solr 配置多个entity_Solr---企业级搜索应用服务器(一)

当一个人先从自己的内心开始奋斗,他就是个有价值的人
【Solr】
主要内容
- Solr简介
- Solr搜索原理
- Solr单机版安装
- 可视化管理界面
- 新建核心
- 分词
- Dataimport
- 菜单项目Documents使用办法
- 菜单项目query查询使用办法
- 使用SolrJ操作Solr
- Spring Data for Apache Solr
- SolrCloud
一、 Solr简介
1. 为什么使用Solr
在海量数据下,对MySQL或Oracle进行模糊查询或条件查询的效率是很低的。而搜索功能在绝大多数项目中都是必须的,如何提升搜索效率是很多互联网项目必须要考虑的问题。
既然使用关系型数据库进行搜索效率比较低,最直接的解决方案就是使用专用搜索工具进行搜索,从而提升搜索效率。
2. 常见搜索解决方案
基于Apache Lucene(全文检索工具库)实现搜索。但是Lucene的使用对于绝大多数的程序员都是“噩梦级”的。
基于谷歌API实现搜索。
基于百度API实现搜索。
3. Solr简介
Solr是基于Apache Lucene构建的用于搜索和分析的开源解决方案。可提供可扩展索引、搜索功能、高亮显示和文字解析功能。
Solr本质就是一个Java web 项目,且内嵌了Jetty服务器,所以安装起来非常方便。客户端操作Solr的过程和平时我们所写项目一样,就是请求Solr中控制器,处理完数据后把结果响应给客户端。
4. 正向索引和反向索引
只要讨论搜索就不得不提的两个概念:正向索引(forward index)和反向索引(inverted index)。
正向索引:从文档内容到词组的过程。每次搜索的时候需要搜索所有文档,每个文档比较搜索条件和词组。

反向索引:是正向索引的逆向。建立词组和文档的映射关系。通过找到词组就能找到文档内容。(和新华字典找字很像)

二、Solr搜索原理
1. 搜索原理
Solr能够提升检索效率的主要原因就是分词和索引(反向索引)。
分词:会对搜索条件/存储内容进行分词,分成日常所使用的词语。
索引:存储在Solr中内容会按照程序员的要求来是否建立索引。如果要求建立索引会把存储内容中关键字(分词)建立索引。

2. Solr中数据存储说明
Solr为了给内容建立索引,所以Solr就必须具备数据存储能力。所有需要被搜索的内容都需要存储在Solr中,在开发中需要把数据库中数据添加到Solr中进行初始化,每次修改数据库中数据还需要同步Solr中的数据。
Solr中数据存储是存储在Document对象中,对象中可以包含的属性和属性类型都定义在schema.xml中。如果需要自定义属性或自定义属性类型都需要修改schema.xml配置文件。从Solr5开始schema.xml更改名称为managed-schema(没有扩展名)
三、Solr单机版安装
Solr是使用Java编写,所以必选先安装JDK。
1. 上传并解压
上传压缩包solr-8.2.0.tgz到/usr/local/tmp中。
解压
# cd /usr/local/tmp
# tar zxf solr-8.2.0.tgz
2. 复制到/usr/local中
# cp -r solr-8.2.0 ../solr
3. 修改启动参数
修改启动参数,否则启动时报警告。提示设置SOLR_ULIMIT_CHECKS=false
# cd /usr/local/solr/bin
# vim solr.in.sh

4. 启动Solr
Solr内嵌Jetty,直接启动即可。默认监听8983端口。
Solr默认不推荐root账户启动,如果是root账户启动需要添加-force参数。
# ./solr start -force
四、可视化管理界面
在关闭防火墙的前提下,可以在windows的浏览器中访问Solr。
输入:http://192.168.38.199:8983 就可以访问Solr的可视化管理界面。
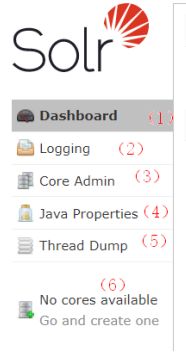
左侧有5个菜单。分别是:
- (1)Dashboard:面板显示Solr的总体信息。
- (2)Logging:日志
- (3)Core Admin:Solr的核心。类似于数据的Database
- (4)Java Perperties:所有Java相关属性。
- (5)Thread Dump:线程相关信息。
- (6)如果有Core,将显示在此处。
五、新建核心
Solr安装完成后默认是没有核心的。需要手动配置。
需要在solr/server/solr下新建文件夹,并给定配置文件,否则无法建立。

1. 新建目录
在/usr/local/solr/server/solr中新建自定义名称目录。此处示例名称为testcore。
# cd /usr/local/solr/server/solr
# mkdir testcore
2. 复制配置文件
在configsets里面包含了_default和sample_techproducts_configs。里面都是配置文件示例。_default属于默认配置,较纯净。sample_techproducts_configs是带有了一些配置示例。
# cp -r configsets/_default/conf/ testcore/
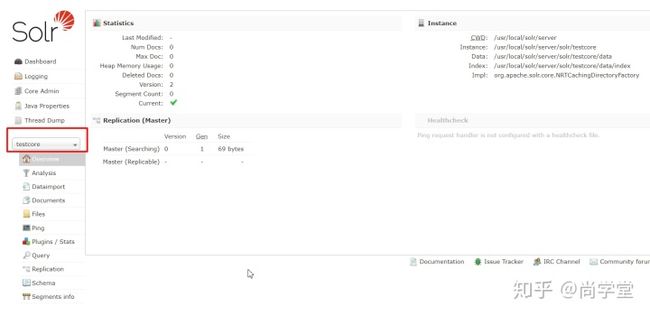
3. 填写Core信息
在可视化管理界面中Core Admin中编写信息后点击Add Core后,短暂延迟后testcore就会创建成功。schema处不用更改。

