网络进行微调
import glob
import tensorflow as tf
keras = tf.keras
layers = tf.keras.layers
train_image_path = glob.glob('/kaggle/input/-2000/dc_2000/train/*/*.jpg')
# print(len(train_image_path))
# print(train_image_path[-5:])
train_image_label = [int(p.split('/')[6] == 'cat') for p in train_image_path]
# print(train_image_label)
# 处理图片
def load_preprosess_image(path, label):
image = tf.io.read_file(path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [256, 256])
image = tf.cast(image, tf.float32)
image = image / 255
return image, label
# 数据集处理
train_image_ds = tf.data.Dataset.from_tensor_slices((train_image_path, train_image_label))
AUTOTUNE = tf.data.experimental.AUTOTUNE
train_image_ds = train_image_ds.map(load_preprosess_image, num_parallel_calls=AUTOTUNE)
# print(train_image_ds)
# for img, label in train_image_ds.take(2):
# plt.imshow(img)
# plt.show()
BATCH_SIZE = 32
train_count = len(train_image_path)
train_image_ds = train_image_ds.shuffle(train_count).repeat().batch(BATCH_SIZE)
test_image_path = glob.glob('/kaggle/input/-2000/dc_2000/test/*/*.jpg')
test_image_label = [int(p.split('/')[6] == 'cat') for p in test_image_path]
test_image_ds = tf.data.Dataset.from_tensor_slices((test_image_path, test_image_label))
print(len(test_image_ds))
test_image_ds = test_image_ds.map(load_preprosess_image, num_parallel_calls=AUTOTUNE)
test_image_ds = test_image_ds.repeat().batch(BATCH_SIZE)
test_count = len(test_image_path)
covn_base = tf.keras.applications.VGG16(weights='imagenet',
include_top=False)
model = keras.Sequential()
model.add(covn_base)
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
print(model.summary())
# ------------微调开始---------------------
# 对后三个层进行微调
covn_base.trainable = True
fine_tune_at = -3
for layer in covn_base.layers[:fine_tune_at]:
layer.trainable = False
# ------------微调结束---------------------
model.compile(optimizer=keras.optimizers.Adam(lr=0.0005),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(
train_image_ds,
steps_per_epoch=train_count//BATCH_SIZE,
epochs=15,
validation_data=test_image_ds,
validation_steps=test_count//BATCH_SIZE)
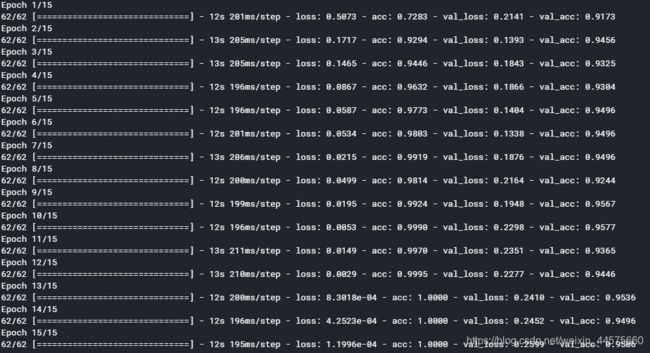
微调之后效果有明显的提升,不过模型出现了过拟合。
Xception预训练网络
在 ImageNet 上预训练的 Xception V1 模型,在 ImageNet 上,该模型取得了验证集 top1 0.790 和 top5 0.945 的准确率。
参数:
include_top: 是否包括顶层的全连接层。
weights: None 代表随机初始化, ‘imagenet’ 代表加载在 ImageNet 上预训练的权值。
input_shape: 可选,输入尺寸元组,仅当 include_top=False 时有效(否则输入形状必须是 (299, 299, 3),因为预训练模型是以这个大小训练的)。它必须拥有 3 个输入通道,且宽高必须不小于 71。例如 (150, 150, 3) 是一个合法的输入尺寸。
pooling: 可选,当 include_top 为 False 时,该参数指定了特征提取时的池化方式。None 代表不池化,直接输出最后一层卷积层的输出,该输出是一个 4D 张量。‘avg’ 代表全局平均池化(GlobalAveragePooling2D),相当于在最后一层卷积层后面再加一层全局平均池化层,输出是一个 2D 张量。‘max’ 代表全局最大池化。
使用Xception预训练网络实例
import glob
import tensorflow as tf
keras = tf.keras
layers = tf.keras.layers
train_image_path = glob.glob('/kaggle/input/-2000/dc_2000/train/*/*.jpg')
# print(len(train_image_path))
# print(train_image_path[-5:])
train_image_label = [int(p.split('/')[6] == 'cat') for p in train_image_path]
# print(train_image_label)
# 处理图片
def load_preprosess_image(path, label):
image = tf.io.read_file(path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [256, 256])
image = tf.cast(image, tf.float32)
image = image / 255
return image, label
# 数据集处理
train_image_ds = tf.data.Dataset.from_tensor_slices((train_image_path, train_image_label))
AUTOTUNE = tf.data.experimental.AUTOTUNE