4. 出现testcore
在客户端管理界面中,选择新建的Core后,就可以按照自己项目的需求进行操作了。
六、分词Analysis
在Solr可视化管理界面中,Core的管理菜单项中都会有Analysis。表示根据Scheme.xml(managed-schema)中配置要求进行解析。
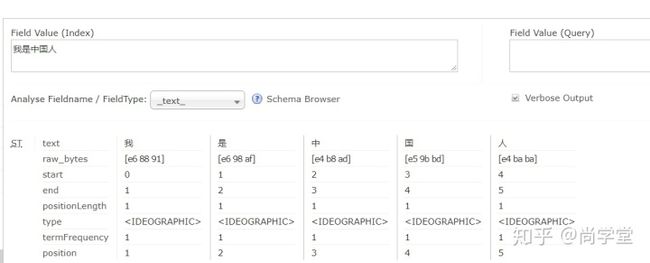
对英文解析就比较简单了,只要按照空格把英文语句拆分成英文单词即可。

但是如果条件是中文时,把一句话按照字进行拆分就不是很合理了。正确的方式是按照合理的词组进行拆分。
1. 中文分词器安装及配置步骤
上传ik-analyzer.jar到webapps中。
去https://search.maven.org/search?q=com.github.magese下载对应版本的ik-analyzer。可以在"软件/Analyzer"中直接获取。
1.1 上传jar到指定目录
上传ik-analyzer-8.2.0.jar到
/usr/local/solr/server/solr-webapp/webapp/WEB-INF/lib目录中
1.2 修改配置文件
修改/usr/local/solr/server/solr/testcore/conf/managed-schema
# vim /usr/local/solr/server/solr/testcore/conf/managed-schema
添加下面内容。
排版:Esc 退出编辑状态下:gg=G
1.3 重启
# cd /usr/local/solr/bin
# ./solr stop -all
# ./solr start -force
1.4 验证
可以在可视化管理界面中找到myfield属性进行验证。
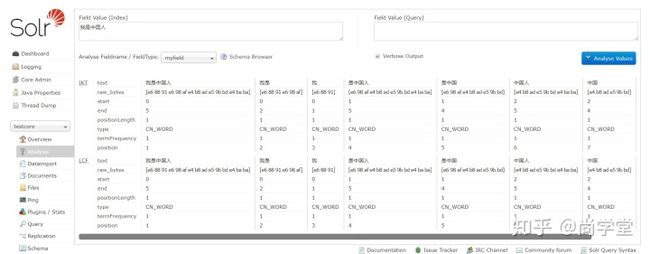
2. managed-schema配置说明
2.1
表示定义一个属性类型。在Solr中属性类型都是自定义的。在上面配置中name="text_ik"为自定义类型。当某个属性取值为text_ik时IK Analyzer才能生效。
2.2
表示向Document中添加一个属性。
常用属性:
- name: 属性名
- type:属性类型。所有类型都是solr使用
配置的 - indexed: 是否建立索引
- stored: solr是否把该属性值响应给搜索用户。
- required:该属性是否是必须的。默认id是必须的。
- multiValued:如果为true,表示该属性为复合属性,此属性中包含了多个其他的属性。常用在多个列作为搜索条件时,把这些列定义定义成一个新的复合属性,通过搜索一个复合属性就可以实现搜索多个列。当设置为true时与
结合使用
2.3
唯一主键,Solr中默认定义id属性为唯一主键。ID的值是不允许重复的。
2.4
名称中允许*进行通配。代表满足特定名称要求的一组属性。
七、Dataimport
可以使用Solr自带的Dataimport功能把数据库中数据快速导入到solr中.
必须保证managed-schema和数据库中表的列对应。
1. 修改配置文件
修改solrconfig.xml,添加下面内容
data-config.xml
2. 新建data-config.xml
和solrconfig.xml同一目录下新建data-config.xml
3. 添加jar
向solr-webapp中添加三个jar。在dist中两个还有一个数据库驱动。
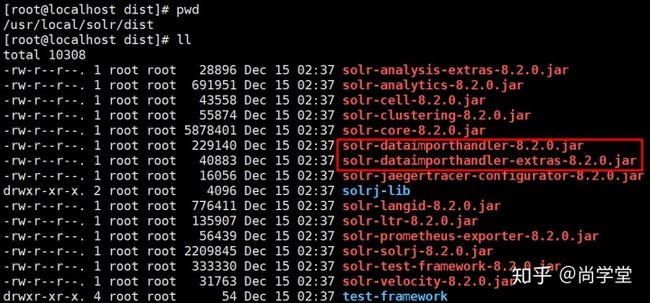
4. 操作
重启solr后,在可视化管理页面中进行数据导入。
注意:
点击导入按钮后,要记得点击刷新按钮。