train_image_ds = train_image_ds.map(load_preprosess_image, num_parallel_calls=AUTOTUNE)
# print(train_image_ds)
# for img, label in train_image_ds.take(2):
# plt.imshow(img)
# plt.show()
BATCH_SIZE = 32
train_count = len(train_image_path)
train_image_ds = train_image_ds.shuffle(train_count).repeat().batch(BATCH_SIZE)
test_image_path = glob.glob('/kaggle/input/-2000/dc_2000/test/*/*.jpg')
test_image_label = [int(p.split('/')[6] == 'cat') for p in test_image_path]
test_image_ds = tf.data.Dataset.from_tensor_slices((test_image_path, test_image_label))
print(len(test_image_ds))
test_image_ds = test_image_ds.map(load_preprosess_image, num_parallel_calls=AUTOTUNE)
test_image_ds = test_image_ds.repeat().batch(BATCH_SIZE)
test_count = len(test_image_path)
# 使用Xception预训练网络
covn_base = keras.applications.xception.Xception(weights='imagenet',
include_top=False,
input_shape=(256, 256, 3),
pooling='avg')
model = keras.Sequential()
model.add(covn_base)
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
print(model.summary())
# 设置为不可训练
covn_base.trainable = False
model.compile(optimizer=keras.optimizers.Adam(lr=0.0005),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(
train_image_ds,
steps_per_epoch=train_count//BATCH_SIZE,
epochs=5,
validation_data=test_image_ds,
validation_steps=test_count//BATCH_SIZE)

对Xception预训练网络进行微调
import glob
import tensorflow as tf
keras = tf.keras
layers = tf.keras.layers
train_image_path = glob.glob('/kaggle/input/-2000/dc_2000/train/*/*.jpg')
# print(len(train_image_path))
# print(train_image_path[-5:])
train_image_label = [int(p.split('/')[6] == 'cat') for p in train_image_path]
# print(train_image_label)
# 处理图片
def load_preprosess_image(path, label):
image = tf.io.read_file(path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [256, 256])
image = tf.cast(image, tf.float32)
image = image / 255
return image, label
# 数据集处理
train_image_ds = tf.data.Dataset.from_tensor_slices((train_image_path, train_image_label))
AUTOTUNE = tf.data.experimental.AUTOTUNE
train_image_ds = train_image_ds.map(load_preprosess_image, num_parallel_calls=AUTOTUNE)
# print(train_image_ds)
# for img, label in train_image_ds.take(2):
# plt.imshow(img)
# plt.show()
BATCH_SIZE = 32
train_count = len(train_image_path)
train_image_ds = train_image_ds.shuffle(train_count).repeat().batch(BATCH_SIZE)
test_image_path = glob.glob('/kaggle/input/-2000/dc_2000/test/*/*.jpg')
test_image_label = [int(p.split('/')[6] == 'cat') for p in test_image_path]
test_image_ds = tf.data.Dataset.from_tensor_slices((test_image_path, test_image_label))
print(len(test_image_ds))
test_image_ds = test_image_ds.map(load_preprosess_image, num_parallel_calls=AUTOTUNE)
test_image_ds = test_image_ds.repeat().batch(BATCH_SIZE)
test_count = len(test_image_path)
# 使用Xception预训练网络
covn_base = keras.applications.xception.Xception(weights='imagenet',
include_top=False,
input_shape=(256, 256, 3),
pooling='avg')
model = keras.Sequential()
model.add(covn_base)
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
print(model.summary())
# 微调
covn_base.trainable = True
fine_tune_at = -33
for layer in covn_base.layers[:fine_tune_at]:
layer.trainable = False
model.compile(optimizer=keras.optimizers.Adam(lr=0.0005),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(
train_image_ds,
steps_per_epoch=train_count//BATCH_SIZE,
epochs=5,
validation_data=test_image_ds,
validation_steps=test_count//BATCH_SIZE)

微调后效果反而不好了